
大模型基石——Transformer架构深度解构
2017年的《Attention Is All You Need》开辟了大语言模型时代。本文将从原理部分出发,剖析模型的设计思想,并且使用PyTorch搭建Transformer模型,训练一个机器翻译模型,以更深入理解Transformer结构。
1 词嵌入
将token转换为计算机能够理解的语言,这叫做词嵌入(Word Embedding)。即把一个token映射到词向量空间中,用一个高维度的向量来表示。在统计机器学习时代,词向量使用独热编码、词袋等模型来表示,但这些模型并不能反映词语和词语之间语义的关联。
之后Word2Vec模型提出将token映射为静态的向量,不需要再考虑其在句子中的位置、上下文之间的关系。比如说将token映射到3维空间中,那么语义相近的词向量,方向也应该是相近的。如图所示以中文token为例,token“善”和“好”都是正面的词汇,映射在第一卦限中;“恶”是负面的词汇,和前面两个token的语义完全相反,距离更远,因此其方向是相反的,比如在第八卦限中。
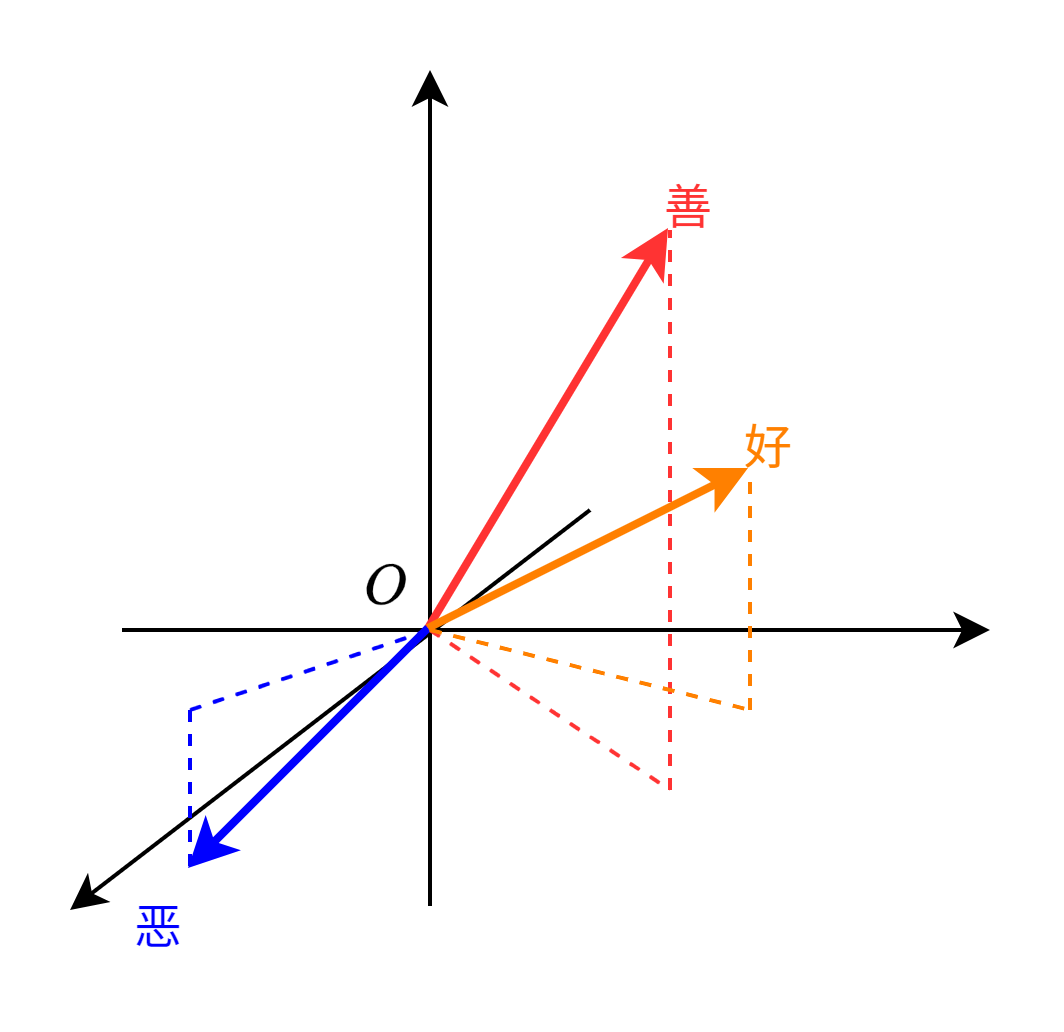
一个词也不仅仅有语义之间的差别,还有词性,如动词、名词之间的差别。因此,低维度的向量无法充分表示token之间各种各样的关系,词嵌入一般将一个token映射到一个高维度空间中,向量之间的距离代表token之间语义、词性等的关系。
Word2Vec通过大量的语料来单独训练出一个词嵌入模型,将token转换为静态的高维度的向量。而Transformer的做法是将词嵌入模型和语言模型放在一起训练,模型参数更新的同时也调整词嵌入向量的方向,让模型在语料中自行学习token之间的关系,并适配所训练的模型。
将token映射到维度大小为\(d_{model}\)的向量空间中,基于此将一个长度为\(S\)(seq_len = S)的序列映射为一个矩阵,记作\(\boldsymbol E_{token}\in\mathbb{R}^{S\times d_{model}}\)。注意\(\boldsymbol E_{token}\)是可学习的参数。
位置编码 Positional Encoding
尽管后续的大模型并未采用Transformer的静态正余弦位置编码(采用的是旋转位置编码),但位置编码仍为后续模型的设计提供了思路。Transformer的正余弦静态编码的思路就是对每个词的位置向量,奇数位采用余弦值生成,偶数位采用正弦值生成,位置向量的维度和词嵌入的向量维度一样,皆是\(\mathbb{R}^{d_{model}}\):
式中\(\text{pos}\)表示这个token在原序列中的位置,下标从\(0\)开始算。记位置编码矩阵为\(\boldsymbol E_{pos}\),该矩阵的值是静态不变的。
综上,Transformer的输入是\(\boldsymbol X=\boldsymbol E_{pos}+{\color{red} \boldsymbol E_{token}}\),标红部分的值是随着模型的训练而动态调整的。
2 注意力机制
回顾Seq2Seq
回忆一下Seq2Seq模型结构,比如使用Seq2Seq完成一个机器翻译的模型训练任务,Encoder负责理解和总结待翻译的序列(上文),经过RNN的最后一个时间步的隐藏层输出,作为上下文向量(Context Vector)\(\boldsymbol C\)输入给Decoder。如图所示,比如我要将“你好呀”翻译为“Nice to meet you”,首先我要将两个序列进行分词得到一个一个的token,然后再将其映射到高维的词向量空间中。
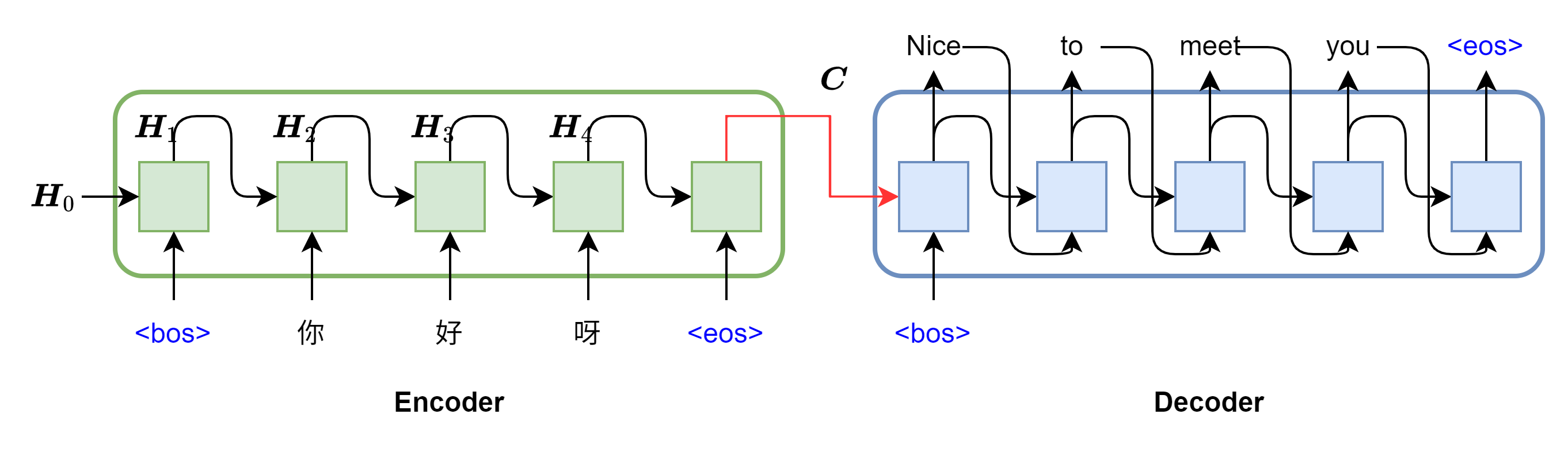
中文语句分词为['<bos>', '你', '好', '呀', '<eos>'],这里为了画图方便,省略了句号,句号也应该作为一个单独的token。此外,序列还加上了两个特殊的token,用于表示句子的开头和结尾。Encoder将分词后的序列中的语义提取出来,归纳总结为一个向量,然后输入给Decoder作为上文的参考,Decoder根据上文的语义信息来进行推理预测:一切句子的开头都是<bos>这个特殊的token,经过上文的提示,第一个时间步预测出“Nice”,并将“Nice”的词向量和当前时间步的隐藏层输出作为下一个时间步的输入。直到输出预测的序列长度达到设定的最大值或预测输出句子的结尾token<eos>。
注意力思想
在Encoder中,无论输入序列有多长,终究都要被压缩为一个固定维度的向量,这个过程不可避免地导致信息的损失。Decoder序列过长的时候,网络会遗忘上文信息,因此在生成下一个token的时候,要时不时回头看一下原序列的相关内容。就好比做阅读理解,针对一个选择题,需要在原文的信息强相关的段落去找答案,而不是把整篇文章读一遍再去选择答案,这样会造成注意力涣散,难以做出正确的选择,即我需要将注意力放在解决当前问题的上文段落中。因此在每个时间步的输入,需要添加一个关于上文的注意力向量。对于时间步\(j\)来说,可以想到使用加权的方法得到注意力向量:
其中,\(S\)表示Encoder输入序列的长度,表示时间步\(j\)的输出和第\(i\)个token的相关性,且\(\displaystyle \sum_{i=1}^S\alpha_{ij}=1\)。相关性越大,表示Deocder时间步\(j\)的输出答案应该去Encoder的第\(i\)个时间步的隐藏层输出(提取了第\(i\)个输入token和其上文的语义信息)的信息里面找,即\(\alpha_{ij}\)越大。那么如何知道上文中哪些信息很相关呢?上面提到的词嵌入给出了答案。token的语义、词性等属性越相近,其词向量在向量空间中就越接近,那么它们的点积就越大。因此对于Encoder输入序列\(\boldsymbol X=(\boldsymbol x_1^T,\cdots, \boldsymbol x_S^T)^T\),Decoder的第\(j\)个时间步的token输入\(\boldsymbol y_j\)来说,加权系数(这里也可以叫做注意力分数)计算可以是
其中,词向量采用计算机中的标准来表示,即行向量是一维的,列向量是特殊的二维矩阵。一般来说,Encoder和Decoder的词嵌入向量维度是一样的,若不一样,则需要经过线性映射再进行点积:\(e_{ij}=\boldsymbol x\boldsymbol W\boldsymbol y^T\)。之后再进行归一化,一般采用Softmax方法:
这就是2015年《Effective Approaches to Attention-based Neural Machine Translation》提出的Luong Attention(也叫做Multiplicative Attention)。你可以通过向量拼接的方式将注意力向量输入到Decoder中:\((\boldsymbol y_j, \boldsymbol a_j)\)。维度翻倍,这时候只需要将RNN中的线性变换矩阵的某一维度也翻倍即可。怎样输入注意力矩阵并不重要,重要的是知道注意力的目的和计算方式。
自注意力机制 Self-Attention
