
人类偏好对齐——大模型PPO算法原理
🚀 欢迎来到《大语言模型》系列,博客文章将围绕现代大模型框架和技术展开讨论。基于Hugging Face的transformers库,该系列代码的实现尽在GitHub仓库项目🔗Milli-Chat中集成,感谢大家的支持!
当你使用大模型的时候,你是否留意过模型输出对话的左下角或者右下角有点赞👍或者踩👎的图标?又或者大模型有时候给你输出两个回答,让你选择其中一个你认为较好的回答?大模型厂商会将用户反馈的数据搜集起来,用于训练它们的大模型,来更好地提供用户想要的回答。
上述案例就是人类偏好对齐的一种方式。总而言之,人类偏好对齐的目的是在微调好模型之后,也就是模型能够流畅地对话之后,让模型能够输出符合自己的价值观的回答。目前(截至本文发布时间)主要有两种对齐路线,一种是基于强化学习的在线方式,这也是ChatGPT早期采用的方式;另一种是不需要奖励模型、直接在静态数据上训练的离线方式,这很像是上面案例所采取的方式。
为了阅读的方便,本文仅详细介绍人类偏好对齐过程中的RLHF算法。DPO及其家族属于另一种对齐路线。
1 强化学习基本概念
以《神庙逃亡》这款游戏为例,下面解释一些术语

- Environment,环境:这个游戏程序中所展现的虚拟世界,有一套无法改变的规则
- Agent,智能体:让计算机来操作人物的动作,计算机就是这个智能体
- State,状态:人物在环境中遇到的障碍物、转弯处,或者平路。有时候只看到游戏画面的一部分,因此状态也可以称为Observation
- Action,动作:遇到障碍物、转弯处之后需要手势的上下左右操作
- Reward,奖励:空中的钻石,手势上滑可以跳跃拿到
基于上述最基本的概念,有
- Action Space,动作空间:玩《神庙逃亡》时人物所有的操作,上跳、下蹲、左右转弯、左右偏向。对应Agent的动作空间包含上下左右滑动、手机左右倾斜这6个动作
- Policy,策略:用\(\pi\)表示,表示输出每一步Action的概率分布。比在\(t\)时刻如遇到钻石,选择手势上滑的概率是\(0.9\),用数学表示就是\(\pi(\text{上滑}|s_t=\text{钻石})=0.9, \pi(\text{下滑}|s_t=\text{钻石})=0.1, \pi(\text{其他动作}|s_t=\text{钻石})=0\). 其中\(s_t\)就是当前的输入状态。当然每一次的Action概率分布采样,也就是让Agent遇到\(s_t\)时选择什么动作,并不是选择概率最大的那个动作,而是需要探索采取其他动作后会带来什么收益,贪心策略只顾眼前,不一定能够得到全局的最优解,而只有探索才有可能找到更优解。
- Trajectory,轨迹:有时也称Episode,用\(\tau\)来表示,表示状态和动作的序列\((s_0,a_0,\cdots,s_T,a_T)\)。假设游戏结束就是终点,那么从起点到终点的所有遇到的状态和相应采取的动作序列就是一个轨迹。
- Return,回报:Return是游戏结束时得到的Reward累计和。
由上可知强化学习的目的是:训练一个Policy神经网络\(\pi_\theta\),在所有的Trajectory中得到Return期望最大。将该目的转换为数学语言:
其中\(\theta\)表示\(\pi_\theta\)的参数。
2 策略梯度
2.1 REINFORCE
接下来采用梯度上升的方法求上述期望的梯度。对于离散的期望而言\(\displaystyle \mathbb{E}_{f(x)\sim P(x)}[x]=\sum f(x)\cdot P(x)\),对于连续的期望\(\displaystyle \mathbb{E}_{f(x)\sim p(x)}[x]=\int f(x)\cdot p(x)\mathrm{d}x\),一般而言计算机中是离散的变量,因此下面用离散的形式表示期望函数\(J(\theta)\)的梯度
上面的推导用了一个小技巧——对数求导技巧(Log-Derivative Trick):\(\displaystyle \nabla_\theta\log f(\theta)=\frac{\nabla_\theta f(\theta)}{f(\theta)}\)。
