

实用指南:Spring Cloud 熔断降级实战:Sentinel 熔断策略与规则持久化
Spring Cloud 熔断降级实战:Sentinel 熔断策略与规则持久化
结合我们之前掌握的 Sentinel 基础(流量控制、Feign 降级),今天我们聚焦 “熔断降级” 这一核心能力 —— 它是微服务应对 “下游服务故障” 的关键手段,能避免故障像多米诺骨牌一样扩散。本文会从 “熔断与降级的区别” 讲起,详细拆解 Sentinel 的三种熔断策略(慢调用比例、异常比例、异常数),再解决生产环境的关键问题 “规则持久化”(避免重启后规则丢失),全程结合我们熟悉的 ServiceThree、ServiceTwo 案例,帮我们搞懂 “每一步配置的目的” 和 “背后的运行逻辑”。
1. 先理清:熔断和降级到底是什么?(避免混淆)
很多初学者会把 “熔断” 和 “降级” 混为一谈,其实它们是 “配合工作” 的两个概念,我们用通俗的例子先区分清楚:
| 概念 | 我们的通俗理解 | 核心作用 | 类比场景 |
|---|---|---|---|
| 熔断 | 像家里的 “保险丝”—— 当电流过大(服务故障),保险丝自动断开,避免电路烧毁 | 暂时 “切断” 对故障服务的调用,防止故障扩散 | 餐厅某道菜的食材用完了,服务员直接告诉顾客 “这道菜暂时没有”,不往后厨下单 |
| 降级 | 像餐厅食材不够时,用 “替代品”—— 比如没有牛排,提供汉堡,保证顾客有餐可吃 | 熔断后返回 “友好结果”,不抛出异常 | 服务员告诉顾客 “牛排没了,试试汉堡吧”,而不是让顾客空等或报错 |
我们的核心结论:熔断是 “触发条件”(什么时候停止调用),降级是 “熔断后的处理逻辑”(停止调用后返回什么);没有熔断,降级只是 “备用逻辑”,没有降级,熔断后会直接返回默认错误(如 Blocked by Sentinel),用户体验差。两者结合才能实现 “故障可控、用户体验友好”。
2. Sentinel 熔断规则核心:5 个关键配置项(必须理解)
在学习具体策略前,我们先搞懂 Sentinel 熔断规则的 “通用配置项”—— 无论哪种熔断策略,都需要配置这些基础参数,理解它们才能避免乱配置。
| 配置项 | 我们的通俗理解 | 取值范围 / 说明 | 为什么需要它? |
|---|---|---|---|
| 资源名(resource) | 要熔断的 “目标”—— 可以是接口路径(如/serviceThree_toTwo)或 Feign 调用资源(如GET:http://service-two/serviceTwo) | 必须与 Sentinel 簇点链路中的资源名完全一致 | 告诉 Sentinel 要 “监控哪个对象”,错一个字符都会导致规则不生效 |
| 熔断策略(grade) | 触发熔断的 “条件类型”—— 是 “响应太慢”“异常太多” 还是 “异常次数够了” | 0 = 慢调用比例;1 = 异常比例;2 = 异常数 | 定义 “什么情况算故障”,不同场景选不同策略 |
| 最小请求数(minRequestAmount) | 统计时间内 “至少要多少请求” 才判断是否熔断 —— 避免少量请求误触发 | 正整数(如 5、10) | 比如 1 个请求慢了,不能算故障;5 个请求里 3 个慢了,才判定为故障 |
| 统计时长(statIntervalMs) | 统计 “故障情况” 的时间窗口 —— 比如统计 1 分钟内的请求情况 | 毫秒(默认 60000=1 分钟) | 限定 “观察故障的时间范围”,避免跨长时间统计导致误判 |
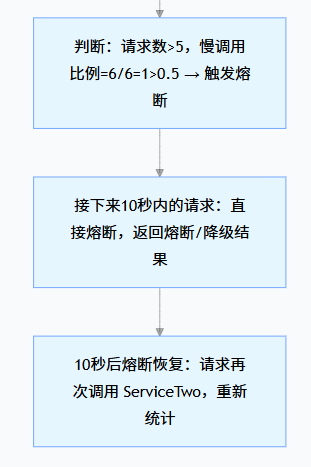
| 熔断时长(timeWindow) | 熔断后 “多久恢复”—— 比如熔断后 10 秒内不再调用,10 秒后尝试恢复 | 秒(如 5、10) | 给故障服务 “喘息时间”,避免频繁调用加重故障 |
我们的配置原则:这些参数不是 “随便填” 的,要结合业务场景 —— 比如秒杀场景,最小请求数可以设大(如 100),避免秒杀开始时少量慢请求误触发熔断;普通业务场景,最小请求数设 5-10 即可,避免漏判故障。
