SRGAN图像超分重建算法Python实现(含数据集代码)
 本文介绍深度学习的SRGAN图像超分重建算法,使用Python以及Pytorch框架实现,包含完整训练、测试代码,以及训练数据集文件。博文介绍图像超分算法的原理,包括生成对抗网络和SRGAN模型原理和实现的代码,同时结合具体内容进行解释说明,完整代码资源文件请转至文末的下载链接。
本文介绍深度学习的SRGAN图像超分重建算法,使用Python以及Pytorch框架实现,包含完整训练、测试代码,以及训练数据集文件。博文介绍图像超分算法的原理,包括生成对抗网络和SRGAN模型原理和实现的代码,同时结合具体内容进行解释说明,完整代码资源文件请转至文末的下载链接。

摘要:本文介绍深度学习的SRGAN图像超分重建算法,使用Python以及Pytorch框架实现,包含完整训练、测试代码,以及训练数据集文件。博文介绍图像超分算法的原理,包括生成对抗网络和SRGAN模型原理和实现的代码,同时结合具体内容进行
解释说明,完整代码资源文件请转至文末的下载链接。
完整代码下载地址:https://download.csdn.net/download/qq_32892383/87953641
COCO训练数据集:https://pan.baidu.com/s/18xiqkK2m34TKo1FcKo0RJw?pwd=y5gf 提取码:y5gf
前言
一张低分辨率的图像要想放大为更高尺寸的图像,需要对确实的细节进行插值,常见的线性插值方法利用相邻像素的信息进行补充,但放大后图像模糊、质量低下的问题仍然存在。图像的超分辨率重建技术指的是将给定的低分辨率图像通过特定的算法恢复成相应的高分辨率图像。简单来理解超分辨率重建就是将小尺寸图像变为大尺寸图像,使图像更加“清晰”,但放大时通过了深度学习的技术补充了更多细节。
这种细节的补充并不是简单插值,而是在经过大量现实数据的训练后,针对细节的“推理”填充,你可以简单理解为和人在见过大量的高清照片后,对于模糊的相似部分能够“脑补”画面,根据画面大体轮廓将具体细节勾画出来。图像超分效果如下图所示:

可以看到,通过特定的超分辨率重建算法,使得原本模糊的图像变得清晰了,直至今日,依托深度学习技术,图像的超分辨率重建已经取得了非凡的成绩,在效果上愈发真实和清晰。至于应用就更加广泛,如医学成像、遥感、公共安防、视频感知等。在影视素材画质的增强恢复中,许多基于深度学习的超分重建技术得到了实际应用,比如Topaz Video Enhance AI软件。有了图像超分技术,从此再也不用忍受渣渣画质了,老司机萌觉得还可以怎么用呢。
1. 实现原理
图像的超分重建算法按照时间和效果,可以分为传统算法和深度学习算法两类。传统的超分辨率重建算法主要依靠基本的数字图像处理技术进行重建,常见的有基于插值的超分辨率重建、基于退化模型的超分辨率重建、基于学习的超分辨率重建等。
1.1 超分重建流程
基于深度学习进行超分辨率重建的算法,较早的要属SRCNN(Super-Resolution Convolutional Neural Network)算法了,作为开山之作,其原理简单。SRCNN利用深度学习模型和大批量样本数据的训练,在超分性能上超越了一大批传统图像处理算法,从此深度学习开始向超分辨率领域研究迈进。SRCNN的网络结构如下图所示:
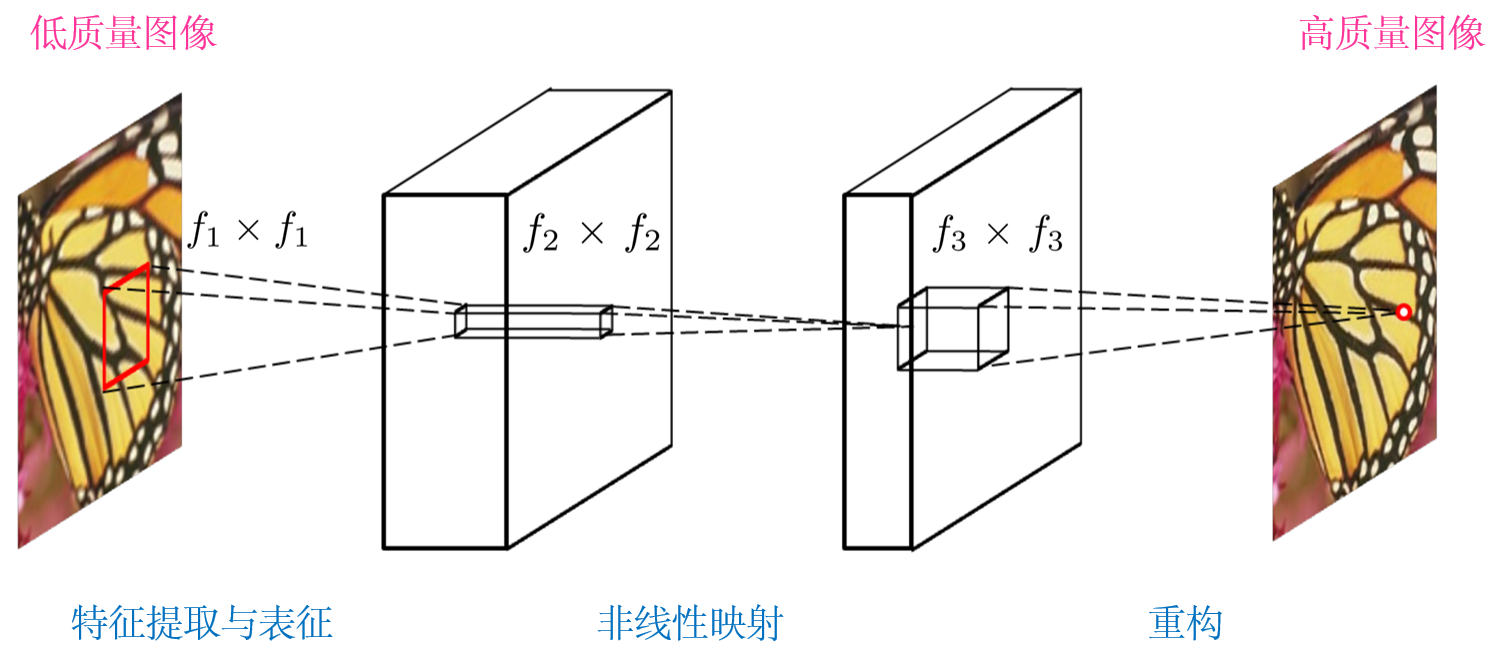
以上模型(博主已添加中文注释)来自Chao Dong等人的论文"Image Super-Resolution Using Deep Convolutional Networks",主要由一个三层结构的卷积神经网络(CNN)构成。对于一张低分辨率图像,首先使用双立方插值将其放大至目标尺寸,使用以上的CNN模型去拟合低分辨率图像与高分辨率图像之间的非线性映射,最后通过重构将网络输出的结果作为高分辨率图像。
SRCNN的流程可以简单理解为两步:图像放大和修复,如下图所示。其中,放大是采用某种方式(SRCNN采用插值上采样)将图像放大到指定倍数,再利用大数据的学习模型结合图像修复原理,将放大后的图像映射为最终输出目标。可以看出,超分辨率重建相比简单的插值放大,其在此基础上又具备了图像修复的作用,因此在超分性能上无疑大大增强。因此,超分辨率重建的很多算法也被学者迁移到图像修复领域中,完成一些诸如jpep压缩去燥、去模糊等任务。