通过Luong Attention的学习,我们知道一个token想要注意到上文信息对自己重要的部分,需要有3种向量参与运算:上文序列的词向量\(\boldsymbol x_i\ (1\le i\le S)\),第\(i\)个时间步经过RNN上文语义信息提取的隐藏层输出\(\boldsymbol h_i\),以及Decoder当前时间步\(j\)的输入token词向量\(\boldsymbol y_j\)。由于RNN的第\(t\)个时间步需要等待上一个时间步\(t-1\)的输出,导致模型的训练和推理是串行执行的,速度非常慢。因此Transformer提出Self-Attention,使模型的训练和推理能够并行执行,下一个token的输出不再依赖于上一个token的输入。
具体的做法就是将输入token \(\boldsymbol x_i\ (\in\mathbb{R}^{d_{model}})\)映射为3个向量:\(\boldsymbol q_i, \boldsymbol k_i, \boldsymbol v_i\ (\in\mathbb{R}^{d_{model}})\)。先解释一下这三个向量的含义:
- \(\boldsymbol q_i\)表示query,询问上文中哪些语义、文本信息是值得注意的,相当于上面提到的\(\boldsymbol y_j\);
- \(\boldsymbol k_i\)表示key,相当于上一段提到的\(\boldsymbol x_i\)(不是本段的),是上文序列的词向量;
- \(\boldsymbol v_i\)表示value,相当于提取上文序列词向量\(\boldsymbol k_i\)信息的隐藏层\(\boldsymbol h_i\)。
这三个向量的来源是一致的,即\(\boldsymbol x_i\),只不过线性变换不同:
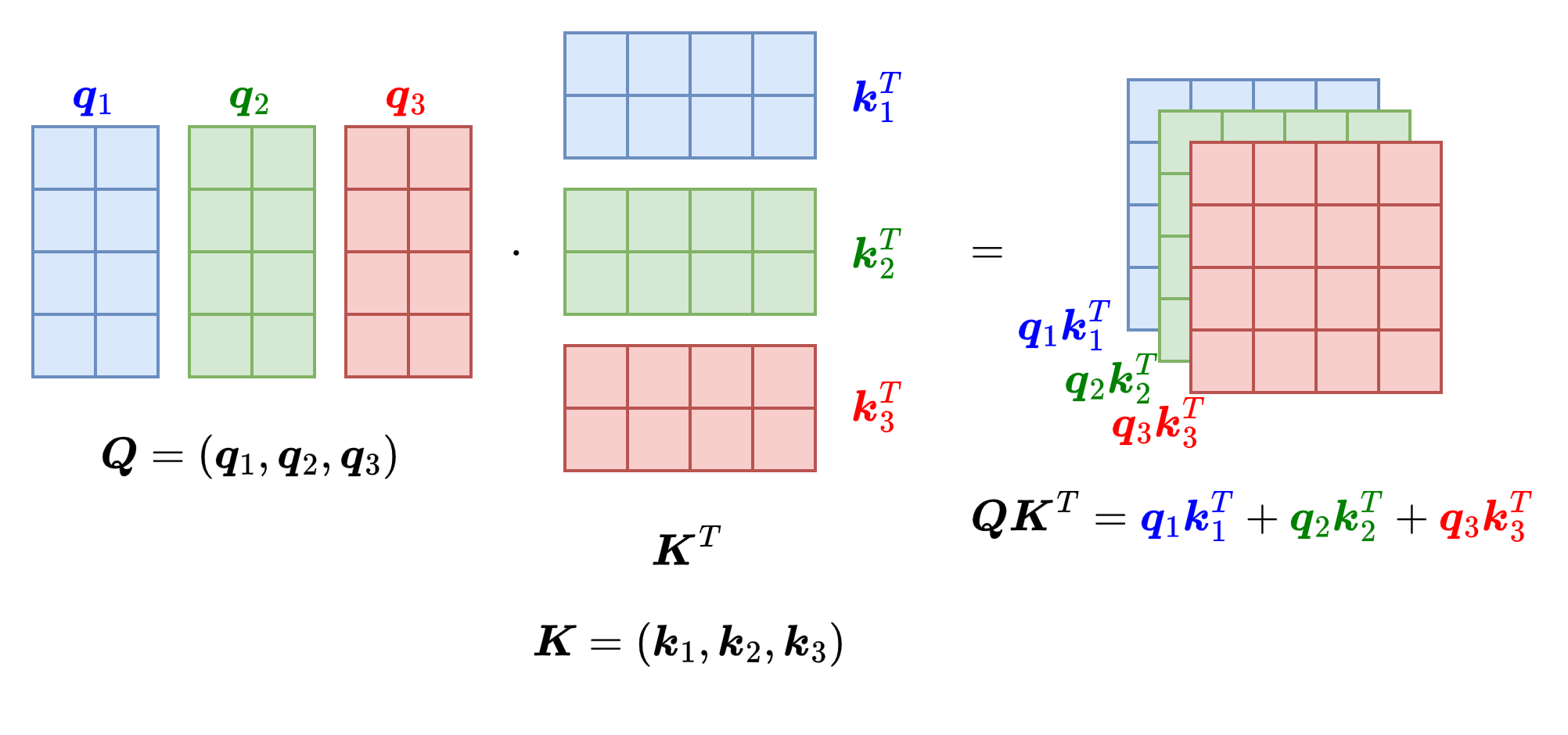
token和下标\(i\)一一对应。那么\(\boldsymbol q_i, \boldsymbol k_i, \boldsymbol v_i\)凭什么能够对应上计算注意力的3个向量呢?实际上,\(\boldsymbol q_i, \boldsymbol k_i, \boldsymbol v_i\)是线性映射得到的,映射空间\(\boldsymbol W^Q, \boldsymbol W^K, \boldsymbol W^V\ (\in\mathbb{R}^{d_{model}\times d_{model}})\)需要模型自己去学习,让模型在训练过程中理解这种注意力的思想。因此需要构造出注意力计算的流程,才能让模型学习到。将向量组装成矩阵来进行计算,如下图所示,让token的注意力放在自身上下文当中,这就是Self的由来。
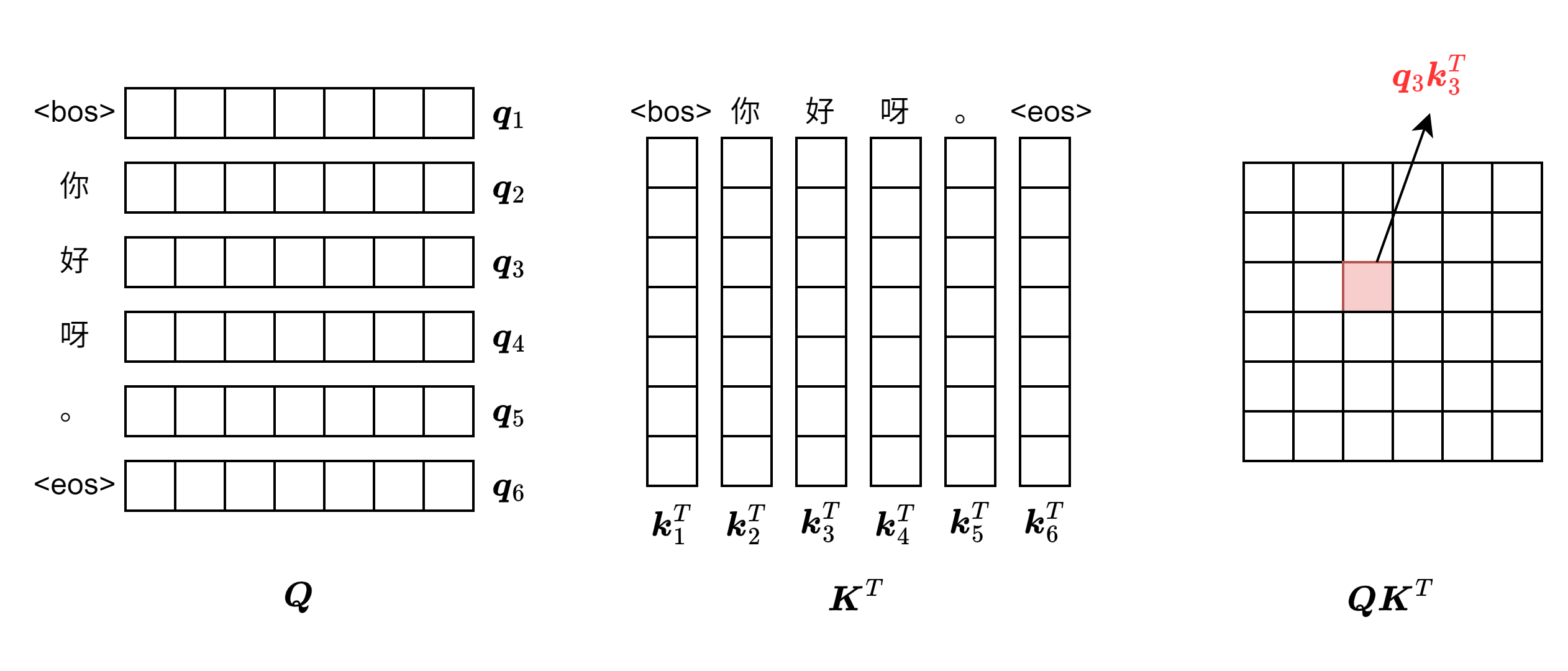
经过点积计算,可以得到每个token在自身上下文中的注意力分数矩阵\(\boldsymbol Q\boldsymbol K^T\)。由于模型对参数的大小非常敏感,论文首先采用缩放点积注意力(Scaled Dot-Product Attention)的方式对注意力分数进行缩放,然后再进行Softmax,最后和语义信息矩阵\(\boldsymbol V\)相乘,得到注意力矩阵:
在这里\(d_k=d_{model}\),\(\boldsymbol Q, \boldsymbol K, \boldsymbol V\in\mathbb{R}^{S\times d_{model}}\)。注意力矩阵\(\text{Attention}(\boldsymbol Q, \boldsymbol K, \boldsymbol V)\in\mathbb{R}^{S\times d_{model}}\),意味着第\(i\)行的向量是第\(i\)个token的注意力向量,因为乘\(\boldsymbol V\)是加权求和的过程(将\(\boldsymbol V\)的所有行向量加权求和)。
掩码机制 Masked Self-Attention
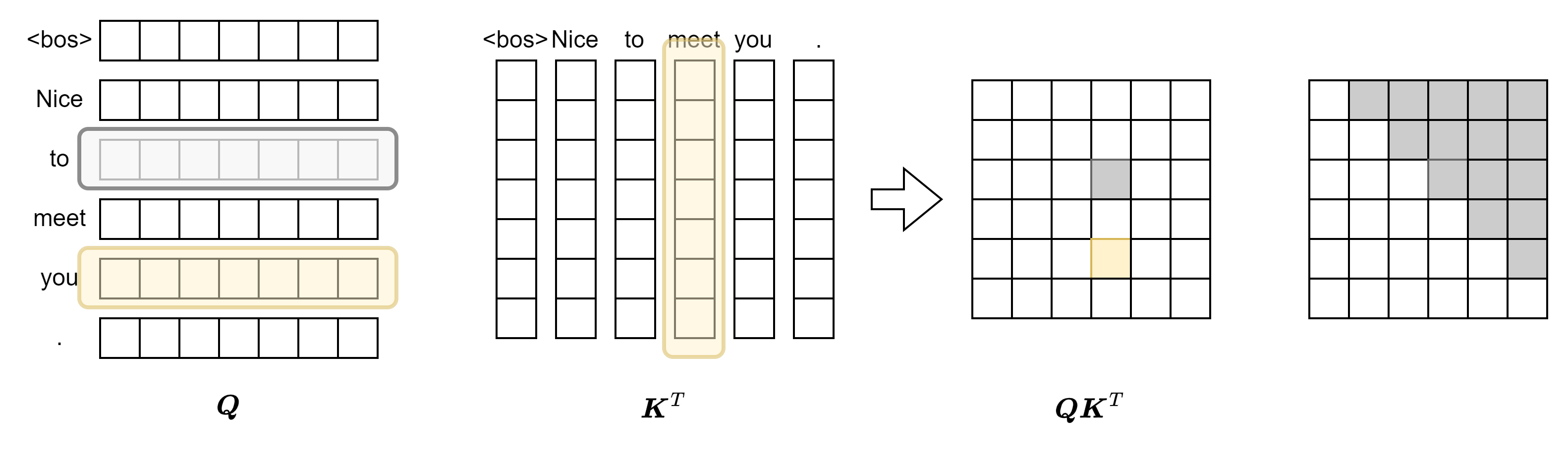
在Decoder阶段,需要使用序列['<bos>', 'Nice', 'to', 'meet', 'you', '.']预测输出['Nice', 'to', 'meet', 'you', '.', '<eos>']。即通过上文来预测下文,这并不是做一个“完形填空”的NLP任务,因此一个token就不能注意到它所有的上下文了。具体来讲,to只能注意到Nice和<bos>,而不能注意到meet和you,否则模型在训练的过程中会发现,将注意力放在后文能够更快地降低损失,导致过拟合。这就相当于在考试的过程中给模型提供答案。因此,我们希望token对于后文的注意力分数为0。如图所示,灰色代表值为0(或者极小),黄色代表值非0,在Query矩阵中,to对应的query向量不能注意到meet,而you可以,在对应的注意力分数矩阵中的值分别为0和非0。依此类推,所有的token只能注意到其自身上文的token,最终得到的注意力分数矩阵的上三角(不含对角线)应该均为0。可以用一个掩码矩阵对\(\boldsymbol Q\boldsymbol K^T\)按位相乘来实现掩码。
多头注意力机制 Multi-Head Attention
经过自注意力机制,输入输出的并行已经提高了训练和推理的速度。然而,这还不够快。基于数学原理,在\(d_{model}\)维度上做切分。举一个例子,\(d_{model}=6\),将这个维度切分成3个部分,\(\boldsymbol Q, \boldsymbol K, \boldsymbol V\)都是同样的操作。得到如图所示的蓝、绿、红三个部分,相同颜色的矩阵做乘法,分别得到注意力分数矩阵的一部分,这些零散的部分相加就是完整的注意力分数矩阵。上述的这些矩阵乘法操作在GPU上可以并行执行。因此,蓝、绿、红是3个不同的头(Head),这几个头并行做相同的操作。
一般而言,\(d_{model}\)能够被头的个数\(h\)整除,\(\boldsymbol Q, \boldsymbol K, \boldsymbol V\)的维度则变为了\(\mathbb{R}^{S\times h\times d_k}\),其中\(d_k=d_{model} / h\)。这几个头能够并行执行,因此将头这个维度放在最外层,也就是\(\mathbb{R}^{h\times S\times d_k}\),即\(h\)个大小为\(\mathbb{R}^{S\times d_k}\)的矩阵同时做相同的操作(矩阵乘、掩码)。由数学推导,要得到和没有进行多头切分的计算结果,\(\boldsymbol V\)不应该进行多头处理,那么为什么这里计算注意力矩阵的每个头是
而不是\(\displaystyle \text{head}_k=\text{Sofrmax}(\frac{\boldsymbol q_k\boldsymbol k_k^T}{\sqrt{d_k}})\boldsymbol V\)?实际上,多头注意力不仅仅实现了并行计算注意力,而且通过将输入映射到多个不同的子空间,增强模型捕捉不同语义关系的能力,比如说第一个头的子空间(\(\in\mathbb{R}^{d_k}\))代表词性,第二个头的子空间代表token含义......这些子空间的含义在训练过程中让模型自己学习。