解答一些可能的疑惑
- \(\pi_\theta(\tau)\):在基本概念中说\(\pi\)指的是Action的概率分布,这里不严谨,因此用更具体的\(\pi_\theta(a_t|s_t)\)来表示将当前的游戏状态\(s_t\)输入给网络、然后输出在\(s_t\)的条件下各动作\(a_t\)的概率分布,下标\(\theta\)可带可不带,主要表示该策略网络的参数。而\(\pi_\theta(\tau)\)表示通关方式的概率分布。(下图中使用神经网络示意图来表示任意的网络模型)
- 高中数学用\(\ln\)来表示\(\log_e\),但是人工智能领域全都用\(\log\)来表示了。
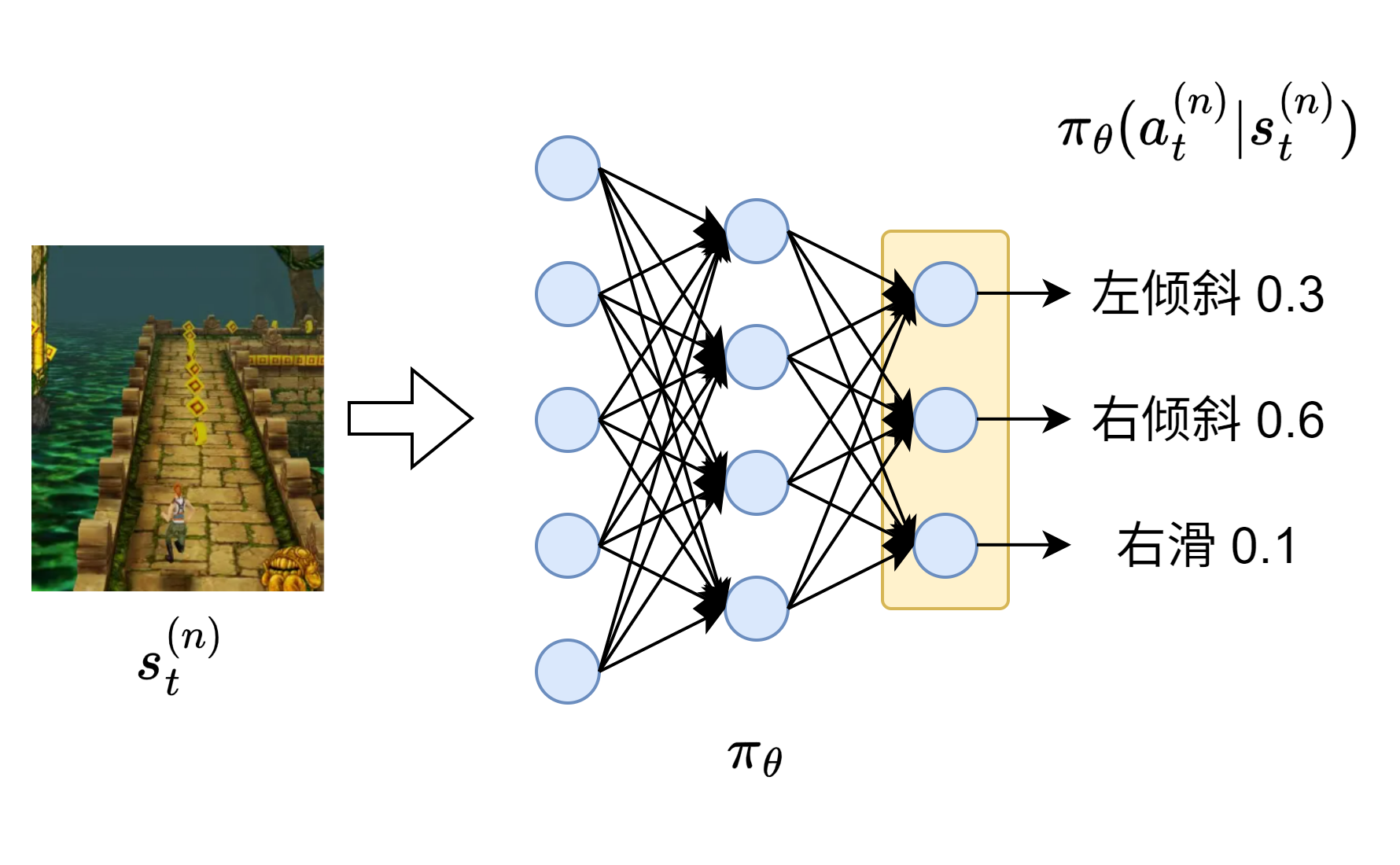
一个轨迹\(\tau\)发生的概率取决于:初始状态概率\(P(s_0)\),策略产生的动作概率\(\pi_\theta(a_t|s_t)\),环境的状态转移概率。结合所有的时间步可以得到
其中\(P(s_{t+1}|s_t,a_t)\)表示在状态\(s_t\)下采取动作\(a_t\)之后转移到状态\(s_{t+1}\)的概率,这是由环境决定的。然而它和策略网络的参数无关,因此
因为\(R(\tau)\nabla_\theta\log\pi_\theta(\tau)\)是关于\(\tau\)的函数,因此将期望的梯度用期望来表示,结合上式替换\(\nabla_\theta\log\pi_\theta(\tau)\)得到
然而轨迹\(\tau\)是无法穷举的,得不到完整的轨迹概率分布\(\pi_\theta(\tau)\),导致期望很难精确计算。因此接下来采用蒙特卡洛采样将期望展开。蒙特卡洛采样讲了这样一件事情,假设\(f(x)\sim p(x)\),从分布\(p(x)\)大量采样得到\(N\)个样本点\(x_1,\cdots,x_N\),因此有
有点像大数定律。根据蒙特卡洛采样从策略模型中采样大量的样本\(\tau_1,\cdots, \tau_N\),用来估计期望梯度:
用上述的梯度\(\nabla_\theta J(\theta)\)来更新策略神经网络的参数\(\theta\),也就是\(-lr\cdot \nabla J(\theta)\),这种梯度叫做策略梯度。
上述推导就是经典的Vanilla Policy Gradient (VPG, REINFORCE)。缺点也很明显: 极其不稳定,因为它是对数据进行采样,一旦学习率过大,策略更新幅度过大,模型性能会瞬间崩塌(Policy Collapse)。
解决训练不稳定
当\(R(\tau^{(n)})>0\)时,增加这个路径\(\tau^{(n)}\)中所有状态下采取对应的Action的概率;反之\(R(\tau^{(n)})<0\)的时候,减小这个路径中所有状态下采相应Action的概率。每一条路径更新幅度的贡献值为
意思就是在路径\(\tau^{(n)}\)中,对于每一个状态\(s_t^{(n)}\),选择动作\(a_t^{(n)}\)产生的回报为\(R(\tau^{(n)})\),是所有状态采取相应动作所获得的Reward的加和,也可以理解为对该状态\(s_t\)所采取动作\(a_t\)的概率的更新幅度。很显然,状态\(s_t^{(n)}\)下的动作\(a_t^{(n)}\)只影响后续有限的几步,因此引入衰减因子\(\gamma\)(\(\in(0,1)\)),仅考虑当前及后续动作的Reword \(r_{t'}^{(n)}\),将产生的回报改进为
衰减因子可以理解为:距离当前步数\(t\)越远,则当前动作\(a_t\)对回报的影响越小。它规定了Agent的有效视野。
由于轨迹是采样的,所以同一个状态下产生的回报\(R_t\)方差很大,形式好的时候(玩游戏所采取的动作都是最优解)策略模型参数的更新都会朝着增加Action的概率的方向更新,反之形势很差的时候(玩游戏连连失误)就会朝着减少的方向更新。这样更新参数的幅度太大,导致训练不稳定。因此考虑每个状态所产生的平均/期望回报(不管采取什么动作),对\(R_t^{(n)}\)减去一个该状态下的平均/期望回报\(B(s_t^{(n)})\)。综上所述,REINFORCE的更新公式可以优化为
