


Qwen3: Think Deeper, Act Faster
思深,行速
- 引言
2025年4月29日,阿里通义千问推出最新大模型Qwen3,旗舰型Qwen3-235B-A22B在代码、数学、通用能力基准测试中,与Deepseek-R1、o1、o3-mini、Grok-3和Gemini-2.5-pro等顶级模型相比,表现出极具竞争力的结果,此外,小模型MoE模型Qwen3-30B-A3B的激活参数量是QWQ-32B的10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
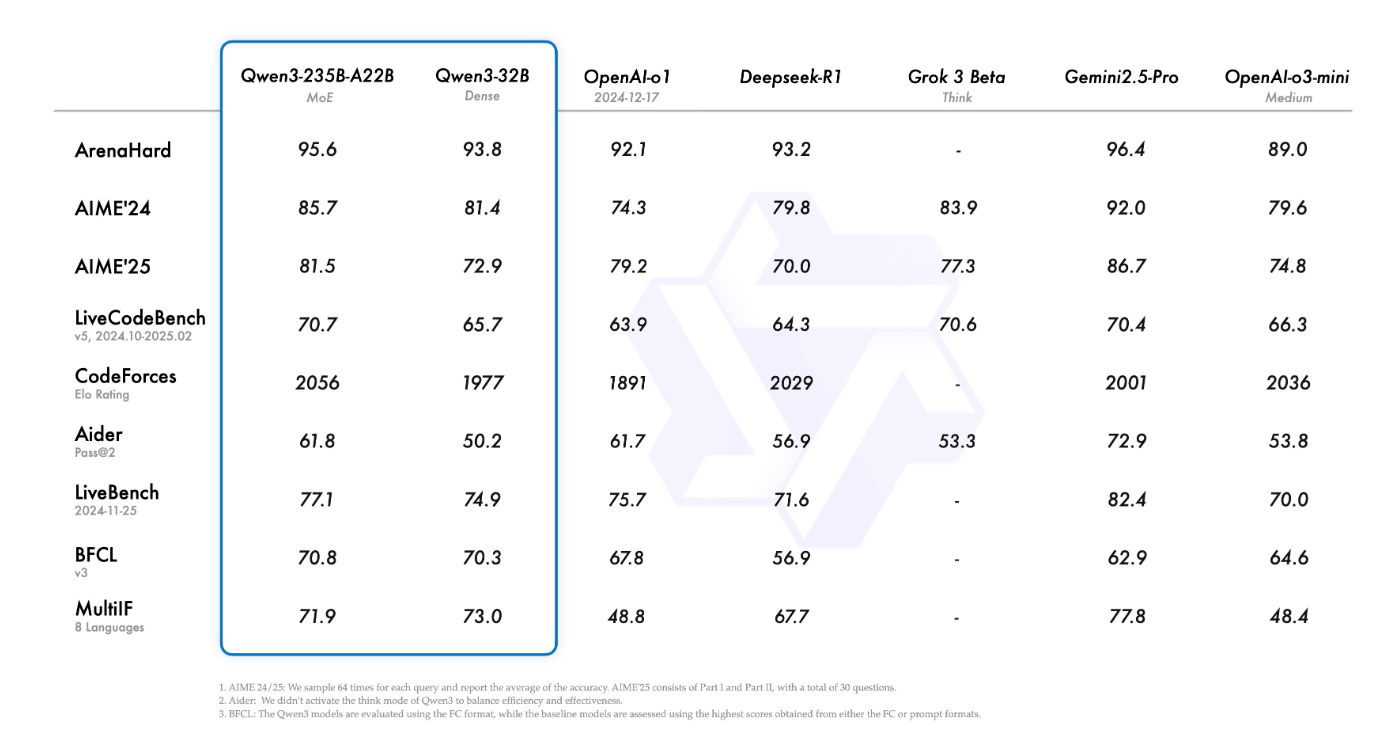
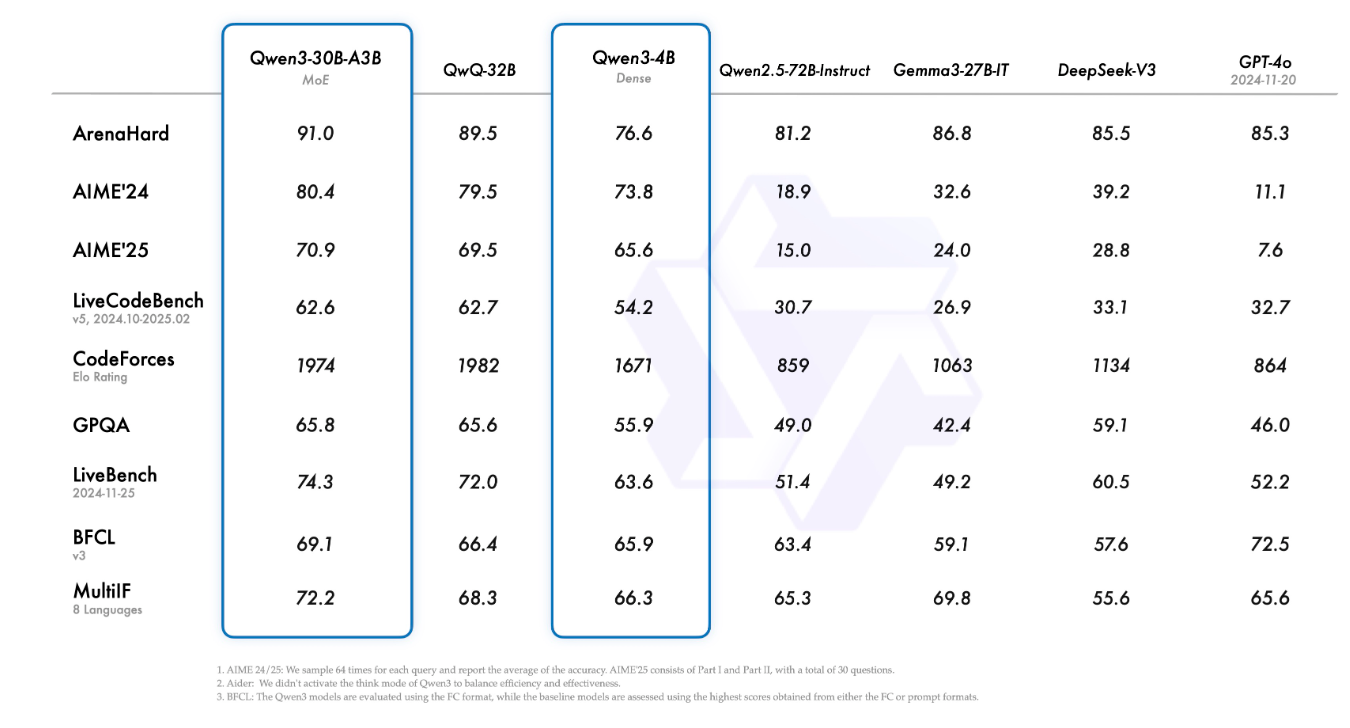
*基准测试指标*
Arena-Hard:
真实世界任务的泛化能力:通过实时收集的人类提问(非标准题库),模拟真实应用场景中的开放性问题(如多层推理、跨领域知识整合);抗数据污染能力:动态更新测试集,避免模型因训练数据包含测试题而“作弊”;复杂性和创造性:要求模型解决需要技术准确性、创造力和解决问题能力的任务。
AIME'24 / AIME'25:
数学推理与逻辑推导:聚焦数学竞赛级别的复杂问题(如代数、几何、数论),要求多步推理和严谨计算;事实忠诚性:通过优化框架(如SIFT)减少模型在推理中的“事实漂移”(Factual Drift),提升答案保真度;模型鲁棒性:在长期链式推理中保持稳定正确率(如DeepSeek-R1在AIME'24/25上的显著提升)
LiveCodeBench:
动态编程问题解决:实时生成新颖编程题(类似LeetCode或Codeforces的竞赛场景),考验模型面对未知问题时的快速适应能力;代码质量评估:不仅检查功能正确性(是否通过测试用例),还评估代码效率、可读性、简洁性等实用维度;反过拟合机制:通过持续更新题目防止模型依赖预训练数据中的固定答案。
Codeforces:
算法竞赛能力:模拟ICPC/ACM等编程比赛场景,侧重算法设计(贪心、动态规划、图论等)、时间复杂度优化和边界条件处理;限时响应能力:考核在有限时间内完成高质量代码生成的速度与准确性。
Aider:
交互式编程辅助能力:模拟开发者与AI助手的协作场景(如GitHub Copilot风格),测试代码补全、错误修复、文档生成等;长上下文理解:在大型代码库中定位问题并提供针对性解决方案(如条目[6]中SWE-Bench的要求)
LiveBench:
持续学习与适应能力:通过动态更新任务(如新出现的技术栈、政策法规等),评估模型的在线学习能力;多模态实时任务:结合文本、图像、音频等多源输入,处理随时间变化的综合问题。
BFCL (Big-Five Code Llama):
