
Transformer, ELMo, GPT, 到Bert
RNN:难以并行
CNN:filter只能考虑局部的信息,要叠多层
Self-attention:可以考虑全局的信息,并且可以并行 (Attention Is All You Need)
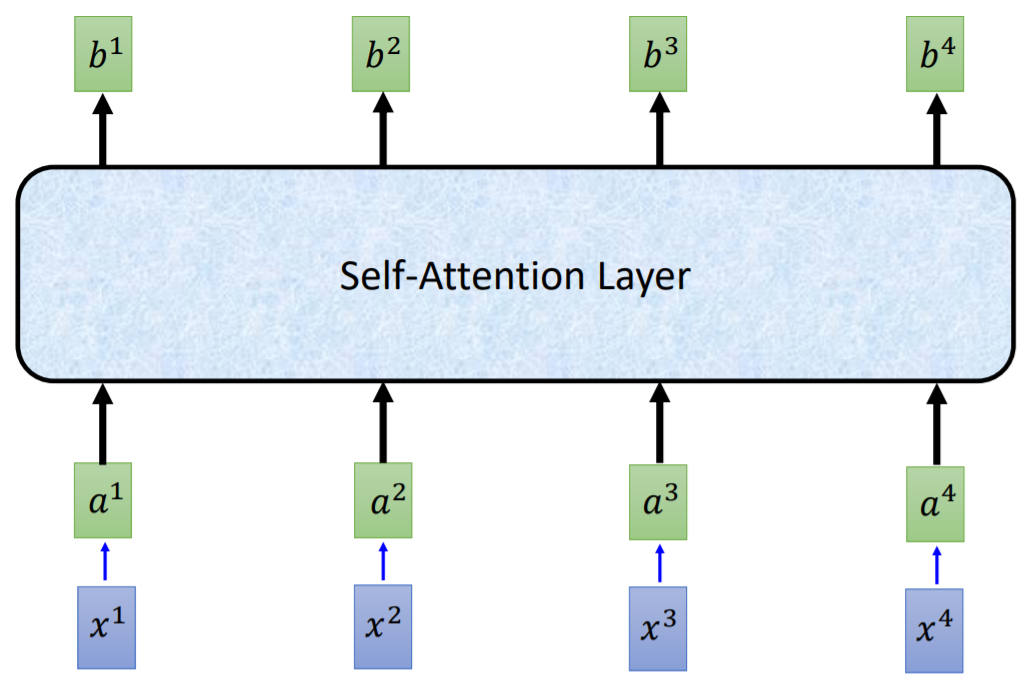
示意图:x1, x2, x3, x4先embedding成a1, a2, a3, a4,然后输入到Self-Attention Layer输出 𝑏1, 𝑏2, 𝑏3, 𝑏4, ps:它们能够平行计算
下面我们来看看如何计算b1
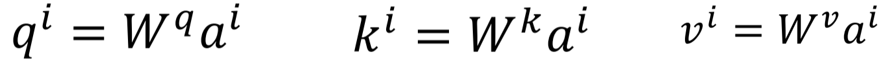