3. 实战:Sentinel 三种熔断策略(从场景到操作)
Sentinel 提供三种熔断策略,分别对应不同的 “故障场景”。我们结合 ServiceThree 调用 ServiceTwo 的场景,逐个实战,每一步都讲 “配置目的→代码修改→测试验证→运行逻辑”。
3.1 策略 1:慢调用比例(应对 “下游服务响应慢”)
适用场景:下游服务(如 ServiceTwo)因数据库慢、网络卡等原因,响应时间变长(比如正常 100ms,现在要 1 秒),此时触发熔断,避免 ServiceThree 的线程被长时间占用。
步骤 1:理解配置逻辑
我们要实现:1 分钟内(60000ms),如果调用 ServiceTwo 的请求超过 5 次(最小请求数),且其中 50% 以上的请求响应时间超过 200ms(慢调用 RT),则熔断 10 秒。
步骤 2:在 Sentinel 控制台配置熔断规则
进入 ServiceThree 的 “熔断规则” 页面(
http://localhost:8480/#/dashboard/service-three/degrade);点击 “新增”,配置规则:
资源名:选
GET:http://service-two/serviceTwo(Feign 调用 ServiceTwo 的资源名,Sentinel 自动生成);熔断策略:慢调用比例;
最大 RT:200(超过 200ms 的请求算 “慢调用”);
比例阈值:0.5(50% 的慢调用比例);
最小请求数:5(1 分钟内至少 5 次请求才判断);
统计时长:60000(1 分钟,默认值);
熔断时长:10(熔断后 10 秒恢复);
点击 “新增”,规则生效。
步骤 3:修改 ServiceTwo 模拟 “慢调用”
我们在 ServiceTwo 的 serviceTwo 方法中加 1 秒睡眠,模拟响应慢的场景:
@RestController
public class ServiceTwoController {
@RequestMapping("/serviceTwo")
public JSONObject serviceTwo() {
try {
// 模拟1秒响应时间(超过我们配置的200ms慢调用阈值)
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 正常返回结果
JSONObject ret = new JSONObject();
ret.put("code", 0);
ret.put("message", "Service two method return!");
return ret;
}
}步骤 4:测试熔断效果
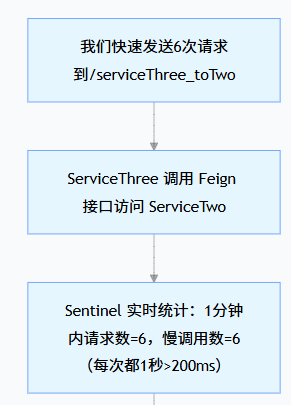
访问
http://localhost:8088/service-three/serviceThree_toTwo(通过 Gateway 调用,更贴近真实场景);快速刷新 5 次以上(1 分钟内完成):
前 5 次:每次都要等 1 秒才返回(慢调用);
第 6 次及之后:触发熔断,直接返回
Blocked by Sentinel (flow limiting)(如果我们之前配置了 Feign 降级,会返回降级结果,如ServiceTwo暂时不可用);
等待 10 秒后,再次访问:熔断恢复,又会等 1 秒返回结果。
背后的运行流程(我们要搞懂)
 |  |
|---|---|
关键逻辑:Sentinel 会在 “统计时长” 内累计 “请求数” 和 “慢调用数”,只有两个条件同时满足(请求数≥最小请求数、比例≥阈值),才会触发熔断 —— 这是为了避免 “少量慢请求” 误判为服务故障。
3.2 策略 2:异常比例(应对 “下游服务频繁抛异常”)
适用场景:下游服务(如 ServiceTwo)因代码 bug、数据库连接失败等原因,频繁抛出异常(比如每 2 次请求抛 1 次异常),此时触发熔断,避免 ServiceThree 反复调用故障服务。
步骤 1:理解配置逻辑
我们要实现:1 分钟内,若调用 ServiceTwo 的请求超过 5 次,且异常比例超过 10%(10 个请求里 1 个异常),则熔断 10 秒。