代码生成与缺陷检测:针对Meta的Llama系列模型,测试代码编写、漏洞修复(如SQL注入、内存泄漏)和安全合规性;跨语言兼容性:验证模型在Python、Java、C++等多种编程语言中的表现一致性。
MultiLF:
多语言/多模态能力:评估模型在多种语言(如中文、西班牙语)和模态(文本、图像、音频)间的迁移能力;文化敏感性:检测模型在不同语言文化背景下的伦理合规性和表达适配性。
他们开源了两个 MoE 模型的权重:Qwen3-235B-A22B,一个拥有 2350 多亿总参数和 220 多亿激活参数的大模型,以及Qwen3-30B-A3B,一个拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型。此外,六个 Dense 模型也已开源,包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B,均在 Apache 2.0 许可下开源。
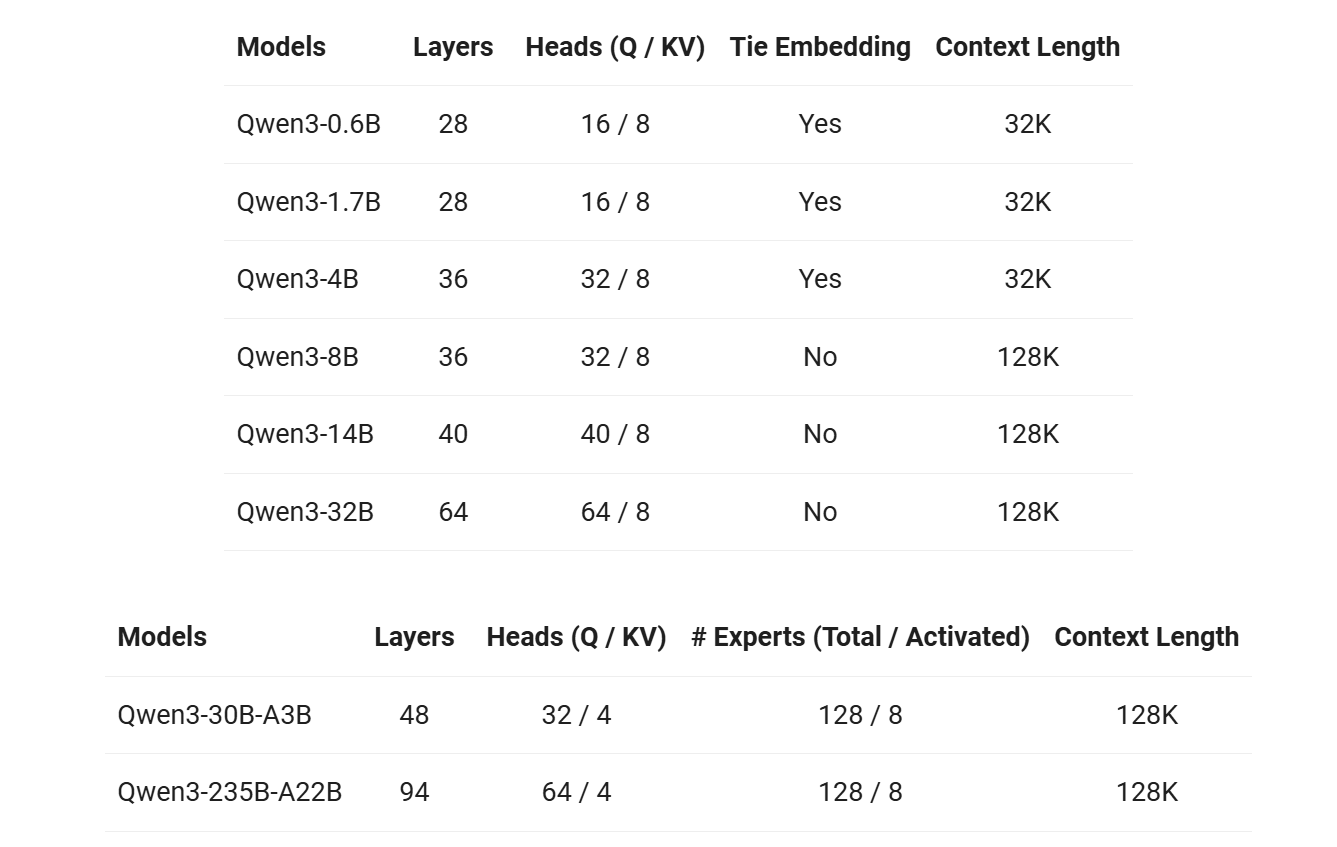
Layers(层数):Transformer模型的层数,层数越多通常模型复杂度越高。例如,Qwen3-32B有64层,而较小的Qwen3-0.6B仅28层。
Heads (Q / KV)(注意力头数):Q(查询头):参与计算查询向量的注意力头数。KV(键值头):共享键和值向量的注意力头数。
Tie Embedding(嵌入绑定):是否将输入嵌入层(Token Embedding)和输出分类层(如语言模型头)的参数共享。Yes:参数共享,减少模型体积(如Qwen3-0.6B);No:参数独立,提升模型表达能力(如Qwen3-8B及以上)
Context Length(上下文长度):模型支持的最大上下文窗口(Token数);较小模型(0.6B/1.7B/4B)支持32K Token,适用于中等长度文本。较大模型(8B/14B/32B)支持128K Token,适合处理长文本(如文档分析)。
经过后训练的模型,例如 Qwen3-30B-A3B,以及它们的预训练基座模型(如 Qwen3-30B-A3B-Base),现已在 Hugging Face、ModelScope 和 Kaggle 等平台上开放使用。对于部署,推荐使用 SGLang 和 vLLM 等框架;而对于本地使用,像 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 这样的工具。
- 核心点亮
多种思考模式。Qwen3 模型支持两种思考模式:
1.思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
2.非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
多语言。Qwen3 模型支持 119 种语言和方言。

增强的 Agent 能力
他们优化了 Qwen3 模型的 Agent 和 代码能力,同时也加强了对 MCP 的支持。
