Redis-1(介绍以及五大数据类型)
一.Nosql概述
1. 单机的Mysql时代
90年达的时候网站的访问量不是特别大,单个的数据库完全够用,但是随着时代的变化,用户增多,网站出现了以下的问题:
- 数据量增加到了一定的程度,单机的数据库就存不下了
- 数据的索引(B+Tree),一个机器内存也存放不下
- 访问量变大之后,一台服务器承受不了压力
![image]()

2. Memcached(缓存)+Mysql+垂直拆分(读写分里)
网站80%的情况下都是在读取数据,每次都要去数据库查询的话就十分麻烦,所以希望减少数据库的压力,可以使用缓存来保证效率,就是查出来之后放到缓存中,别人查相同的时候可以直接调用缓存中的数据
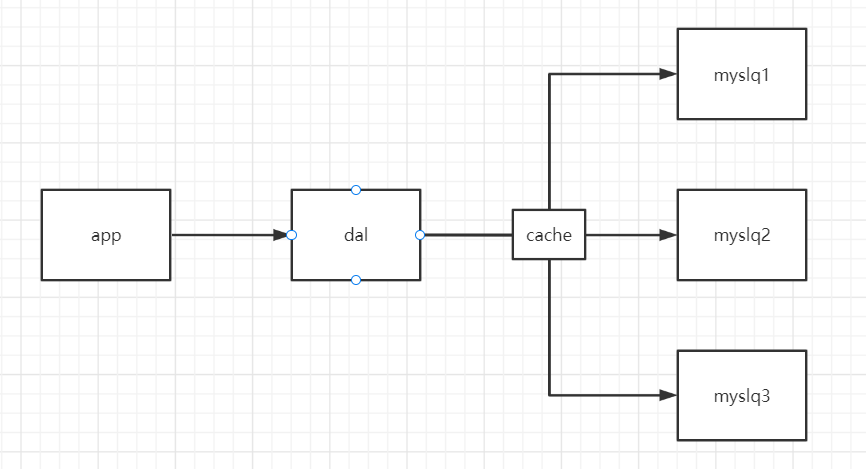
优化经历了以下的过程
- 优化数据库的数据结构和索引(难度大)
- 文件缓存,通过IO流获取比每次访问数据库的效率略高,但是流量爆炸式增长的时候,IO也承受不了
- MemCache是当时最热门的技术,通过数据库和数据库访问层之间加上一层的缓存,第一次访问时查询数据库,将结果存到缓存中,后续的查询先检索cache如果有直接使用,如果没有的话就去数据库中.
3. 分库分表+水平拆分+Mysql集群
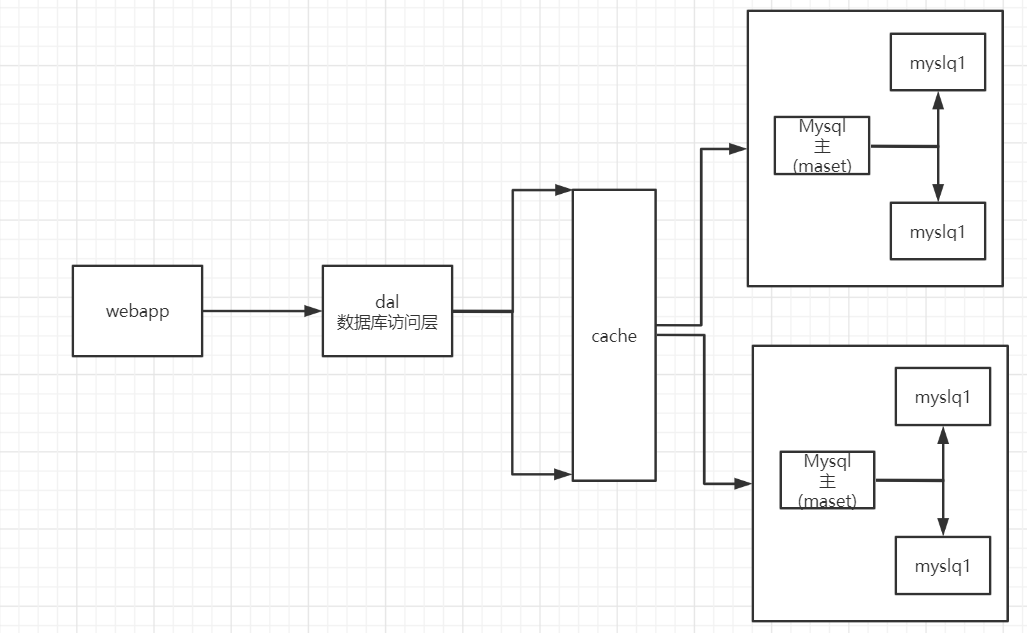
4. 如今的时代
如今的时代信息海量增长,各种各样的数据的出现(用户定位,图片数据等),大数据下的关系型数据库无法满足大量的数据需求,Nosql数据库就可以轻松地解决这些问题

5. 为什么要使用Nosql
用户的个人信息,社交网络,地理位置,等等,用户自己产生的数据,用户日志等等爆发式的增长,这时候我们就需要Nosql数据库,他可以很好地处理上述的所有问题
什么是Nosql
Nosql= not only sql不仅仅是sql
not only structured query language
关系型数据库:列+行,同一个表下的数据的结构是一样的.