由于\(\mathbb{E}_{\tau\sim\pi_\theta}[R_t]=B(s_t)\),\(B(s_t)\)为\(R_t\)的无偏估计,因此上述等号成立。这种无偏估计是由下面即将介绍的Critic网络打分得到的,需要通过学习训练该网络。
和深度学习中Normalization的目的一样,都是为了训练稳定。而上述的无偏估计也说明了为什么不是Normalization,而仅仅是减去平均值。
引入A2C算法
Advantage Actor-Critic(A2C)就是这样将策略梯度与价值函数估计结合,通过引入优势函数(Advantage Function)来解决训练不稳定的问题。该算法有两大部分:
- Actor,即策略网络\(\pi_\theta\),负责做动作。
- Critic,状态价值(State-Value)网络\(V_\phi(s)\),输入状态\(s\),输出该状态的预估价值/期望回报,目标是准确预测智能体从当前状态开始能拿到的总奖励。这就是上面所提到的\(B(s_t)\)。
除此之外,需要引入动作价值(Action-Value)函数\(Q_\pi(s_t,a_t)\),表示Agent处于状态\(s_t\)时,做出动作\(a_t\)所观测到的累积Return。这就是上面提到的\(R_t\)。而\(R_t-B(s_t)\)换一种表述方式:
上述公式为优势函数(Advantage Function)。用来衡量在当前状态\(s_t\)下,做这个动作\(a_t\)比平均表现好多少。\(V_\phi(s_t)\)是\(Q_\pi(s_t,a_t)\)的期望,即为该状态下所有可能动作的加权平均得分\(\displaystyle V_\phi(s_t)=\sum_{a\in\mathcal{A}}\pi_\theta(a|s_t)Q_\pi(s_t,a)\)。
Bellman方程告诉我们一个状态的价值应该等于即时奖励\(r_t\)加上未来奖励,即下一个状态价值的折现:
其中\(s\sim P\)表示状态服从状态转移分布,前面的推导过程提到过。理想情况下,状态价值网络非常完美,两边相等。然而实际情况是\(V_\phi(s)\)在训练初期是胡乱猜的,和真实情况有一定的误差,等式两边并不相等。因此构造误差\(\delta_t\),该误差就是TD(Temporal Difference,时序差分)误差:
为什么期望没了:因为实际操作过程中这两部分都是采样得到的。当我们观察到一个真实的步长\((s_t,a_t, r_{t+1}, s_{t+1})\)时,TD目标\(r_{t+1}+\gamma V_\phi(s_{t+1})\)是更精确一点的估计,比\(V_\phi(s_t)\)更接近现实。
\(r_{t+1}\)表示在\(t\)时刻执行动作\(a_t\)后,由环境\(s_{t+1}\)时刻给出的即时奖励。即\(\displaystyle s_t\stackrel{a_t}{\longrightarrow}(r_{t+1}, s_{t+1})\). 当然写成\(r_t\)也没错,只要意思表示正确即可。
对于Critic而言,目的是让\(\delta_t\)趋近于\(0\),因此Critic网络的loss函数为\(\delta_t^2\)。对于Actor而言,它是优势函数。因为根据Bellman方程可以得知\(Q(s,a)\)的采样就是\(r+\gamma V(s')\)。因此
实际上,Critic网络可以直接修改\(\pi_\theta\)的最后一层为一个标量的输出,作为Critic网络来预测状态价值。因此其参数下标也可以写为\(\theta\),上面是为了区分属于不同的网络,才采用下标\(\phi\)来表示Critic网络的参数。
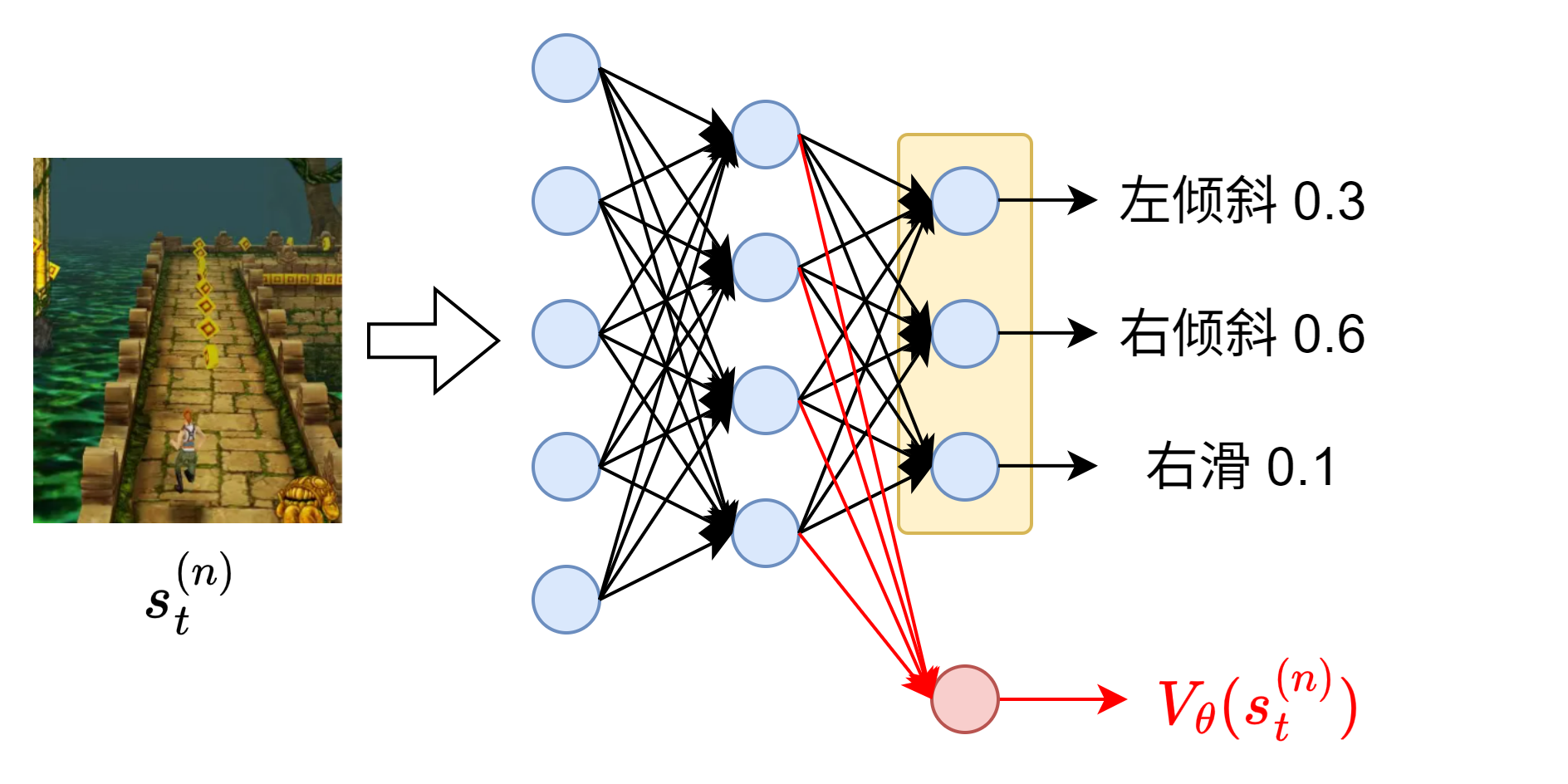
理想情况下\(V_\phi(s_{t+1})=r_{t+2}+\gamma V_\phi(s_{t+2}),\cdots\),递归推导,往后面多看几步:
可以发现本质上优势函数就是误差累积。接着引入超参数\(\lambda\)(\(\in(0,1)\)),定义GAE (Generalized Advantage Estimation,广义优势估计)
在编程中可以写成递推的形式
当\(\lambda=0\)的时候\(A_t^{GAE}=\delta_t\),就是简单的TD误差,方差极小,但非常依赖\(V_\phi\)的准确性;而当\(\lambda\rightarrow 1\)时,\(\displaystyle A_t^{GAE}=\sum_{l=0}^\infty \gamma^l r_{t+1+l}-V_\phi(s_t)\),这变成了蒙特卡洛采样,\(\displaystyle \sum_{l=0}^\infty \gamma^l r_{t+1+l}\)这一部分并没有\(V_\phi\)网络估计出来的部分,是完全无偏的,即理论上\(\mathbb{E}_{s_t\sim V_\phi}[A_t^{GAE}]=0\),意为误差的期望为0. 综上所述,\(\nabla_\theta J(\theta)\)可以估计为
2.2 TRPO思想
TRPO(Trust Region Policy Optimization,置信域策略优化)。这里不进行公式的推导、不给出理论上的结果,仅仅阐述这种算法的思想是怎么来的,方便引出PPO。
重要性采样
尽管经过优化后的策略梯度能够稳定训练,但是每一次训练之后改变了策略模型的参数\(\theta\),因而每次都需要在不断更新的网络\(\pi_\theta\)上重新采样数据进行训练,数据利用率太低、训练效率太低,这显然是不现实的。这种采集和训练的数据的策略是同一个的特点叫做on-policy。
蒙特卡洛采样中的Importance Sampling(重要性采样)告诉我们,当分布\(p(x)\)的期望很难求出来时,可以通过构造一个Reference分布\(q(x)\),在\(q(x)\)分布上采集样本\(x_1,x_2,\cdots,x_N\),每个样本粒子的权重为\(\displaystyle \frac{p(x_i)}{q(x_i)}\),那么就可以用\(q(x)\)分布上的样本来估计\(p(x)\)分布上的期望:
【比喻理解】
班上的老师是Critic网络,小明同学是Actor策略网络,而班上的其他同学也是策略网络。老师批评小明上课玩手机,那么小明为了不挨批评就会减小玩手机的概率。班上的其他同学看到小明被挨骂了,自然也会参考他的下场,从而减少玩手机的概率。小明玩手机的概率是40%,而小王玩手机的概率是20%,自然小王不需要像小明那样努力克制自己,只需要付出小明0.5倍(20% / 40%)的努力(幅度)来更新自己的网络参数。当然了,小明死不悔改(不更新参数),玩手机的概率仍然是40%,而小王玩手机的概率下降到了10%,因此小明再被批评的时候,被震慑住的小王只需要付出小明1/4倍的努力来戒掉手机。此时小王属于off-policy,即\(p(x)\),因为他只需要使用小明被老师骂的“样本”来更新自己的网络参数,不是自己被骂;而小明属于on-policy,即\(q(x)\),因为小明需要持续不断地接收老师的“样本”来不断地更新自己的参数。
重要性采样将on-policy转化为了off-policy,从而提高了数据的利用率。当然也不是将算法真的转换为了off-policy,只是让采集的数据能多用几个Iteration。
同样的道理,如果小明的学习成绩很好,被老师表扬;而小王的学习成绩很差,自然无法从老师的表扬中学习参考,接下来从哪个方向努力也是迷茫的;如果成绩相当,倒还是可以追平。如果比喻不恰当,凑合着理解吧。因此,\(p(x)\)和\(q(x)\)这两个分布的“实力”相差不要太悬殊,否则\(p(x)\)学习\(q(x)\)产生的样本会被带到沟里去(参数更新幅度太大)。
所以使用重要性采样的时候,需要给两个分布加以限制:采用KL散度衡量两个分布的差异性,KL散度越大说明分布差异越大。因而需要让KL散度小于一个阈值\(\delta\):
经过重要性采样,即在\(\pi_{\theta_{old}}\)(\(\pi_\theta\)更新参数前的分布)上采样\(N\)个轨迹样本来估计\(\pi_\theta\)分布上的期望,可以继续推导梯度估计:
将\(\nabla_\theta\)拿掉就是目标函数的近似。经过前面的铺垫,最终可以理解TRPO的目标以及约束为什么要这么写了:
- 期望上的hat符号表示这是一个估计值。
- KL散度非对称,顺序是\(\pi_{\theta_{old}},\pi_\theta\),反过来写呢❓
TRPO给出了这个复杂的带有KL约束的优化目标的解析解来估计梯度,但是求解该解析解仍然给计算机带来了不小的挑战:目标函数一阶Tayler展开得到梯度,KL约束二阶Tayler展开得到Hessian矩阵(RL称为Fisher信息矩阵),再通过共轭梯度法(Conjugate Gradient)计算搜索方向,进行线性搜索。
3 PPO算法原理
2017年OpenAI团队发表论文《Proximal Policy Optimization Algorithms》,提出Proximal Policy Optimization,近端策略优化算法。实际上就是TRPO的平替。
因为KL散度的二阶展开计算过于复杂,因此PPO采用截断替代目标(Clipped Surrogate Objective)来限制更新幅度,即最大化下列目标
其中\(\displaystyle r_t(\theta)=\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\)。\(\mathrm{clip}\)函数表示将比值\(r_t(\theta)\)限制在\((1-\epsilon,1+\epsilon)\)范围内,如果小于下界,则\(\mathrm{clip}=1-\epsilon\),如果大于上界则\(\mathrm{clip}=1+\epsilon\)。如果动作是好的,即\(\hat A_t>0\),则应该提高该动作的概率,如果\(\pi_\theta\)提升太多导致\(r_t(\theta)>1+\epsilon\),则强制锁定在\(1+\epsilon\),防止模型为了更新这个好动作而飘了;反之亦然,防止打压某个坏动作,保留探索性。
相比之下,TRPO的目的是最大化替代目标
CPI表示conservative policy iteration。实际上,KL散度约束项可以作为惩罚项写进公式中,那么目标变为了最大化如下替代函数
然而选择一个固定的惩罚系数\(\beta\)是非常困难的,会带来很多问题,因此原论文在实际操作过程中采取动态调节的方法,每次策略更新后都需要动态调整\(\beta\)的值,至于具体怎么调节这里就不展开讲了。总之工程中太麻烦了,基本上没什么人用这个方法,直接用\(L^{CLIP}(\theta)\)进行策略更新,直接将超出范围的梯度裁剪掉,写成Loss函数如下:
在深度学习框架中总是最小化Loss函数,因此在前面加一个负号。
4 人类反馈强化学习
《Training language models to follow instructions with human feedback》这篇论文通过人类反馈微调,使语言模型能够更好地遵循用户意图和指令,其核心方法是使用RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)对GPT-3进行微调。后来论文中的步骤成为RLHF的流程范式。具体有如下三个阶段:
-
SFT,让模型学会遵循指令。训练完成之后得到一个模型\(\pi^{SFT}\),这里的符号采用的是强化学习中的智能体的符号表示。
-
训练奖励模型,Reward Modeling(RM):人类给模型的回答打分。具体的操作如下
-
采样:让\(\pi^{SFT}\)对同一个prompt产生多个回答,比如生成4个回答A、B、C、D
-
标注:让数据标注工程师对这4个回答打分排序,B>A>D>C
-
将排序转化为成对的比较数据(pairwise comparisons):Label的构造形如\((y_w, y_l)\),\(y_w\)(win)是更好的回答,\(y_l\)(loss)是较差的回答。
-
