Python-爬虫网站入门
Python-爬虫网站入门
1、安装相关依赖
pip install requests #发送请求
pip install bs4 #获取网页HTML信息
pip install lxml #解析调整HTML格式
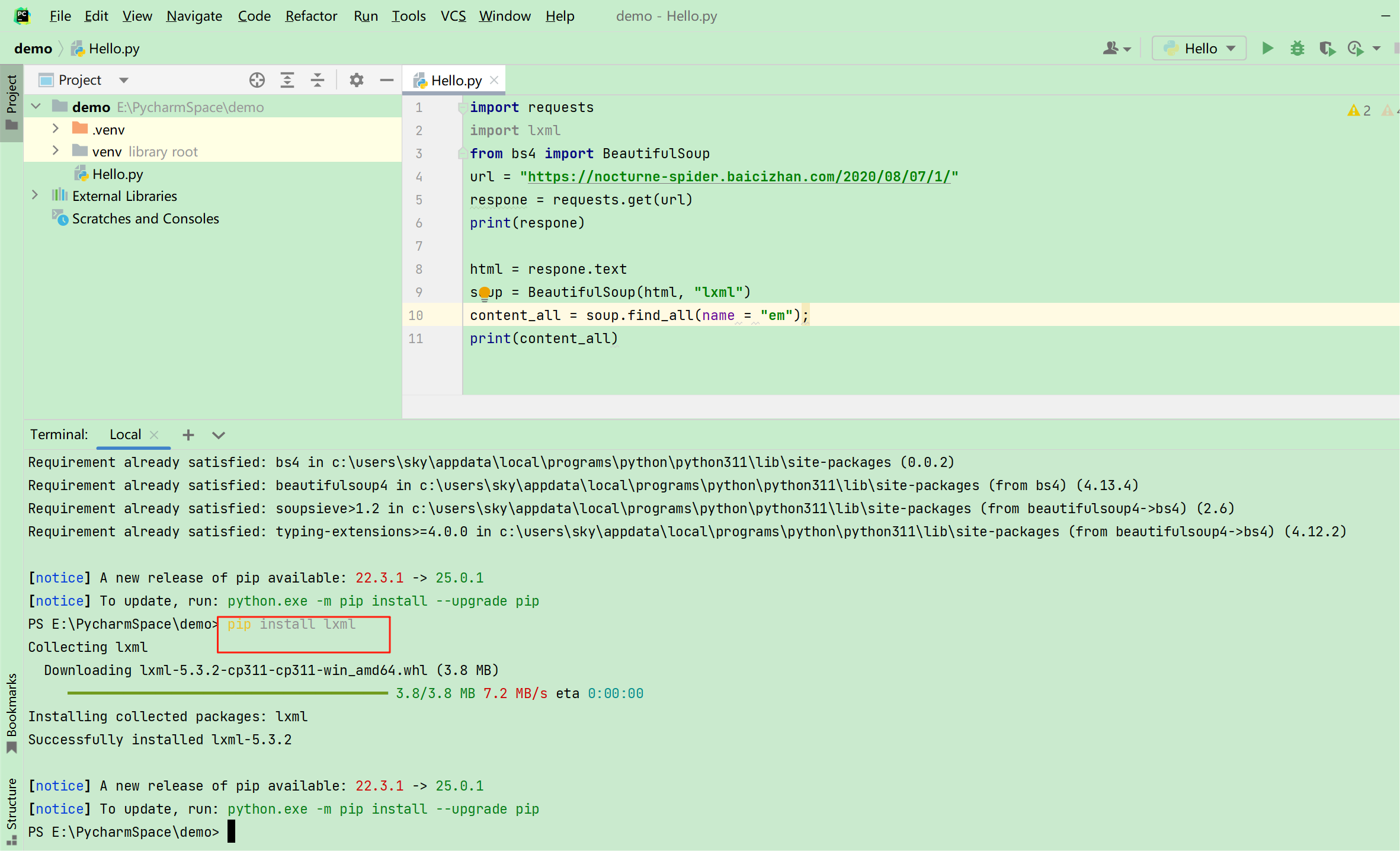
2、以下代码可以获取爬取的网站中的所有em标签属性
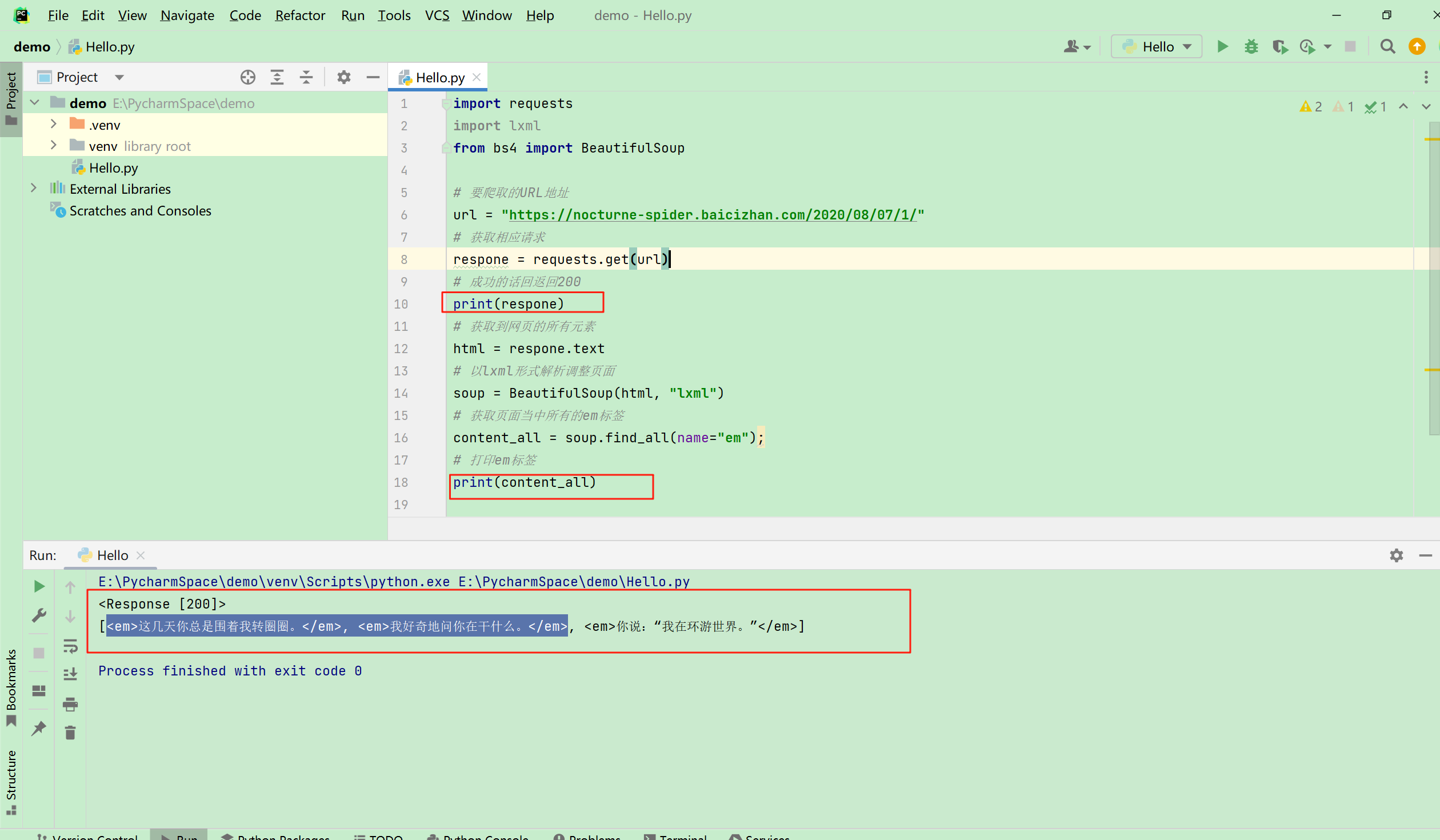
import requests
import lxml