由于\(\boldsymbol q_k\boldsymbol k_k^T\)的大小不变,因此做掩码的时候,几个头是并行mask的。在并行计算完成以后,需要将维度还原为\(\mathbb{R}^{S\times d_{model}}\),即完成头的拼接:\(\text{Concat}(head_1,\cdots,head_h)\)。在此之后还需要做一个线性变换(线性变换的参数\(\boldsymbol W^O\)是可学习的),得到最终的多头注意力矩阵:
3 层归一化 Layer Normalization
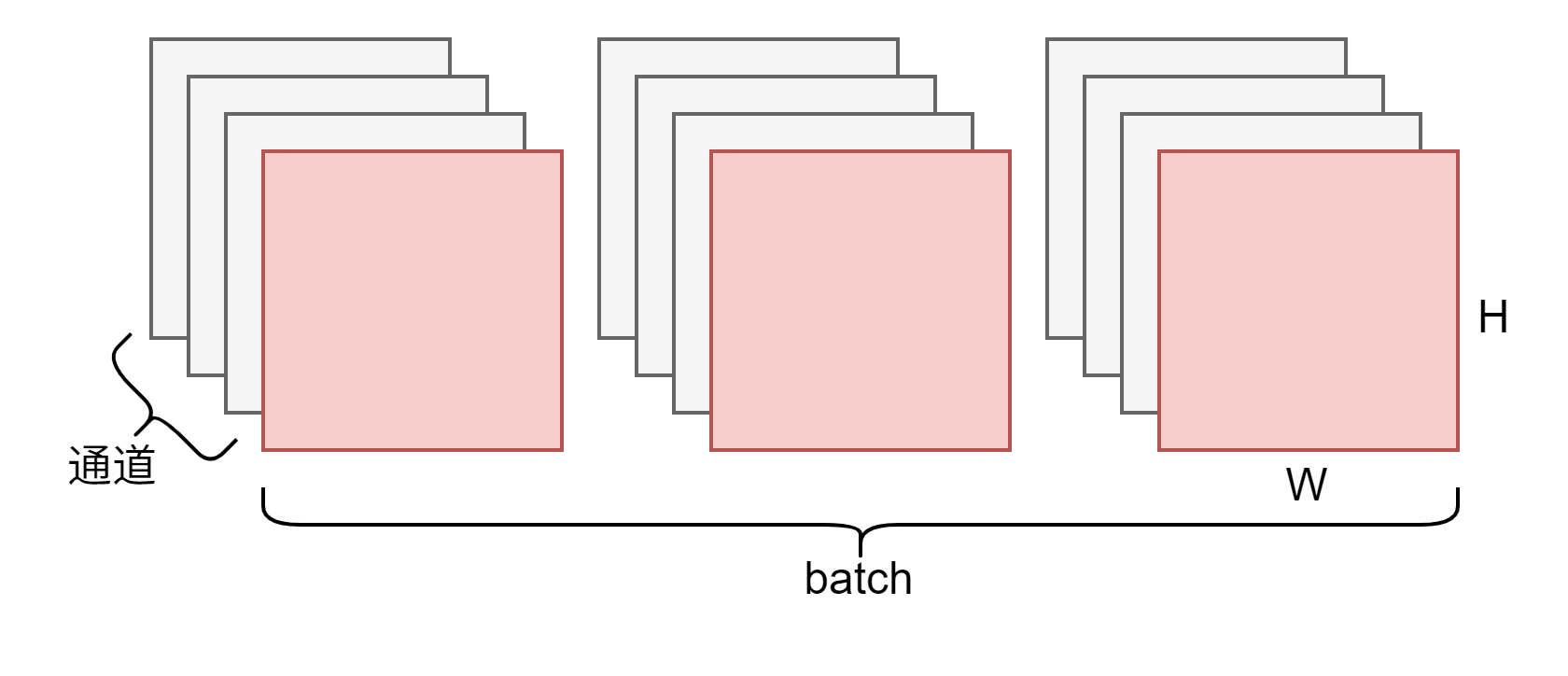
简单回顾一下在CNN卷积神经网络中的批归一化(Batch Normalization)。如图所示,以一个Batch中的每个特征图的同一个通道为单位进行归一化,即计算图中红色部分的所有数据的均值和方差。
2016年《Layer Normalization》提出层归一化,即以一张特征图(通道数×H×W)为单位进行归一化,和Batch没关系了。Transformer将这个思想引入到序列数据中:将通道Channel看作是一个token的特征维度\(d_{model}\),\(H\times W\)这一张特征图相当于token词向量中的一个特征,一共有\(d_{model}\)个这样的特征,因此Transformer中的Layer Norm是以一个token的特征向量(词向量)为单位进行层归一化。
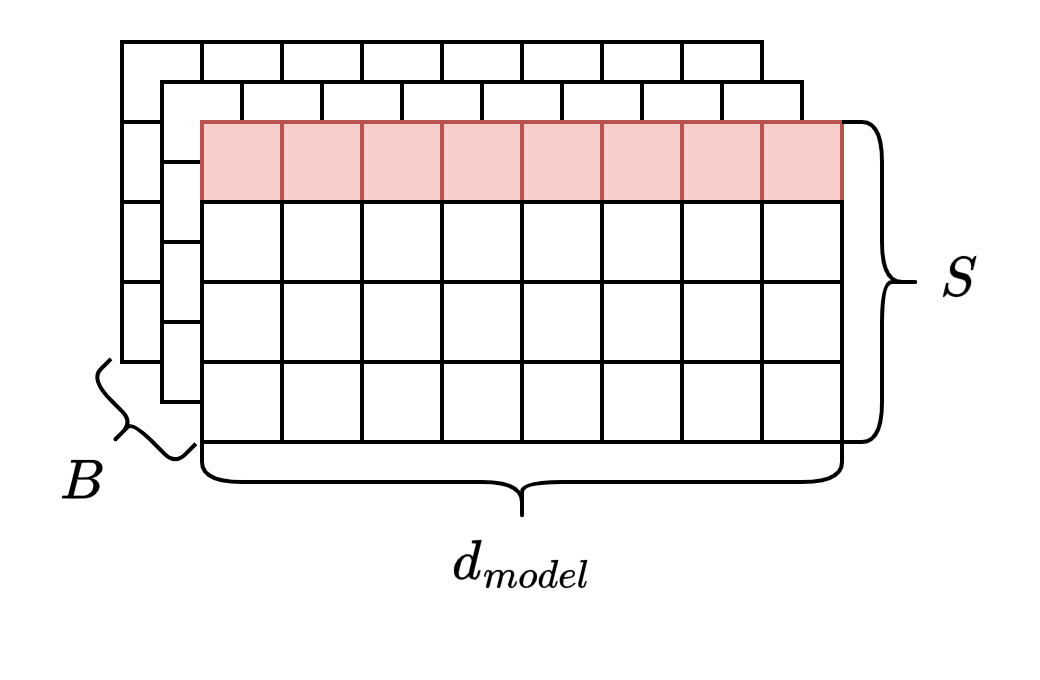
归一化(Layer或Batch)的具体流程是计算一个单位\(\boldsymbol x=(x_1,\cdots,x_{d_{model}})\)中的均值\(E(\boldsymbol x)\)和方差\(D(\boldsymbol x)\),然后再对每个值进行线性变换(缩放和平移),得到每个数值的归一化
其中线性变换的参数\(\gamma_i\)和\(\beta_i\)是可学习的参数,随着模型的训练一起调整。有时候分母还写作\(\sqrt{D(\boldsymbol x)+\epsilon}\),这个并没有关系。
Layer Normalization的线性变换参数\(\boldsymbol\gamma,\boldsymbol\beta\)和序列长度、批次大小都没有关系,因此保证了训练和推理时的计算行为一致。
4 用PyTorch组装起来
Transformer主要的思想和重要的结构已经讲解完毕,接下来我们使用PyTorch搭建一个Transformer网络。首先查看论文中所给出的模型结构:
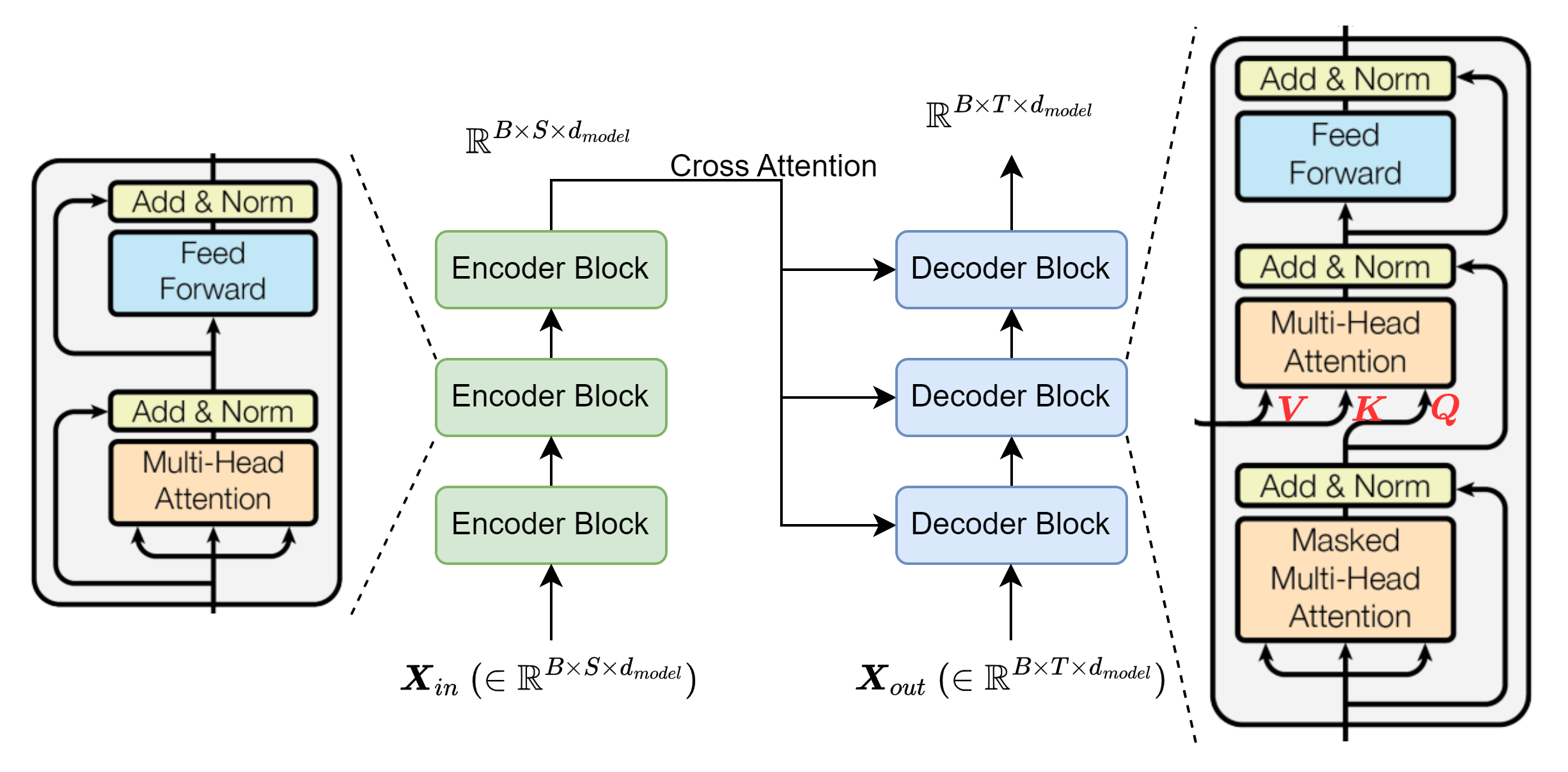
训练的过程中一般都是以批次为单位,批次大小为batch_size = B,这就意味着\(B\)个大小相同的序列\(S\times d_{model}\)做相同的操作,因此图中Encoder Block的输入输出大小总是\(B\times S\times d_{model}\)。原论文图中的\(N\)表示Encoder Block的个数。Encoder模块最后一层的输出作为所有Decoder Block的交叉注意力输入,输入到MHA的value和key的位置,这和Seq2Seq的含义相同,编码器将源序列(Source Sequence)的信息压缩到大小为\(S\times d_{model}\)的矩阵中,作为目标序列(Target Sequence)的“查询”对象。
与此同时,Decoder的输入和输出的大小一样,与Encoder类似,只不过序列长度记作\(T\)。但是实际上\(S=T\),如果序列长度不一样的话,矩阵乘法就不能对应上了。所以需要将源序列和目标序列的长度填充至最大值。
1. MHA

图中有3个注意力模块(橘黄色方块),每个模块的操作是一样的,只不过在输入和输出、是否添加掩码这几个方面不同。将该操作总结到一个网络模块中:
import math
import torch
import torch.optim as optim
class MHABlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float):
super().__init__()
self.d_model = d_model
self.h = h
assert d_model % h == 0, "h 无法整除 d_model"
self.d_k = d_model // h
self.WQ = nn.Linear(d_model, d_model, bias=False)
self.WK = nn.Linear(d_model, d_model, bias=False)
self.WV = nn.Linear(d_model, d_model, bias=False)
self.WO = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
@staticmethod
def attention(Q: torch.tensor, K: torch.tensor, V: torch.tensor, mask, dropout: nn.Dropout):
# Q, K, V: (B, h, S, d_k)
d_k = Q.shape[-1]
attn_scores = (Q @ K.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
attn_scores.masked_fill_(mask == 0, -1e9)
attn_scores = attn_scores.softmax(dim=-1)
if dropout is not None:
attn_scores = dropout(attn_scores)
return attn_scores @ V
def forward(self, XQ: torch.tensor, XK: torch.tensor, XV: torch.tensor, mask):
# 多头拆分 (B, S, d_model) ==> (B, S, h, d_k) ==> (B, h, S, d_k)
Q = self.WQ(XQ)
K = self.WK(XK)
V = self.WV(XV)
Q = Q.view(Q.shape[0], Q.shape[1], self.h, self.d_k).transpose(1, 2)
K = K.view(K.shape[0], K.shape[1], self.h, self.d_k).transpose(1, 2)
V = V.view(V.shape[0], V.shape[1], self.h, self.d_k).transpose(1, 2)
attn = MHABlock.attention(Q, K, V, mask, self.dropout)
# 多头合并 contiguous()感觉是深拷贝的意思
attn = attn.transpose(1, 2).contiguous().view(attn.shape[0], -1, self.d_model)
return self.WO(attn)
- 在多头注意力机制中,大小为\(B\times h\times S\times d_k\)的张量计算表示\(B\times h\)个\(S\times d_k\)矩阵并行计算。