步骤 2:在 Sentinel 控制台配置熔断规则
进入 “熔断规则” 页面,点击 “新增”;
配置规则:
资源名:还是
GET:http://service-two/serviceTwo;熔断策略:异常比例;
比例阈值:0.1(10% 的异常比例);
最小请求数:5(1 分钟内至少 5 次请求);
统计时长:60000(1 分钟);
熔断时长:10(熔断后 10 秒恢复);
点击 “新增”。
步骤 3:修改 ServiceTwo 模拟 “频繁异常”
我们让 ServiceTwo 每 2 次请求抛 1 次异常,模拟故障场景:
@RestController
public class ServiceTwoController {
private static int count = 0; // 计数,控制异常抛出
@RequestMapping("/serviceTwo")
public JSONObject serviceTwo() {
count++;
// 每2次请求抛1次异常(异常比例50%,超过我们配置的10%)
if (count % 2 == 0) {
throw new RuntimeException("ServiceTwo数据库连接失败!");
}
// 正常返回结果
JSONObject ret = new JSONObject();
ret.put("code", 0);
ret.put("message", "Service two method return!");
return ret;
}
}步骤 4:测试熔断效果
访问http://localhost:8088/service-three/serviceThree_toTwo,快速刷新 6 次:
第 1、3、5 次:正常返回(无异常);
第 2、4、6 次:抛出异常(被 Sentinel 统计);
第 6 次后:异常比例 = 3/6=50%>10%,且请求数 = 6≥5 → 触发熔断;
熔断后访问:直接返回熔断 / 降级结果(如我们之前配置的
ServiceTwo暂时不可用);10 秒后恢复:再次访问会重新统计异常比例。
我们的关键发现
在熔断期间,我们查看 ServiceTwo 的控制台,会发现没有新的异常日志—— 这证明 Sentinel 在熔断后,直接拦截了请求,没有调用 ServiceTwo,避免了故障服务被反复打扰,给 ServiceTwo 留出了恢复时间。
3.3 策略 3:异常数(应对 “下游服务异常次数达标”)
适用场景:下游服务(如 ServiceTwo)虽然异常比例不高,但 “异常次数累计到一定数量”(比如 1 分钟内异常 10 次),此时触发熔断 —— 适合 “异常比例低但总次数多” 的场景(如每秒 100 次请求,1% 异常就是 1 次 / 秒,1 分钟 60 次,需要熔断)。
步骤 1:理解配置逻辑
我们要实现:1 分钟内,若调用 ServiceTwo 的异常次数超过 3 次,且请求数≥5,则熔断 10 秒。
步骤 2:配置规则与测试(流程类似前两种)
控制台配置:熔断策略选 “异常数”,阈值(count)设 3,最小请求数 5,熔断时长 10 秒;
修改 ServiceTwo:让每次请求都抛异常(简化测试);
测试:1 分钟内刷新 6 次,前 3 次异常后,第 4 次触发熔断(因异常数 = 3≥阈值,请求数 = 4≥5?不,要等请求数≥5—— 第 5 次异常时,异常数 = 5≥3,请求数 = 5≥5,触发熔断)。
我们的注意点:异常数策略的 “阈值” 是 “累计异常次数”,不是比例 —— 比如阈值设 3,只要 1 分钟内异常次数≥3 且请求数≥最小请求数,就会熔断,适合对 “异常次数敏感” 的场景。
4. 生产环境必做:Sentinel 规则持久化(避免重启丢失)
我们之前在 Sentinel 控制台配置的规则,默认是存放在微服务的内存中—— 如果 ServiceThree 重启,所有规则都会丢失,需要重新配置,这在生产环境是不可接受的。因此,我们必须解决 “规则持久化” 问题,我推荐用 Nacos 作为规则存储中心(我们之前用 Nacos 做服务注册,兼容性好)。
4.1 先懂:Sentinel 规则推送的三种模式
