
mysql
服务器处理客户端请求:客户端进程向服务器进程发送一段文本(MySQL语句),服务器进程处理后再向客户端进程发送一段文本(处理结果)。
流程:连接管理,解析与优化(查询缓存,语法解析,查询优化),存储引擎
连接管理:每当有一个客户端进程连接到服务器进程时,服务器进程都会创建一个线程来专门处理与这个客户端的交互,当该客户端退出时会与服务器断开连接,服务器并不会立即把与该客户端交互的线程销毁掉,而是把它缓存起来,在另一个新的客户端再进行连接时,把这个缓存的线程分配给该新客户端。(线程池,连接池)
查询缓存:mysql8.0中被删除
语法解析:判断语法是否正确,编译语法
查询优化:MySQL的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接等等的一堆东西。优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序是什么样的。我们可以使用EXPLAIN语句来查看某个语句的执行计划
字符集与比较规则:乱码问题
character_set_client |
服务器解码请求时使用的字符集 |
character_set_connection |
服务器处理请求时会把请求字符串从character_set_client转为character_set_connection |
character_set_results |
服务器向客户端返回数据时使用的字符集 |
Innodb记录结构:
将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16 KB。也就是在一般情况下,一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。
行格式(ROW_FORMAT):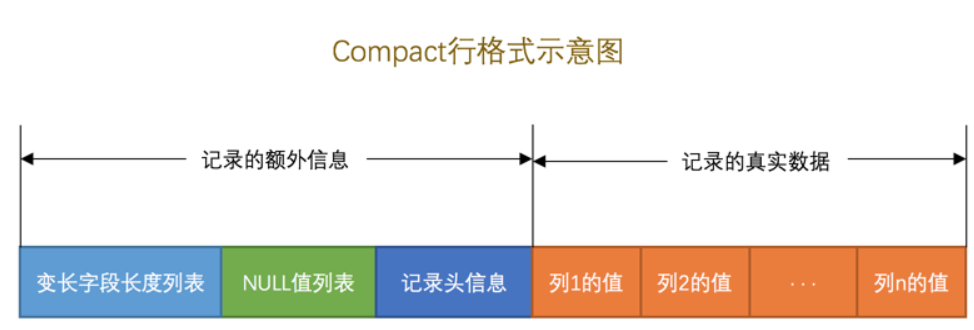
边长字段长度列表:倒序存储
null值列表:倒序存储,01,
