Spark基础入门(01)—RDD
1,基本概念
RDD(Resilient Distributed Dataset) :弹性分布式数据集
它是Spark中最基本的数据抽象,是编写Spark程序的基础。简单的来讲,一个Spark程序可以概括为:
<输入> => [转换] => <输出>
输入和输出是必须要有的,转换是大部分情况下都有的,将这个过程细化一下,放到Spark中,大概是这样:
(1)输入
一个或多个数据源作为输入,数据源可以是:本地文件,hdfs,数据库,程序中构造的数据集等等,在Spark中,会被抽象为不同的RDD
(2)转换
对输入的RDDs进行一些逻辑处理,由RDDs转换为新的RDDs,实现这个过程可以通过调用RDD的Transformation方法
(3)输出
将最终生成的结果RDD输出,例如:输出到数据库,写入到文件,在程序中转换为集合,数组等等,实现这个过程也是通过调用RDD的Action方法
当然,一个Spark程序中,输入、转换、输出都可能是多个,Transformation,Action算子有哪些这里就不列举了,随便一搜一大堆,这里只说一下两者的区别:Transformation算子只有在碰到Action算子时,才会真正执行,有点像JavaBean的Builder
2,特性
作为一个可以处理大数据量的分布式计算引擎,在兼顾执行性能和开发者体验的同时,这几个问题是很难避开的:
(1)支持多种数据源
RDD提供了不同的实现,可以从不同的存储中读取数据,也可以自定义RDD来实现数据读取
(2)数据吞吐量
RDD通过Partition来控制并发,每个分区会由Spark启动一个Task来进行计算,开发者只需要开发具体的开发逻辑,无须关注调度细节
Spark规定,RDD数据只读,不可更改,更改数据只能生成一个新的RDD,提高调度性能
所有的Transformation操作,数据都是在内存中,并不会落盘,只有在shuffle时会落盘,整个流程形成了一个数据处理的管道,举个例子:
//假如有3个rdd,对输入rdd产生的数据进行了处理
Iterator<Row> transform(Iterator<Row> iterator){
Iterator<Row> ite = f1(iterator)//rdd1
ite = f2(ite)//rdd2
return f3(ite)//rdd3
}
即使调用了transform方法,也不会触发计算(排除f1, f2, f3生成的数据直接放内存中,例如:list.iterator()),只有在最终输出时才会进行计算:
Iterator<Row> iterator = transform(inputIterator);
while(iterator.hasNext){
iterator.next();
//...
}
//此时会依次触发f3、f2、f1转换逻辑
因此整个过程是在内存中进行的,因此计算速度会很快,并且开发者只需要关注自己的转换逻辑即可
(3)任务容错
在大数据计算过程中,因为执行时间长,数据量大,因此容易出现执行失败的情况,Spark可以对失败的任务进行重试
(4)开发工具
支持缓存rdd,方便多次使用rdd时,无须进行重复计算
提供必要的抽象,让开发者专注于业务逻辑,易于上手(熟悉原理使用效果更佳~)
3,基础方法
3.1 基础方法
那么一个RDD最基本的信息是什么?
我们通过实现一个最最基础的自定义RDD,必须实现的方法有2个:
class TestRDD(sc : SparkContext) extends RDD[Row](sc, Nil){
override def compute(split: Partition, context: TaskContext): Iterator[Row] = {
Iterator()
}
override protected def getPartitions: Array[Partition] = {
Array()
}
}
因此,最基础的方法毫无疑问也是这两个:
getPartitions:获取所有的分区信息
compute:计算每个分区的结果,返回迭代器
没错,虽然spark相当复杂,但是最基础的东西,往往都非常简单、朴素,将这两个方法带入:
【<输入> => [转换] => <输出>】,这个流程中,仔细想想,这两个方法是不是就可以完成很多工作?
