Zabbix实战-简易教程--DB类--ClickHouse
一、ClickHouse介绍
Clickhouse是一个用于联机分析处理(OLAP)的列式数据库管理系统(columnar DBMS)。
传统数据库在数据大小比较小,索引大小适合内存,数据缓存命中率足够高的情形下能正常提供服务。但残酷的是,这种理想情形最终会随着业务的增长走到尽头,查询会变得越来越慢。你可能通过增加更多的内存,订购更快的磁盘等等来解决问题(纵向扩展),但这只是拖延解决本质问题。如果你的需求是解决怎样快速查询出结果,那么ClickHouse也许可以解决你的问题。
应用场景:
1.绝大多数请求都是用于读访问的2.数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作3.数据只是添加到数据库,没有必要修改4.读取数据时,会从数据库中提取出大量的行,但只用到一小部分列5.表很“宽”,即表中包含大量的列6.查询频率相对较低(通常每台服务器每秒查询数百次或更少)7.对于简单查询,允许大约50毫秒的延迟8.列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)9.在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)10.不需要事务11.数据一致性要求较低12.每次查询中只会查询一个大表。除了一个大表,其余都是小表13.查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
相应地,使用ClickHouse也有其本身的限制:
1.不支持真正的删除/更新支持 不支持事务(期待后续版本支持)2.不支持二级索引3.有限的SQL支持,join实现与众不同4.不支持窗口功能5.元数据管理需要人工干预维护