Sentinel 支持三种规则存储模式,我们重点学生产环境用的 “Push 模式”:
| 模式 | 我们的通俗理解 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 原始模式 | 规则存在微服务内存中,控制台直接改内存 | 简单,无依赖 | 重启丢失,不保证一致性 | 本地测试 |
| Pull 模式 | 微服务定期去规则中心(如文件、数据库)拉取规则 | 规则持久化,无额外依赖 | 实时性差(比如 10 秒拉一次,规则改了要等 10 秒生效) | 小型非实时场景 |
| Push 模式 | 规则中心(如 Nacos)主动推规则给微服务,微服务监听变化 | 实时性强、一致性好、规则持久化 | 需要依赖 Nacos/Zookeeper 等组件 | 生产环境首选 |
我们选 Push 模式的理由:我们已经用了 Nacos 做服务注册,不用额外引入新组件;而且 Nacos 支持 “配置变更实时推送”,规则改完后,ServiceThree 能立即生效,满足生产环境的实时性需求。
4.2 实战:用 Nacos 实现规则持久化(分流控和熔断)
我们以 ServiceThree 为例,实现 “流控规则” 和 “熔断规则” 的持久化,步骤分 “加依赖→改配置→Nacos 写规则”。
步骤 1:给 ServiceThree 加 Nacos 持久化依赖
在 ServiceThree 的 pom.xml 中引入 sentinel-datasource-nacos 依赖,让 Sentinel 能从 Nacos 读取规则:
com.alibaba.csp
sentinel-datasource-nacos
步骤 2:配置流控规则持久化(以 /serviceThree 接口为例)
我们要实现:/serviceThree 接口的 QPS 限流规则(QPS=2)存在 Nacos 中,ServiceThree 重启后自动加载。
2.1 修改 ServiceThree 的 application.yml
添加 Sentinel 数据源配置,指定从 Nacos 拉取流控规则:
spring: cloud: sentinel: transport: dashboard: localhost:8480 eager: true # 新增:Sentinel 规则持久化配置(从 Nacos 拉取) datasource: # 流控规则数据源(名称 flow 可自定义) flow: nacos: server-addr: ${spring.cloud.nacos.discovery.server-addr} # 复用 Nacos 地址(127.0.0.1:8848) dataId: sentinel-sample-flow-rules # Nacos 中配置的 Data ID(必须对应) groupId: DEFAULT_GROUP # Nacos 分组(默认即可) rule-type: flow # 规则类型:flow=流控,degrade=熔断 # Feign 配置不变 feign: sentinel: enabled: true
2.2 在 Nacos 控制台创建流控规则配置
访问 Nacos 控制台(
http://127.0.0.1:8848/nacos),进入 “配置管理→配置列表”;点击 “+” 新建配置:
Data ID:
sentinel-sample-flow-rules(必须和 yml 中的 dataId 一致);Group:
DEFAULT_GROUP(和 yml 中的 groupId 一致);配置格式:
JSON;配置内容(流控规则的 JSON,每个字段含义我们后面解释):
[ { "resource": "/serviceThree", // 要限流的资源名(接口路径) "limitApp": "default", // 来源应用(default=所有来源) "grade": 1, // 阈值类型:1=QPS,0=并发线程数 "count": 2, // 单机阈值:QPS=2 "strategy": 0, // 流控模式:0=直接限流(对当前资源) "controlBehavior": 0, // 流控效果:0=快速失败(直接返回限流) "clusterMode": false // 是否集群:false=单机模式 } ]