RDD提供的几个基础方法:
final def getNumPartitions //获取分区总数(基于getPartitions实现)
final def iterator(split: Partition, context: TaskContext): Iterator[T] //获取某个分区计算结果(基于compute实现)
def map[U: ClassTag](f: T => U): RDD[U] //将当前rdd转换成新的rdd(基于iterator实现)
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] // 将当前rdd转换成新的rdd,(基于iterator实现)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] //重新分区(基于getPartitions、compute实现)
当然,还有很多很多实现,可以看org.apache.spark.rdd.RDD源码,里面有详细介绍
3.2 进阶方法
大部分框架都是这样,先用一些实用,并且使用简单的方法让人可以快速上手,但是这些基础功能只是冰山一角,RDD也是这样,也有一些高阶功能:
protected def getDependencies: Seq[Dependency[_]] = deps //获取rdd的依赖关系,也可以在继承RDD时初始化
protected def getPreferredLocations(split: Partition): Seq[String] = Nil //返回分区最佳的计算主机地址,主要用来分配任务,保证任务尽量在本机计算,减少网络传输
val partitioner: Option[Partitioner] = None //自定义分区,可以为每个key分配对应的分区
这些方法也有很多地方可以使用,这里暂不展开,有个印象即可
4,依赖
首先,我们需要再明确一下,一个Spark程序,有如下的执行流程:
<输入> => [转换] => <输出>
流程中每一个节点,都是1~N个RDD构成,那么RDD之间,就需要有依赖关系,才能保证Spark能正确的按照流程进行执行
根据2.2的介绍,可以知道,RDD的依赖,通过getDependencies定义,那么我们使用伪代码,则有2种情况:
R1 => R2 => R3
R2的实现为:
def getDependencies = Seq(R1)
(R0, R1) => R2 => R3
R2的实现为:
def getDependencies = Seq(R1, R2)
这个是RDD级别的依赖关系,但是请注意,RDD是有分区的,所以这个依赖关系还需要细化
4.1 依赖关系定义
细化依赖关系之前,还需要说明一下在Spark中,依赖的定义:
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
它有2个实现:

ShuffleDependency:被称为宽依赖,这种也是最复杂的,需要进行shuffle操作
NarrowDependency:被称为窄依赖,它有3个实现:
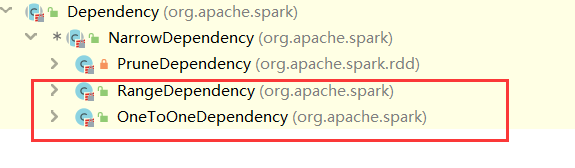
OneToOneDependency:很容易理解,用来处理1:1这种依赖关系
RangeDependency,PruneDependency(Spark内部使用):处理N:N这种依赖关系
4.2 分区依赖关系
为了简化流程,我们这里使用:R1=>R2,这种单一依赖来进行说明,多依赖情况是类似的,Spark中,将分区依赖分为以下4种情况:
(1)1:1
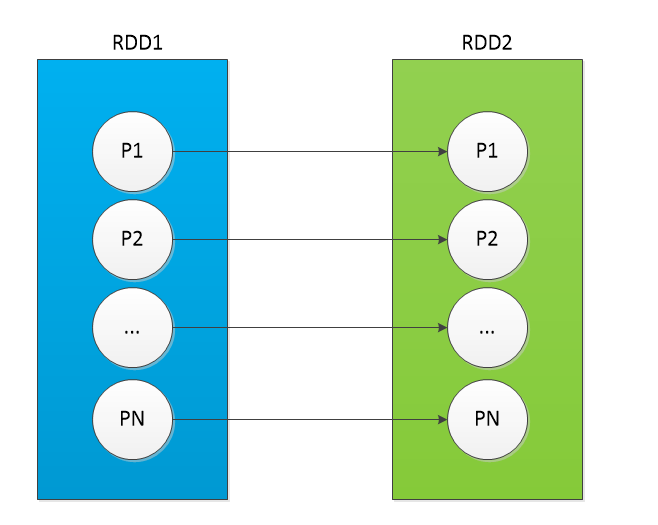
每个子分区,都来源于同一个父分区(通过:OneToOneDependency实现)
(2)N:1
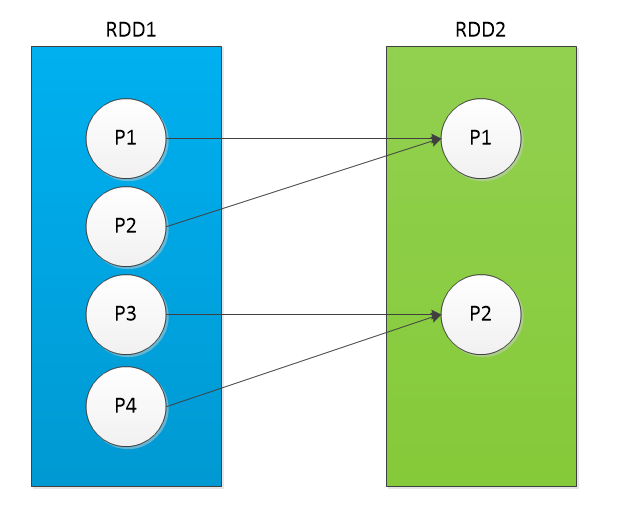
1个子分区,由多个父分区组成,可以通过:RangeDependency实现
(3)N:N
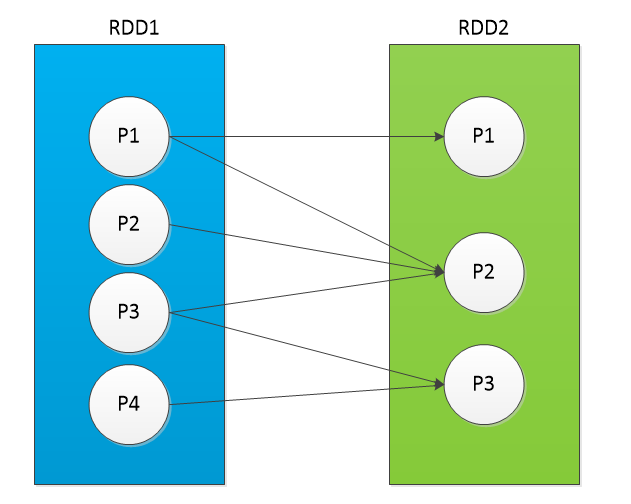
1个子分区,由多个父分区组成,同时1个父分区(所有数据)也为多个子分区提供数据,可以通过:RangeDependency实现
注意:N:1其实也是N:N的一种,N:N想象空间就很大了,一般是使用:RangeDependency来实现,Spark的UnionRDD就是N:1
(4)N:N (shuffle)
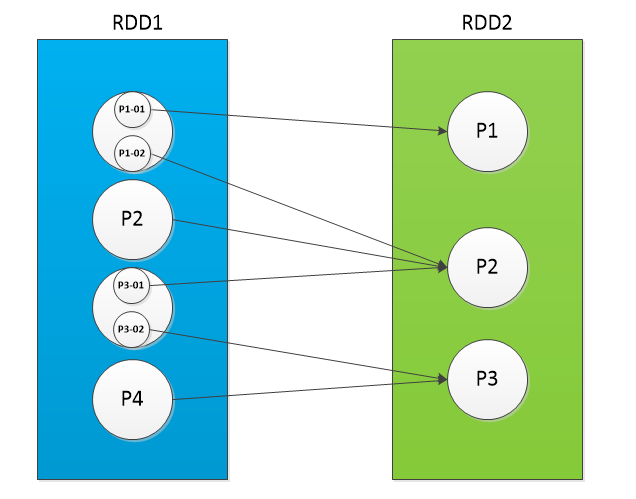
1个子分区,由多个父分区组成,同时1个父分区(与(3)不同,这里是:部分数据)也为多个子分区提供数据(通过ShuffleDependency)
4.3 总结
因此,在Spark的依赖体系中,大致可总结如下:
Dependency
ShuffleDependency (N:N)
NarrowDependency
PruneDependency (N:N, 内部使用)
OneToOneDependency (1:1)
RangeDependency (N:N)
5 总结
RDD作为Spark核心中的核心,顶级抽象类,要了解它的设计,个人的学习步骤如下:
(1)明确它的核心作用,从定义可以看到:弹性分布式数据集
(2)了解它的设计理念
(3)在实践中,分析它需要解决的具体问题,搞清楚它的功能边界,哪些是必须它解决的,哪些是可以通过其他方法解决的
(4)循环(2),(3)两步相互印证

 浙公网安备 33010602011771号
浙公网安备 33010602011771号