

第六次作业
作业一
-
要求
1.用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
2.每部电影的图片,采用多线程的方法爬取,图片名字为电影名
3.了解正则的使用方法
-
候选网站
豆瓣电影:https://movie.douban.com/top250
-
代码
import requests
from bs4 import BeautifulSoup
import re
import threading
import os
import urllib.request
import pymysql
class getmovie:
headers = {
"cookie": 'bid=dOfzqcoGwc8; douban-fav-remind=1; __yadk_uid=fs4EIYDm4ktLSzlMARMvkQW27iVjnCqI; __utmc=30149280; ll="108300"; _vwo_uuid_v2=DDA4784A3B42CB1A915A89AADDA47E88B|e5af71068eb42622bd7e996068f4f8fe; __gads=ID=ff90ca43368398de-22cd1195e3c40038:T=1606267810:RT=1606267810:R:S=ALNI_MbybazjMvXWrIHATGVK5Jvkql0ojg; push_noty_num=0; push_doumail_num=0; __utmv=30149280.22726; dbcl2="227263654:nW4OxOSmsbU"; ck=5PZt; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1606286052%2C%22https%3A%2F%2Faccounts.douban.com%2Fpassport%2Flogin%22%5D; _pk_ses.100001.8cb4=*; __utma=30149280.1056962913.1600579272.1606267178.1606286055.4; __utmz=30149280.1606286055.4.3.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; __utmt=1; _pk_id.100001.8cb4=7eeb4b40044b549f.1600579272.4.1606286058.1606272135.; __utmb=30149280.4.10.1606286055',
"user-agent": "Mozilla/5.0"}
threads = []
def movieInfo(self, url):
#获取电影的详细界面信息,从中获取导演和主演信息
r = requests.get(url, headers=self.headers)
r.encoding = "utf-8"
moviehtml = r.text
soup = BeautifulSoup(moviehtml, 'html.parser')
span = soup.select("body div[id='info'] span")
director = span[0].select("a")[0].text
actor = span[2].select("span[class = 'attrs'] a")[0].text
return director, actor
def download(self, url, name):
#下载电影图片
try:
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
if not os.path.exists('images'):
os.makedirs('images')
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\\" + name + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded" + name + ext)
except Exception as err:
print(err)
def start(self):
#连接mysql数据库
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from movie")
def closeUp(self):
#关闭连接并上传
try:
self.con.commit()
self.con.close()
except Exception as err:
print(err)
def insertDB(self,rank, name, director, actor, year, country, type, score, number, quote,filepath):
#将数据插入数据库中
try:
print(rank, name, director, actor, year, country, type, score, number, quote,filepath)
self.cursor.execute("insert into movie (排名,电影名称,导演,主演,上映时间,国家,电影类型,评分,评价人数,引用,文件路径) values "
"(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(rank, name, director, actor, year, country, type, score, number, quote,filepath))
except Exception as err:
print(err)
def readMovie(self, html):
#获取电影信息
soup = BeautifulSoup(html, 'html.parser')
for li in soup.select("body div[id='wrapper'] li"):
rank = li.select("div[class='pic'] em")[0].text
name = li.select("div[class='info'] a span")[0].text
filepath = name+".jpg"
#获取电影详细介绍界面的url,并从中获取导演和主演信息
movieurl = li.select("div[class='pic'] a")[0]['href']
director, actor = self.movieInfo(movieurl)
infos = li.select("div[class='bd'] p")[0].text
#通过正则表达式获取字符串中需要的相应信息
year = re.findall(r'\d+.+', infos)[0].split('/')[0].strip()
