

第一次作业——结合三次小作业
作业一
(1)UniversityRanking实验
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
- 代码
import requests
from bs4 import BeautifulSoup
import bs4
def readInfo(result,html):
#获取校园排名的数据
soup = BeautifulSoup(html,'html.parser')
for tr in soup.select("tbody tr"):
tds = tr('td')
result.append([tds[0].text.strip(), tds[1].text.strip(),tds[2].text.strip(),tds[3].text.strip(), tds[4].text.strip()])
def writeInfo(result, num):
#将获取到的校园排名数据按照指定格式输出
print("{0:<5}\t{1:^15}\t{2:^10}\t{3:^10}\t{4:^5}".format('排名', '学校名称','省份','学校类型', '总分'))
for i in range(num):
info = result[i]
print("{0:<5}\t{1:^15}\t{2:^10}\t{3:^10}\t{4:^5}".format(info[0], info[1], info[2],info[3],info[4]))
result = []
url = 'http://www.shanghairanking.cn/rankings/bcur/2020.html'
r = requests.get(url) #向网站发送请求,并获取响应对象
r.encoding = "utf-8" #设置编码方式
html = r.text #获取抓取到的对象中的内容
readInfo(result, html)
writeInfo(result, num=20)
- 运行结果截图
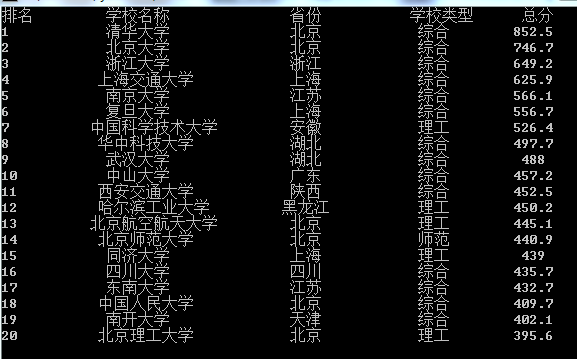
(2)心得体会
1.对爬取网页信息的整体过程有了初步的了解
2.进一步明白了对requests,BeautifulSoup和select的使用
3.通过这次的实验复习了对输出格式的修改
4.学习并了解了网页源代码的结构形式
作业二
(1)GoodsPrices实验
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
- 代码
import requests
import re
headers = {
'authority': 's.taobao.com',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'sec-fetch-user': '?1',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 't=b21c97129d993a82ac8cfcf501e00317; v=0; _tb_token_=f7e5e89603581; _m_h5_tk=16267b384e83df934237bf2a8253f456_1600610541104; _m_h5_tk_enc=2b7ca35e36e2ceb6e2a11b205e340a55; cna=kIzXFxb5DwcCAWp6TqatlOPm; xlly_s=1; _samesite_flag_=true; cookie2=1a755ab33292b77f9496de1dc6a5b2cf; sgcookie=E100xunr7Tw75y59WPI27PduQ%2BuG9O%2Fue6nKmgM7IZHqqhRncTa8XEtaPkEdkyVLjWJ4THy7yJ5X1T5N8gP0scXzZg%3D%3D; unb=3978611290; uc3=lg2=URm48syIIVrSKA%3D%3D&nk2=F5RBzL9uq%2FMwu3M%3D&vt3=F8dCufeJMxOMW0noC70%3D&id2=UNkweIKfiNxKdQ%3D%3D; csg=6eaf7f71; lgc=tb492891376; cookie17=UNkweIKfiNxKdQ%3D%3D; dnk=tb492891376; skt=07c21c435a7c4544; existShop=MTYwMDYwMjIwMQ%3D%3D; uc4=id4=0%40Ug46tyRDnc9OByWbtuTI6V1BgCL6&nk4=0%40FY4KqaBnM9Wj44QWsrqJuO4E3dvbXQ%3D%3D; tracknick=tb492891376; _cc_=URm48syIZQ%3D%3D; _l_g_=Ug%3D%3D; sg=604; _nk_=tb492891376; cookie1=BxVQAf1PouLoMHV%2FUpPeBu1XDN8kgpjJbQjQKkngdWs%3D; enc=RhU4JzsN4VDWhG9v7aU8xgomDiQxZdI05GZ%2F8ELHQd6eoMsvpamANrxfzonN5sADPORzGw51MZuGX7%2F1szRLAA%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; mt=ci=11_1; uc1=cookie21=VT5L2FSpccLuJBreK%2BBd&pas=0&cookie15=U%2BGCWk%2F75gdr5Q%3D%3D&existShop=false&cookie16=V32FPkk%2FxXMk5UvIbNtImtMfJQ%3D%3D&cookie14=Uoe0bU5UvUbxjw%3D%3D; JSESSIONID=87FEC60EE5C1E4486FB50E39D7497D0B; isg=BPDwLlowW5T6ageQ2mVCswK7wb5COdSD8760aupBkMsepZFPkkmkE6DU-a3FNYxb; l=eBIxmmtqOFtnhSSYBOfZlurza77TRIRfguPzaNbMiOCPOk5p5AJGWZroSh89CnGVHs_pR3z9IwceBeDMqyCSnxv9-3k_J_0-3wC..; tfstk=cZZ1BFGyMCA1-ib2bR6EgWISNGnfaHxIKHcUCPNM0BW2xglS9sjH4bNwtAOCwuHC.',
}
def readInfo(result,html):
#通过正则表达式直接获取商品的名称与价格
prices = re.findall(r'"view_price":"[\d.]*"', html)
titles = re.findall(r'"raw_title":".*?"', html)
for i in range(0,len(prices)):
#获取商品的名称与价格的值,并且去除引号
price = prices[i].split(':')[1].replace('"','')
title = titles[i].split(':')[1].replace('"','')
result.append([price , title])
def writeInfo(result):
#打印商品信息
for i in range(0,len(result)):
info = result[i]
print("{0:^5}{1:^10}{2:^15}".format(i+1, info[0],info[1]))
keyword = '书包' #设置搜索关键词
result = []
print("{0:^5}{1:^5}{2:^15}".format('序号','价格','商品名称'))
for i in range(0,3): #获取三页的商品信息
url = 'https://s.taobao.com/search?q='+keyword+'&imgfile=&js=1&stats_click=search_radio_tmall%3A1' \