- 如果没有传入mask矩阵,即
mask = None,则表示不进行掩码操作。
2. Layer Norm
将gamma和beta定义为可学习的参数,保留最后一个维度,即keepdim=True,方便PyTorch广播。
class LayerNorm(nn.Module):
def __init__(self, features: int, eps: float=1e-6):
super().__init__()
self.eps = eps
self.gamma = nn.Parameter(torch.ones(features))
self.beta = nn.Parameter(torch.zeros(features))
def forward(self, x):
# x (B, S, d_model)
# 在代码表示中 d_model = hidden_size = features
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True) # (B, S, 1)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
3. Positional Encoding
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int, dropout: float):
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len, d_model)
# 大小为d_model的行向量, 再添加一个维度使之变成列向量
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1)
div_term = torch.pow(10000.0, -torch.arange(0, d_model, 2, dtype=torch.float) / d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 在 batch_size 维度上广播
# 注册为一个buffer, 不会参与训练, 但会随模型一起被保存到GPU中
self.register_buffer('pe', pe)
def forward(self, x):
x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False)
return self.dropout(x)
4. Feed Forward
前向传播模块很简单,先升维,将\(d_{model}\)映射到\(d_{ff}\)空间中,然后再降维回\(d_{model}\),类似于计算机视觉中上采样和下采样的过程。
class FFNBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, d_ff), nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model)
)
def forward(self, x):
return self.net(x)
5. 组装Encoder*
class EncoderBlock(nn.Module):
def __init__(self, features: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.mha_block = MHABlock(d_model=features, h=num_heads, dropout=dropout)
self.ffn_block = FFNBlock(d_model=features, d_ff=d_ff, dropout=dropout)
self.norm1 = LayerNorm(features)
self.norm2 = LayerNorm(features)
self.dropout = nn.Dropout(dropout)
def forward(self, x, src_mask):
# Pre-Norm
_x = self.norm1(x)
x = x + self.dropout(self.mha_block(_x, _x, _x, src_mask))
_x = self.norm2(x)
x = x + self.dropout(self.ffn_block(_x))
return x
class Encoder(nn.Module):
def __init__(self, num_layers: int, features: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.layers = nn.ModuleList([EncoderBlock(features, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, x, src_mask):
for layer in self.layers:
x = layer(x, src_mask)
return x
Pre-Norm和Post-Norm是两种不同的Layer Normalization和Residual Connections组合方式。它们在Transformer模型中有着不同的应用和效果。
原始的Transformer论文中使用的是Post-Norm结构:
y = Norm(x + attn(x)) x_next = Norm(y + FFN(y))在训练深层网络时,存在梯度容易爆炸、学习率敏感、初始化权重敏感等问题,需要大量调参和Warm up
而Pre-Norm:
y = x + attn(Norm(x)) x_next = y + FFN(Norm(y))这样训练更加稳定,收敛性更好,因此在大模型时代被广泛采用。但是也存在潜在的表示塌陷问题,即靠近输出位置的层会变得非常相似,从而对模型的贡献变小。
6. 组装Decoder
和Encoder结构类似
class DecoderBlock(nn.Module):
def __init__(self, features: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.mha_block = MHABlock(d_model=features, h=num_heads, dropout=dropout)
self.masked_mha_block = MHABlock(d_model=features, h=num_heads, dropout=dropout)
self.ffn_block = FFNBlock(d_model=features, d_ff=d_ff, dropout=dropout)
self.norm1 = LayerNorm(features)
self.norm2 = LayerNorm(features)
self.norm3 = LayerNorm(features)
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# Pre-Norm