country = re.findall(r'\d+.+', infos)[0].split('/')[1].strip()
type = re.findall(r'\d+.+', infos)[0].split('/')[2].strip()
score = li.select("div[class='bd'] span[class='rating_num']")[0].text
number = li.select("div[class='bd'] div span")[3].text
number = re.findall(r'\d+', number)[0]
#判断电影是否有引用,有则获取
if li.select("div[class='bd'] p[class='quote'] span"):
quote = li.select("div[class='bd'] p[class='quote'] span")[0].text
else:
quote = ''
self.insertDB(rank, name, director, actor, year, country, type, score, number, quote,filepath)
#获取电影图片的url并进行下载
picurls = soup.select("div[class='pic'] img")
for url in picurls:
T = threading.Thread(target=self.download, args=(url['src'], url['alt']))
T.setDaemon(False)
T.start()
self.threads.append(T)
mv = getmovie()
mv.start()
#通过翻页操作爬取所有电影信息
for page in range(0, 11):
url = 'https://movie.douban.com/top250?start=' + str(page * 25) + '&filter='
r = requests.get(url, headers=mv.headers)
r.encoding = "utf-8"
html = r.text
mv.readMovie(html)
mv.closeUp()
-
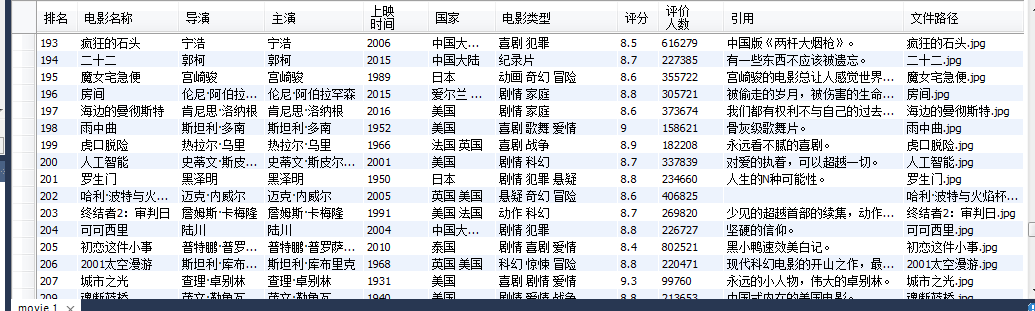
运行结果截图
-
心得体会
1.复习了beautifulsoup的使用,
2.进一步熟练了对正则表达式的使用
3.加强了对网页信息的提取
作业二
-
要求
1.熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
2.爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
-
候选网络
https://www.shanghairanking.cn/rankings/bcur/2020
-
思路
1.首先连接mysql数据库,并将每个学校详细介绍页面的url获取下来
2.逐个获取每个学校详细页面的信息
3.将爬取的股票信息存储进mysql数据库中
4.结束与mysql的连接
-
代码
-
MySpider
import scrapy
from getrank.items import GetrankItem
from bs4 import UnicodeDammit
import urllib.request
import requests
import os
class MySpider(scrapy.Spider):
name = 'mySpider'
start_url = 'https://www.shanghairanking.cn'
source_url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
headers = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"
}
def start_requests(self):
r = requests.get(self.source_url) # 向网站发送请求,并获取响应对象
r.encoding = "utf-8" # 设置编码方式
html = r.text
selector = scrapy.Selector(text=html)
trs = selector.xpath('//*[@id="content-box"]/div[2]/table/tbody/tr')
schoolurl = []
#获取每个学校详细页面的url
for tr in trs:
schoolurl.append(self.start_url + tr.xpath("./td[2]/a/@href").extract_first())
print(self.start_url + tr.xpath("./td[2]/a/@href").extract_first())
#逐个获取学校信息
for url in schoolurl:
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
#获取所需的学校数据
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
item = GetrankItem()
item['schoolName'] = selector.xpath("//div[@class='info-container']//tbody/tr[1]/td[2]/div[1]/text()").extract_first()
item['officalUrl'] = selector.xpath("//div[@class='info-container']//tbody/tr[2]//a/text()").extract_first()
#有些学校没有评语,因此导致tr的数量不同,需要采用两种不同的xpath提取信息
if selector.xpath("//div[@class='info-container']//tbody/tr[4]/td[2]//tr/td[1]/div[1]/a/text()").extract_first():
item['sNo'] = selector.xpath("//div[@class='info-container']//tbody/tr[4]/td[2]//tr/td[1]/div[1]/a/text()").extract_first()
else:
item['sNo'] = selector.xpath("//div[@class='info-container']//tbody/tr[3]/td[2]//tr/td[1]/div[1]/a/text()").extract_first()
item['city'] = selector.xpath("//div[@class='science-ranks']/div[2]/div[2]/text()").extract_first()[:2]