先通过Wq, Wk, Wv将ai变成(qi, ki, vi),ps:三个矩阵乘的都是ai,这就是为什么叫self-attention

计算b1的过程
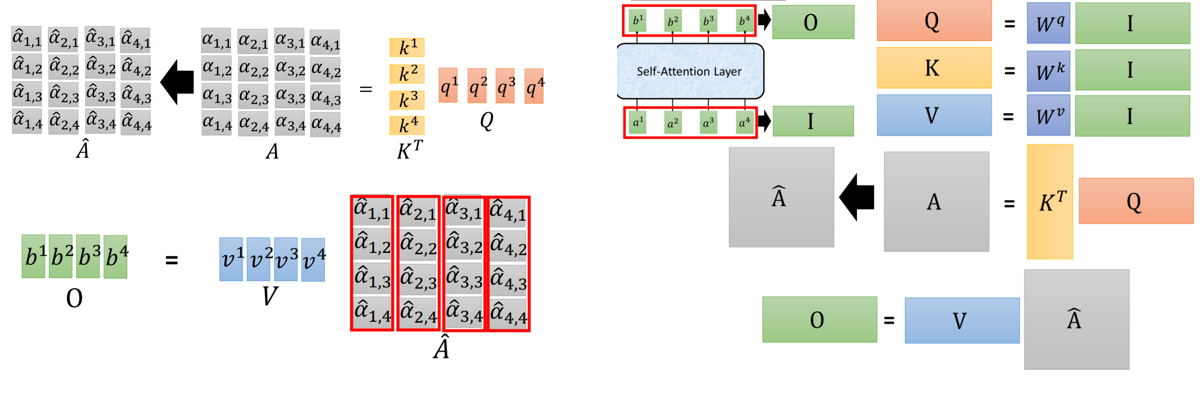
整个过程的示意图(省略了scale的部分)
还有一些操作:
1. Multi-head Self-attention: MultiHead(Q,K,V)=Concat(head1,…,headh)WO, where headi=Attention(QWiQ,KWiK,VWiV)
2. Positional Encoding (原始paper是人工设计的,不是训练出来的)
Transformer
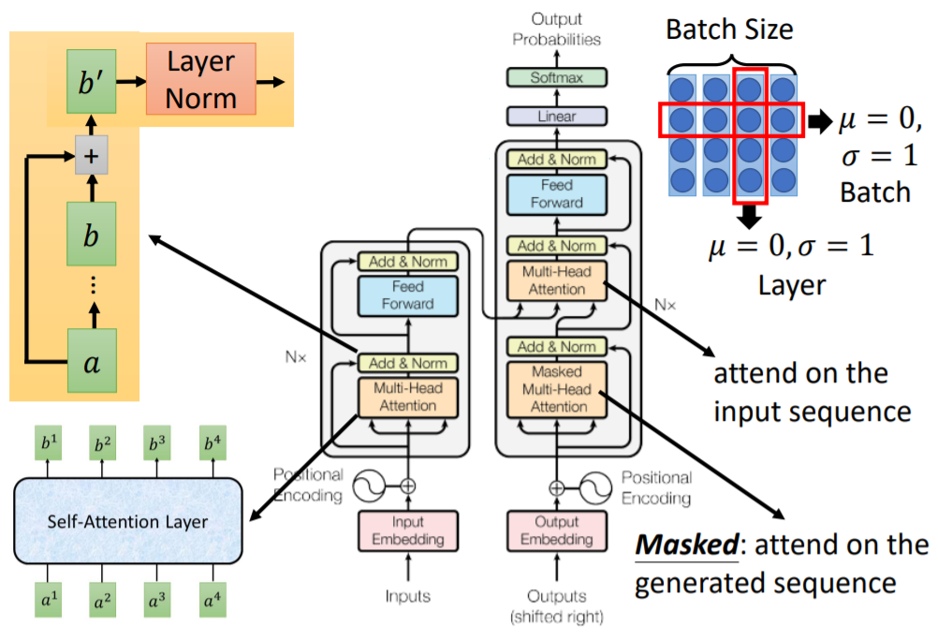