'&initiative_id=staobaoz_20190508&tab=mall&ie=utf8&sort=sale-desc&filter=reserve_price%5B%2C200%5D' \
'&bcoffset=0&p4ppushleft=%2C44&s=' + str(44*i)
r = requests.get(url,headers = headers)
r.encoding = "utf-8"
html = r.text
readInfo(result, html)
writeInfo(result)
- 运行结果截图
一共爬取了淘宝中三页商品的信息
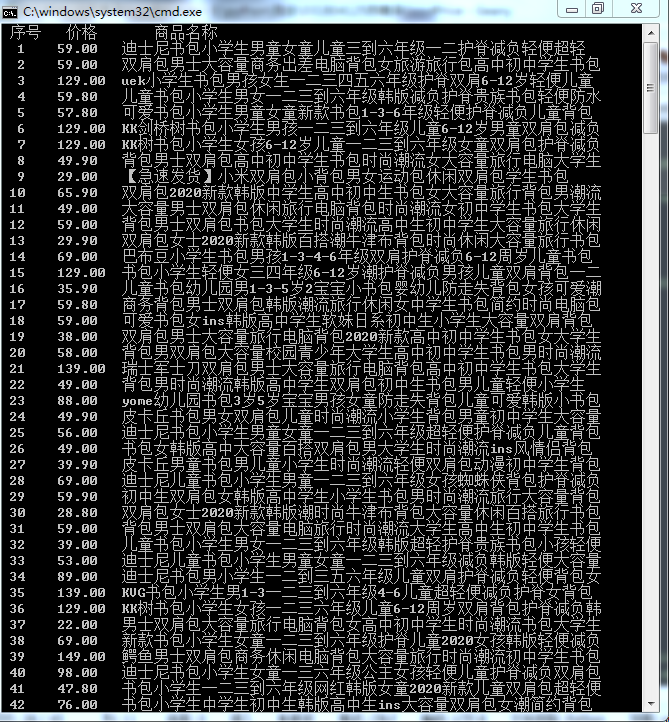
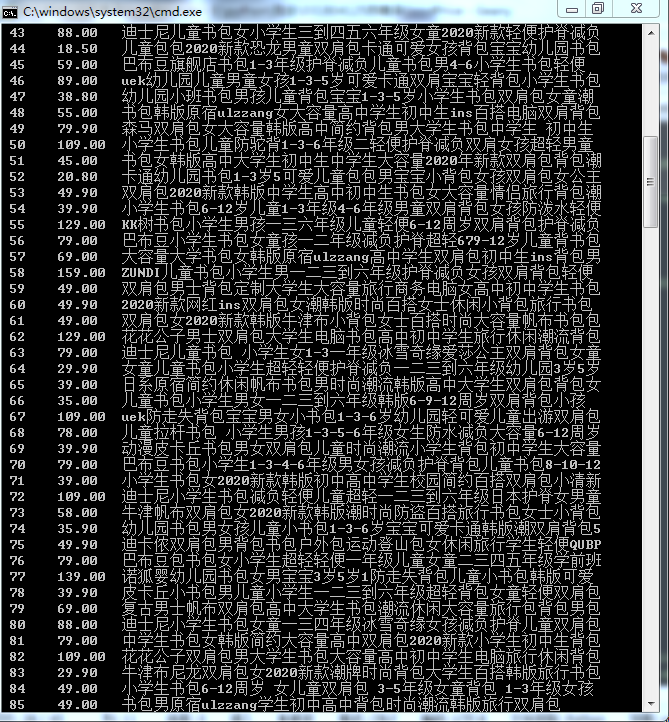
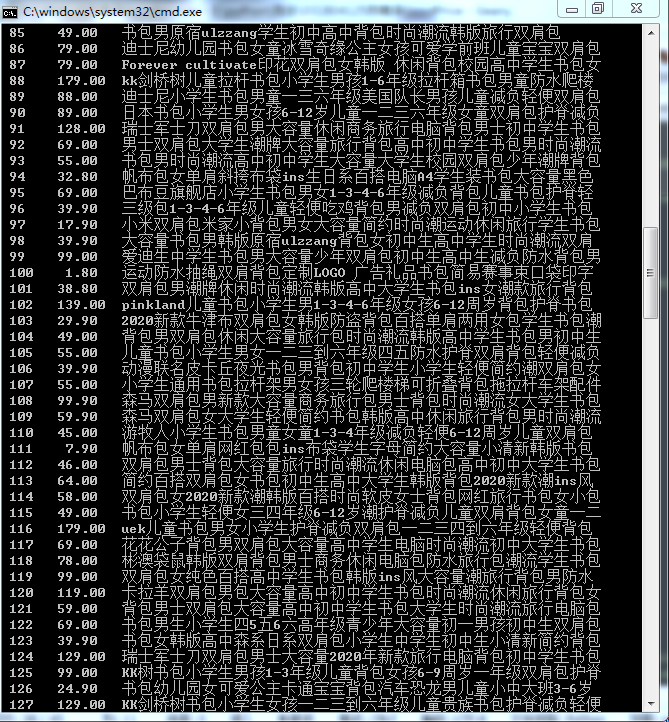
(2)心得体会
1.通过这次实验了解了怎么模拟浏览器的headers去爬取信息。
2.了解了淘宝的搜索接口和翻页处理。通过比较搜索不同的商品以及不同页数下的url,可以发现淘宝中搜索关键词的字段是keyword,通过改变keyword的可以起到搜索不同商品的作用。同时翻页的操作是通过设置s的值来实现的,将s的值设置为页数-1的44倍就可以获取到想要页数的商品信息。
3.熟悉了正则表达式的使用。
作业三
(1)JPGFileDownload实验
要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
- 代码
import requests
import re
from bs4 import BeautifulSoup
import bs4
import urllib.request
import os
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51"}
def getUrl(html):
#获取网站中图片的url地址
img_url = []
imgs1 = re.findall(r'src="(.+jpg)"', html)
imgs2 = re.findall(r'"(/.+jpg)"', html)
imgs = imgs1+imgs2
for img in imgs:
if img.startswith("src"):
src = img.split('=')[1]
else:
src = img
if src[0] == '/':
#如果获取的是相对地址则补充完整
url_ = url + src
else:
url_ = src
img_url.append(url_)
return img_url
def writeData(img_url):
#建立结果存储目录
if not os.path.exists('images'):
os.makedirs('images')
for i in range(len(img_url)):
#打开url下载图片数据
data = urllib.request.urlopen(img_url[i]).read()
with open('images/'+img_url[i].split('/')[-1].split('.')[0]+'.jpg','wb') as f:
f.write(data)
url = 'http://xcb.fzu.edu.cn/'
r = requests.get(url,headers = headers)
r.encoding = "utf-8"
html = r.text
soup = bs4.BeautifulSoup(html,"html.parser")
img_url = getUrl(html)
writeData(img_url)
- 结果截图
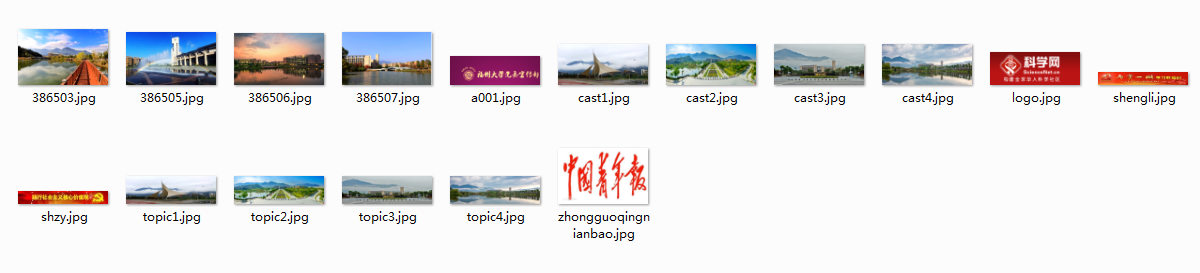
(2)心得体会
1.通过这次实验进一步了解了对正则表达式的使用
2.熟悉了web下载图片的操作,并且复习了在本地建立结果存储目录的代码
3.进一步学习了网页源代码的结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号