除此之外,对于模型的训练其流程也具有参考意义:(1)寻找大量真实场景下的高清图像样本,对每张图片进行下采样处理以降低图像分辨率(如2倍下采样、4倍下采样等),这样经过下采样图像长宽均得到等比例缩小;(2)将采样后的图像作为低分辨率图像用于输入,采样前的图像作为高分辨率图像作为真实值,以此构成有效的训练样本集;(3)利用深度学习模型对低分辨率图像进行放大重建为高分辨率的输出结果,将其与原始高分辨率图像进行比较计算误差,调整模型参数并不断迭代,使得误差下降至最低;(4)训练完的模型可以用于对新的低分辨率图像进行重建,得到高分辨率图像。
1.2 SRResNet的深度网络
相比只有3个卷积层的SRCNN,SRResNet采用更深的网络结构模型,抽取出更高级的图像特征,深层模型对图像可以更好的进行表达,实现超分重构的性能也得到加强。深度残差网络(ResNet)的提出,很好解决了深层模型不能很好收敛的问题,其在图像分类、图像分割、目标检测等领域有着广泛应用。
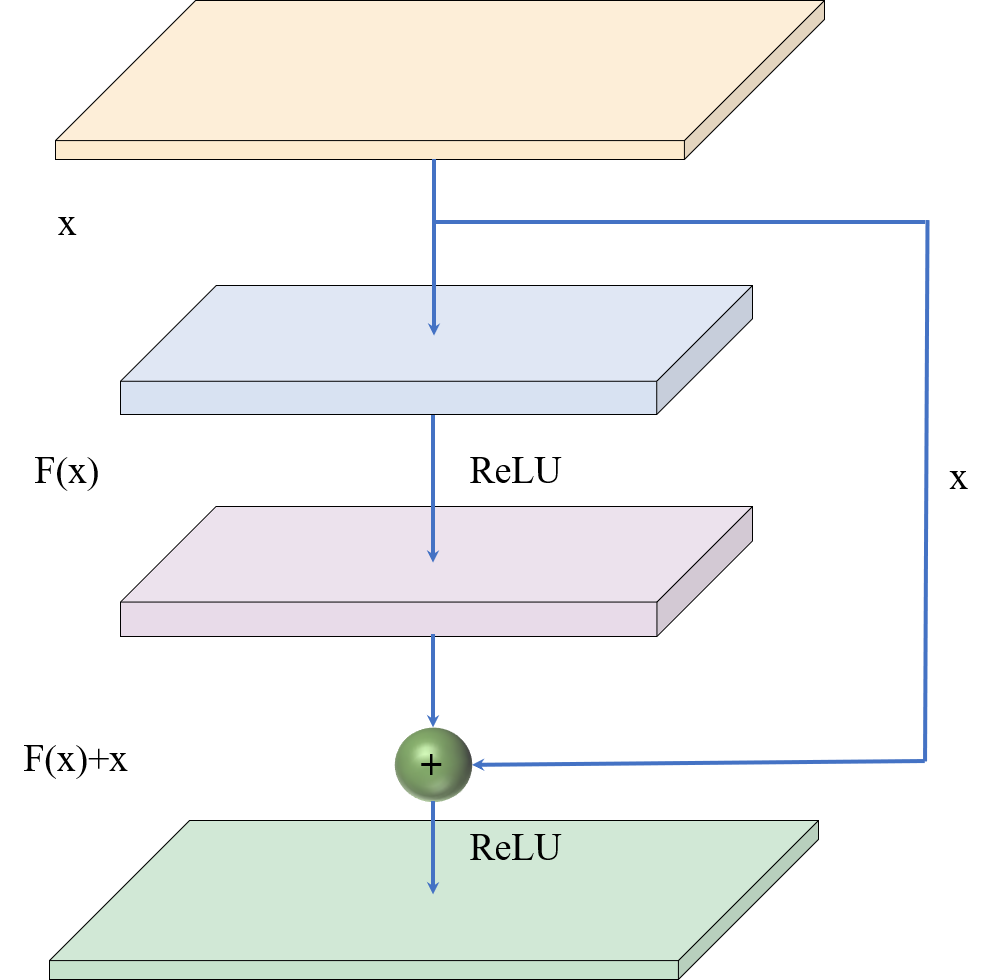
ResNet成功的重要一点,是在传统网络中引入了残差学习(Residual Learning),从而有效解决深层网络中梯度消失和精度下降的问题,使得网络层数能够大大加深。残差网络的原理图如下图所示,从图中可以看出原始数据x不仅有直接进入下一层的链接,还有一条跨越两层网络(跳链)的链接,将x带入到输出中,此时输出改为F(x)+x,使得整个模型训练时不容易发散。这里我绘制了一个残差模块,如下图所示:
至此可以借住ResNet的特性,在SRCNN的基础上我们就可以构建更加强大的网络结构,用于超分重建的深度神经网络。SRResNet模型的主干网络其实采用了这种网络结构,如下图所示:
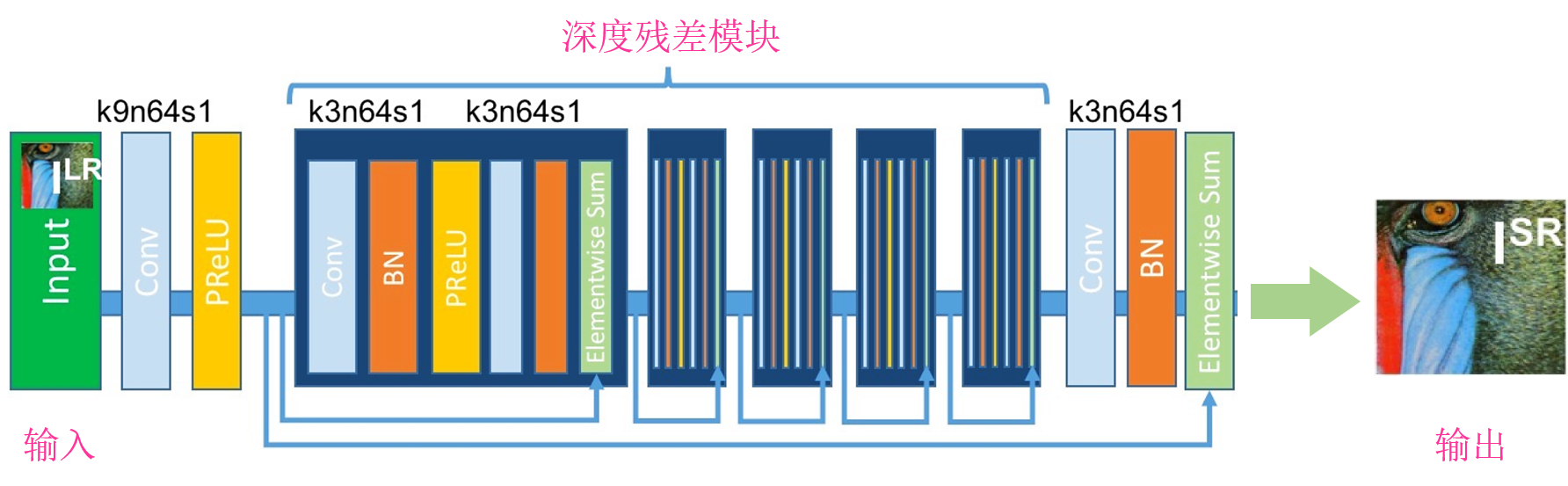