Transformer示意图
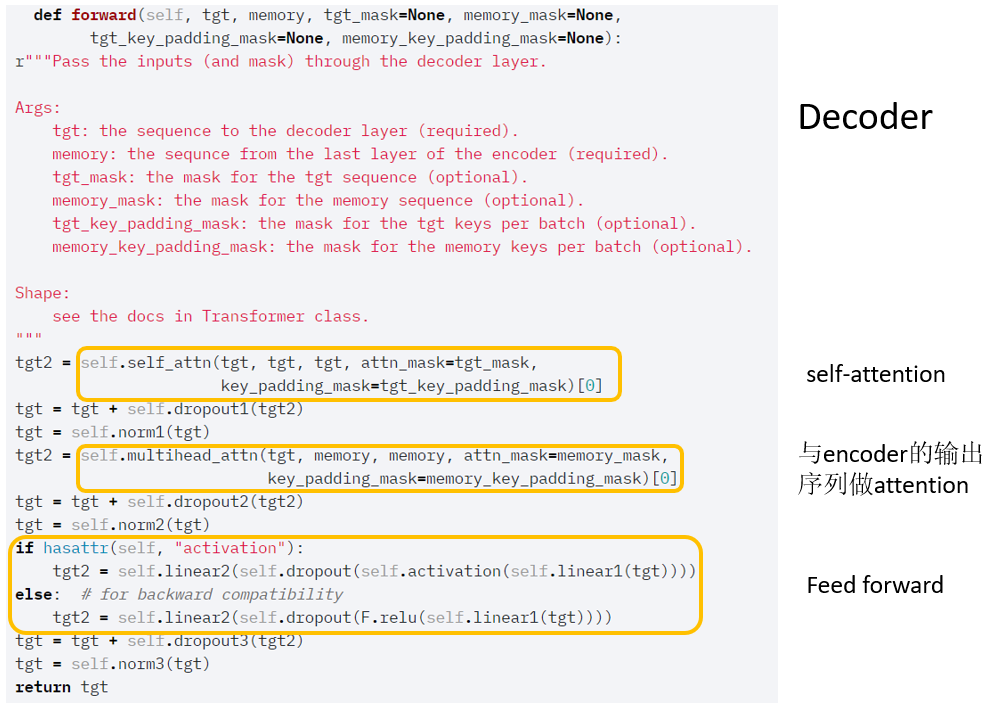
Decoder 部分
默认参数:
- d_model=512:layer的输入输出都是512维度
- nhead=8:8个head-attention
- num_encoder_layers=6:6个encoder block
- num_decoder_layers=6:6个decoder block
- im_feedforward=2048:feed forward 隐层的神经元个数
可以查看google blog,transformer的大致工作的gif示意图.
ELMo
对数似然函数:
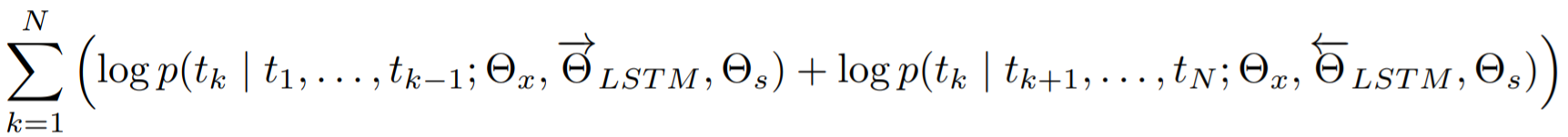
Θx:token representation的参数 , Θs: Softmax layer参数
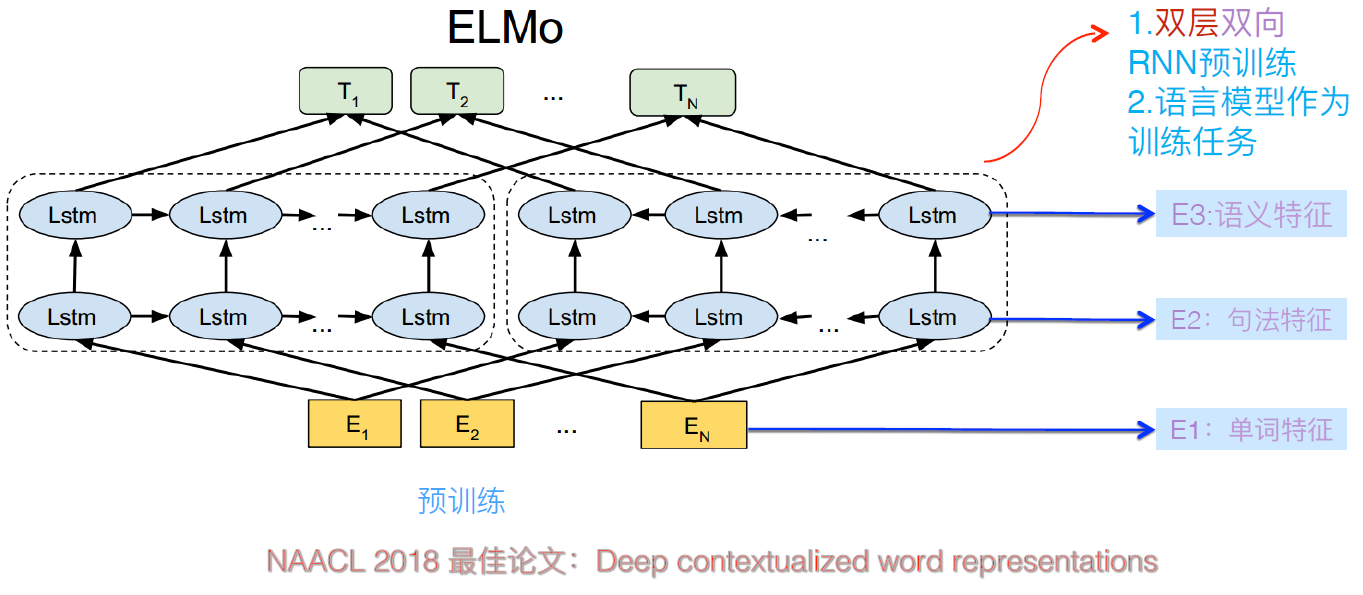
假设我们使用的是L层的双向LSTM,那么,对于每一个token tk, 我们可以得到2L+1个向量表示
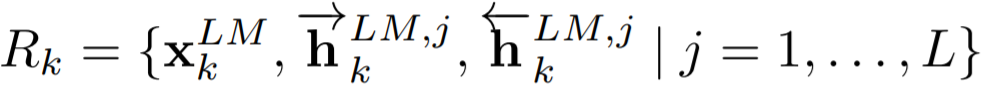
ELMo具体操作是将这2L+1个向量进行加权平均,权重是学出来的,针对不同的下游任务,
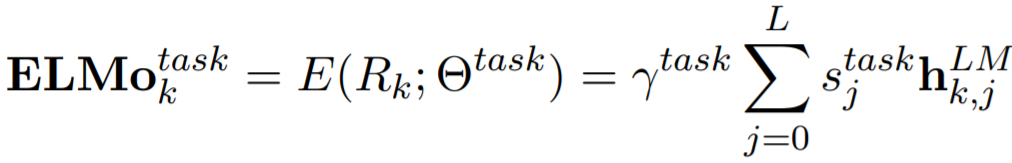
