

KafKa概念与安装 - 详解
Kafka 的核心概念
- Producer(生产者):向 Kafka 集群发送消息的应用程序
- Consumer(消费者):从 Kafka 集群读取消息的应用程序
- Broker(代理):Kafka 服务器,负责存储消息和处理客户端请求
- Topic(主题):消息的分类名称,生产者向特定主题发送消息,消费者从特定主题读取消息
- Partition(分区):每个主题分为多个分区,实现消息的并行处理和存储
- Offset(偏移量):每个分区中的消息都有一个唯一的偏移量,用于标识消息位置
- Consumer Group(消费者组):多个消费者组成的群体,共同消费一个主题的消息
Kafka 的主要特点
- 高吞吐量:能够处理每秒数十万条消息
- 持久性:消息被持久化到磁盘,可持久保存
- 分布式:集群部署,具有高可用性和容错性
- 实时性:支持实时数据处理和流处理
- 可扩展性:可以轻松扩展集群规模
为什么使用消息中间件(MQ)
- 异步调用,一个应用内部的两个模块之间(同步变异步)
- 应用解耦(提供基于数据的接口层)
- 流量削峰(缓解瞬时高流量压力)
典型应用场景
- 日志收集:集中收集分布式系统的日志数据(如 ELK 架构中的日志传输)。
- 实时数据管道:在不同系统间构建实时数据流转通道(如数据库变更同步、业务数据实时分发)。
- 流处理:与流处理框架(如 Flink、Spark Streaming)结合,实现实时数据清洗、分析和计算(如实时监控、实时推荐)。
- 消息系统:作为高可靠的消息中间件,实现系统解耦和异步通信。
kafka的安装
kafka安装:⾸先恢复快照
(1)下载并上传kafka_2.11-2.4.0.tgz到/opt/software
(2)解压:tar -zxvf kafka_2.11-2.4.0.tgz -C /opt/install
(3)创建软链接:ln -s kafka_2.11-2.4.0/ kafka
(4)配置环境变量:vi /etc/profile
export KAFKA_HOME=/opt/install/kafka
export KAFKA_HOME=/opt/install/kafka
(5)使环境变量⽣效:source /etc/profile
(6)修改config/server.properties⽂件:
log.dirs=/opt/install/kafka/kafka-logs zookeeper.connect=hadoop101:2181/kafka末尾添加:delete.topic.enable=true
(7)启动zookeeper服务:zkServer.sh start
(8)启动kafka服务:bin/kafka-server-start.sh -daemon config/server.properties
(9)新开窗⼝,验证服务:jps
(10)创建主题:kafka-topics.sh --create --bootstrap-server hadoop101:9092 --topic mytopic001
(11)查看所有主题:kafka-topics.sh --list --bootstrap-server hadoop101:9092
(12)查看特定主题:kafka-topics.sh --describe --bootstrap-server hadoop101:9092 --topic mytopic001
(13)新开窗⼝,⽣产消息:kafka-console-producer.sh --broker-list hadoop101:9092 --topic mytopic001 --property parse.k
ey=true【默认消息键与消息值间使⽤“Tab键”进⾏分隔】
(14)新开窗⼝,消费消息:kafka-console-consumer.sh --bootstra
p-server hadoop101:9092 --topic mytopic001 --property print.key=true --from-beginning
,然后在⽣产窗⼝中输⼊数据并观察消费窗⼝
(15)删除主题:kafka-topics.sh --delete --bootstrap-server
hadoop101:9092 --topic mytopic001
(16)停⽌kafka服务:bin/kafka-server-stop.sh
(17)停⽌zookeeper服务:zkServer.sh stop
流程:生产者发消息到主题分区→Broker 存储并同步副本→消费者组从分区拉取消息处理。
核心特点:分区并行提升吞吐量,副本保证高可用,支持海量数据持久化与实时处理。
Kafka Topic
1. Topic
主题是已发布消息的类别名称
发布和订阅数据必须指定主题
主题副本数量不⼤于Brokers个数
Partition
⼀个主题包含多个分区,默认按Key Hash分区
每个Partition对应⼀个⽂件夹<topic_name>-<partition_id>
每个Partition被视为⼀个有序的⽇志⽂件(LogSegment)
Replication策略是基于Partition,⽽不是Topic
每个Partition都有⼀个Leader,0或多个Follower且被动复制
Leader
基本的配置在/opt/install/kafka/conf/server.properties⽂件中
kafka-topics.sh --create
--bootstrap-server hadoop101:9092 \
--topic mytopic002 --partitions 3
--replication-factor 3
创建⼀个主题,分区数为3, 副本数为1
kafka-topics.sh --create \
--bootstrap-server hadoop101:9092 \
--topic mytopic002 \
--partitions 3 \
--replication-factor 1
查看特定主题
kafka-topics.sh --describe \
--bootstrap-server hadoop101:9092 \
--topic mytopic002Kafka Producer
2. Producer直接发送消息到Broker上的Leader Partition
Producer发布消息时根据消息是否有键,采⽤不同的分区策略:
消息没有键时,通过轮询⽅式进⾏客户端负载均衡;
消息有键时,根据分区语义(例如hash)确保相同键的消息总是发
送到同⼀分区
15. Kafka Consumer
1. 消费者通过订阅消费消息
offset的管理是基于消费组(group.id)的级别
每个Partition只能由同⼀消费组内的⼀个Consumer来消费
每个Consumer可以消费多个分区
消费过的数据仍会保留在Kafka中
同⼀组的消费者数量不能超过分区数量
消费模式
发布/订阅:所有消费者可被分配到不同的消费组
一个生产者,两个消费者
(13)新窗口,生产消息
kafka-console-producer.sh \
--broker-list hadoop101:9092 \ # 指定 Kafka 集群的 Broker 地址
--topic mytopic002 \ # 消息要发送到的目标主题
--property parse.key=true # 允许输入消息的 Key(键)
(14)新开窗口,消费消息
新开窗⼝,消费消息:kafka-console-consumer.sh --bootstra
p-server hadoop101:9092 --topic mytopic002 --property pr
int.key=true
(14)新开窗⼝,消费消息:kafka-console-consumer.sh --bootstra
p-server hadoop101:9092 --topic mytopic002 --property pr
int.key=true
两个消费者,在同一个默认组里,只能有一个消费?????