item['info'] = selector.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
picurl = selector.xpath("//div[@class='info-container']//tbody//img/@src").extract_first()
self.download(picurl,item['schoolName'])
item['mFile'] = picurl
yield item
except Exception as err:
print(err)
def download(self,url,name):
#下载学校logo
try:
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
if not os.path.exists('images'):
os.makedirs('images')
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("images\\" + name + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded" + name + ext)
except Exception as err:
print(err)-
pipelines
from itemadapter import ItemAdapter
import pymysql
class GetrankPipeline:
def open_spider(self, spider):
#连接数据库
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from schools")
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
#关闭连接
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
print(item['sNo'], item["schoolName"], item["city"], item["officalUrl"],
item["info"],item["mFile"])
#将数据插入到数据库中
try:
if self.opened:
self.cursor.execute("insert into schools (sNo,schoolName,city,officalUrl,info,mFile) values "
"(%s,%s,%s,%s,%s,%s)",
(item['sNo'], item["schoolName"], item["city"], item["officalUrl"],
item["info"],item["mFile"]))
except Exception as err:
print(err)
return item
-
items
import scrapy
class GetrankItem(scrapy.Item):
sNo = scrapy.Field()
schoolName = scrapy.Field()
city = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mFile = scrapy.Field()
pass
-
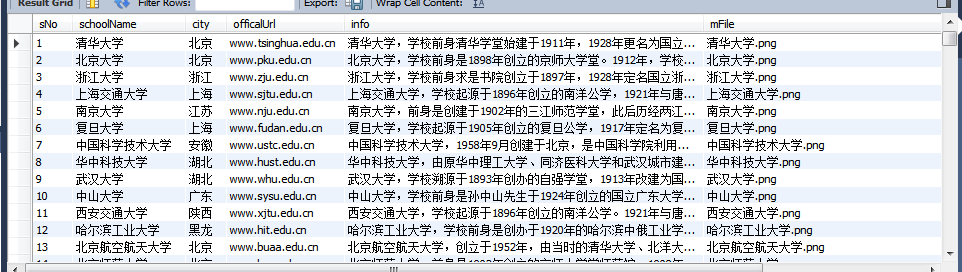
运行结果截图


-
心得体会
1.复习了对scrapy的使用
2.清楚了selenium中的一些方法与scrapy中的方法的区别
作业三
-
要求
1.熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
2.使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
3.其中模拟登录账号环节需要录制gif图。
-
候选网站
中国mooc网:https://www.icourse163.org
-
思路
1.建立浏览器对象,连接mysql数据库
2.通过url访问页面,进行登入操作
3.打开个人中心,并将所有已选课程的介绍页面url获取下来
4.逐个打开课程url,通过页面跳转来获取课程中的信息
5.打开新的课程页面,重复之前课程的爬取
6.结束爬取,关闭浏览器,将爬取到的数据存储到数据库中
-
代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import pymysql
import re
class getMoocs:
headers = {
"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre)"
"Gecko/2008072421 Minefield/3.0.2pre"
}
no = 1
page = 1
courseurls = []
def startUp(self,url):
'''chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')'''
self.driver = webdriver.Chrome()#options=chrome_options)
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("delete from moocs")
except Exception as err:
print(err)
self.driver.get(url)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def signUp(self):
time.sleep(2)
#登入
self.driver.find_element_by_xpath("//div[@class='m-navTop-func']//div[@class='u-navLogin-loginBox']//div[@class='m-navlinks']").click()
time.sleep(1)
self.driver.find_element_by_xpath("//div[@class='ux-login-set-scan-code_ft']/span[@class='ux-login-set-scan-code_ft_back']").click()
time.sleep(2)
self.driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']/li[2]").click()
# 切换次页面
time.sleep(2)
self.driver.switch_to.frame(self.driver.find_element_by_xpath("//div[@class='ux-login-set-container']/iframe"))