_x = self.norm1(x)
x = x + self.dropout(self.masked_mha_block(_x, _x, _x, tgt_mask))
_x = self.norm2(x)
x = x + self.dropout(self.mha_block(_x, encoder_output, encoder_output, src_mask))
_x = self.norm3(x)
x = x + self.dropout(self.ffn_block(_x))
return x
class Decoder(nn.Module):
def __init__(self, num_layers: int, features: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.layers = nn.ModuleList([DecoderBlock(features, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return x
7. 搭建完整的模型
在此只是简单的实现,torch.nn中的实现只有Deocder和Encoder结构,不包含词嵌入和最终预测输出的部分。还有一些参数已经在前面的模块中写死了,比如Q、K、V的计算是否需要bias。
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size: int,
tgt_vocab_size: int,
d_model: int=512,
nhead: int=8,
num_encoder_layers: int=6,
num_decoder_layers: int=6,
dim_feedforward: int=2048,
dropout: float=0.1,
src_seq_len: int=512,
tgt_seq_len: int=512
):
super().__init__()
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.input_pe = PositionalEncoding(d_model, src_seq_len, dropout)
self.output_pe = PositionalEncoding(d_model, tgt_seq_len, dropout)
self.encoder = Encoder(num_encoder_layers, d_model, nhead, dim_feedforward, dropout)
self.decoder = Decoder(num_decoder_layers, d_model, nhead, dim_feedforward, dropout)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
self.d_model = d_model
def forward(self, src, tgt, src_mask, tgt_mask):
src = self.input_pe(self.src_embedding(src) * math.sqrt(self.d_model))
tgt = self.output_pe(self.tgt_embedding(tgt) * math.sqrt(self.d_model))
encoder_output = self.encoder(src, src_mask)
decoder_output = self.decoder(tgt, encoder_output, src_mask, tgt_mask)
output = self.fc_out(decoder_output)
return output
为什么这里的位置编码需要乘\(\sqrt{d_{model}}\)?
词嵌入层通常使用Xavier或Kaiming初始化,其权重方差设计为\(1/d_{model}\),若未进行缩放,则嵌入输出的方差为1,但点积后方差仍会膨胀至\(d_k\),因此输入Embedding应该先乘\(\sqrt{d_{model}}\),使嵌入输出的方差为\(d_{model}\),点积后再除\(\sqrt{d_k}\),将方差拉回1。
5 训练一个机器翻译模型
在写代码之前,必须搞清楚应当如何处理一个序列。数据处理的流程如下图所示。假设现在有两句话“衬衫的价格是9磅15便士。”以及“李华正在写作文。”,将这两句话作为一个批次输出,那么批次大小\(B = 2\)。对批次中的每一句话进行分词,图中以BERT中文分词器为例。接下来添加首位特殊token,用于判别句子的开始和结尾,并且以一个批次中的最大长度为准,将该batch中的所有句子填充到最大长度,便于构造出一个三个维度的张量用于计算。然后通过查询词汇表,将token转换成token id。最后进行词嵌入,每个id对应一个大小为$$d_{model}的向量,那么每个句子就用一张\(S\times d_{model}\)大小的矩阵表示(图中红色方框表示),一个批次中有\(B\)个这样的矩阵(图中有2个),于是得到Decoder或Encoder的一次输入\(\boldsymbol X\ (\in\mathbb{R}^{B\times S\times d_{model}})\)。
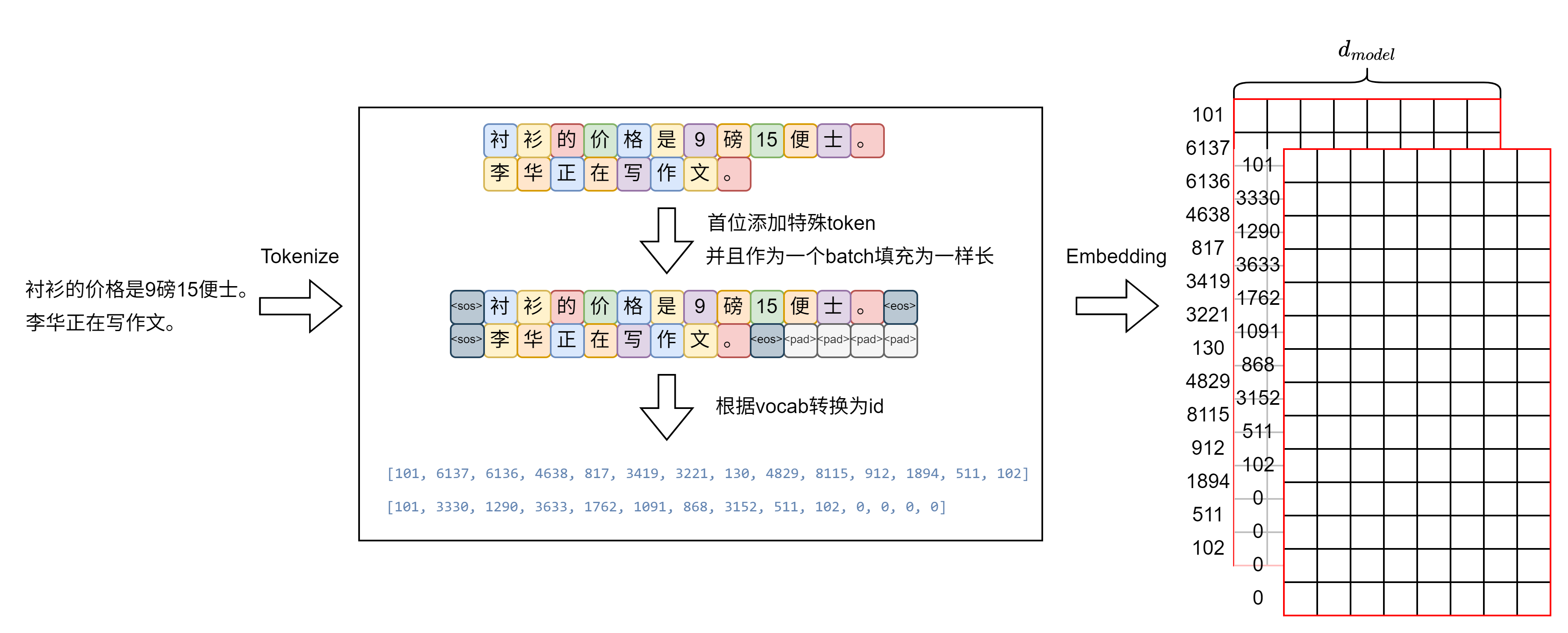
数据处理
首先准备数据集,中英文翻译的数据集比较难找,这里推荐translation2019zh数据集,在kaggle上就能搜索到。该数据集包含train和valid两个部分,train的大小大概是1.2G,其JSON数据包含格式为:{"english": "xxx", "chinese": "xxx"},有多个这样的JSON行。它并不是一个标准的JSON文件,而是每一行符合JSON格式。因此采用以下方式进行数据的处理:
from torch.utils.data import Dataset, DataLoader
import json
class TranslationDataset(Dataset):
def __init__(self, data_path, src_tokenizer, tgt_tokenizer, max_len=128):
self.data = self.load_data(data_path)
self.src_tokenizer = src_tokenizer
self.tgt_tokenizer = tgt_tokenizer
self.max_len = max_len
def load_data(self, path):
data = []
if not os.path.exists(path):
print(f"ERROR:文件 {path} 不存在")
return None
with open(path, 'r', encoding='utf-8') as f:
content = f.read().strip()
lines = content.split('\n')
for line in lines:
data.append(json.loads(line))