stask:softmax-normalized weights, γtask:the scalar parameter -- allows the task model to scale the entire ELMo vector
Bert
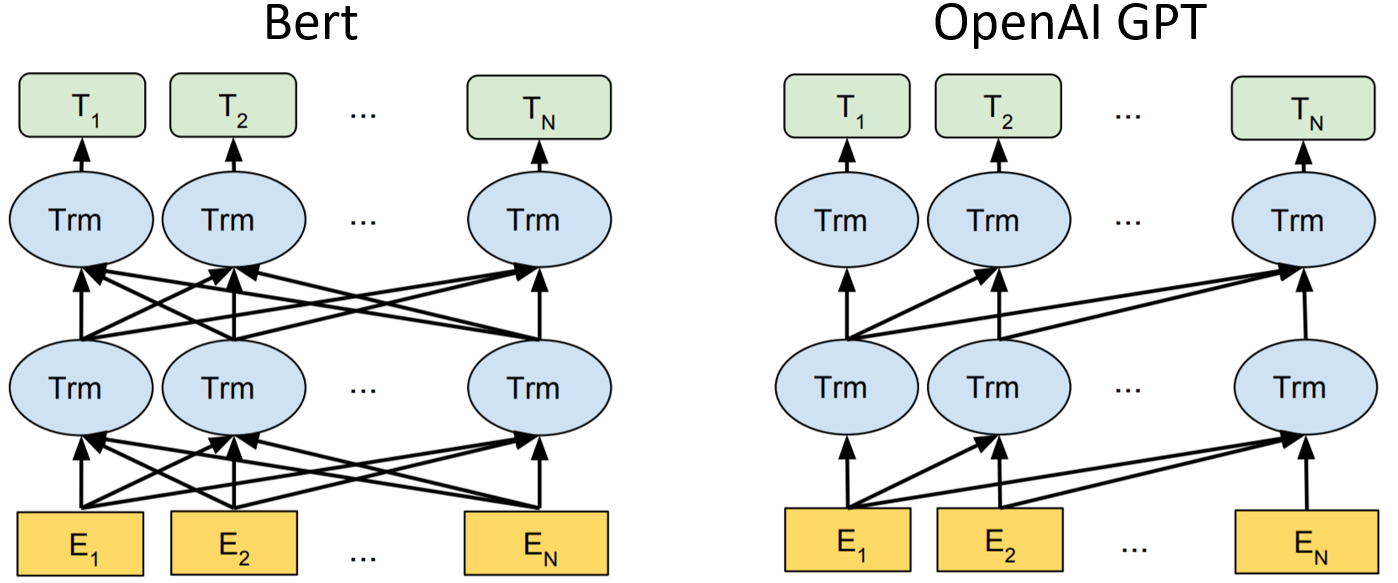
BERT用了双向的Transformer的encoder,而GPT是单向的decoder
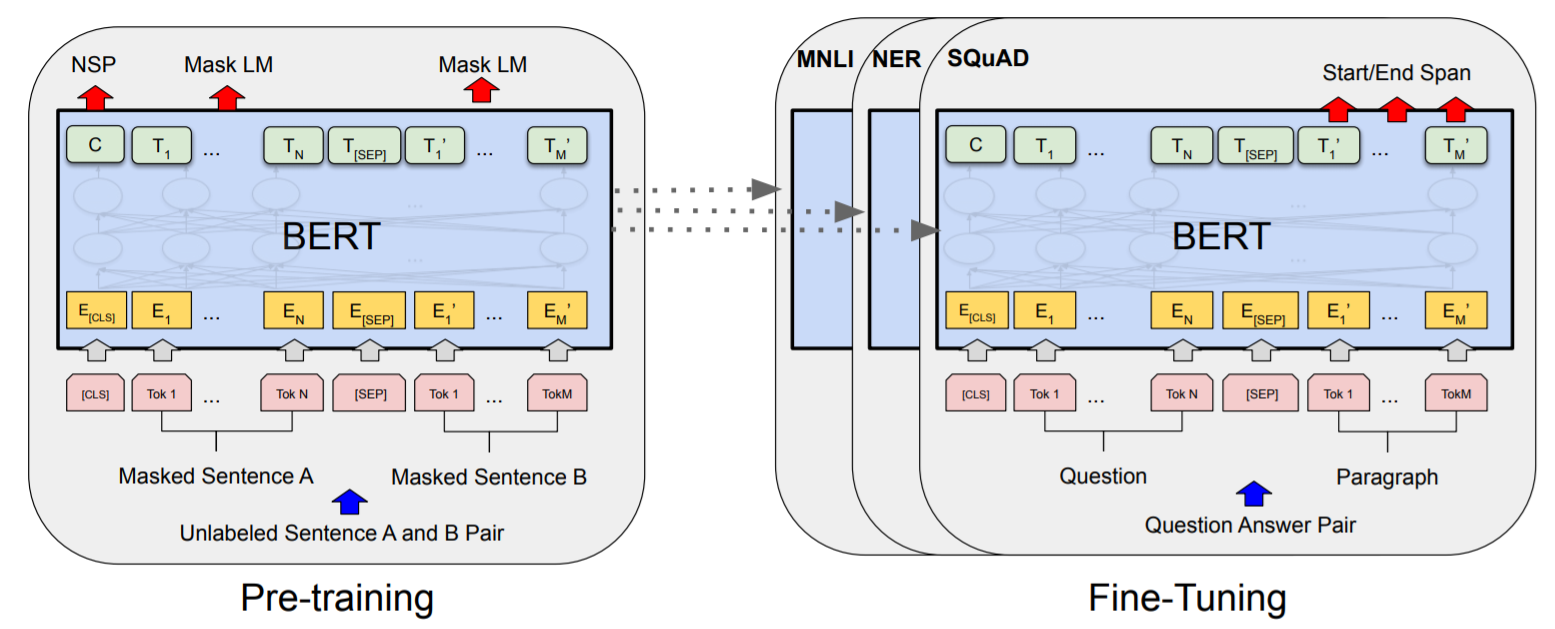
BERT用了Masked Language model和Next Sentence Prediction(NSP), 并且可以很好的对下游任务进行fine-tune,一般只需要在额外加一层output layer就可以得到非常好的结果.
