
Huffman编码
Huffman编码
哈夫曼编码(Huffman Coding),是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码 。
-
预备知识
-
哈夫曼树的存储结构
typedef struct
{
unsigned int weight;
unsigned int parent, lchild, rchild;
}HTNode,*HuffmanTree; //动态分配数组存储哈夫曼树
-
哈夫曼编码的存储结构
typedef char * *HuffmanCode;
//动态分配数组存储哈夫曼编码表
-
-
实验题目
从键盘接收任意一个字符串。以字符串中某字符出现的次数,作为该字符的权值。利用得到的权值构造huffman树、并输出每个字符对应的huffman编码。
代码运行的预编译命令
#include <stdio.h>
#include <malloc.h>
#include <string.h>
所用的函数的声明以及结构体定义
#include "CommonDef.h"
typedef struct{
int weight;
int parent,lchild,rchild;
}HTNode,*HuffmanTree;
typedef struct{
char ch;
int weight;
}ww,*W;
typedef char **HuffmanCode;
void select(HuffmanTree *HT,int n,int *s1,int *s2);
void HuffmanCoding(HuffmanTree *HT,W *w,int n);
void Huffman(HuffmanTree HT,HuffmanCode *HC,W *w,int n);
具体的函数实现
Huffman树的构建
void HuffmanCoding(HuffmanTree *HT,W *w,int n){
HuffmanTree p;
int s1,s2,m,i;
if(n<=1) return;
m=2*n-1;
*HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode));
for(p=*HT+1,i=1;i<=n;i++,p++){
p->weight=w[i-1]->weight;
p->lchild=0;
p->parent=0;
p->rchild=0;
}
for(;i<=m;i++,p++){
p->weight=0;
p->lchild=0;
p->parent=0;
p->rchild=0;
}
for(i=n+1;i<=m;i++){
select(HT,i-1,&s1,&s2);
(*HT)[s1].parent=i;
(*HT)[s2].parent=i;
(*HT)[i].lchild=s1;(*HT)[i].rchild=s2;
(*HT)[i].weight=(*HT)[s1].weight+(*HT)[s2].weight;
}
for(p=*HT+1,i=1;i<=m;i++){
printf("%d %d %d %d\n",p->weight,p->parent,p->lchild,p->rchild);
p++;
}
}
构建Huffman树中找查最小值与次小值的实现
void select(HuffmanTree *HT,int n,int *s1,int *s2){
int i=1,min,cmin;
HuffmanTree p;
p=*HT+1;
while(p->parent!=0){
p++;
i++;}
min=p->weight;*s1=i;//最小
p++;i++;
while(p->parent!=0){
p++;
i++;}
cmin=p->weight;*s2=i;//次小
for(i=1,p=*HT+1;i<=n;i++,p++){
if(p->parent==0){
if(p->weight<min){
cmin=min;
min=p->weight;
*s2=*s1;
*s1=i;
}
else if(p->weight<cmin&&(*s1!=i)){
cmin=p->weight;
*s2=i;
}
}
}
}
通过Huffman树实现Huffman编码
void Huffman(HuffmanTree HT,HuffmanCode *HC,W *w,int n){
char *cd;
int i,start,c,f;
*HC=(HuffmanCode)malloc((n+1)*sizeof(char *));
cd=(char *)malloc(n*sizeof(char));
cd[n-1]='\0';
for(i=1;i<=n;i++){
start=n-1;
for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent){
if(HT[f].lchild==c) cd[--start]='0';
else cd[--start]='1';
}
(*HC)[i]=(char *)malloc((n-start)*sizeof(char));
strcpy((*HC)[i],&cd[start]);
}
free(cd);
}
测试代码
int main(){
W w[26];
int n,n1,i,j;
int zifu[26]={0};
char *s;
FILE *fp1,*fp2;
HuffmanTree HT;
HuffmanCode HC;
s=(char *)malloc(100*sizeof(char));
fp1=fopen("input.txt","r");
fp2=fopen("output.txt","w");
if(!fp1)
{
printf("can't open file\n");
return -1;
}
fscanf (fp1,"%s",s);
n=strlen(s);
for(i=0;i<26;i++){
w[i]=(W)malloc(sizeof(ww));//结构体数组分配空间
}
for(i=0;i<n;i++){
zifu[s[i]-'a']++;
}
for(i=0,j=0;i<26;i++){
if(zifu[i]!=0){
w[j]->ch=i+'a';
w[j]->weight=zifu[i];//给每个数组赋值
j++;
}
}
n1=j;
for(i=0;i<n1;i++){
printf("%c的权值%d\n",w[i]->ch,w[i]->weight);
fprintf(fp2,"%c的权值%d\n",w[i]->ch,w[i]->weight);
}
HuffmanCoding(&HT,w,n1);
Huffman(HT,&HC,w,n1);
for(i=1;i<=n1;i++){
printf("%c的编码:%s\n",w[i-1]->ch,(HC)[i]);
fprintf(fp2,"%c的编码:%s\n",w[i-1]->ch,(HC)[i]);
}
return 0;
}
一些注意事项
-
测试代码中的数据是从文件读入,然后再写入文件中。读入的文件全为字母,我的测试数据中全用的小写字母。
-
代码首先对读入字母进行统计出现的个数,然后再实现编码。
-
本来只把算出来的编码写入文件中,但是为了更好观看,也打印在屏幕中了。
-
本来代码中无法对应每个字母,如图
![]()

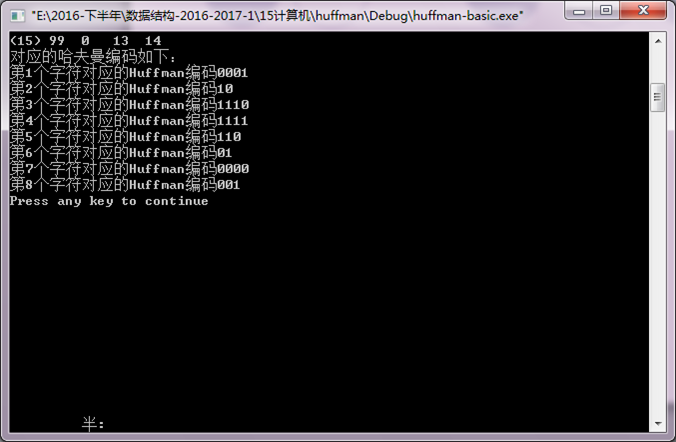
为了更好看出每个字母对应的编码,采用了结构体来存储每个字母的权值,这样既可以存储权值,也可以把字母存储进去。
测试数据
-
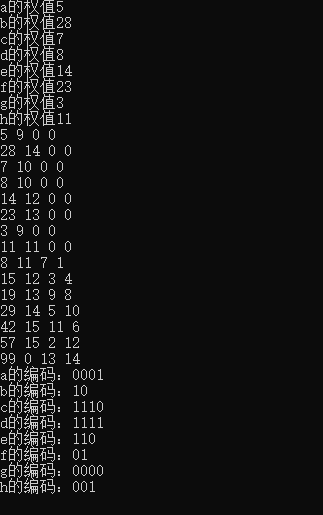
input文件的数据: aaaaabbbbbbbbbbbbbbbbbbbbbbbbbbbbcccccccddddddddeeeeeeeeeeeeeefffffffffffffffffffffffggghhhhhhhhhhh
-
所得到的Huffman编码
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号