非关系型的数据库:数据存储没有固定的格式,并且可以进行横向的扩展
Nosql泛指非关系型数据库,随着web2.0的时代到来,传统的关系型数据库结觉不了2.0时代的问题,尤其是大规模高并发的社区,暴露出很多的问题,Nosql在当今时代的环境下发展迅速,Redis是现在发展最快的Nosql型数据库
Nosql的特点
- 方便扩展
- 大数据量高性能(一秒可以写8万次数据,可读11万次,是一种细粒度的缓存,性能会很高)
- 数据类型是多样的(不需要实现设计数据库,随取随用)
- 传统的RDBMS 和 Nosql比较
传统的 RDBMS(关系型数据库)
SQL
- 数据和关系都存在单独的表中 row col
- 操作,数据定义语言
- 严格的一致性
- 基础的事务
...
Nosql
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库(社交关系)
- 最终一致性
- CAP定理和BASE
- 高性能,高可用,高扩展
- 大数据的时代3V:描述的是问题
海量Velume
多样Variety
实时Velocity - 大数据时代的3高:针对程序的要求
高并发
高可扩
高性能
公司中使用的是:Nosql+RDBMS
二.Redis入门
Redis是什么
概念:是远程字典服务
是一个开源的使用ANSI C语言编写的,支持网络,可基于内存也可以持久化的日志型,Key-Value数据库,并且提供多种语言的API
与momcached一样,为了保证效率,数据基本上都是在缓存中.区别为redis会周期性的把更新的数据写入磁盘中或者把修改了的写入磁盘中,实现了主从同步(master-slave)
Redis能干什么
- 内存存储,持久化(内存是断点丢失的,所以需要持久化)
- 高效率,用于告诉缓存
- 发布订阅信息
- 地图信息分析
- 计时器,计数器(浏览量)
特性
- 多样的数据特性
- 持久化
- 集群
- 事务
...
三.环境搭建(linux)
记得去开启daemonize yes
启动的服务器命令 redis-server sliconfig/redis.conf
启动客户端 redis-cli -p 6379
测试ping 返会 pong则为连接成功
四.性能测试
redis-benchmark:官方提供的压力测试工具
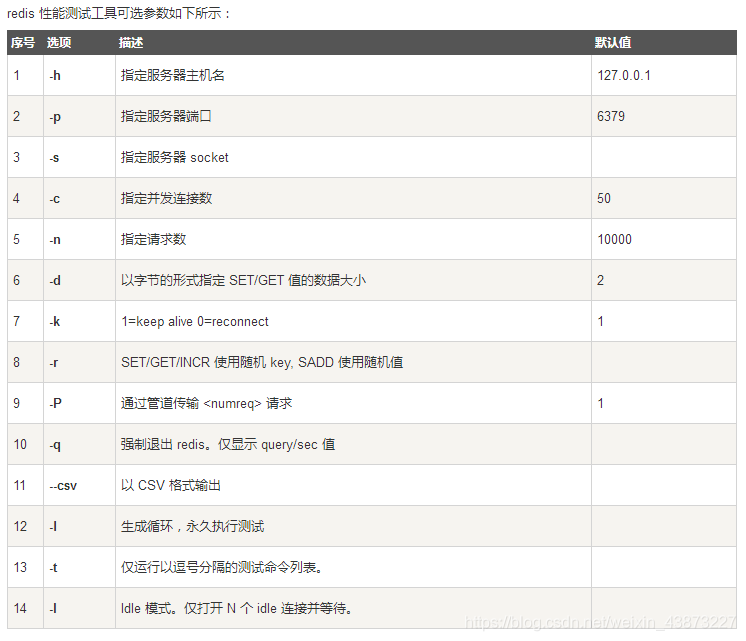
2. 简单测试
# 测试:100个并发连接 100000请求 redis-benchmark -h localhost -p 6379 -c 100 -n 100000
结果
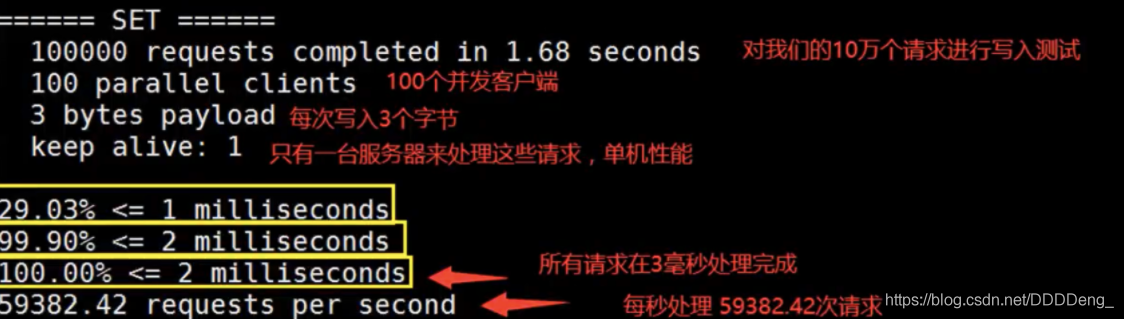
五.基础知识
默认有16个数据库
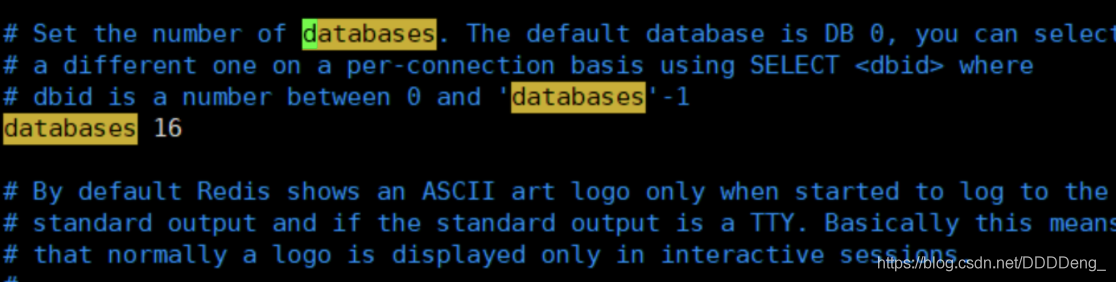
默认使用第0个
16个数据库从0~15可以使用select x 来切换dbsize可以查看当前数据库的大小,与key的数量相关
keys * 可以查看当前数据库中所有的key
flushdb清空当前数据库
flushall清空所有的数据库
redis 是单线程,也是基于内存进行操作的
所以Redis的性能瓶颈不是CPU,而是机器内存和网络带宽
redis为什么单线程还这么快
- 误区1.高性能服务器是多线程
- 误区2.多线程cpu会进行上下文切换,一定单线程效率最高
核心:Redis是将所有的数据放在内存中的,所以说使用单线程去操作效率就是最高的,多线程(CPU上下文会切换:耗时的操作!),对于内存系统来说,如果没有上下文切换效率就是最高的,多次读写都是在一个CPU上的,在内存存储数据情况下,单线程就是最佳的方案。
六.五大数据类型
Redis-key
在redis操作中,无论是什么数据类型,在数据库中都是进行key-value来保存的,通过进行对Redis-key的操作,来完成对数据库中数据的操作
exists key:判断键是否存在
del key:删除键值对
move key db:将键值对转移到指定的数据库
expire key x:设置键值对的过期时间
type key:查看value的数据类型
ttl key:查看当前的过期时间
- 没有过期时间会返回-1
- 有过期时间且过期了会返回-2
- 设置了过期时间,还没过期则会返回剩余的过期时间
rename key newkey:修改key的名称
renamenx key newkey:当newkey不存在的时候,将key改名为newkey