训练奖励模型:通常是一个比生成模型小一点的、基于Transformer架构的模型,或者直接将SFT微调好的模型的最后一层换成一个线性层输出一个标量值,这是一种Bradley-Terry Model,损失函数可以设计为
\[L(\theta)=-\mathbb{E}_{(x,y_w,y_l)\sim D}[\log(\sigma(r_{\theta}(x,y_w)-r_{\theta}(x,y_l)))], \]其中\(r_{\theta}(x,y)\)是RM给出的分数;\(\sigma\)是sigmoid激活函数,将差值归一化;\(D\)表示人类偏好数据集,是一个三元组,\(x\)表示用户的提示词。对于数据采样而言,把期望去掉,loss就是一个批次的平均值。该loss的目的就是要最大化更好回答分数比较差回答分数高的概率,分差越大,loss越小。
-
-
使用PPO算法来优化大模型策略\(\pi_\theta\),使其生成的回答能获得奖励模型RM的高分。
大模型PPO强化微调应用
在LLM的RLHF场景下,Actor-Critic结构的PPO算法涉及4个模型:
- Actor,即Policy Model:我们要训练的模型\(\pi_\theta\),由\(\pi^{SFT}\)经过PPO训练得来;
- Critic,即Value Model:预测\(V(s)\),即“当前这句话写到这里,最终大概能得多少分”,用于计算Advantage;
- Reward Model:给Actor的回答打分;
- Reference Model:\(\pi^{Ref}=\pi^{SFT}\),参数需要冻结。用于KL散度约束,不要让模型微调跑偏太多。
在大语言模型语境下,输入给模型的prompt相当于初始状态\(s_0\),大模型输出每一个token都是每一步\(t\)所采取的动作\(a_t\),一个完整的轨迹\(\tau=(s_0, a_0, \cdots,s_T, a_T)\)是大模型一轮完整的上下文。所以PPO算法中所提到的\(\pi_\theta(a_t|s_t)\)就是token \(a_t\)的概率,\(t\)表示该序列的下标减prompt部分的长度。
举个例子🌰:输入prompt = [你, 是, 谁, ?],通过model.generate后输出完整的上下文full_ids = [你, 是, 谁, ?, 我, AI, <eos>],包括提示词部分和回答部分。实际上generate函数的输出是token id列表,这里为了解释而直接用token来替代。
假设词表中就只有这几个token,如图所示。要得到每个token的概率值,就得将full_ids直接输入给model。由于存在shifted right操作,因此得到的结果是大小为batch×seq×vocab_size的张量,为了方便解释,batch设置为1。seq×vocab_size这个矩阵表示full_ids中每个token预测的下一个token位置的概率分布。因此便得到了每一步所采取的action的概率。实际上只需要关心response部分的token概率,即图中黄色部分,在代码中通过mask来实现。

注意输入的full_ids是整个上下文,经过模型的输出token对应需要错位,即最后一行是对结束符<eos>后面一位token的预测,没用。
类似地,Critic网络结构可以和Actor一样,只不过最后一层的输出大小修改为batch×seq×1,seq维度的每一位表示当前动作的Value值。
最后在实际的工程实践中,算法的Loss为
其中\(L^{VF}\)是Critic网络的Value Function Loss,即MSE;而\(S\)部分是Entropy奖励,即希望模型保留一定的随机性,不要过早坍缩到某一个答案,为了训练稳定,通常省略熵项或设得极小。
算法流程:
-
环境采样Rollout:采样一批提示词\(x\),给Actor输出一批回答\(y\);
-
各方评审
(1)RM打分
最终的得分奖励Reward除了RM给出的一部分\(R(y,x)\),还需要带上KL散度惩罚项
$$
\mathrm{Reward}=R(x,y)-\beta D_{KL}(\pi_\theta(\cdot|x)||\pi^{Ref}(\cdot|x)).
