

字符编码 and cpp
预备知识
- 字符:抽象的最小文本单位。仅代表符合没有实际意义(如:¥, a, 国)
- 字符集:字符的集合(如gb2312, ASCII, UNICODE)
- 编码:是对字符集的描述,计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。 如:utf-7,utf-16,ASCII编码,gb2312编码
对所有的文本、字符, 计算机都是以0011010101这样的方式存储和传输的。而在我们使用的时候, 就需要通过其编码翻译为我们能识别的文本或字符。 每一种编码都有一个码表以便于从0011010101到字符的转变如:
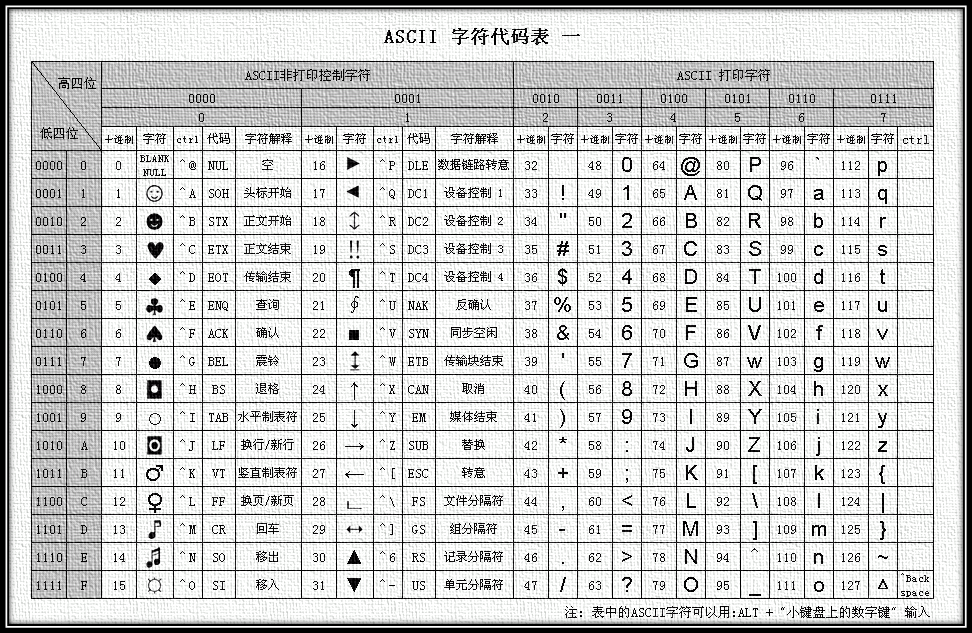
乱码:所以 如果我以ascii编码存的0011010101以gb2312方式去解码的时候,在gb2312表中找不到对应的关系,则出现了乱码。
Unicode
正如上所说, unicode是一种字符集。
unicode用4个字节来表示一个字符, 所以理论上可以表示2的32次 个字符。
UTF-32/ UTF-16/ UTF-8是unicode的三种编码方案。为啥这么多, 因为4个字节太浪费效率了。
UTF-32 太大, UTF-16 有大端小端的问题, 所以utf-8变为了最常用的网络传输编码。
utf-8
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码
- 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码。
- 其他极少使用的Unicode辅助平面的字符使用四字节编码。
char 和 wchar_t
窄字符char,8bit表示的byte,char字符只能表示ASII码表中的256个字符。
宽字符wchar_t则是因为char所能表示的字符数太少(256个)而应运而生的,它的长度可以8bit,16bit,32bit,长度是与不同平台上的c库相关的。其实这个长度是根据指定平台上想要用的encoding编码方式来设定的。
wchar_t就是存储的字符的unicode码值的编码值,如windows平台下则是用utf-16编码的。
c/c++标准只是声明wchar_t是一个可以表示字符集中的任意一个字符的足够宽的变量类型。wchar_t可以用任何encoding编码方式来存储这个字符,如ANSI, or UCS-2, or UCS- 4, 甚至是SCU-128,只不过我们通常是用unicode编码方式。wchar_t是与实现相关

 浙公网安备 33010602011771号
浙公网安备 33010602011771号