- 预训练
在预训练方面,Qwen3 的数据集相比 Qwen2.5 有了显著扩展。Qwen2.5是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用的数据量几乎是其两倍,达到了约 36 万亿个 token,涵盖了 119 种语言和方言。为了构建这个庞大的数据集,我们不仅从网络上收集数据,还从 PDF 文档中提取信息。我们使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 改进提取内容的质量。为了增加数学和代码数据的数量,我们利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个数学和代码领域的专家模型合成数据,合成了包括教科书、问答对以及代码片段等多种形式的数据。
预训练过程分为三个阶段。在第一阶段(S1),模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token。这一阶段为模型提供了基本的语言技能和通用知识。在第二阶段(S2),我们通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练。在最后阶段,我们使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。
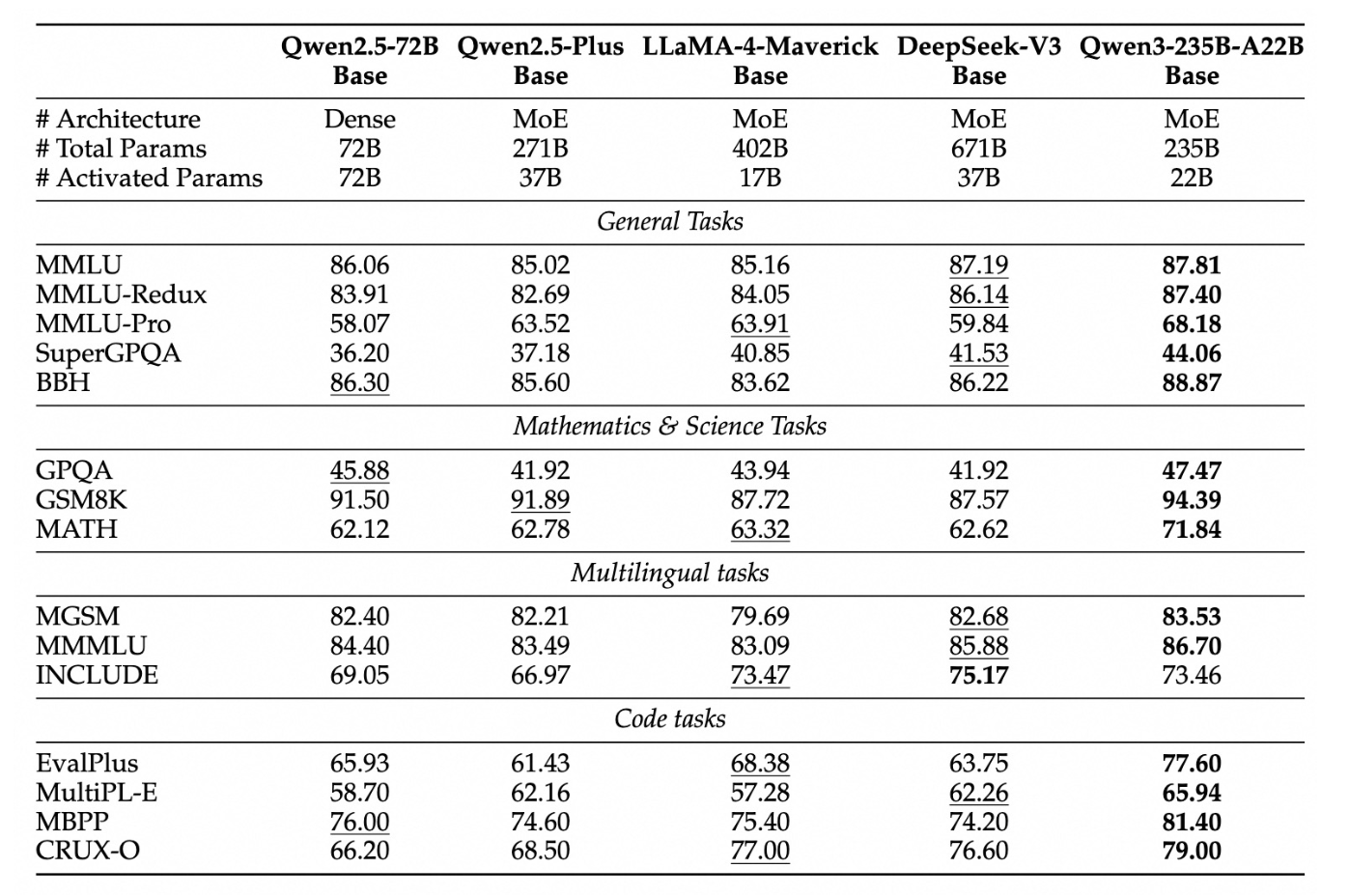
任务性能分类:
通用任务(General Tasks):如 MMLU(多任务语言理解)、BBH(复杂推理)。
数学与科学任务(Mathematics & Science Tasks):如 GSM8K(数学问题)、MATH(竞赛级数学题)。
多语言任务(Multilingual tasks):如 MGSM(多语言数学题)、INCLUDE(多语言常识推理)。
代码任务(Code tasks):如 EvalPlus(代码生成)、MBPP(Python 编程题)。
- 后训练:
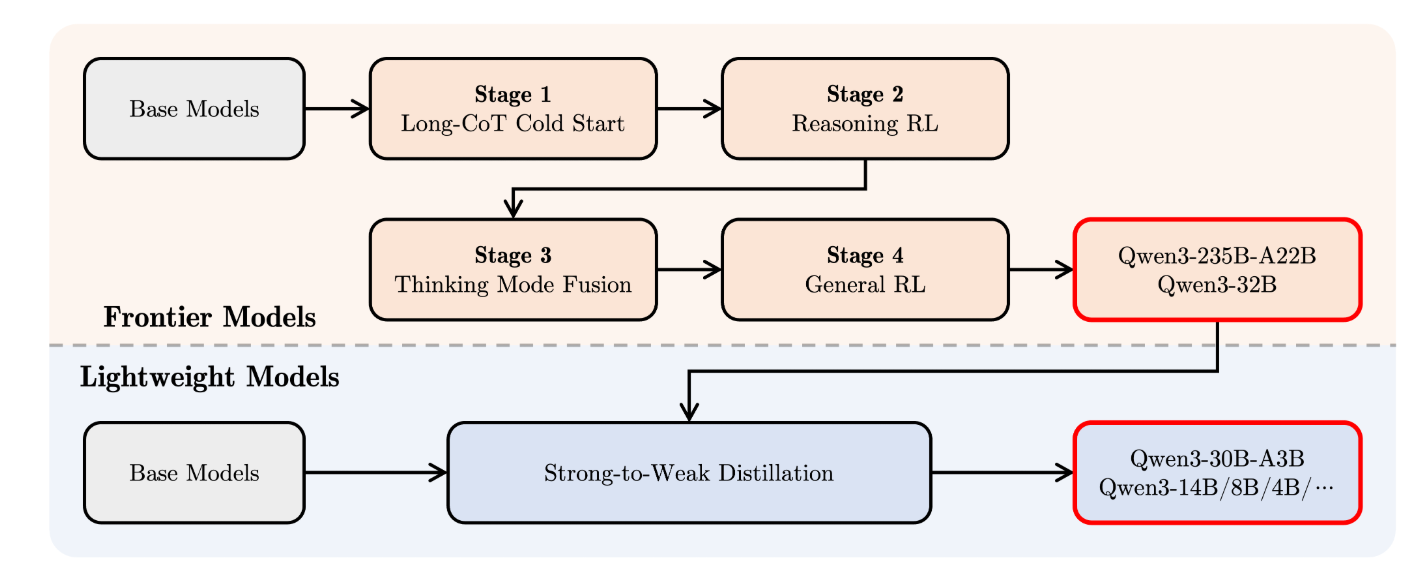
为了开发能够同时具备思考推理和快速响应能力的混合模型,实施了一个四阶段的训练流程。该流程包括:
(1)长思维链冷启动,(2)长思维链强化学习,(3)思维模式融合,(4)通用强化学习。
在第一阶段,我们使用多样的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力。第二阶段的重点是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。在第三阶段,我们在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。最后,在第四阶段,我们在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