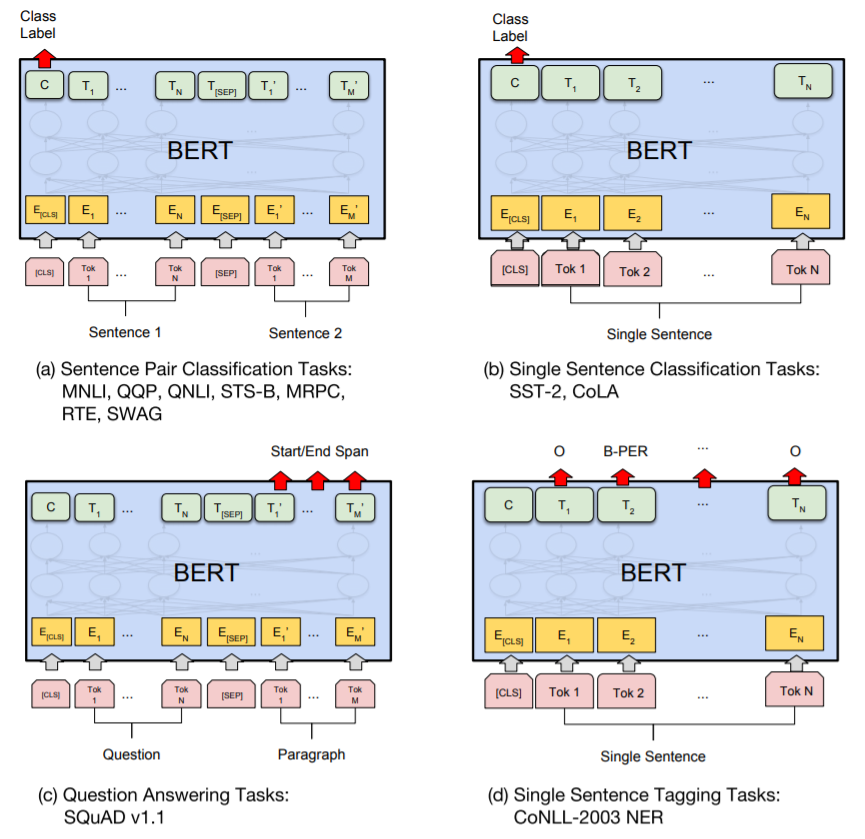
对于不同的task, Fine-tune BERT
下面讲一下具体的一些细节。
Masked LM
对于每一句话,mask掉 15%的token, 对于这部分mask掉的token,
- 80%被替换成[MASK], my dog is hairy → my dog is [MASK]
- 10%替换成random token (根据unigram distribution), my dog is hairy → my dog is apple
- 10% 不变, my dog is hairy → my dog is hairy
然后我们只预测masked words。
Next Sentence Prediction
例子
- Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
- Label = IsNext
- Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
- Label = NotNext
最近,还有一些新的版本的Bert。
ERNIE: 掩盖了短语和实体等单元(以便从这些单元中隐式地学习句法和语义信息)

不同的masking level
SpanBERT:随机掩盖连续的word

连续的span(用几何分布采样span的长度),然后加了一个span boundary objective(SBO)的损失 (用边界tokens ‘was’ 和‘to’ 去预测masked span中的每一个 token)
ALBERT:主要做了两个参数降低的办法
1.Factorized embedding parameterization:词表 V 到 隐层 H 的中间,插入一个小维度 E,多做一次尺度变换