$$
KL Penalty是为了防止Reward Hacking,即防止模型为了得到高分而生成一些人类看不懂的乱码或者过度讨好人类,必须强制Actor不能偏离原始的语言模型\(\pi^{Ref}\)太远。
从期望的角度来看
实际上,分布是采样得到的,实际的计算公式是期望里面的平均。因此在代码实现中,分数奖励减去的是一个log值,这是KL散度在采样下的表现形式。
注意,RM应该是对完整的response进行打分,而不是每输出一个token打一次分,所以将\(R(x,y)\)加到最后一个token的Reward上,而其他token只有KL Penalty这一项。
(2)Critic估算
GAE优势估计:Critic估计每一步的价值,得到一个更精确的回报估计值\(\mathrm{Reward}_{t+1}+\gamma V_{t+1}(s_{t+1})\),这个作为labels,和\(V_t(s_t)\)做一个MSE即可。
- PPO策略梯度更新Actor和Critic参数
一个Batch重复训练几个Epoch。经过一轮更新,根据更新后的模型重新采样多迭代训练几次。
参考代码
👉参考大模型PPO训练源码
上面的讲解是对代码的补充解释,可能写的内容仍然不完善、全面,需要结合下列代码慢慢理解。代码和上述解释可能有错误,我会保持更新、补充、修正。
下列代码是微调自己基于transformers框架标准构建的模型模块,包含XXXForCausalLM、XXXPretrainedModel、XXXConfig等,因此无法单独跑通。重点是train_ppo()中的操作流程,需结合上述的数学推导来理解。
除此之外,RM还需要单独训练,在下面的代码中仅仅做了初始化。因此私以为RLHF这条对齐路线非常非常麻烦,工程量巨大,自己强化训练小模型还是采用DPO这条路线。
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer
from torch.optim import AdamW
import numpy as np
from tqdm import tqdm
# 自定义模型模块
from model.model_slm import SLMPretrainedModel, SLMModel, SLMForCausalLM
from model.configuration_slm import SLMConfig
class SLMForSequenceClassification(SLMPretrainedModel):
def __init__(self, config: SLMConfig):
super().__init__(config)
self.num_labels = 1
self.model = SLMModel(config)
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
self.post_init()
def forward(self, input_ids, attention_mask=None, past_key_values=None, **kwargs):
# 1. 获取隐状态
outputs = self.model(input_ids, attention_mask=attention_mask, past_key_values=past_key_values)
hidden_states = outputs[0] # [batch, seq, dim]
# 对每个token打分:output shape: [batch, seq, 1]
scores = self.score(hidden_states)
return scores.squeeze(-1)
#########################################
# ▲ 数据处理
#########################################
class PPODataset(Dataset):
def __init__(self, prompts: list[str], tokenizer: AutoTokenizer):
self.prompts = prompts
self.tokenizer = tokenizer
def __len__(self):
return len(self.prompts)
def __getitem__(self, index):
return self.prompts[index]
def collate_fn(batch_prompts, tokenizer: AutoTokenizer, device: torch.device):
'''提示词左填充, 右对齐'''
tokenizer.padding_side = "left"
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
enc = tokenizer(batch_prompts, padding=True, return_tensors="pt").to(device)
return enc.input_ids, enc.attention_mask
#########################################
# ▲ 数学计算:log probability & gae
#########################################
def get_log_probs_and_values(model, input_ids, attention_mask, critic_model=None):
'''
序列每个token的log_probs和values
- log_probs: log pi_theta
- values: V_theta
'''
# Actor / Ref
outputs = model(input_ids, attention_mask=attention_mask, output_hidden_states=True)
logits = outputs.logits # (batch, seq_len, vocab)
log_probs = F.log_softmax(logits, dim=-1)
logits_seq = log_probs[:, :-1, :]
input_ids_seq = input_ids[:, 1:]
selected_log_probs = torch.gather(logits_seq, -1, input_ids_seq.unsqueeze(-1)).squeeze(-1)
# Critic forward
values = None
if critic_model is not None:
critic_outputs = critic_model(input_ids, attention_mask=attention_mask)
values = critic_outputs[:, :-1]
return selected_log_probs, values
def compute_gae(rewards, values, bootstrap_value, gamma, var_lambda, mask):
'''
rewards: (batch, seq) 包含KL penalty
values: (batch, seq)
bootstrap_value: (batch, 1) 最后一个token之后的估值
mask: (batch, seq) response部分为1, padding/prompt部分为0
'''
values_extended = torch.cat([values, bootstrap_value], dim=1)
gae = 0
advantages = torch.zeros_like(rewards)
seq_len = rewards.shape[1]
for t in reversed(range(seq_len)):
delta = rewards[:, t] + gamma * values_extended[:, t+1] - values_extended[:, t]
gae = delta + gamma * var_lambda * gae
# 只计算response部分的优势, prompt相当于初始state
advantages[:, t] = gae * mask[:, t]
returns = advantages + values
return advantages, returns
#########################################
# ▲ 训练主循环
#########################################
import os
import json
if os.path.exists("./config/ppo_config.json"):
with open('./config/ppo_config.json', 'r') as f:
CONFIG = json.load(f)
else:
CONFIG = None
def train_ppo():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(CONFIG["sft_model_path"])
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# ================= 加载4个网络 =================
actor = SLMForCausalLM.from_pretrained(CONFIG["sft_model_path"]).to(device)
ref_model = SLMForCausalLM.from_pretrained(CONFIG["sft_model_path"]).to(device)
ref_model.eval()
critic = SLMForSequenceClassification.from_pretrained(
CONFIG["sft_model_path"],
num_labels=1,
ignore_mismatched_sizes=True
).to(device)
# ❗❗需要单独训练, 这里仅仅作了初始化
reward_model = SLMForSequenceClassification.from_pretrained(