return data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
src_text = item.get('chinese', '')
tgt_text = item.get('english', '')
# BertTokenizer 会自动添加[CLS]和[SEP]来表示句子的起始和中止,在这里手动添加
src_encoding = self.src_tokenizer(src_text, truncation=True, max_length=self.max_len, add_special_tokens=False)
tgt_encoding = self.tgt_tokenizer(tgt_text, truncation=True, max_length=self.max_len, add_special_tokens=False)
# 获取 ID 列表
src_ids = src_encoding['input_ids']
tgt_ids = tgt_encoding['input_ids']
# 添加特殊 token (借用BERT的[CLS]作为SOS, [SEP]作为EOS)
sos_id = self.src_tokenizer.cls_token_id
eos_id = self.src_tokenizer.sep_token_id
return torch.tensor([sos_id] + src_ids + [eos_id], dtype=torch.long), \
torch.tensor([sos_id] + tgt_ids + [eos_id], dtype=torch.long)
本文的重点不在分词上,因此借用BERT分词器实现。在这里添加特殊的token<bos>(代码中写的是sos,begin和start都是一个意思)和<eos>是为了适用于其他分词器,比如自己训练的,手动添加特殊token。
接下来自定义Batch处理函数,在DataLoader中使用(collate_fn这个变量)。下面函数的目的就是将每个Batch中的源序列和目标序列填充到一样的长度,使用特殊token<pad>来填充。每个batch中填充后的序列长度可能是不一样的。
from torch.nn.utils.rnn import pad_sequence
def collate_fn(batch):
src_batch, tgt_batch = zip(*batch)
# 0是BERT tokenizer默认的pad_token_id
pad_idx = 0
# 填充序列 (Padding)
src_padded = pad_sequence(src_batch, batch_first=True, padding_value=pad_idx)
tgt_padded = pad_sequence(tgt_batch, batch_first=True, padding_value=pad_idx)
return src_padded, tgt_padded
掩码生成
掩码有两种:
src_mask:\(B\times 1\times 1\times S\),中间两个维度是为了在\(h\)和列方向上进行广播(下图最右图所示,当\(1\times d_{model}\)的矩阵和\(k\times d_{model}\)的矩阵做加法运算时,\(1\times d_{model}\)会将第一个维度的\(1\)扩展到\(k\)大小,即复制\(k\)行的向量)。所有的token都不能查询padding,也就是对padding形成注意力,所以\(\boldsymbol K^T\)的最后被padding的几列(图中灰色的部分)和\(\boldsymbol Q\)的所有行相乘得到的注意力分数为0(代码中是\inf),而<pad>可以对其他token形成注意力。所以只需要生成大小为\(d_{model}\times d_{model}\)、最后被padding的几列均为-inf(图中是最后两列)的掩码矩阵即可。
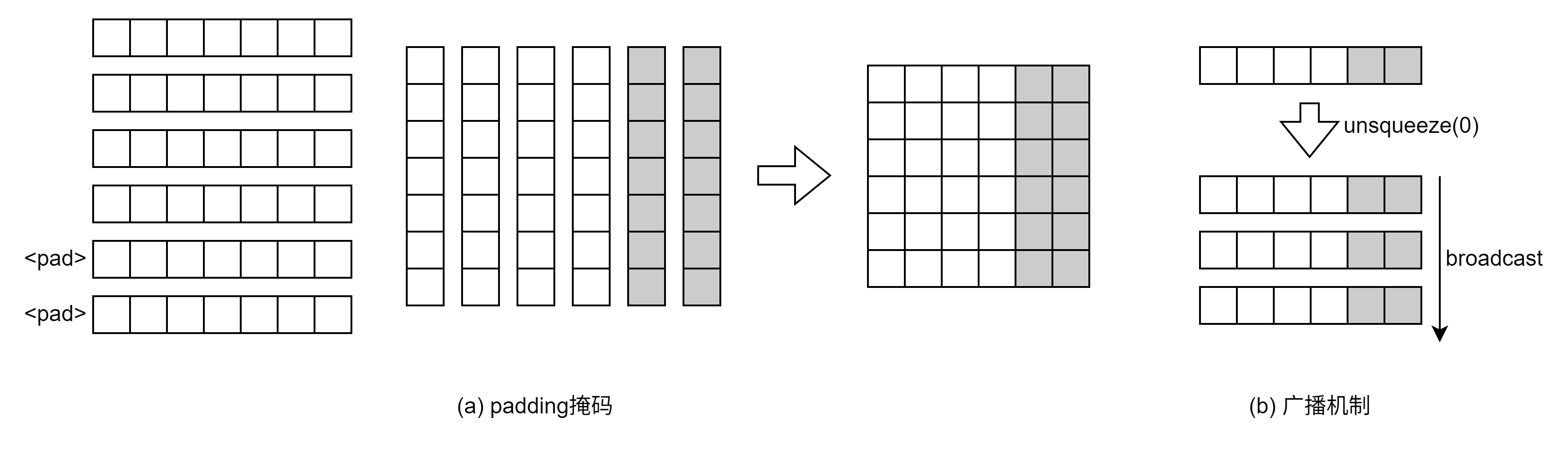
tgt_mask:\(B\times 1\times S\times S\),不仅需要上三角掩码,还需要对padding进行掩码。
def create_masks(src, tgt, pad_idx=0):
src_seq_len = src.shape[1]
tgt_seq_len = tgt.shape[1]
# (src != pad_idx) -> (B, S) -> unsqueeze -> (B, 1, 1, S)
src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2)
# 屏蔽pad: (B, 1, 1, T)
tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(2)
# 屏蔽未来 (Look-ahead): (1, 1, T, T)
# 下三角矩阵为1,其余为0
tgt_sub_mask = torch.tril(torch.ones((tgt_seq_len, tgt_seq_len), device=src.device)).bool()
# 两个矩阵结合
tgt_mask = tgt_pad_mask & tgt_sub_mask.unsqueeze(0).unsqueeze(0)
return src_mask, tgt_mask
训练
显卡:Kaggle上的P40有16G大小的显存。如果没有更好的计算资源,可以使用Kaggle免费提供的GPU。
首先配置参数:注意,如果在自己的系统上使用BERT分词器,需要安装Hugging Face维护的transformers库
class Config:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_data_path = "/translation2019zh/translation2019zh_train.json"
valid_data_path = "/translation2019zh/translation2019zh_valid.json"
# 训练超参数
batch_size = 32
num_epochs = 1
learning_rate = 0.0001
max_len = 128 # 限制最大句子长度
# 模型参数
d_model = 512
nhead = 8
num_encoder_layers = 3
num_decoder_layers = 3
dim_feedforward = 2048
dropout = 0.1
# 使用Hugging Face的BERT分词器
src_tokenizer_name = 'bert-base-chinese'
tgt_tokenizer_name = 'bert-base-uncased'
包装训练和评估模块
from tqdm import tqdm
def train(model, iterator, optimizer, criterion, clip, device):
model.train()
epoch_loss = 0
proc_bar = tqdm(iterator, desc="Training")