二、ClickHouse监控
本文不介绍ClickHouse的具体功能,只是讨论监控。牛逼的Altinity公司提供了,clickhouse zabbix监控的脚本及模板,但是导入模板时,发现是3.4版本的,里面有些参数不支持,所以重新制作了3.0版本的模板。
废话不多说,直接说监控过程。
1、前提条件
- 确保
xmllint已经安装. - 确保
clickhouse-client已经安装. - 编辑
/etc/zabbix/zabbix_agentd.conf. 添加内容:
UserParameter=ch_params[*],sh /PATH/TO/zbx_clickhouse_monitor.sh "$1" "HOST_WHERE_CH_IS_RUNNING"
2、说明
/PATH/TO/zbx_clickhouse_monitor.sh取决于你存放的位置HOST_WHERE_CH_IS_RUNNING是个可选参数,如果没有指定,localhost是默认使用的。
3、导入模板
导入模板:zbx_clickhouse_template.xml
4、数据展示
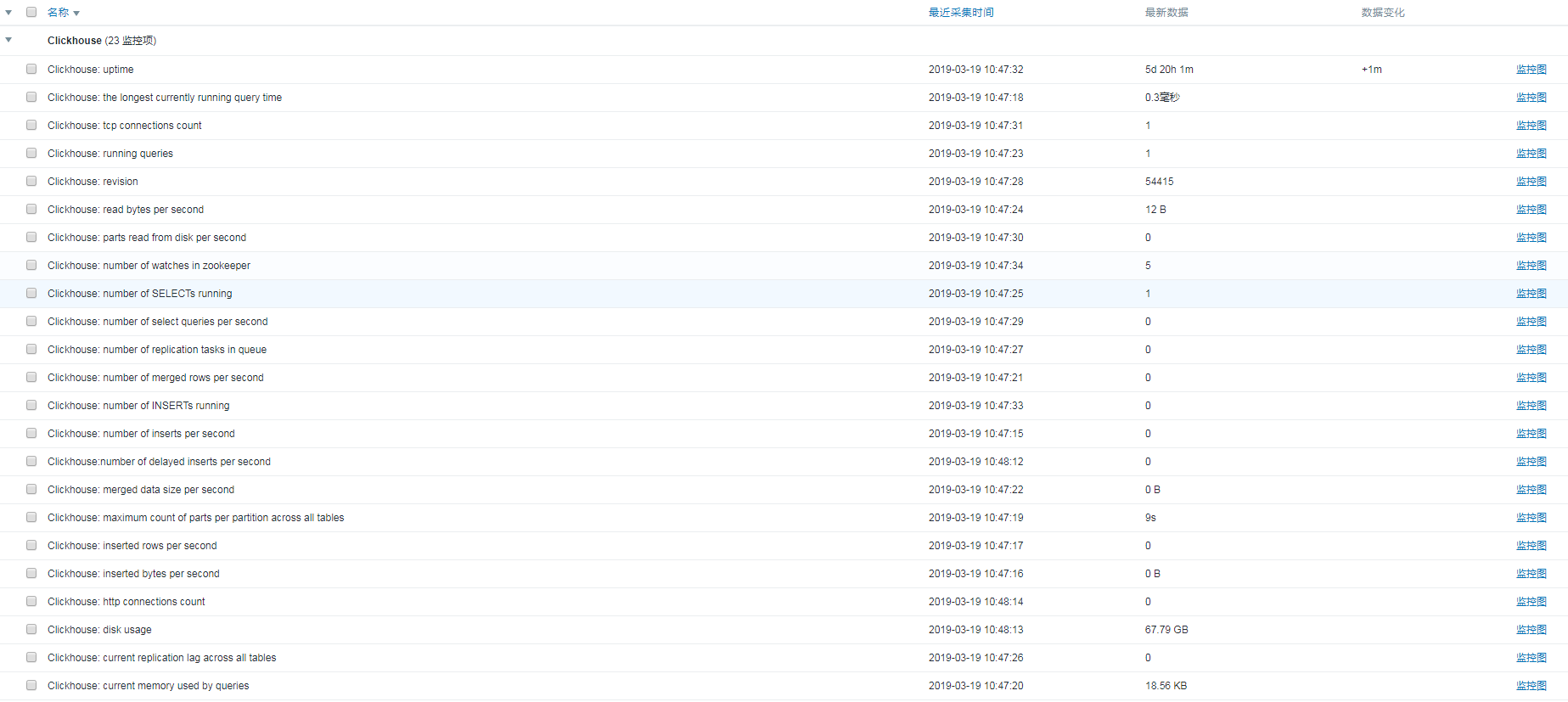
5、图表展示
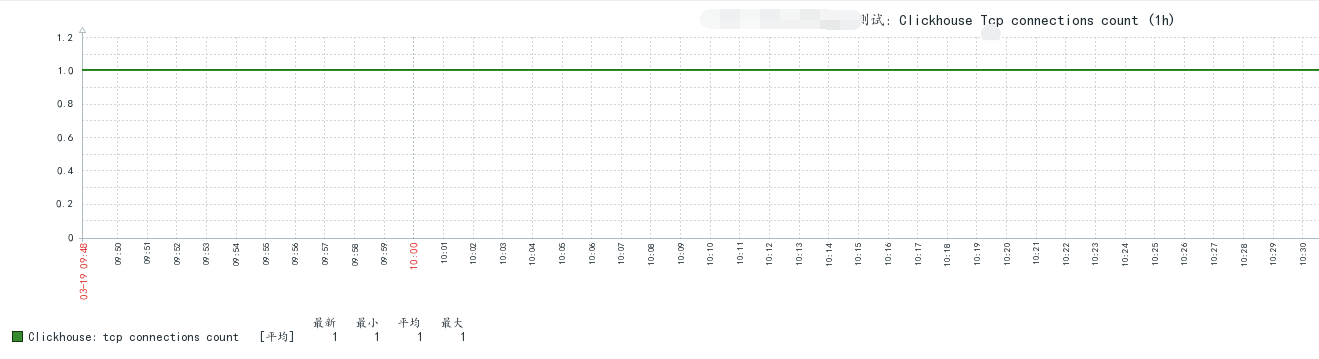
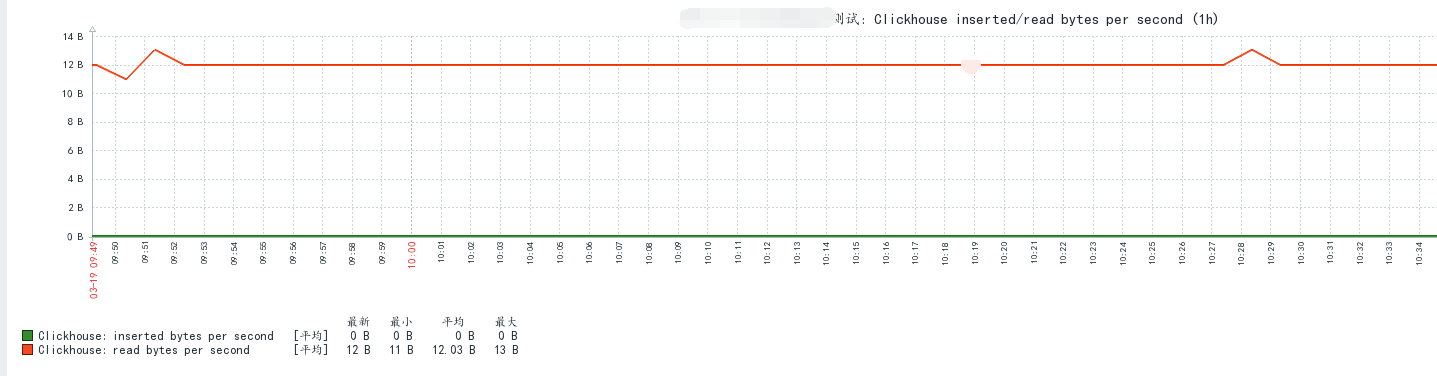
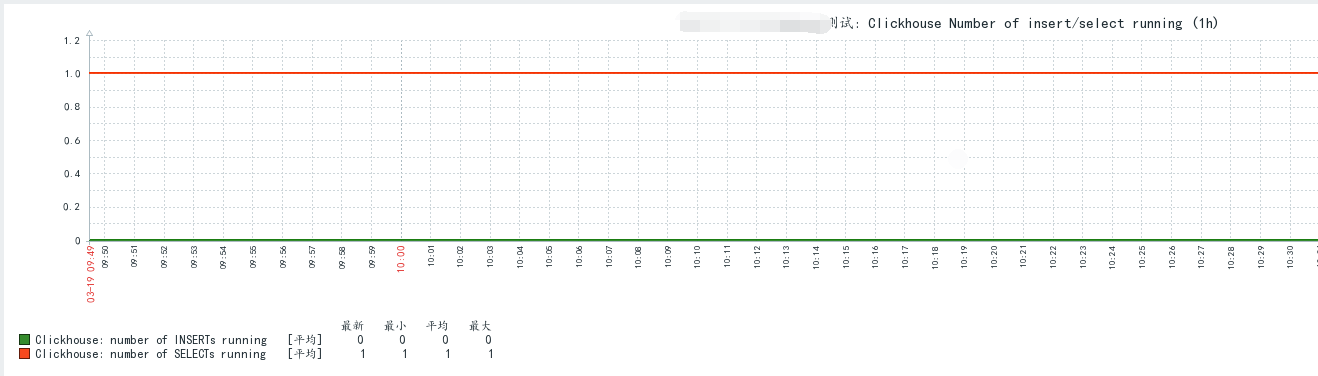
三、源码
附上源码和模板:
https://github.com/loveqx/zabbix-doc/tree/master/zabbix-scripts/zabbix-template-clickhouse

 浙公网安备 33010602011771号
浙公网安备 33010602011771号