127.0.0.1:6379> keys * # 查看当前数据库所有key (empty list or set) 127.0.0.1:6379> set name qinjiang # set key OK 127.0.0.1:6379> set age 20 OK 127.0.0.1:6379> keys * 1) "age" 2) "name" 127.0.0.1:6379> move age 1 # 将键值对移动到指定数据库 (integer) 1 127.0.0.1:6379> EXISTS age # 判断键是否存在 (integer) 0 # 不存在 127.0.0.1:6379> EXISTS name (integer) 1 # 存在 127.0.0.1:6379> SELECT 1 OK 127.0.0.1:6379[1]> keys * 1) "age" 127.0.0.1:6379[1]> del age # 删除键值对 (integer) 1 # 删除个数 127.0.0.1:6379> set age 20 OK 127.0.0.1:6379> EXPIRE age 15 # 设置键值对的过期时间 (integer) 1 # 设置成功 开始计数 127.0.0.1:6379> ttl age # 查看key的过期剩余时间 (integer) 13 127.0.0.1:6379> ttl age (integer) 11 127.0.0.1:6379> ttl age (integer) 9 127.0.0.1:6379> ttl age (integer) -2 # -2 表示key过期,-1表示key未设置过期时间 127.0.0.1:6379> get age # 过期的key 会被自动delete (nil) 127.0.0.1:6379> keys * "name" 127.0.0.1:6379> type name # 查看value的数据类型 string
String(字符串)
普通的set/get直接
常用的命令及示例:
append key value向指定的key的value后面追加字符
127.0.0.1:6379> set msg hello OK 127.0.0.1:6379> append msg " world" (integer) 11 127.0.0.1:6379> get msg “hello world”
incr/decr key将指定的key的value数值进行+1/-1可以用于进行记录阅读量等等
127.0.0.1:6379> set age 20 OK 127.0.0.1:6379> incr age (integer) 21 127.0.0.1:6379> decr age (integer) 20
strlen key获取key保存值的字符串长度
127.0.0.1:6379> get msg “hello world” 127.0.0.1:6379> STRLEN msg (integer) 11
getrange key start end按起止位置获取字符串(闭区间,起止位置都会获取)
127.0.0.1:6379> get msg “hello world” 127.0.0.1:6379> GETRANGE msg 3 9 “lo worl”
setrange key offset value用于指定的value替换key中的offset开始的值
127.0.0.1:6379> set msg hello OK 127.0.0.1:6379> setrange msg 2 hello (integer) 7 127.0.0.1:6379> get msg "hehello" 127.0.0.1:6379> set msg2 world OK 127.0.0.1:6379> setrange msg2 2 ww (integer) 5 127.0.0.1:6379> get msg2 "wowwd"
getset key value将给定的key的值设置为value,并返回key的旧值
127.0.0.1:6379> GETSET msg test “hello world”
setnx key value仅限key不存在的时候进行set
127.0.0.1:6379> SETNX msg test (integer) 0 127.0.0.1:6379> SETNX name sakura (integer) 1
setex key seconds valueset键值对并设置过期时间
127.0.0.1:6379> setex name 10 root OK 127.0.0.1:6379> get name (nil)
mset key1 value1[key2 value2...]批量设置set键值对
127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3 OK
msetnx key1 value1[key2 value2...]批量设置键值对,仅当参数中所有的key都不存在时执行