for i, (src, tgt) in enumerate(proc_bar):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:, :-1] # tgt输入: 去掉最后一个 token <eos>
tgt_output = tgt[:, 1:] # tgt输出(标签): 去掉第一个 token <sos>
src_mask, tgt_mask = create_masks(src, tgt_input, pad_idx=0)
optimizer.zero_grad()
output = model(src, tgt_input, src_mask, tgt_mask) # (B, T, tgt_vocab_size)
output_dim = output.shape[-1]
# 拉平
output = output.contiguous().view(-1, output_dim)
tgt_output = tgt_output.contiguous().view(-1)
loss = criterion(output, tgt_output)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
proc_bar.set_postfix(loss=loss.item())
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion, device):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, (src, tgt) in enumerate(iterator):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:, :-1]
tgt_output = tgt[:, 1:]
src_mask, tgt_mask = create_masks(src, tgt_input, pad_idx=0)
output = model(src, tgt_input, src_mask, tgt_mask)
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
tgt_output = tgt_output.contiguous().view(-1)
loss = criterion(output, tgt_output)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
开始训练
import torch.optim as optim
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["HF_HOME"] = "./model/"
from transformers import AutoTokenizer # 缓存和下载地址的配置都必须在导入这个包之前完成
src_tokenizer = AutoTokenizer.from_pretrained(Config.src_tokenizer_name)
tgt_tokenizer = AutoTokenizer.from_pretrained(Config.tgt_tokenizer_name)
train_dataset = TranslationDataset(Config.train_data_path, src_tokenizer, tgt_tokenizer, max_len=Config.max_len)
val_dataset = TranslationDataset(Config.valid_data_path, src_tokenizer, tgt_tokenizer, max_len=Config.max_len)
# 传入数据的同时填充序列到相同长度(按照批次中最长的那个序列)
train_loader = DataLoader(train_dataset, batch_size=Config.batch_size, shuffle=True, collate_fn=collate_fn)
val_loader = DataLoader(val_dataset, batch_size=Config.batch_size, shuffle=False, collate_fn=collate_fn)
model = Transformer(
src_vocab_size=src_tokenizer.vocab_size,
tgt_vocab_size=tgt_tokenizer.vocab_size,
d_model=Config.d_model,
nhead=Config.nhead,
num_encoder_layers=Config.num_encoder_layers,
num_decoder_layers=Config.num_decoder_layers,
dim_feedforward=Config.dim_feedforward,
dropout=Config.dropout,
src_seq_len=Config.max_len + 5,
tgt_seq_len=Config.max_len + 5
).to(Config.device)
# 初始化权重Xavier init通常对Transformer有效
def initialize_weights(m):
if hasattr(m, 'weight') and m.weight.dim() > 1:
nn.init.xavier_uniform_(m.weight.data)
model.apply(initialize_weights)
optimizer = optim.Adam(model.parameters(), lr=Config.learning_rate)
# 忽略<pad>的loss
criterion = nn.CrossEntropyLoss(ignore_index=0)
best_valid_loss = float('inf')
start_epoch = 0
for epoch in range(start_epoch, Config.num_epochs):
train_loss = train(model, train_loader, optimizer, criterion, 1.0, Config.device)
valid_loss = evaluate(model, val_loader, criterion, Config.device)
# 保存最佳模型
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'transformer_model.pt')
经过5个半小时才训练完一轮,loss在训练完30%的数据时才下降到3.0左右,训练完剩下的数据,loss下降到2.5左右。上述所有的代码可以直接按顺序复制到jupytor或者python文件中运行,建议在jupytor notebook中运行,因为它可以保存已经执行的状态。另外需要注意自己的GPU显存大小,对于16G的显存大小,batch size设置为32比较好,设置为64或者更大的时候可能会出现错误:CUDA out of memory。
