

爬虫作业
爬网站(学号36):
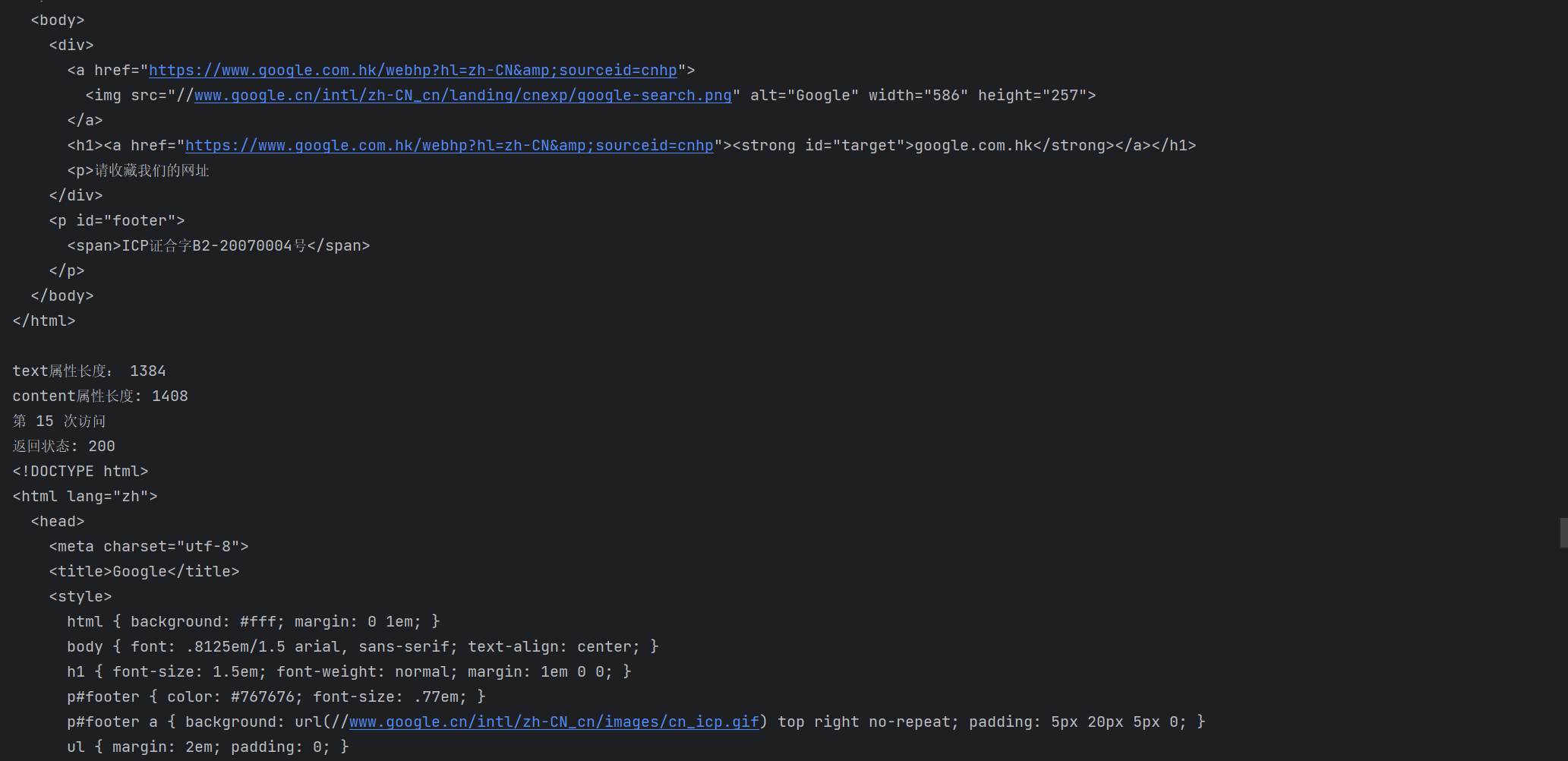
1 import requests 2 for i in range (20): 3 print("第",i+1,"次访问") 4 r=requests.get("https://www.google.cn/") 5 r.encoding='utf-8' 6 print("返回状态:",r.status_code) 7 print(r.text) 8 print("text属性长度:",len(r.text)) 9 print("content属性长度:",len(r.content))
我也想打印,但奈何本人太菜,只能截个图了
爬中国大学排行(2017):
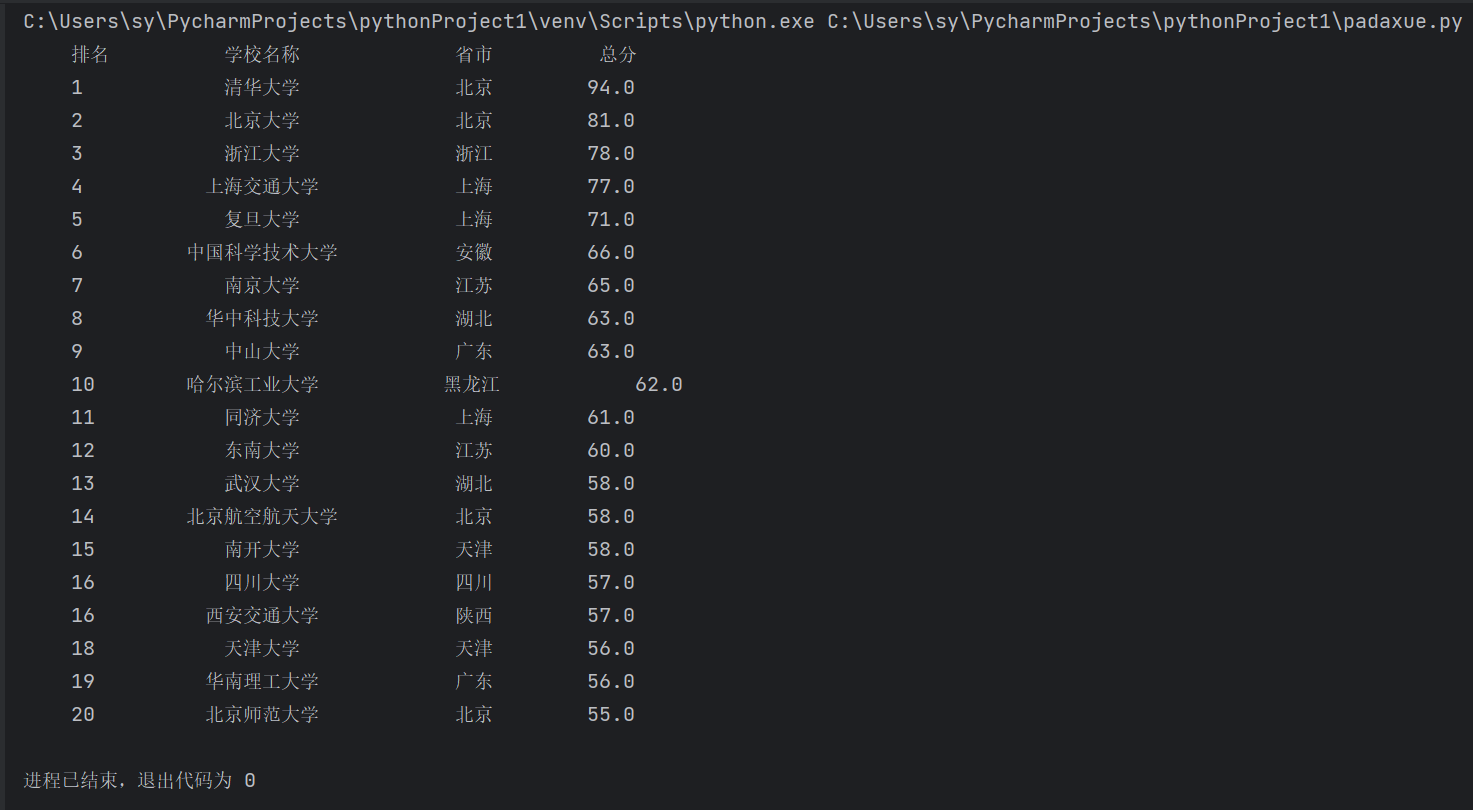
1 import requests 2 from bs4 import BeautifulSoup 3 import csv 4 all_univ = [] 5 def get_html_text(url): 6 try: 7 r = requests.get(url, timeout=30) 8 r.raise_for_status() 9 r.encoding = 'utf-8' 10 return r.text 11 except: 12 return "" 13 def fill_univ_list(soup): 14 data = soup.find_all('tr') 15 for tr in data: 16 ltd = tr.find_all('td') 17 if len(ltd) < 5: 18 continue 19 single_univ = [ltd[0].string.strip(), ltd[1].find('a', 'name-cn').string.strip(), ltd[2].text.strip(), 20 ltd[4].string.strip()] 21 all_univ.append(single_univ) 22 def print_univ_list(num): 23 file_name = "大学排行.csv" 24 print("{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}".format("排名", "学校名称", "省市", "总分", chr(12288))) 25 with open(file_name, 'w', newline='', encoding='utf-8') as f: 26 writer = csv.writer(f) 27 writer.writerow(["排名", "学校名称", "省市", "总分"]) 28 for i in range(num): 29 u = all_univ[i] 30 writer.writerow(u) 31 print("{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}".format(u[0], u[1], u[2], u[3], chr(12288))) 32 def main(num): 33 url = "https://www.shanghairanking.cn/rankings/bcur/201711.html" 34 html = get_html_text(url) 35 soup = BeautifulSoup(html, features="html.parser") 36 fill_univ_list(soup) 37 print_univ_list(num) 38 main(20)
运行截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号