from bs4 import BeautifulSoup
要爬取的URL地址
url = "https://nocturne-spider.baicizhan.com/2020/08/07/1/"
# 获取相应请求
respone = requests.get(url)
# 成功的话回返回200
print(respone)
# 获取到网页的所有元素
html = respone.text
# 以lxml形式解析调整页面
soup = BeautifulSoup(html, "lxml")
# 获取页面当中所有的em标签
content_all = soup.find_all(name="em");
# 打印em标签
print(content_all)
3、爬取页面:
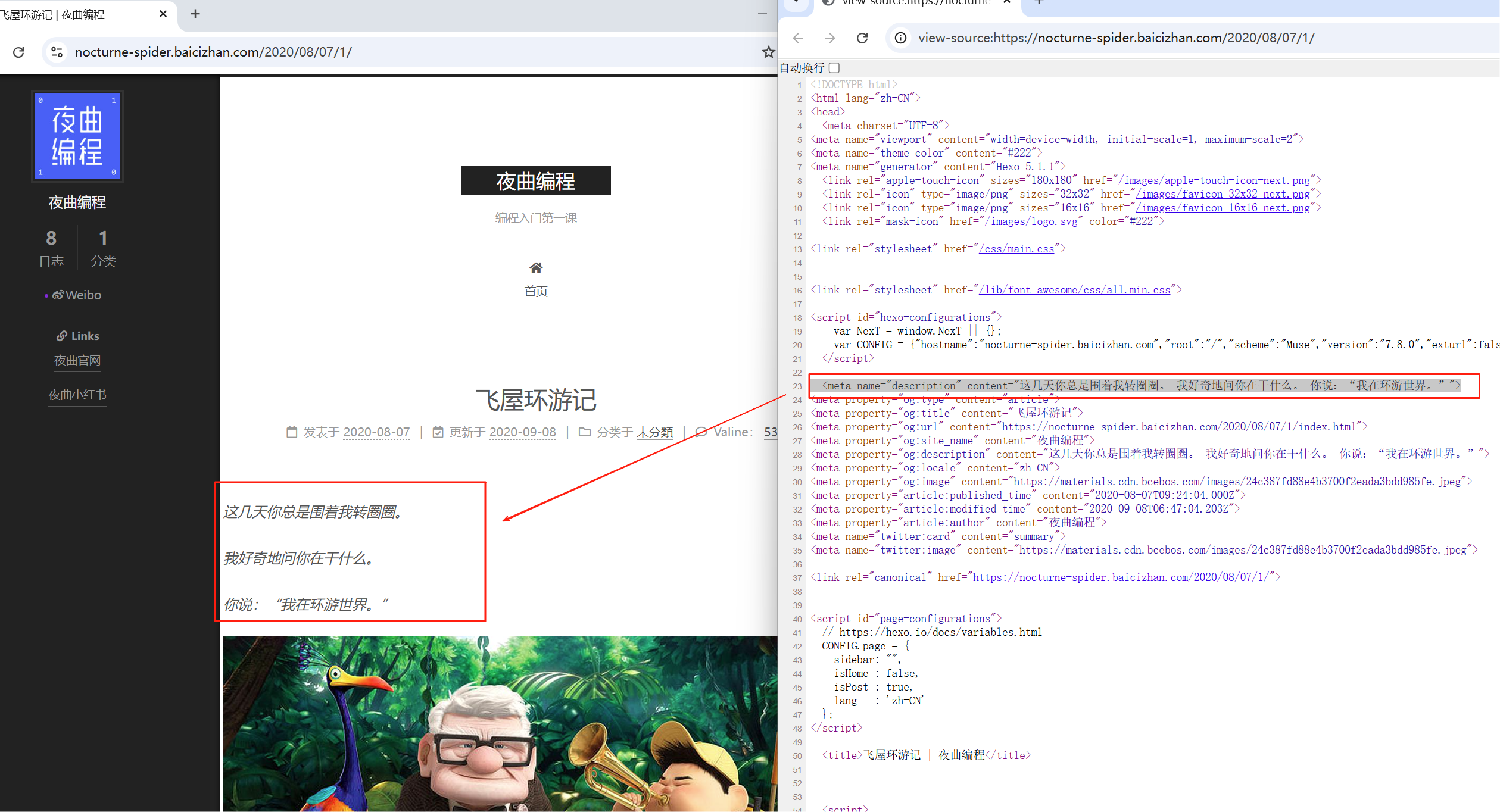
4、爬取内容:
本文来自博客园,作者:skystrivegao,转载请注明原文链接:https://www.cnblogs.com/skystrive/p/18832026
整理不易,如果对您有所帮助 请点赞收藏,谢谢~
 浙公网安备 33010602011771号
浙公网安备 33010602011771号