mget key1[key2...]批量获取多个key保存的值
使用场景
- 计数器
- 统计多单位数量: uid : 1234134 :follow()
- 粉丝数
- 对象存储缓存
List(列表)
LPUSH/RPUSH key value1[value2..]从左边/右边向列表中PUSH值(一个或者多个)。LRANGE key start end获取list 起止元素(索引从左往右 递增)LPUSHX/RPUSHX key value向已存在的列名中push值(一个或者多个)LINSERT key BEFORE|AFTER pivot value在指定列表元素的前/后 插入valueLLEN key查看列表长度LINDEX key index通过索引获取列表元素LSET key index value通过索引为元素设值LPOP/RPOP key从最左边/最右边移除值 并返回RPOPLPUSH source destination将列表的尾部(右)最后一个值弹出,并返回,然后加到另一个列表的头部LTRIM key start end通过下标截取指定范围内的列表LREM key count value List中是允许value重复的 count > 0:从头部开始搜索 然后删除指定的value 至多删除count个 count < 0:从尾部开始搜索… count = 0:删除列表中所有的指定value。BLPOP/BRPOP key1[key2] timout移出并获取列表的第一个/最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。BRPOPLPUSH source destination timeout和RPOPLPUSH功能相同,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
---------------------------LPUSH---RPUSH---LRANGE--------------------------------
127.0.0.1:6379> LPUSH mylist k1 # LPUSH mylist=>{1}
(integer) 1
127.0.0.1:6379> LPUSH mylist k2 # LPUSH mylist=>{2,1}
(integer) 2
127.0.0.1:6379> RPUSH mylist k3 # RPUSH mylist=>{2,1,3}
(integer) 3
127.0.0.1:6379> get mylist # 普通的get是无法获取list值的
(error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> LRANGE mylist 0 4 # LRANGE 获取起止位置范围内的元素
"k2"
"k1"
"k3"
127.0.0.1:6379> LRANGE mylist 0 2
"k2"
"k1"
"k3"
127.0.0.1:6379> LRANGE mylist 0 1
"k2"
"k1"
127.0.0.1:6379> LRANGE mylist 0 -1 # 获取全部元素
"k2"
"k1"
"k3"
---------------------------LPUSHX---RPUSHX-----------------------------------
127.0.0.1:6379> LPUSHX list v1 # list不存在 LPUSHX失败
(integer) 0
127.0.0.1:6379> LPUSHX list v1 v2
(integer) 0
127.0.0.1:6379> LPUSHX mylist k4 k5 # 向mylist中 左边 PUSH k4 k5
(integer) 5
127.0.0.1:6379> LRANGE mylist 0 -1
"k5"
"k4"
"k2"
"k1"
"k3"
---------------------------LINSERT--LLEN--LINDEX--LSET----------------------------
127.0.0.1:6379> LINSERT mylist after k2 ins_key1 # 在k2元素后 插入ins_key1
(integer) 6
127.0.0.1:6379> LRANGE mylist 0 -1
"k5"
"k4"
"k2"
"ins_key1"
"k1"
"k3"
127.0.0.1:6379> LLEN mylist # 查看mylist的长度
(integer) 6
127.0.0.1:6379> LINDEX mylist 3 # 获取下标为3的元素
