
数据结构-图
无向图

图1
图1中字母叫作顶点,每个顶点和其他顶点连接的线条叫作边,每个顶点所拥有的边的个数叫作度
这个概念有点类似微信的好友结构
图中每个顶点代表了微信好友中的每个人
边代表了每个人(顶点)对应有哪些好友,A-C的意思就是A是C的好友,C也是A的好友,A-D的意思就是A是D的好友,D也是A的好友
每个顶点所拥有的边的条数,就是微信中每个人拥有的好友个数
有向图
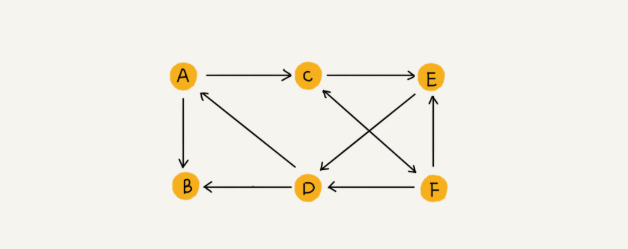
图2
有向图的概念简单明了,就是有方向嘛,
有向图的概念和微博的好友结构一样
A->C,A到C这条边的方向是A指向C,对应微博中就是A这个人主动关注了C,但是C没有关注A,在看图2中C<->F这条边,就对应了C关注了F,F也关注了C
有向图中关于度的概念有了变化,分为入度和出度,顾名思义
入度就是指向某个顶点的边的条数,比如说D的入度就是2
出度就是某个顶点指向其他顶点的边的个数,比如说A的出度就是2
带权图
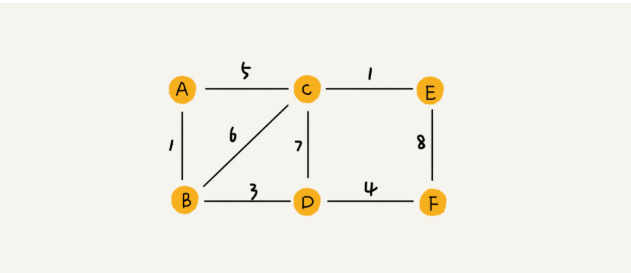
图3
带权图就是在每条边上面加上了权重,就像QQ的好友亲密度,比如A-C这条就代表了A和C的好友亲密度是5
下面我们来看存储方法
邻接矩阵法
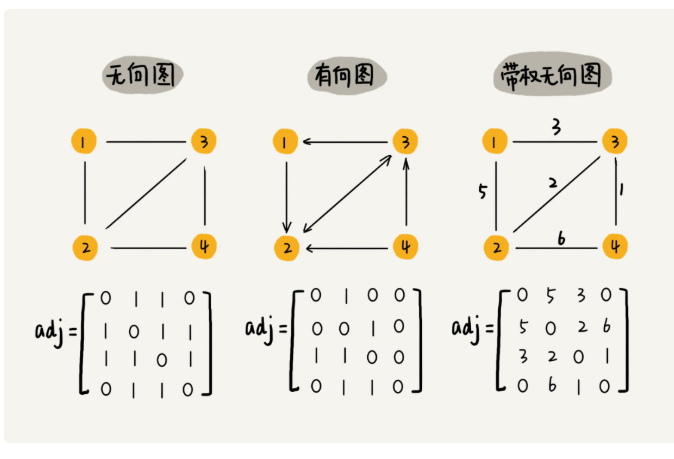
图4
图4中所表示的方法叫作邻接矩阵法,这种方法底层依赖一个二维数组
对于无向图如果i和j之间有边,我们就把a[i][j]记为1,a[j][i]也记为1
对于有向图来说,如果有一条箭头从i指向j,就把a[i][j]记为1,如果有一条箭头从j指向i,就把a[j][i]记为1
对于带权图,数组中就存储对应的权重
这种存储方法有一些缺点
对于无向图来说如果a[i][j]=1,那么a[j][i]肯定也等于1,这样其实就白白浪费了一半的空间
还有如果是稀疏图,比如说微信用户很多,但是每个用户的好友不是很多,一般也就三五百个,那绝大部分的空间就浪费掉了
但这也并不是说,邻接矩阵的存储方法就完全没有优点。
首先,邻接矩阵的存储方式简单、直接
因为基于数组,所以在获取两个顶点的关系时,就非常高效。
邻接表存储方法
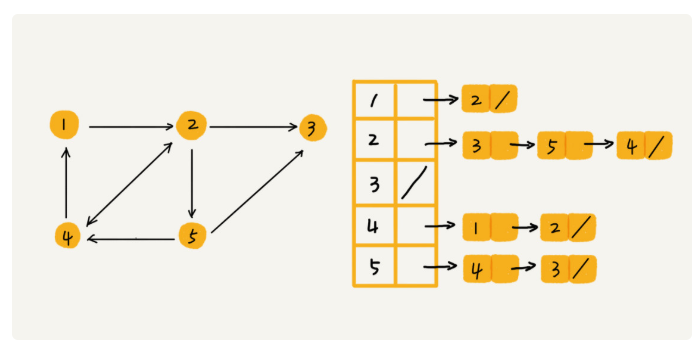
图5
图5中画的是一个有向图的邻接表存储方式
其实就是散列表
在每个顶点后面挂一条链表,链表中存储的就是顶点所指向的其他顶点
这种存储方式虽然占用空间比邻接矩阵法小,但是他的缺点就是对cpu缓存是不友好的哈,因为链表在内存中不是连续存储的
还有就是比如说我们要查看2和4是否有对应关系,我们就需要查询出2中的链表数据,循环查询看是否有4,这样在邻接表中查询两个顶点的关系就没有那么高效了
还有一个点就是如果某个顶点的链接长度过长,这样查询数据就是O(n)的时间复杂度,查询时间会很长,我们可以设置一个阈值,比如说一个顶点的链表长度超过了50
那么就把链表的存储方法改为平衡二叉查找树,比如红黑树(是平衡二叉查找树的一种方式),红黑树的理解比较复杂,大家感兴趣可以去查询一下
对于邻接矩阵法来说就是空间换时间
对于邻接表存储方法来说就是时间换空间
了解更多:https://www.toutiao.com/c/user/83293539887/#mid=1633933053814798

 浙公网安备 33010602011771号
浙公网安备 33010602011771号