深度学习应用简述
深度学习应用简述
硬件
首先,深度学习的成功应用离不开硬件的发展。GPU由于其高内存带宽,非常适合需要存储很多参数、激活值及梯度值的神经网络,而且许多神经网络可以并行运算,GPU在这方面也优于CPU,而GPU相对于CPU有较低的时钟速度及处理复杂计算的劣势,由于大部分神经网络单元并不需要复杂逻辑运算所以也并无很大影响。当然,也写好高效的GPU上运行的代码并不容易,值得庆幸的是,现在大部分库如TensorFlow等都已经将这些封装好了。另一方面,分布式计算也在飞速发展,所以有了asynchronous stochastic gradient descent,可以极大的加快训练时模型的更新速度。同时,为了使一些模型能够有效的运行在手机端,需要对模型进行压缩(model compression),即用需要内存及计算量更小的模型来替代原来较昂贵的模型。硬件方面,专门为深度学习设计的硬件也在发展,例如谷歌的TPU等。
图像处理
图形图像(computer vision)领域的发展,主要有物体识别,物体标记,图像转译,图像生成等等,主要应用了之前卷积神经网络的发展及之后要讲到的GAN等模型。有的时候,为了保证模型更好的工作,我们常常也需要借助传统的图像预处理等技术,例如normalization, dataset augmentation等等。Normalization的作用主要是减少数据间的变化,例如contrast normalization利用将数据减掉平均值并且将标准差调整到定值的方法降低对比度不同对模型造成的影响。这能够将样本映射到一个空间超球,类似于全连接网络的样本归一化。这种空间的均匀化能够让神经网络更快速的学习到特征,从而一定程度上避免了病态条件。
当然还有一种叫白化的操作,这种操作于contrast normalization不同,本质上就是批归一化,是将样本变为标准多维高斯分布,从而利于梯度下降算法的更新。
Dataset Augmentation利用对原数据做一些微调人为增加训练数据的方法使得模型在微扰下更稳定,常见的方法有平移、翻转、添加随机噪声等等。
语音识别
语音识别(speech recognition)也得益于深度学习。语音识别即输入时一系列的声音信号,输出是对应的文字,之前常采用的是HMM(Hidden Markov)与GMM(Gaussian mixture model)相结合的办法,而现在通常采用的是RNN模型。
n-gram
自然语言处理(Natural language processing)即将某种语言翻译成其他语言或机器语言,通常依赖于词组句子等的概率分布。之前采用的通常是一些概率统计模型,例如基于n-gram的模型定义了基于前n-1个词汇时第n个词的条件概率
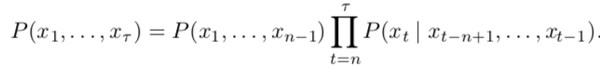
但是该模型会受到维度的诅咒,通常对于词汇量为 \(V\) 的问题,有 \(V^n\) 种n-gram,计算量很大,而且实际上大部分n-gram并不会出现在训练集中。
为了解决维度过高的问题,我们可以将单词s映射到word embedding空间,可以将其想为一个更低维度的空间,并且相似的单词在该空间中距离更近。而为了从这一表征空间重新映射到单词,我们需要利用Softmax,而由于映射到的类是 \(V\) 的量级,普通的Softmax计算量过大,这时候可以采用Hierachical Softmax, Importance Sampling等方法。
神经网络模型
现在效果较好的Neural Machine Translation系统通常采用Encoder-Decoder的结构,这在第十章已经介绍过,即利用Encoder将输入的文字序列转化为一个新的表征context,再利用Decoder将context转化为所需要的语言文字,Encoder、Decoder通常采用RNN结构。近期发现利用Attention模型和RNN结合能取得更好的效果。其基本思想是RNN的输出向量对于长句子来说之前的上下文会被遗忘,为了考虑整个句子的context,我们将这个信息存储起来,并在输出不同位置的结果时将侧重点(利用不同的权重参数)放在不同的记忆元素上,即对feature vector做weighted average,这种attention方法最早被应用在图像识别中,推广到机器翻译中也收获了很好的效果。这在之前的补充章节中也已经介绍(基于注意力的RNN)。
其他的机器学习的应用还有推荐系统。推荐系统主要依赖于用户过去的购买记录来计算不同用户或产品之间的相似性,这种方法叫做collaborative filtering,但这种方法对于新用户或新商品来说由于缺乏历史信息效果较差,通常我们会提取用户或商品其他方面的信息,并利用神经网络将其映射到embedding空间来寻找相似的推荐。除了监督学习模型,为了平衡exploration(尝试获取之前未探索过的信息)和exploitation(从已有信息尽可能高的获利)的问题,还可以尝试强化学习(Reinforcement Learning)的方法,因为强化学习可以同时平衡exploration和exploitation,其采用策略来进行选择action,并从environment中获得reward。
小结
深度学习还有很多其他方面的应用,在此主要是列举比较有代表性的一些应用。至此,工业中实际应用的深度学习知识总结完毕,下一章开始总结处于研究阶段的机器学习方法,如处理小数据以及通用机器学习模型等问题。而第三部分内容难度大,理应有大量推导,但由于花书的篇幅有限,所以其对这部分的知识描写较为晦涩,难以理解,如果想要深入学习应该以论文为主。因此对于后面部分的笔记将会偏向于总结,待以后学习到时再进行补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号