记录头信息:delete_mask(标记该记录是否被删除),next_record(表示下一条记录的相对位置),min_rec_mask(B+树的非叶子节点中的最小记录),heap_no(表示当前记录在本页中的位置),record_type(0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录),n_owned(一个数据页中的行会分成多组,每组最后一行的n_owned表示该组中有几行)
隐藏列:row_id(行ID,唯一标识一条记录,非必须),transaction_id(事务ID),roll_pointer(回滚指针)
innodb主键生成策略:自定义主键->unique键->row_id
char和carchar:另外有一点还需要注意,变长字符集的CHAR(M)类型的列要求至少占用M个字节,而VARCHAR(M)却没有这个要求。比方说对于使用utf8字符集的CHAR(10)的列来说,该列存储的数据字节长度的范围是10~30个字节。即使我们向该列中存储一个空字符串也会占用10个字节,这是怕将来更新该列的值的字节长度大于原有值的字节长度而小于10个字节时,可以在该记录处直接更新,而不是在存储空间中重新分配一个新的记录空间,导致原有的记录空间成为所谓的碎片。
innodb数据页:16K,划分为多个部分。
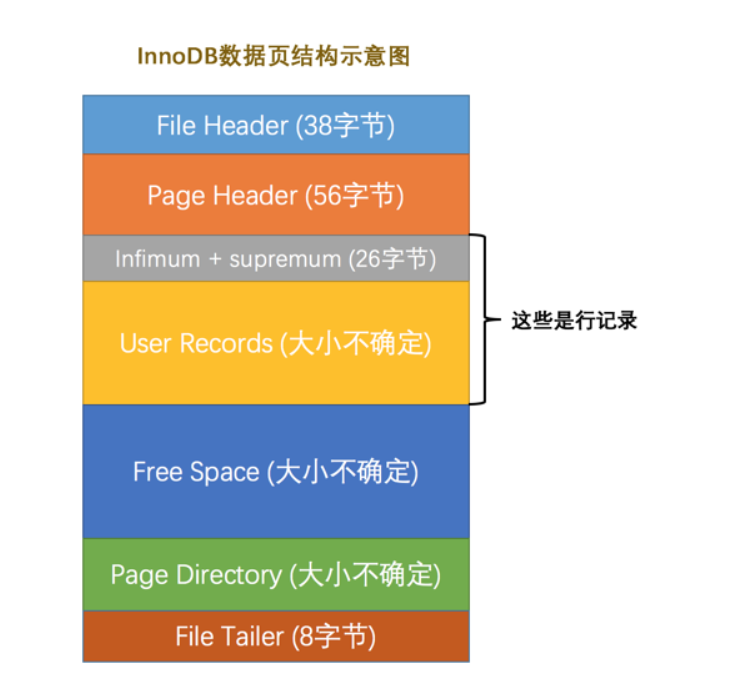
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
File Header |
文件头部 | 38字节 |
页的一些通用信息 |
Page Header |
页面头部 | 56字节 |
数据页专有的一些信息 |
Infimum + Supremum |
最小记录和最大记录 | 26字节 |
两个虚拟的行记录 |
User Records |
用户记录 | 不确定 | 实际存储的行记录内容 |
Free Space |
空闲空间 | 不确定 | 页中尚未使用的空间 |
Page Directory |
页面目录 | 不确定 | 页中的某些记录的相对位置 |
File Trailer |
文件尾部 | 8字节 |
校验页是否完整 |
Page Directory(页目录):
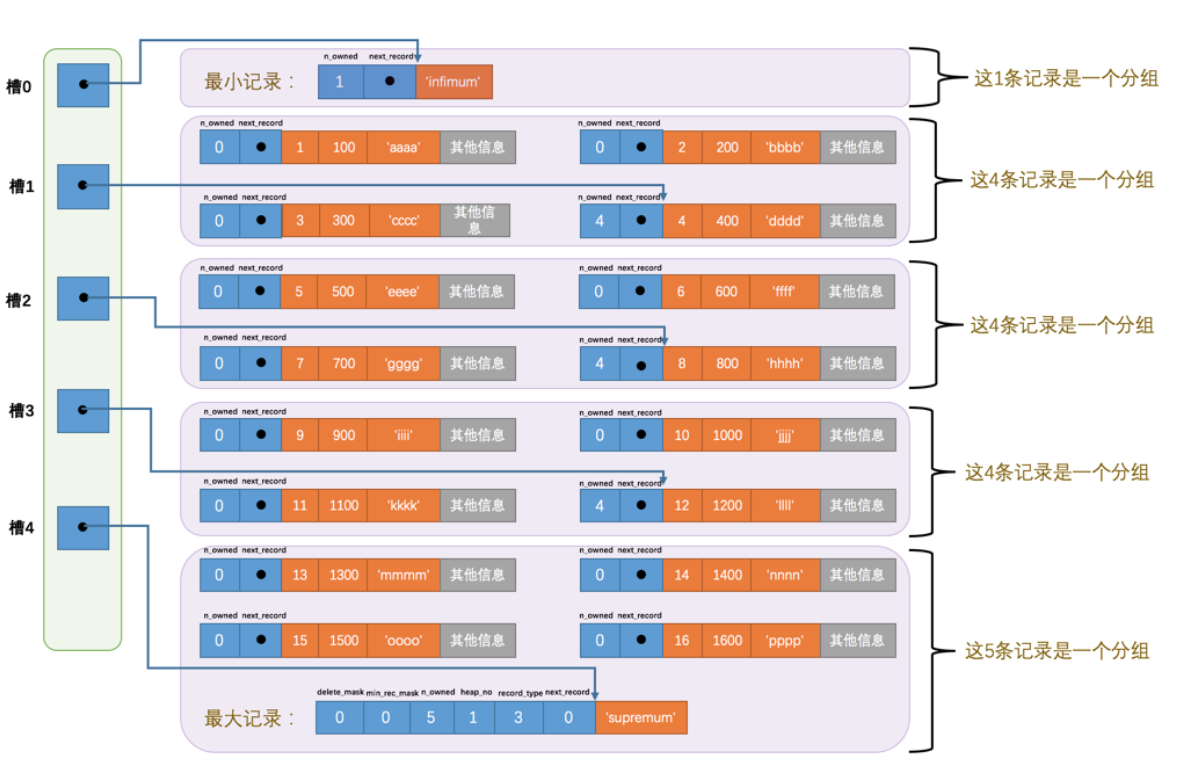