CONFIG["sft_model_path"],
num_labels=1,
ignore_mismatched_sizes=True
).to(device)
reward_model.eval()
opt_actor = AdamW(actor.parameters(), lr=CONFIG["lr_actor"])
opt_critic = AdamW(critic.parameters(), lr=CONFIG["lr_critic"])
dataset = PPODataset(CONFIG["prompt_data"] * 10, tokenizer) # 测试数据
dataloader = DataLoader(dataset, batch_size=CONFIG["rollout_batch_size"], shuffle=True)
# ================= 开始训练 =================
total_steps = 0
pbar = tqdm(total=CONFIG["total_episodes"])
while total_steps < CONFIG["total_episodes"]:
try:
batch_prompts = next(iter(dataloader))
except StopIteration:
dataloader = DataLoader(dataset, batch_size=CONFIG["rollout_batch_size"], shuffle=True)
batch_prompts = next(iter(dataloader))
# rollout
with torch.no_grad():
prompt_ids, prompt_mask = collate_fn(batch_prompts, tokenizer, device)
prompt_len = prompt_ids.shape[1]
# prompt + response
full_ids = actor.generate(
prompt_ids,
attention_mask=prompt_mask,
max_new_tokens=CONFIG["max_gen_len"],
do_sample=True,
top_k=50,
pad_token_id=tokenizer.pad_token_id
)
# response: 1, prompt/pad: 0. 因为batch 所以生成的时候右边会有padding
attention_mask = (full_ids != tokenizer.pad_token_id).long()
action_mask = torch.zeros_like(full_ids)
action_mask[:, prompt_len:] = 1
action_mask_seq = action_mask * attention_mask
action_mask_seq = action_mask[:, 1:] # 和log_probs对齐
old_log_probs, old_values = get_log_probs_and_values(actor, full_ids, attention_mask, critic)
ref_log_probs, _ = get_log_probs_and_values(ref_model, full_ids, attention_mask, None)
# Rewards = KL Penalty + RM Score, RM仅保存最后一个token的得分
rm_scores = reward_model(full_ids, attention_mask=attention_mask)
last_token_idx = attention_mask.sum(dim=1) - 1 # 最后一个非padding的idx -> shape=(batch)
env_rewards = rm_scores[torch.arange(rm_scores.size(0)), last_token_idx]
# KL Divergence = log_p - ref_log_p
kl_div = old_log_probs - ref_log_probs
rewards = - CONFIG["kl_coef"] * kl_div
# 环境奖励只加到最后一个token上, 因为是对整个回答的评价
last_token_idx_seq = torch.clamp(last_token_idx - 1, min=0)
for i in range(len(env_rewards)):
rewards[i, last_token_idx_seq[i]] += env_rewards[i]
# prompt部分的reward为0
rewards = rewards * action_mask_seq
old_values = old_values * action_mask_seq
# 计算GAE. bootsrap是序列结束后的价值, 通常是0或mask掉的value
bootstrap_value = torch.zeros((old_values.shape[0], 1)).to(device)
advantages, returns = compute_gae(rewards, old_values, bootstrap_value, CONFIG["gamma"], CONFIG["lambda"], action_mask_seq)
# 对response部分的优势归一化, 以训练稳定
valid_advs = advantages[action_mask_seq == 1]
adv_mean, adv_std = valid_advs.mean(), valid_advs.std()
advantages = (advantages - adv_mean) / (adv_std + 1e-8)
advantages = advantages * action_mask_seq
# ================= PPO Update =================
actor.train()
critic.train()
batch_size = full_ids.size(0)
indices = np.arange(batch_size)
# 用上面采集到的数据更新ppo_epochs次
for _ in range(CONFIG["ppo_epochs"]):
# 采样N个
np.random.shuffle(indices)
for start_idx in range(0, batch_size, CONFIG["mini_batch_size"]):
mb_idx = indices[start_idx : start_idx + CONFIG["mini_batch_size"]]
mb_ids = full_ids[mb_idx]
mb_attn_mask = attention_mask[mb_idx]
mb_action_mask = action_mask_seq[mb_idx]
mb_old_log_probs = old_log_probs[mb_idx]
mb_advantages = advantages[mb_idx]
mb_returns = returns[mb_idx]
new_log_probs, new_values = get_log_probs_and_values(actor, mb_ids, mb_attn_mask, critic)
ratio = torch.exp(new_log_probs - mb_old_log_probs)
surr1 = ratio * mb_advantages
surr2 = torch.clamp(ratio, 1.0 - CONFIG["clip_ratio"], 1.0 + CONFIG["clip_ratio"]) * mb_advantages
policy_loss = -torch.min(surr1, surr2).sum() / mb_action_mask.sum()
# Critic loss = (V_new - Return)^2
value_loss = F.mse_loss(new_values * mb_action_mask, mb_returns * mb_action_mask, reduction='sum') / mb_action_mask.sum()
# 总
total_loss = policy_loss + CONFIG["vf_coef"] * value_loss
opt_actor.zero_grad()
opt_critic.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_norm_(actor.parameters(), 1.0)
torch.nn.utils.clip_grad_norm_(critic.parameters(), 1.0)
opt_actor.step()
opt_critic.step()
total_steps += batch_size
pbar.update(batch_size)
pbar.set_postfix({"loss": total_loss.item(), "reward": env_rewards.mean().item()})
print("✅ 完成PPO")
actor.save_pretrained(CONFIG["output_dir"])
模型路径和超参数配置如下:
{
"sft_model_path": "./out",
"output_dir": "./out/ppo_model",
"prompt_data": ["你好", "哈喽"],
"ppo_epochs": 4,
"mini_batch_size": 2,
"rollout_batch_size": 2,
"total_episodes": 100,
"lr_actor": 1e-5,
"lr_critic": 5e-5,
"gamma": 0.99,
"lambda": 0.95,
"clip_ratio": 0.2,
"kl_coef": 0.02,
"vf_coef": 0.1,
"max_gen_len": 50
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号