Xavier初始化(又称Glorot初始化)是一种深度神经网络权重初始化方法,由Xavier Glorot和Yoshua Bengio在2010年提出,其核心目标是解决深度网络训练初期梯度消失或爆炸的问题,通过控制权重初始化的范围,确保信号在前向传播和反向传播过程中的方差稳定性。(后续完善)
推理
保证网络结构、参数配置和训练时的一样
def translate_sentence(sentence, src_tokenizer, tgt_tokenizer, model, device, max_len=128):
model.eval()
# 手动添加特殊token,因此add_special_tokens=False
tokens = src_tokenizer(sentence, truncation=True, max_length=max_len, add_special_tokens=False)['input_ids']
sos_idx = src_tokenizer.cls_token_id
eos_idx = src_tokenizer.sep_token_id
src_indices = [sos_idx] + tokens + [eos_idx]
src_tensor = torch.LongTensor(src_indices).unsqueeze(0).to(device) # (1, src_len)
# 屏蔽<pad>,这里batch=1且无pad,但为了兼容性还是加上。你也可以直接传入None
src_mask = (src_tensor != 0).unsqueeze(1).unsqueeze(2) # (1, 1, 1, src_len)
with torch.no_grad():
# 对应Transformer.forward中的: src = self.input_pe(self.src_embedding(src) * math.sqrt(self.d_model))
src_emb = model.src_embedding(src_tensor) * math.sqrt(model.d_model)
src_emb = model.input_pe(src_emb)
encoder_output = model.encoder(src_emb, src_mask)
# 自回归生成
tgt_indices = [sos_idx] # 初始输入只有<sos>
for i in range(max_len):
tgt_tensor = torch.LongTensor(tgt_indices).unsqueeze(0).to(device) # (1, current_tgt_len)
# Look-ahead mask (注意, 在推理的过程中实际上不需要掩码了, 因为Decoder的过程本来就是预测未来)
# tgt_len = tgt_tensor.shape[1]
# tgt_sub_mask = torch.tril(torch.ones((tgt_len, tgt_len), device=device)).bool() # (T, T)
# tgt_mask = tgt_sub_mask.unsqueeze(0).unsqueeze(0) # (1, 1, T, T)
with torch.no_grad():
# 对应Transformer.forward中的: tgt = self.output_pe(self.tgt_embedding(tgt) * math.sqrt(self.d_model))
tgt_emb = model.tgt_embedding(tgt_tensor) * math.sqrt(model.d_model)
tgt_emb = model.output_pe(tgt_emb)
output = model.decoder(tgt_emb, encoder_output, src_mask, tgt_mask)
# 通过全连接层映射到词表
output = model.fc_out(output)
# 获取最后一个时间步的预测结果 output shape: (1, T, tgt_vocab_size)
pred_token = output.argmax(2)[:, -1].item()
tgt_indices.append(pred_token)
# 预测出结束符<eos>则停止生成
if pred_token == eos_idx:
break
# ID转换回token, skip_special_tokens=True 会自动去掉特殊token
translated_sentence = tgt_tokenizer.decode(tgt_indices, skip_special_tokens=True)
return translated_sentence
自回归Auto-Regression:Decoder首先输入
<sos>,模型根据从Encoder中理解到的信息生成下一个token,比如it,将该token加入到Decoder输入中,得到下一个输入序列[<sos>, it],将这个序列作为Decoder的输入,预测得到下一个token's,再将该token加入到输入序列中得到[<sos>, it, 's]......如此循环,直到预测的下一个token是句子的截止符<eos>或者达到设定的序列最大长度。
展示:
src_tokenizer = AutoTokenizer.from_pretrained(Config.src_tokenizer_name)
tgt_tokenizer = AutoTokenizer.from_pretrained(Config.tgt_tokenizer_name)
# model = Transformer(...)
model_path = 'transformer_model.pt'
model.load_state_dict(torch.load(model_path, map_location=Config.device))
print("-" * 50)
print("Enter a Chinese sentence to translate (type 'q' to quit):")
print("-" * 50)
while True:
sentence = input("Chinese: ")
if sentence.lower() == 'q':
break
translation = translate_sentence(sentence, src_tokenizer, tgt_tokenizer, model, Config.device)
print(f"Chinese input: {sentence} ==> English: {translation}")
print("-" * 50)

可以发现,仅仅训练了一轮,就能达到不错的翻译效果。若想要量化语言模型的效果,可以选择BLEU等评价指标,在这里就不赘述了。但是最直观的判断模型效果的方法就是人的感受。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号