指定两个消费者
(13)新窗口,生产消息
kafka-console-producer.sh \
--broker-list hadoop101:9092 \ # 指定 Kafka 集群的 Broker 地址
--topic mytopic002 \ # 消息要发送到的目标主题
--property parse.key=true # 允许输入消息的 Key(键)
两消费者,不在通过一个组里面 -- group
# 消费者1(组g1)
kafka-console-consumer.sh
--bootstrap-server hadoop101:9092 \
--topic mytopic002
--property print.key=true
--group g1
# 消费者2(组g2)
kafka-console-consumer.sh
--bootstrap-server hadoop101:9092 \
--topic mytopic002
--property print.key=true
--group g2
两个消费者在不同的组里面都会收到消息kafkaMessage
ZooKeeper在Kafka中的作⽤
1. Broker注册并监控状态
/brokers/ids
Topic注册
/brokers/topics
⽣产者负载均衡
每个Broker启动时,都会完成Broker注册过程,⽣产者会通过该节
点的变化来动态地感知到Broker服务器列表的变更
offset维护
Kafka使⽤⾃⼰的内部主题维护offset
kafka数据流
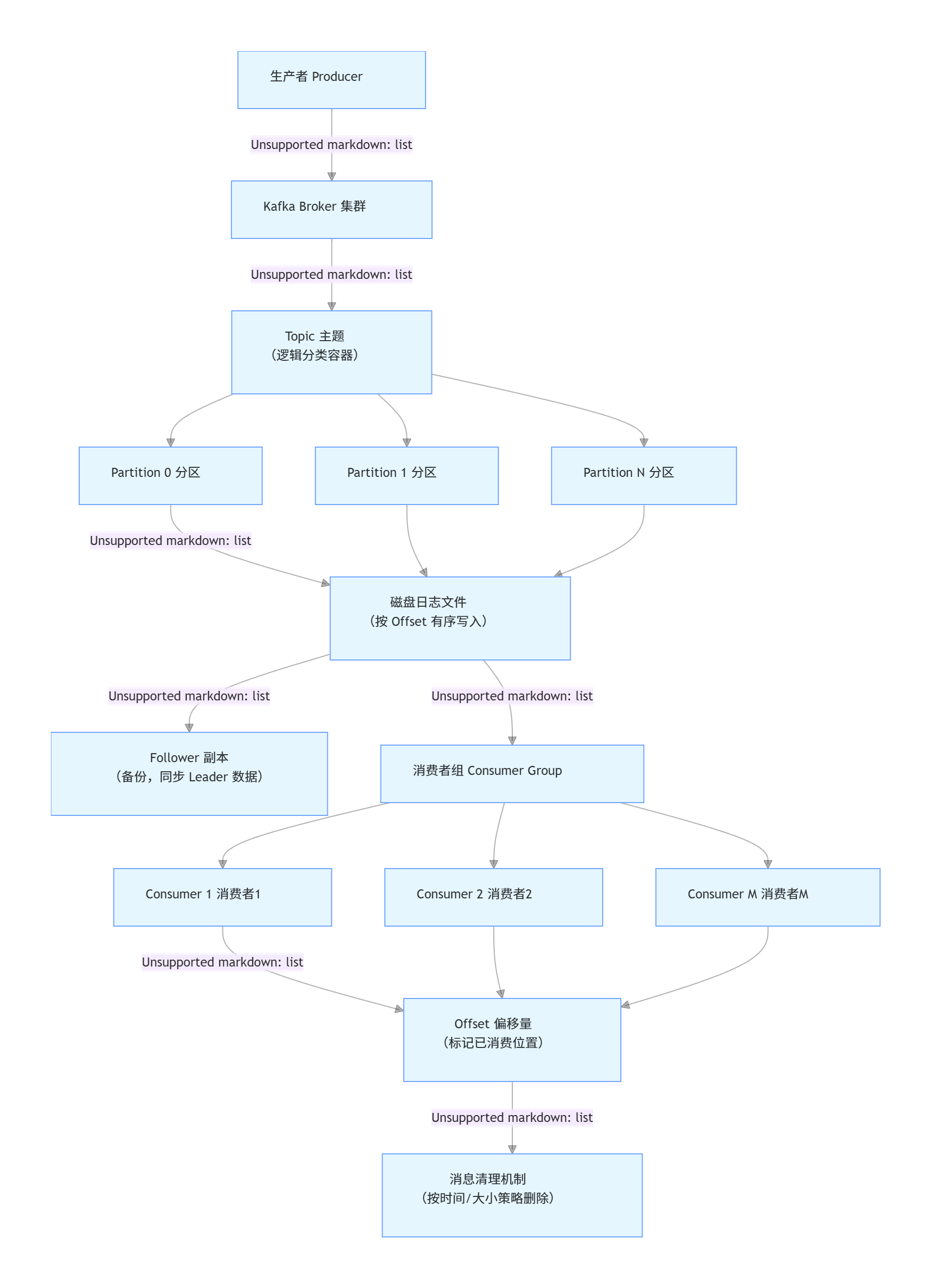
流程图关键步骤说明:
- 生产者发送:生产者将封装好的消息(含业务数据 Value、路由用 Key、附加 Headers)发送到 Broker 集群。
- 分区路由:Kafka 根据消息 Key 的哈希值,将消息分配到 Topic 下的指定分区(保证同 Key 消息入同一分区)。
- 持久化存储:消息按 Offset 顺序写入分区对应的磁盘日志文件,确保数据不丢失。
- 副本同步:Leader 分区(处理读写)的数据实时同步到 Follower 副本(备份节点),保证高可用。
- 消费者拉取:消费者组内的消费者主动从分配到的分区拉取消息(组内分区唯一分配,实现负载均衡)。
- 记录 Offset:每个消费者组独立维护 Offset,标记已消费的消息位置,支持断点续传和回溯消费。
- 消息清理:按配置的保留策略(如默认 7 天)自动删除过期消息,释放磁盘空间。
副本同步、容灾、高并发、负载均衡
broker : 有3台
producer: 有2个⽣产者
consumer: 有4个消费者
group : 有2个消费组
topic : 有2个主题
topic0 有2个分区
topic0 有3个副本
topic1 有1分区
leader 是红⾊
蓝线是⽣产者给leader发消息
绿线是leader给 flower同步消息
同⼀个分区的消息,同组⾥只能有⼀个消费者消费
同⼀个消息可以给不同的分组消费
1.生产者发送消息
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// 1. 配置生产者参数
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop101:9092"); // Broker 地址
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // Key 序列化器