self.driver.find_element_by_xpath("//html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input").send_keys("18950511233")
self.driver.find_element_by_xpath("//html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]").send_keys("000SUJINGZE")
self.driver.find_element_by_xpath("//div[@class='f-cb loginbox']").click()
time.sleep(10)
# 进入个人中心
self.driver.find_element_by_xpath(
"//div[@id='j-indexNav-bar']/div/div/div/div/div[7]/div[3]/div/div/a/span").click()
def getcourse(self):
#获取个人中心中的所有课程的url
time.sleep(3)
divs = self.driver.find_elements_by_xpath("//div[@id='j-coursewrap']/div/div[1]/div")
for div in divs:
courseurl = div.find_element_by_xpath("./div[4]/div[1]/a").get_attribute("href")
self.courseurls.append(courseurl)
print(courseurl)
#进行翻页操作
try:
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-disable-gh']")
except:
nextPage = self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-main-gh']")
nextPage.click()
self.getcourse()
def getinfo(self):
for url in self.courseurls:
#切换到要爬取信息的页面
self.driver.get(url)
print(self.driver.current_url)
id = self.no
self.no += 1
time.sleep(3)
#爬取需要的数据
cCourse = self.driver.find_element_by_xpath("//div[@id='g-body']//span[@class='course-title f-ib f-vam']").text
cCollege = self.driver.find_element_by_xpath("//a[@data-action='点击学校logo']/img[@class='u-img']").get_attribute('alt')
cTeacher = self.driver.find_element_by_xpath("//div[@data-action='点击课程团队头像']/div/h3").text
teachers = self.driver.find_elements_by_xpath("//div[@class='um-list-slider_con']/div")
cTeam = ''
for i in range(len(teachers)):
name = teachers[i].find_element_by_xpath("./div//img").get_attribute("alt")
if i != len(teachers)-1:
cTeam += name + ','
else:
cTeam += name
#通过正则表达式提取字符串中的数字信息
cCount = self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-enroll']/div/span").text
cCount = re.findall(r'\d+', cCount)[0]
cProcess = self.driver.find_element_by_xpath("//div[@id='course-enroll-info']/div/div[1]/div[2]/div[1]/span[2]").text
cBrief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
self.insertDB(id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief)
def insertDB(self,id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief):
try:
print(id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief)
self.cursor.execute("insert into moocs (id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) values (%s,%s,%s,%s,%s,%s,%s,%s)",
(id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief))
except Exception as err:
print(err)
def executeSpider(self, url):
print("Spider starting......")
#建立浏览器对象,连接数据库
self.startUp(url)
print("Spider processing......")
#登入mooc
self.signUp()
#爬取课程数据
self.getcourse()
self.getinfo()
#关闭
self.closeUp()
url = "https://www.icourse163.org"
spider = getMoocs()
spider.executeSpider(url)-
运行结果截图
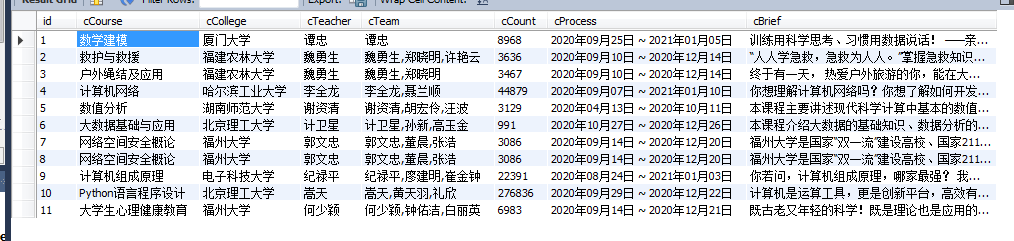


-
心得体会
1.再次进行登录操作,对操作浏览器对象进行登入操作更加熟练。
2.这次的作业跟上次的几乎一样,只不过上次是一个课程一个课程的爬取,要不断打开,关闭新页面和切换页面,而这次是先将所有课程的url获取下来,再一次性不断转换页面来爬取信息。
3.通过xpath获取各种信息更加熟练,同时也巩固了对正则表达式的使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号