![]()
2.Cross-layer parameter sharing:粗暴的做法--共享所有的layer的参数(FFN参数和attention的参数)
XLNet: 乱序语言模型,先用Query stream部分进行预训练,再用Content stream进行fintune
- Permutation:通过mask实现
- Two-Stream Self-Attention
- Content stream: 一般的self-attention
- Query stream: 不能够看到当前的token,只能看到position的embedding
query stream cannot do self-attention and does not have access to the token at the position, while the content stream performs normal self-attention
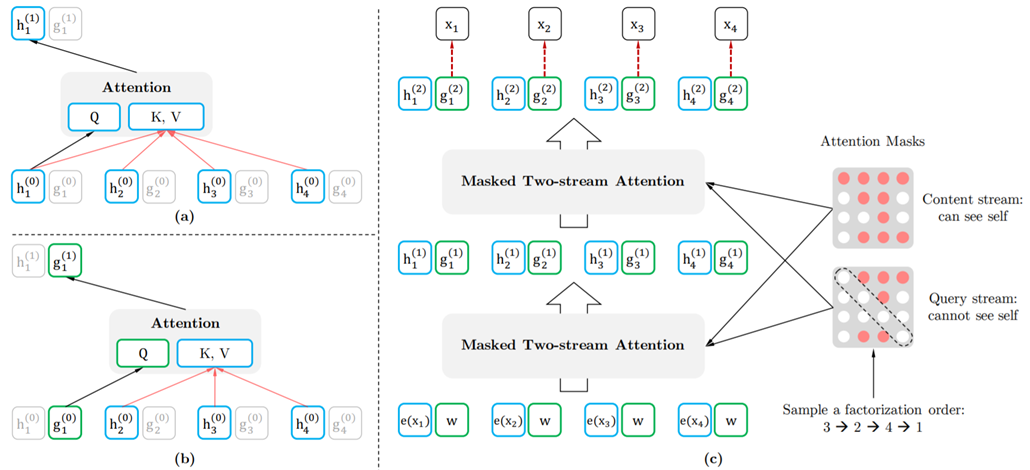
(a) Content stream attention. (b) Query stream attention. (c) Overview
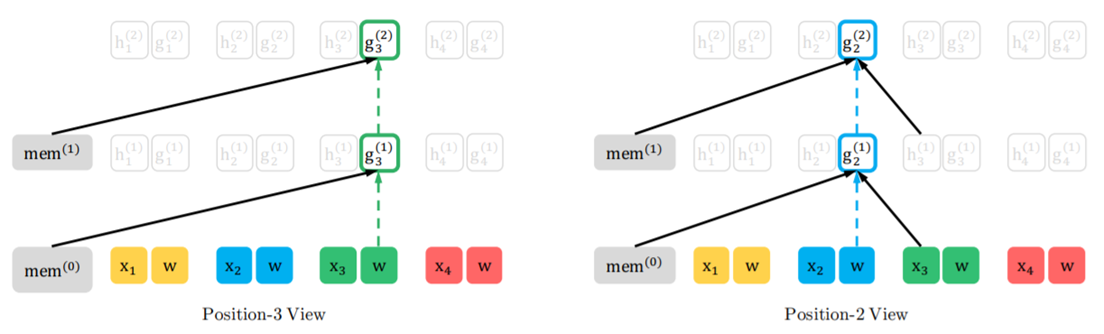
(Factorization order: 3 --> 2 --> 4 --> 1), 只显示3和2部分,ps:虚线部分表示不能access当前的token,只能access position embedding.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号