所以在一个数据页中查找指定主键值的记录的过程分为两步:
-
通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录。
-
通过记录的
next_record属性遍历该槽所在的组中的各个记录。
-
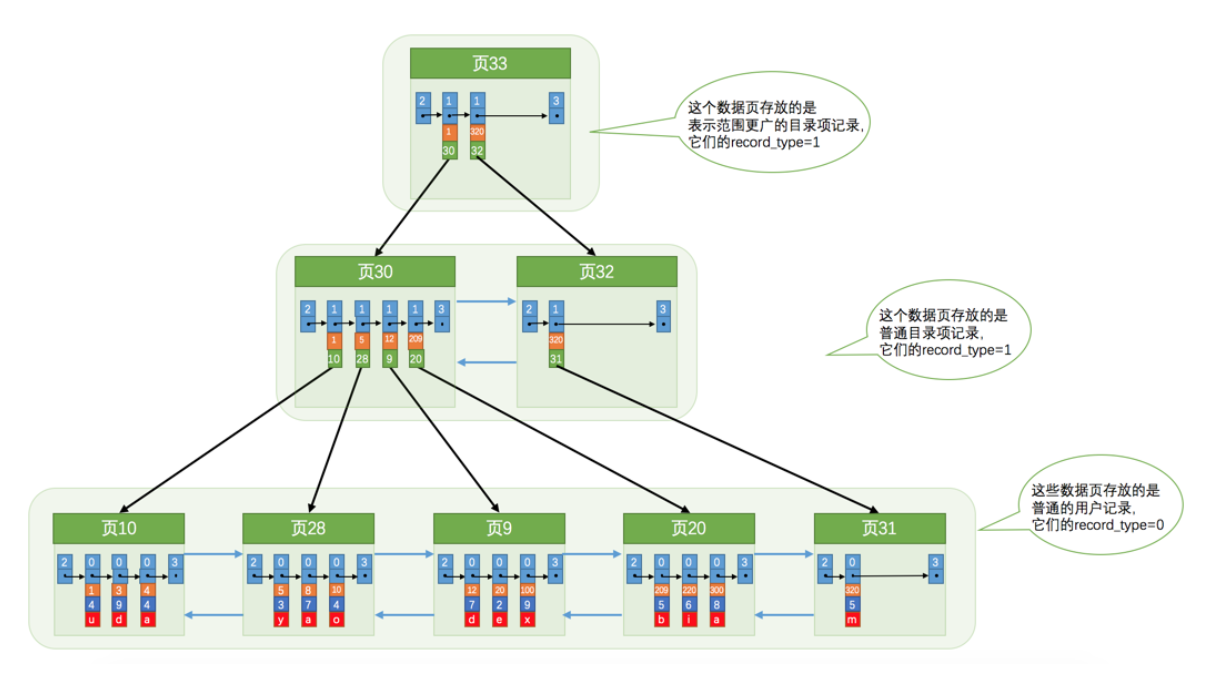
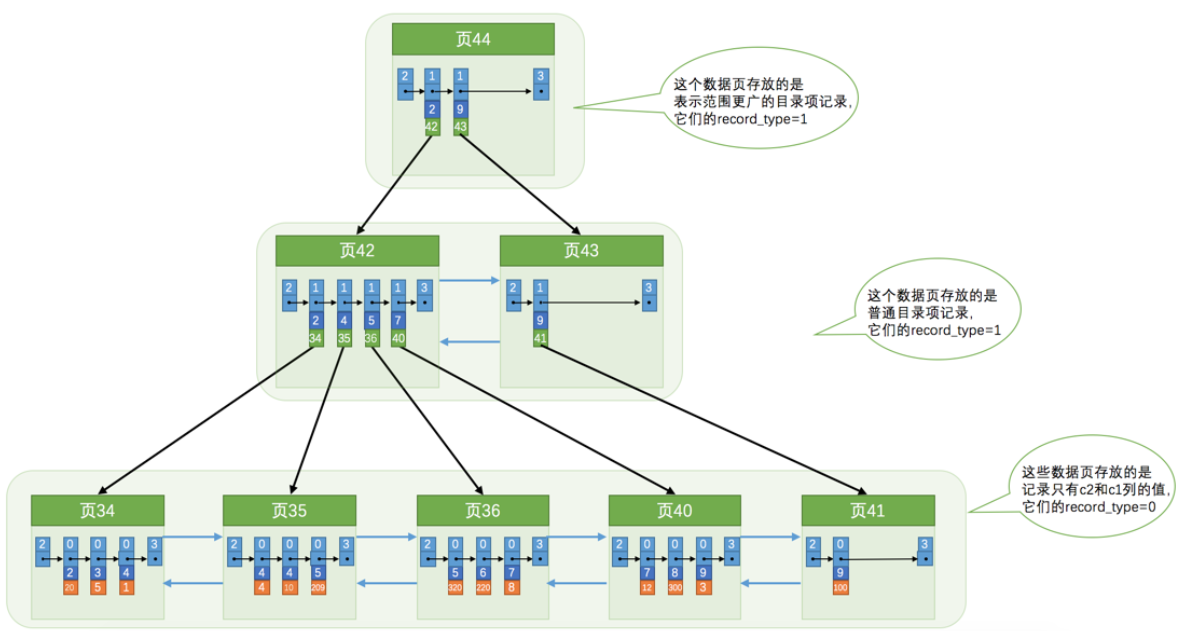
索引:
非叶子节点:目录记录项,record_type=1
叶子节点:用户记录, record_type=0
二级索引:
个人理解:任何二级索引都是联合索引,至少会与主键联合
二级索引+回表 PK 全表扫描
覆盖索引:为了彻底告别回表操作带来的性能损耗,我们建议:最好在查询列表里只包含索引列
索引列前缀:索引比较时只比较前几个字符,以节省空间时间
查询速度:const(单条),ref(多条),range(范围),all(全表查询聚簇索引),索引合并(交集),Union合并,Sort-Union合并
索引合并的时候要看查出来是否主键有序,主键有序的话交集会很快,无序的话做交集时间复杂题高(1.二级索引列是等值匹配的情况 2.主键列可以是范围匹配 )
外连接与内连接:
外连接:驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集
内连接:驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集 (, ;join;inner join;cross join)
where:WHERE子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合WHERE子句中的过滤条件的记录都不会被加入最后的结果集。
on:对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充。
join buffer 基于缓存的连表查询,缓存驱动表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号