HBase优化相关
1.HBase预分区
HBase在创建表时,默认会自动创建一个Region分区。在导入数据时,所有客户端都向这个Region写数据,直到这个Region足够大才进行切分。这样在大量数据并行写入时,容易引起单点负载过高,从而影响入库性能。一个好的方法是在建立HBase表时预先分配数个Region,这样写入数据时,会按照Region分区情况,在集群内做数据的负载均衡。常用命令:
--自定义预分区的RowKey hbase> create 't1', 'f1', SPLITS => ['10', '20', '30'] --使用文件内容预分区 hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt', OWNER => 'johndoe' --使用内置的分区算法HexStringSplit hbase> create 't1', 'f1', {NUMREGIONS => 3, SPLITALGO => 'HexStringSplit'} --指定列族'info'使用'GZ'压缩 hbase> create 'pre', { NAME => 'info', COMPRESSION => 'GZ'}, {NUMREGIONS =>3, SPLITS => ['10', '20']}
使用最后一个创建'pre'表,然后通过Web页面 http://ncst:60010/table.jsp?name=pre 或者通过HBase shell命令scan 'hbase:meta' 查看hbase命名空间下所有标的元数据信息。
pre,,1442404691018.d514 column=info:regioninfo, timestamp=1442404691255, value={ENCODED => d e0dcd3d83aa48704d7f9a64 514e0dcd3d83aa48704d7f9a64db575, NAME => 'pre,,1442404691018.d514e0d db575. cd3d83aa48704d7f9a64db575.', STARTKEY => '', ENDKEY => '10'} pre,10,1442404691018.50 column=info:regioninfo, timestamp=1442404691255, value={ENCODED => 5 42efafeac5c9b6adce9868a 042efafeac5c9b6adce9868a9d0f72e, NAME => 'pre,10,1442404691018.5042e 9d0f72e. fafeac5c9b6adce9868a9d0f72e.', STARTKEY => '10', ENDKEY => '20'} pre,20,1442404691018.81 column=info:regioninfo, timestamp=1442404691255, value={ENCODED => 8 77de50218057a033be26c93 177de50218057a033be26c937c07be5, NAME => 'pre,20,1442404691018.8177d 7c07be5. e50218057a033be26c937c07be5.', STARTKEY => '20', ENDKEY => ''}
可以看到第一个Region的 STARTKEY => '', ENDKEY => '10',第二个Region的 STARTKEY => '10', ENDKEY => '20',第三个Region的 STARTKEY => '20', ENDKEY => ''。
需要注意的是:
hbase> create 'pre', { NAME => 'info', COMPRESSION => 'GZ'}, {NUMREGIONS =>3, SPLITS => ['10', '20']} --上述命令不等同于下面这条命令,并且下面这条命令还是错误的. --这是因为【预分区】是针对整个Table,而不是某个Column Family hbase> create 'pre', { NAME => 'info', COMPRESSION => 'GZ', NUMREGIONS =>3, SPLITS => ['10', '20']}
2.hbase merge regions
对一个表进行预分区后,导入数据发现很多预分的region都没有数据,预分的规则不太好,然后把那些没有数据的region合并,使用hbase 有个merge工具。
用法:hbase org.apache.hadoop.hbase.util.Merge <table_name> <region1> <region2>
具体写法:
//注意:执行该命令前需要停止hbase集群
hbase org.apache.hadoop.hbase.util.Merge pre pre,10,1442404691018.5042efafeac5c9b6adce9868a9d0f72e. pre,20,1442404691018.8177de50218057a033be26c937c07be5.
执行完后重新启动集群,master:60010查看一下该表的regions,可以看到已经合并了。
3.HBase的Bloom Filter
最根本的解释:判断一个元素是否属于这个集合。Bloom Filter是一个很长的二进制向量和一系列随机映射函数
如果这个集合中的元素足够多,那么通过传统遍历的方法进行判断耗时会很多。Bloom Filter就是一种利用很少的空间换取时间的实用方法。但是要说明的是:Bloom Filter的这种高效是有一定代价的,在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(误判存在 false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
1.Bloom Filter的原理?