点击 “发布”,配置保存到 Nacos。
2.3 测试持久化效果
重启 ServiceThree(之前的内存规则已丢失);
访问http://localhost:8088/service-three/serviceThree,1 秒内刷新 3 次:
前 2 次正常返回,第 3 次触发限流(
Blocked by Sentinel);查看 Sentinel 控制台 “流控规则”:
/serviceThree的规则已自动加载(来自 Nacos);
结论:规则持久化生效,重启后不用重新配置。
步骤 3:配置熔断规则持久化(以 /serviceThree_toTwo 为例)
我们要实现:/serviceThree_toTwo 调用 ServiceTwo 的慢调用比例熔断规则(RT=200ms,比例 = 50%)存在 Nacos 中。
3.1 修改 ServiceThree 的 application.yml
在 sentinel.datasource 下新增熔断规则数据源:
spring: cloud: sentinel: datasource: # 之前的流控规则配置... flow: {...} # 新增:熔断规则数据源(名称 degrade 可自定义) degrade: nacos: server-addr: ${spring.cloud.nacos.discovery.server-addr} dataId: sentinel-sample-degrade-rules # Nacos 中的 Data ID groupId: DEFAULT_GROUP rule-type: degrade # 规则类型:degrade=熔断
3.2 在 Nacos 控制台创建熔断规则配置
新建配置:
Data ID:
sentinel-sample-degrade-rules(和 yml 一致);Group:
DEFAULT_GROUP;配置格式:
JSON;[ { "resource": "/serviceThree_toTwo", // 要熔断的资源名(接口路径) "limitApp": "default", // 来源应用 "grade": 0, // 熔断类型:0=慢调用比例 "count": 200, // 最大 RT:200ms "timeWindow": 10, // 熔断时长:10秒 "minRequestAmount": 2, // 最小请求数:2次 "slowRatioThreshold": 0.5 // 慢调用比例阈值:50% } ]配置内容(熔断规则 JSON):
点击 “发布”。
3.3 测试熔断规则持久化
重启 ServiceThree;
修改 ServiceTwo 的
serviceTwo方法,加 300ms 睡眠(超过 200ms 慢调用阈值);访问http://localhost:8088/service-three/serviceThree_toTwo,快速刷新 2 次:
2 次请求都是慢调用(300ms),满足 “请求数≥2、比例 = 100%≥50%” → 触发熔断;
查看 Sentinel 控制台 “熔断规则”:规则已自动加载;
结论:熔断规则也实现了持久化,重启后生效。
关键:规则 JSON 字段含义(我们必须记)
无论是流控还是熔断,Nacos 中的 JSON 字段都要精准配置,我们整理了常用字段:
| 规则类型 | 字段名 | 含义 | 取值说明 |
|---|---|---|---|
| 通用 | resource | 资源名(要控制的目标) | 接口路径(如/serviceThree)或 Feign 资源名(如GET:http://service-two/serviceTwo) |
| 通用 | limitApp | 来源应用 | default = 所有来源,指定服务名 = 仅该服务来源 |
| 流控 | grade | 阈值类型 | 0 = 并发线程数,1=QPS |