- 使用Qwen3
以下是如何在不同框架中使用 Qwen3 的简单指南。首先,下面是一个在 Hugging Face transformers 中使用 Qwen3-30B-A3B 的标准示例:
1 from modelscope import AutoModelForCausalLM, AutoTokenizer 2 3 model_name = "Qwen/Qwen3-30B-A3B" 4 5 # load the tokenizer and the model 6 tokenizer = AutoTokenizer.from_pretrained(model_name) 7 model = AutoModelForCausalLM.from_pretrained( 8 model_name, 9 torch_dtype="auto", 10 device_map="auto" 11 ) 12 13 # prepare the model input 14 prompt = "Give me a short introduction to large language model." 15 messages = [ 16 {"role": "user", "content": prompt} 17 ] 18 text = tokenizer.apply_chat_template( 19 messages, 20 tokenize=False, 21 add_generation_prompt=True, 22 enable_thinking=True # Switch between thinking and non-thinking modes. Default is True. 23 ) 24 model_inputs = tokenizer([text], return_tensors="pt").to(model.device) 25 26 # conduct text completion 27 generated_ids = model.generate( 28 **model_inputs, 29 max_new_tokens=32768 30 ) 31 output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() 32 33 # parsing thinking content 34 try: 35 # rindex finding 151668 (</think>) 36 index = len(output_ids) - output_ids[::-1].index(151668) 37 except ValueError: 38 index = 0 39 40 thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n") 41 content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n") 42 43 print("thinking content:", thinking_content) 44 print("content:", content)
对于部署使用 sglang>=0.4.6.post1 或 vllm>=0.8.4 来创建一个与 OpenAI API 兼容的 API endpoint:
- SGLang
1 python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3
- vLLM
1 vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
要禁用思考模式,可以移除参数 --reasoning-parser(以及 --enable-reasoning)
- 高级用法
我们提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。示例如下:
1 from transformers import AutoModelForCausalLM, AutoTokenizer
2
3 class QwenChatbot:
4 def __init__(self, model_name="Qwen3-30B-A3B/Qwen3-30B-A3B"):
5 self.tokenizer = AutoTokenizer.from_pretrained(model_name)
6 self.model = AutoModelForCausalLM.from_pretrained(model_name)
7 self.history = []
8
9 def generate_response(self, user_input):
10 messages = self.history + [{"role": "user", "content": user_input}]
11
12 text = self.tokenizer.apply_chat_template(
13 messages,
14 tokenize=False,
15 add_generation_prompt=True
16 )
17
18 inputs = self.tokenizer(text, return_tensors="pt")
19 response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
20 response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
21
22 # Update history
23 self.history.append({"role": "user", "content": user_input})
24 self.history.append({"role": "assistant", "content": response})
25
26 return response
27
28 # Example Usage
29 if __name__ == "__main__":
30 chatbot = QwenChatbot()
31
32 # First input (without /think or /no_think tags, thinking mode is enabled by default)
33 user_input_1 = "How many r's in strawberries?"
34 print(f"User: {user_input_1}")
35 response_1 = chatbot.generate_response(user_input_1)
36 print(f"Bot: {response_1}")
37 print("----------------------")
38
39 # Second input with /no_think
40 user_input_2 = "Then, how many r's in blueberries? /no_think"
41 print(f"User: {user_input_2}")
42 response_2 = chatbot.generate_response(user_input_2)
43 print(f"Bot: {response_2}")
44 print("----------------------")
45
46 # Third input with /think
47 user_input_3 = "Really? /think"
48 print(f"User: {user_input_3}")
49 response_3 = chatbot.generate_response(user_input_3)
50 print(f"Bot: {response_3}")
- Agent示例
Qwen3 在工具调用能力方面表现出色。推荐使用 Qwen-Agent 来充分发挥 Qwen3 的 Agent 能力。Qwen-Agent 内部封装了工具调用模板和工具调用解析器,大大降低了代码复杂性。要定义可用的工具,您可以使用 MCP 配置文件,使用 Qwen-Agent 内置的工具,或者自行集成其他工具。
1 from qwen_agent.agents import Assistant
2
3 # Define LLM
4 llm_cfg = {