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // Value 序列化器
// 2. 创建生产者实例
Producer producer = new KafkaProducer<>(props);
// 3. 发送消息
String topic = "mytopic002";
for (int i = 0; i < 5; i++) {
String key = "key" + i;
String value = "message" + i;
// 构建消息
ProducerRecord record = new ProducerRecord<>(topic, key, value);
// 同步发送(或使用 send(record, callback) 异步发送)
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.println("发送成功:" + metadata.topic() + "-" + metadata.partition() + "-" + metadata.offset());
} else {
exception.printStackTrace();
}
});
}
// 4. 关闭生产者
producer.close();
}
} 2.消费者接收消息
import org.apache.kafka.clients.consumer.*;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
// 1. 配置消费者参数
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop101:9092"); // Broker 地址
props.put("group.id", "g1"); // 消费者组 ID
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // Key 反序列化器
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // Value 反序列化器
props.put("auto.offset.reset", "earliest"); // 无偏移量时从头消费
// 2. 创建消费者实例
Consumer consumer = new KafkaConsumer<>(props);
// 3. 订阅主题
String topic = "mytopic002";
consumer.subscribe(Collections.singletonList(topic));
// 4. 拉取消息
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100)); // 拉取消息,超时时间 100ms
for (ConsumerRecord record : records) {
System.out.printf("接收消息:topic=%s, partition=%d, offset=%d, key=%s, value=%s%n",
record.topic(), record.partition(), record.offset(),
record.key(), record.value());
}
consumer.commitSync(); // 手动提交偏移量(或配置自动提交)
}
// 5. 关闭消费者(实际中需在退出时调用)
// consumer.close();
}
} 

 浙公网安备 33010602011771号
浙公网安备 33010602011771号