"ins_key1"
127.0.0.1:6379> LINDEX mylist 0
"k5"
127.0.0.1:6379> LSET mylist 3 k6 # 将下标3的元素 set值为k6
OK
127.0.0.1:6379> LRANGE mylist 0 -1
"k5"
"k4"
"k2"
"k6"
"k1"
"k3"
---------------------------LPOP--RPOP--------------------------
127.0.0.1:6379> LPOP mylist # 左侧(头部)弹出
"k5"
127.0.0.1:6379> RPOP mylist # 右侧(尾部)弹出
"k3"
---------------------------RPOPLPUSH--------------------------
127.0.0.1:6379> LRANGE mylist 0 -1
"k4"
"k2"
"k6"
"k1"
127.0.0.1:6379> RPOPLPUSH mylist newlist # 将mylist的最后一个值(k1)弹出,加入到newlist的头部
"k1"
127.0.0.1:6379> LRANGE newlist 0 -1
"k1"
127.0.0.1:6379> LRANGE mylist 0 -1
"k4"
"k2"
"k6"
---------------------------LTRIM--------------------------
127.0.0.1:6379> LTRIM mylist 0 1 # 截取mylist中的 0~1部分
OK
127.0.0.1:6379> LRANGE mylist 0 -1
"k4"
"k2"
初始 mylist: k2,k2,k2,k2,k2,k2,k4,k2,k2,k2,k2
---------------------------LREM--------------------------
127.0.0.1:6379> LREM mylist 3 k2 # 从头部开始搜索 至多删除3个 k2
(integer) 3
删除后:mylist: k2,k2,k2,k4,k2,k2,k2,k2
127.0.0.1:6379> LREM mylist -2 k2 #从尾部开始搜索 至多删除2个 k2
(integer) 2
删除后:mylist: k2,k2,k2,k4,k2,k2
---------------------------BLPOP--BRPOP--------------------------
mylist: k2,k2,k2,k4,k2,k2
newlist: k1
127.0.0.1:6379> BLPOP newlist mylist 30 # 从newlist中弹出第一个值,mylist作为候选
"newlist" # 弹出
"k1"
127.0.0.1:6379> BLPOP newlist mylist 30
"mylist" # 由于newlist空了 从mylist中弹出
"k2"
127.0.0.1:6379> BLPOP newlist 30
(30.10s) # 超时了
127.0.0.1:6379> BLPOP newlist 30 # 我们连接另一个客户端向newlist中push了test, 阻塞被解决。
"newlist"
"test"
(12.54s)
小结
- list实际上是一个链表, before Node after , left/right都可插入值
- 如果key不存在,则创建新的链表
- 如果key存在,新增内容
- 如果移除了所有值,空链表,也代表不存在
- 在两边插入或者改动值,效率最高,修改中间元素,效率相对较低
应用
消息队列 消息队列 栈
Set(集合)
Redis是string类型的无序集合,集合成员是唯一的,这就意味着集合中不能出现重复的数据
Redis中集合是通过hash表实现的,所以添加,删除,查找的复杂度都是O(1)
集合中最大的成员数为232-1(4294967295, 每个集合可存储40多亿个成员)
sadd key member1[member2...]向集合中无序增加一个/多个成员scard key获取集合的成员数smembers key返回集合中所有的成员sismember key member查询member元素是否是集合的成员,结果是无序的srandmember key[count]随机返回集合中的count个成员,count的缺省值为1spop key随机移除并返回集合中的count个成员,count的值默认为1smove source destionation key1[key2...]在SDIFF的基础上,将结果集合中覆盖.不能保存到其他类型keysrem key member[member2...]移除集合一个/多个成员sdiff key1[key2...]返回所有集合的差集key1-key2-...sinter key1 [key2...]返回所有集合的交集