5 'model': 'Qwen3-30B-A3B',
6
7 # Use the endpoint provided by Alibaba Model Studio:
8 # 'model_type': 'qwen_dashscope',
9 # 'api_key': os.getenv('DASHSCOPE_API_KEY'),
10
11 # Use a custom endpoint compatible with OpenAI API:
12 'model_server': 'http://localhost:8000/v1', # api_base
13 'api_key': 'EMPTY',
14
15 # Other parameters:
16 # 'generate_cfg': {
17 # # Add: When the response content is `<think>this is the thought</think>this is the answer;
18 # # Do not add: When the response has been separated by reasoning_content and content.
19 # 'thought_in_content': True,
20 # },
21 }
22
23 # Define Tools
24 tools = [
25 {'mcpServers': { # You can specify the MCP configuration file
26 'time': {
27 'command': 'uvx',
28 'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
29 },
30 "fetch": {
31 "command": "uvx",
32 "args": ["mcp-server-fetch"]
33 }
34 }
35 },
36 'code_interpreter', # Built-in tools
37 ]
38
39 # Define Agent
40 bot = Assistant(llm=llm_cfg, function_list=tools)
41
42 # Streaming generation
43 messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
44 for responses in bot.run(messages=messages):
45 pass
46 print(responses)
参考:https://qwenlm.github.io/zh/blog/qwen3/
2025-04-29

 浙公网安备 33010602011771号
浙公网安备 33010602011771号