| 流控 | count | 单机阈值 | 如 QPS=2 填 2,并发线程数 = 3 填 3 |
| 熔断 | grade | 熔断类型 | 0 = 慢调用比例,1 = 异常比例,2 = 异常数 |
| 熔断 | count | 阈值 | 慢调用比例填 “最大 RT”(如 200),异常比例填 “比例阈值”(如 0.5),异常数填 “异常次数”(如 3) |
| 熔断 | timeWindow | 熔断时长(秒) | 如 10 = 熔断 10 秒 |
| 熔断 | minRequestAmount | 最小请求数 | 如 2 = 至少 2 次请求才判断 |
5. 我们的重点 & 易错点总结(避坑指南)
熔断降级和规则持久化是生产环境必须掌握的能力,我们整理了最容易踩的坑和关键注意事项:
5.1 熔断策略配置易错点
| 易错点描述 | 我们的解决方案 |
|---|---|
| 资源名配置错误,规则不生效 | 资源名必须和 Sentinel 簇点链路中的 “资源名” 完全一致(区分大小写,如/serviceThree_toTwo不能少斜杠);Feign 调用的资源名是GET:http://service-two/serviceTwo,不是接口路径 |
| 最小请求数设太小,误触发熔断 | 最小请求数建议设为 “正常 1 分钟请求数的 1/10”,比如 1 分钟正常 100 次请求,最小请求数设 10,避免少量请求误触发 |
| 熔断时长设太短,故障服务反复被调用 | 熔断时长建议设 5-30 秒,给故障服务足够的恢复时间;如果服务恢复慢,可设 60 秒 |
5.2 规则持久化易错点
| 易错点描述 | 我们的解决方案 |
|---|---|
| Nacos 配置的 Data ID 和 yml 不一致 | 严格保证 sentinel.datasource.flow.nacos.dataId 和 Nacos 中的 Data ID 完全一致(包括大小写) |
| 规则 JSON 格式错误,加载失败 | 用 JSON 校验工具(如 https://json.cn/)检查格式;数组格式不能错(外层用[],内部是对象) |
| 规则类型(rule-type)配置错 | 流控规则填flow,熔断规则填degrade,填反会导致规则不生效 |
| 重启后规则没加载,控制台看不到 | 1. 检查 Nacos 配置是否发布;2. 查看 ServiceThree 控制台日志,是否有 “load rules from Nacos” 成功日志;3. 确认依赖 sentinel-datasource-nacos 已引入 |
6. 关联我们的架构:完整的微服务稳定性防护体系
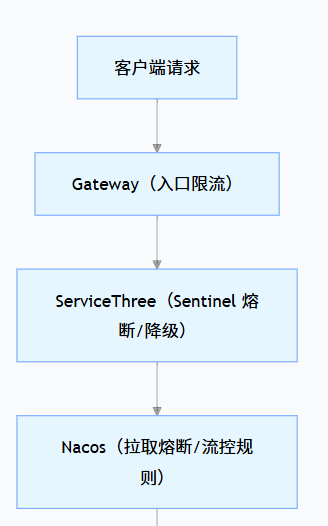
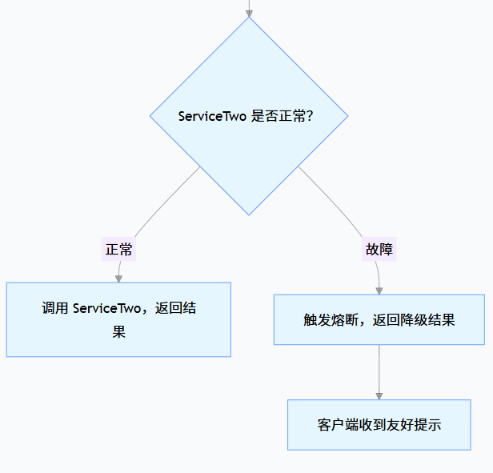
学完熔断降级和规则持久化后,我们的微服务架构终于具备了 “生产级的稳定性防护能力”,完整链路如下:
Gateway 网关层:拦截外部请求,做入口限流(后续可学),过滤无效请求;
ServiceThree 熔断降级:调用 ServiceTwo 时,用 Sentinel 熔断故障服务,返回降级结果;
规则持久化:用 Nacos 存储规则,避免重启丢失,保证配置一致性;
Nacos 服务发现:配合 Sentinel 过滤不健康实例,优先调用正常服务。
我们的防护链路图:
 |  |
|---|---|
7. 总结
熔断降级的核心不是 “杜绝故障”,而是 “让故障可控”—— 通过 Sentinel 的三种熔断策略,我们能精准识别 “服务慢”“服务异常” 等故障场景,及时切断故障链路;通过 Nacos 持久化规则,我们解决了 “重启丢失配置” 的生产痛点。
作为初学者,我们不用一开始就掌握所有策略,先重点掌握 “慢调用比例” 和 “异常比例”(最常用),再逐步理解规则持久化的配置逻辑。记住:每一个配置项都要 “知其然,知其所以然”,比如最小请求数设 5 是为了避免误判,熔断时长设 10 秒是为了给服务恢复时间,这样在实际项目中才能灵活调整。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号