Hadoop的MapReduce进程卡住job/云服务器被矿工挖矿
本人用百度的云服务器搭建集群学习Hadoop,突然发现Java进程占用了99%以上的CPU,自己MapReduce没法运行,卡在job那里,但是通过kill所有Java进程,重启Hadoop集群即可运行一两次MapReduce。我一度以为是配置出了问题。困扰了我许久,冥冥之中肯定有问题在制约着。经过找大师帮忙查看,发现了问题所在。现象及解决方法记录如下,可能不能永久的解决问题。仅为个人记录。
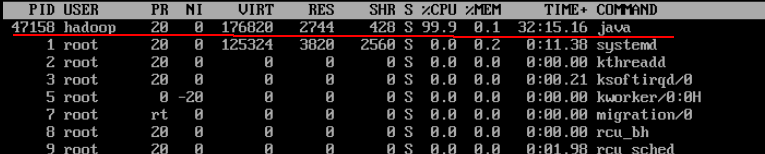
通过top命令查看DataNode上的进程,以前我只是简单的将其kill掉这个Java,却经常出现。
在master上运行任务,卡住不动或报错,我没有主动关闭过应用却出现了这种报错。

查看日志发现,有一个可疑的dr.who用户。

于是去DataNode上继续查看,最后的hadoop为我的用户名
ps -aux | grep hadoop
查找到pid对应的进程路径,发现是在/var/tmp/java,于是把这个java程序删除,但是过了没多久又自动起来了,敌人十分狡猾。
再查找定时任务,发现有一个带ip地址的定时任务,后来去网上一搜是荷兰的IP,
crontab -l
再通过命令关闭定时任务
crontab -r
现在清净了许多,查看博客发现还要注意ddg进程
用ps -aux | grep ddg找到了ddg进程,但是这个pid在不停的变化,根本kill不掉。先放下不管了,暂时不挖矿不影响自己的程序运行还好。
删除/var/spool/cron里面的可疑文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号