---------------SADD--SCARD--SMEMBERS--SISMEMBER--------------------
127.0.0.1:6379> SADD myset m1 m2 m3 m4 # 向myset中增加成员 m1~m4
(integer) 4
127.0.0.1:6379> SCARD myset # 获取集合的成员数目
(integer) 4
127.0.0.1:6379> smembers myset # 获取集合中所有成员
"m4"
"m3"
"m2"
"m1"
127.0.0.1:6379> SISMEMBER myset m5 # 查询m5是否是myset的成员
(integer) 0 # 不是,返回0
127.0.0.1:6379> SISMEMBER myset m2
(integer) 1 # 是,返回1
127.0.0.1:6379> SISMEMBER myset m3
(integer) 1
---------------------SRANDMEMBER--SPOP----------------------------------
127.0.0.1:6379> SRANDMEMBER myset 3 # 随机返回3个成员
"m2"
"m3"
"m4"
127.0.0.1:6379> SRANDMEMBER myset # 随机返回1个成员
"m3"
127.0.0.1:6379> SPOP myset 2 # 随机移除并返回2个成员
"m1"
"m4"
将set还原到{m1,m2,m3,m4}
---------------------SMOVE--SREM----------------------------------------
127.0.0.1:6379> SMOVE myset newset m3 # 将myset中m3成员移动到newset集合
(integer) 1
127.0.0.1:6379> SMEMBERS myset
"m4"
"m2"
"m1"
127.0.0.1:6379> SMEMBERS newset
"m3"
127.0.0.1:6379> SREM newset m3 # 从newset中移除m3元素
(integer) 1
127.0.0.1:6379> SMEMBERS newset
(empty list or set)
下面开始是多集合操作,多集合操作中若只有一个参数默认和自身进行运算
setx=>{m1,m2,m4,m6}, sety=>{m2,m5,m6}, setz=>{m1,m3,m6}
-----------------------------SDIFF------------------------------------
127.0.0.1:6379> SDIFF setx sety setz # 等价于setx-sety-setz
"m4"
127.0.0.1:6379> SDIFF setx sety # setx - sety
"m4"
"m1"
127.0.0.1:6379> SDIFF sety setx # sety - setx
"m5"
-------------------------SINTER---------------------------------------
共同关注(交集)
127.0.0.1:6379> SINTER setx sety setz # 求 setx、sety、setx的交集
"m6"
127.0.0.1:6379> SINTER setx sety # 求setx sety的交集
"m2"
"m6"
-------------------------SUNION---------------------------------------
127.0.0.1:6379> SUNION setx sety setz # setx sety setz的并集
"m4"
"m6"
"m3"
"m2"
"m1"
"m5"
127.0.0.1:6379> SUNION setx sety # setx sety 并集
"m4"
"m6"
"m2"
"m1"
"m5"
Hash(哈希)
Key-(value(key-value))
Redis hash 是一个string类型的field和value的映射表,hash适合存储对象
Set就是一种简化的Hash,只变动key,而value使用默认值填充.可以将一个Hash表作为一个对象进行存储,表中存放对象的信息.