Bloom Filter是m位的数组,且这个数组的每一位都是零。

Step 1 映射:假如我们有A={x1,x2,x3….xn} n个元素,那么我们需要k个相互独立的哈希Hash函数,将其中每个元素进行k次哈希,他们分别将这个元素映射到m位的数组中,而其映射的位置就置为1,如果有重复的元素映射到这个数组的同一个元素,那么这个元素只会记录一次1,后续的映射将不会改变的这个元素的值。如图:
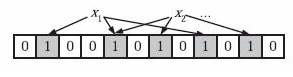
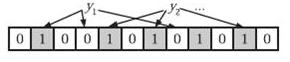
Step 2 判断:在判断B={y1,y2} 这两个元素是否属于A集合时,我们就将这两个元素分别进行上步映射中的k个哈希函数的哈希,如果结果全为1,那么就判断属于A集合,否则判断其不属于A集合。如下图 y2属于,y1则不属于。
2.Bloom filter在HBase中的作用?
HBase利用Bloom filter来提高随机读(Get&Scan)的性能
3.Bloom filter在HBase中的开销?
Bloom filter是一个列族(cf)级别的配置属性,如果你在表中设置了Bloom filter,那么HBase会在生成StoreFile时包含一份bloomfilter结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。
4.Bloom filter如何提高随机读的性能?
对于某个region的随机读,HBase会按照一定的顺序遍历每个memstore及storefile,将结果合并返回给客户端。如果你设置了bloomfilter,那么在遍历读storefile时,就可以利用bloomfilter,忽略某些storefile。
5.HBase中的Bloom filter的类型及使用?
a). ROW行级过滤器, 根据KeyValue中的row来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloom filter为ROW,那么get(r1)时就会过滤sf1,get(r3)就会过滤sf2
b). ROWCOL行加列级过滤器,根据KeyValue中的row+qualifier来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloom filter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取sf1+sf2;而如果设置了CF属性中的bloom filter为ROWCOL,那么get(r1,q1)就会过滤sf2,get(r1,q2)就会过滤sf1
6.ROWCOL一定比ROW效果好么?不一定
a). ROWCOL只对指定列(Qualifier)的随机读(Get)有效,如果应用中的随机读get,只含row,而没有指定读哪个qualifier,那么设置ROWCOL是没有效果的,这种场景就应该使用ROW
b). 如果随机读中指定的列(Qualifier)的数目大于等于2,在0.90版本中ROWCOL是无效的,而在0.92版本以后,HBASE-2794对这一情景作了优化,是有效的(通过KeyValueScanner#seekExactly)
c). 如果同一row多个列的数据在应用上是同一时间put的,那么ROW与ROWCOL的效果近似相同,而ROWCOL只对指定了列的随机读才会有效,所以设置为ROW更佳
7.ROWCOL与ROW只在名称上有联系,ROWCOL并不是ROW的扩展,不能取代ROW
8.region下的storefile数目越多,bloom filter的效果越好
9.region下的storefile数目越少,HBase读性能越好
4.hbaseadmin.balancer()
用hbaseadmin.split()手动对region进行拆分,拆分完之后,每个子region并没有均衡分布到3个regionserver上去。于是手工执行了一下hbaseadmin.balancer(),还是没效果。
查看源码发现原因:banancer()是针对整个集群的region分布,而不是针对某个表的region分布。它只保证每个regionserver上分布的regions在平均regions的0.8到1.2倍之间。
avg = 整个集群的总region数/regionserver个数
min = floor(avg*(1-0.2))
max=ceiling(avg*(1+0.2))
即所有regionserver上的regions个数都在min和max之间的话,就不会执行balancer。
补充说明:默认情况下是针对整个集群的region分布来均衡的,也可以针对表的region来均衡,需要配置:
<property> <name>hbase.master.loadbalance.bytable</name> <value>true</value> </property>
然后重启集群。再执行hbaseadmin.balancer()。可以发现分布在一个regionserver上的一个表的regions被均匀的分布在所有的regionserver上了。
5.hbase宕机处理
HBase的RegionServer宕机超过一定时间后,HMaster会将其所管理的region重新分布到其他活动的RegionServer上,由于数据Store和日志HLog都持久在HDFS中,该操作不会导致数据丢失。所以数据的一致性和安全性是有保障的。
但是重新分配的region需要根据日志HLog恢复原RegionServer中的内存MemoryStore表,这会导致宕机的region在这段时间内无法对外提供服务。
而一旦重分布,宕机的节点重新启动后就相当于一个新的RegionServer加入集群,为了平衡,需要再次将某些Region分布到该server。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号