hset key field value将hash表key的字段field的值设为value,重复设置同一field会覆盖,返回0hmset key field1 value1[field2 value2...]同时将多个field-value(域-值)对设置到hash表key中.hsetnx key field只有在字段field不存在的时候,设置hash表字段的值.hexists key field查看hash表key中,指定的字段是否存在.hget key field1[field2]获取所有给定字段的值hgetall key获取在hash表key的所有字段和值hlen key获取hash表中的字段的数量hvals key获取hash表中的所有值hdel key field1[field2...]删除hash表key中的一个/多个field字段hincrby key field n为hash表key中的指定字段的整数值加上增量n,并返回增量后的结果,适用于整数型字段hincrbyloat key field n为hash表key中的指定字段的浮点数值加上增量n
------------------------HSET--HMSET--HSETNX---------------- 127.0.0.1:6379> HSET studentx name sakura # 将studentx哈希表作为一个对象,设置name为sakura (integer) 1 127.0.0.1:6379> HSET studentx name gyc # 重复设置field进行覆盖,并返回0 (integer) 0 127.0.0.1:6379> HSET studentx age 20 # 设置studentx的age为20 (integer) 1 127.0.0.1:6379> HMSET studentx sex 1 tel 15623667886 # 设置sex为1,tel为15623667886 OK 127.0.0.1:6379> HSETNX studentx name gyc # HSETNX 设置已存在的field (integer) 0 # 失败 127.0.0.1:6379> HSETNX studentx email 12345@qq.com (integer) 1 # 成功 ----------------------HEXISTS-------------------------------- 127.0.0.1:6379> HEXISTS studentx name # name字段在studentx中是否存在 (integer) 1 # 存在 127.0.0.1:6379> HEXISTS studentx addr (integer) 0 # 不存在 -------------------HGET--HMGET--HGETALL----------- 127.0.0.1:6379> HGET studentx name # 获取studentx中name字段的value "gyc" 127.0.0.1:6379> HMGET studentx name age tel # 获取studentx中name、age、tel字段的value "gyc" "20" "15623667886" 127.0.0.1:6379> HGETALL studentx # 获取studentx中所有的field及其value "name" "gyc" "age" "20" "sex" "1" "tel" "15623667886" "email" "12345@qq.com" --------------------HKEYS--HLEN--HVALS-------------- 127.0.0.1:6379> HKEYS studentx # 查看studentx中所有的field "name" "age" "sex" "tel" "email" 127.0.0.1:6379> HLEN studentx # 查看studentx中的字段数量 (integer) 5 127.0.0.1:6379> HVALS studentx # 查看studentx中所有的value "gyc" "20" "1" "15623667886" "12345@qq.com" -------------------------HDEL-------------------------- 127.0.0.1:6379> HDEL studentx sex tel # 删除studentx 中的sex、tel字段 (integer) 2 127.0.0.1:6379> HKEYS studentx "name" "age" "email" -------------HINCRBY--HINCRBYFLOAT------------------------ 127.0.0.1:6379> HINCRBY studentx age 1 # studentx的age字段数值+1 (integer) 21 127.0.0.1:6379> HINCRBY studentx name 1 # 非整数字型字段不可用 (error) ERR hash value is not an integer 127.0.0.1:6379> HINCRBYFLOAT studentx weight 0.6 # weight字段增加0.6 "90.8"
小结
hash变更的数据user name age ,尤其是用户信息类的,经常改变的信息,hash更适合于对象的存储,String更适合字符串存储
Zset(有序集合)
每个元素都会关联一个double类型的分数,redis正是通过这种方式来为集合中的成员进行小到大的排序
score相同,按字典顺序排序
zadd key score member1[socre2 member2]向有序集合中添加一个或者多个成员,或者更新已存在成员的分数zcard key获取成员count个数zcount key min max计算在有序集合中指定区间score的成员数zincrby key n member有序集合中对指定成员的分数加增量nzscore key member返回有序结合中,成员的分数值zrange key start end通过索引区间返回有序结合的成员zrangbyscore key -inf +inf返回区间内所有的从小到大的排序
-------------------ZADD--ZCARD--ZCOUNT--------------
127.0.0.1:6379> ZADD myzset 1 m1 2 m2 3 m3 # 向有序集合myzset中添加成员m1 score=1 以及成员m2 score=2..
(integer) 2
127.0.0.1:6379> ZCARD myzset # 获取有序集合的成员数
(integer) 2
127.0.0.1:6379> ZCOUNT myzset 0 1 # 获取score在 [0,1]区间的成员数量
(integer) 1
127.0.0.1:6379> ZCOUNT myzset 0 2
(integer) 2
----------------ZINCRBY--ZSCORE--------------------------
127.0.0.1:6379> ZINCRBY myzset 5 m2 # 将成员m2的score +5
"7"
127.0.0.1:6379> ZSCORE myzset m1 # 获取成员m1的score
"1"
127.0.0.1:6379> ZSCORE myzset m2
"7"
--------------ZRANK--ZRANGE-----------------------------------
127.0.0.1:6379> ZRANK myzset m1 # 获取成员m1的索引,索引按照score排序,score相同索引值按字典顺序顺序增加
(iteger) 0
127.0.0.1:6379> ZRANK myzset m2
(integer) 2
127.0.0.1:6379> ZRANGE myzset 0 1 # 获取索引在 0~1的成员
"m1"
"m3"
127.0.0.1:6379> ZRANGE myzset 0 -1 # 获取全部成员
"m1"
"m3"
"m2"
testset=>{abc,add,amaze,apple,back,java,redis} score均为0
------------------ZRANGEBYLEX---------------------------------
127.0.0.1:6379> ZRANGEBYLEX testset - + # 返回所有成员
"abc"
"add"
"amaze"
"apple"
"back"
"java"
"redis"
127.0.0.1:6379> ZRANGEBYLEX testset - + LIMIT 0 3 # 分页 按索引显示查询结果的 0,1,2条记录
"abc"
"add"
"amaze"
127.0.0.1:6379> ZRANGEBYLEX testset - + LIMIT 3 3 # 显示 3,4,5条记录
"apple"
"back"
"java"
127.0.0.1:6379> ZRANGEBYLEX testset (- [apple # 显示 (-,apple] 区间内的成员
"abc"
"add"
"amaze"
"apple"
127.0.0.1:6379> ZRANGEBYLEX testset [apple [java # 显示 [apple,java]字典区间的成员
"apple"
"back"
"java"
-----------------------ZRANGEBYSCORE---------------------
127.0.0.1:6379> ZRANGEBYSCORE myzset 1 10 # 返回score在 [1,10]之间的的成员
"m1"
"m3"
"m2"
127.0.0.1:6379> ZRANGEBYSCORE myzset 1 5
"m1"
"m3"
--------------------ZLEXCOUNT-----------------------------
127.0.0.1:6379> ZLEXCOUNT testset - +
(integer) 7
127.0.0.1:6379> ZLEXCOUNT testset [apple [java
(integer) 3
------------------ZREM--ZREMRANGEBYLEX--ZREMRANGBYRANK--ZREMRANGEBYSCORE--------------------------------
127.0.0.1:6379> ZREM testset abc # 移除成员abc
(integer) 1
127.0.0.1:6379> ZREMRANGEBYLEX testset [apple [java # 移除字典区间[apple,java]中的所有成员
(integer) 3
127.0.0.1:6379> ZREMRANGEBYRANK testset 0 1 # 移除排名0~1的所有成员
(integer) 2
127.0.0.1:6379> ZREMRANGEBYSCORE myzset 0 3 # 移除score在 [0,3]的成员
(integer) 2
testset=> {abc,add,apple,amaze,back,java,redis} score均为0
myzset=> {(m1,1),(m2,2),(m3,3),(m4,4),(m7,7),(m9,9)}
----------------ZREVRANGE--ZREVRANGEBYSCORE--ZREVRANGEBYLEX-----------
127.0.0.1:6379> ZREVRANGE myzset 0 3 # 按score递减排序,然后按索引,返回结果的 0~3
"m9"
"m7"
"m4"
"m3"
127.0.0.1:6379> ZREVRANGE myzset 2 4 # 返回排序结果的 索引的2~4
"m4"
"m3"
"m2"
127.0.0.1:6379> ZREVRANGEBYSCORE myzset 6 2 # 按score递减顺序 返回集合中分数在[2,6]之间的成员
"m4"
"m3"
"m2"
127.0.0.1:6379> ZREVRANGEBYLEX testset [java (add # 按字典倒序 返回集合中(add,java]字典区间的成员
"java"
"back"
"apple"
"amaze"
-------------------------ZREVRANK------------------------------
127.0.0.1:6379> ZREVRANK myzset m7 # 按score递减顺序,返回成员m7索引
(integer) 1
127.0.0.1:6379> ZREVRANK myzset m2
(integer) 4
mathscore=>{(xm,90),(xh,95),(xg,87)} 小明、小红、小刚的数学成绩
enscore=>{(xm,70),(xh,93),(xg,90)} 小明、小红、小刚的英语成绩
-------------------ZINTERSTORE--ZUNIONSTORE-----------------------------------
127.0.0.1:6379> ZINTERSTORE sumscore 2 mathscore enscore # 将mathscore enscore进行合并 结果存放到sumscore
(integer) 3
127.0.0.1:6379> ZRANGE sumscore 0 -1 withscores # 合并后的score是之前集合中所有score的和
"xm"
"160"
"xg"
"177"
"xh"
"188"
127.0.0.1:6379> ZUNIONSTORE lowestscore 2 mathscore enscore AGGREGATE MIN # 取两个集合的成员score最小值作为结果的
(integer) 3
127.0.0.1:6379> ZRANGE lowestscore 0 -1 withscores
"xm"
"70"
"xg"
"87"
"xh"
"93"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号