SRResNet模型中采用了多个深度残差模块(16个残差模块)对图像特征进行提取,保证整个网络稳定的同时,采用深度模型提升性能。以上模型中的卷积层仅仅改变了图像的通道数,并未修改图像尺寸,由此可见目前为止的模型仍然可以看出是SRCNN类似的修复模型。
SRResNet模型利用子像素卷积来放大图像,即在以上模型后继续添加两个子像素卷积模块,每个子像素卷积模块使得输入图像放大2倍,因此这个模型最终可以将图像放大4倍。SRResNet模型主要包含两部分:深度残差模型、子像素卷积模型。深度残差模型用来进行高效的特征提取,可以在一定程度上削弱图像噪点;子像素卷积模型主要用来放大图像尺寸,其结构如下图所示:
以上模型中,k表示卷积核大小,s为步长,n表示通道数。最后模型在输出前增加了一个卷积层用于数据调整和增强。为了训练模型SRResNet算法采用了MSE作为目标函数,即最小化模型输出的高分辨率图像(F(X)与原始分辨率图像(Y)的均方误差,其目标函数公式如下:
MSE被广泛应用于超分重建算法的目标函数,但使用该目标函数重建的超分图像可能出现不能很好符合人眼主观感受的问题,SRGAN算法则针对该问题进行了改进。
2. SRGAN 原理与代码实现
SRResNet算法通过深层的卷积模块完成特征映射,但也存在重建出的图像过于平滑,纹理细节信息丢失的缺陷。究其原因是采用MSE的目标函数,纹理细节处理难以满足人眼主观感受,为此如何“无中生有”重建纹理细节,那就需要利用生成对抗网络(Generative Adversarial Network, GAN)。
2.1 生成对抗网络简介
生成对抗网络(GAN)的灵感与博弈论中博弈的思想相契合,对于深度学习而言,不再是简单的单一模型(如SRResNet),而是构造两个深度学习模型:生成网络(Generator)和判别网络(Discriminator),两个模型相互博弈,即生成网络Generator产生以假乱真的图像,而判别网络Discriminator具备辨别图像真伪的能力,彼此在相互竞争对抗中达到更好效果。GAN的模型结构如下图所示:
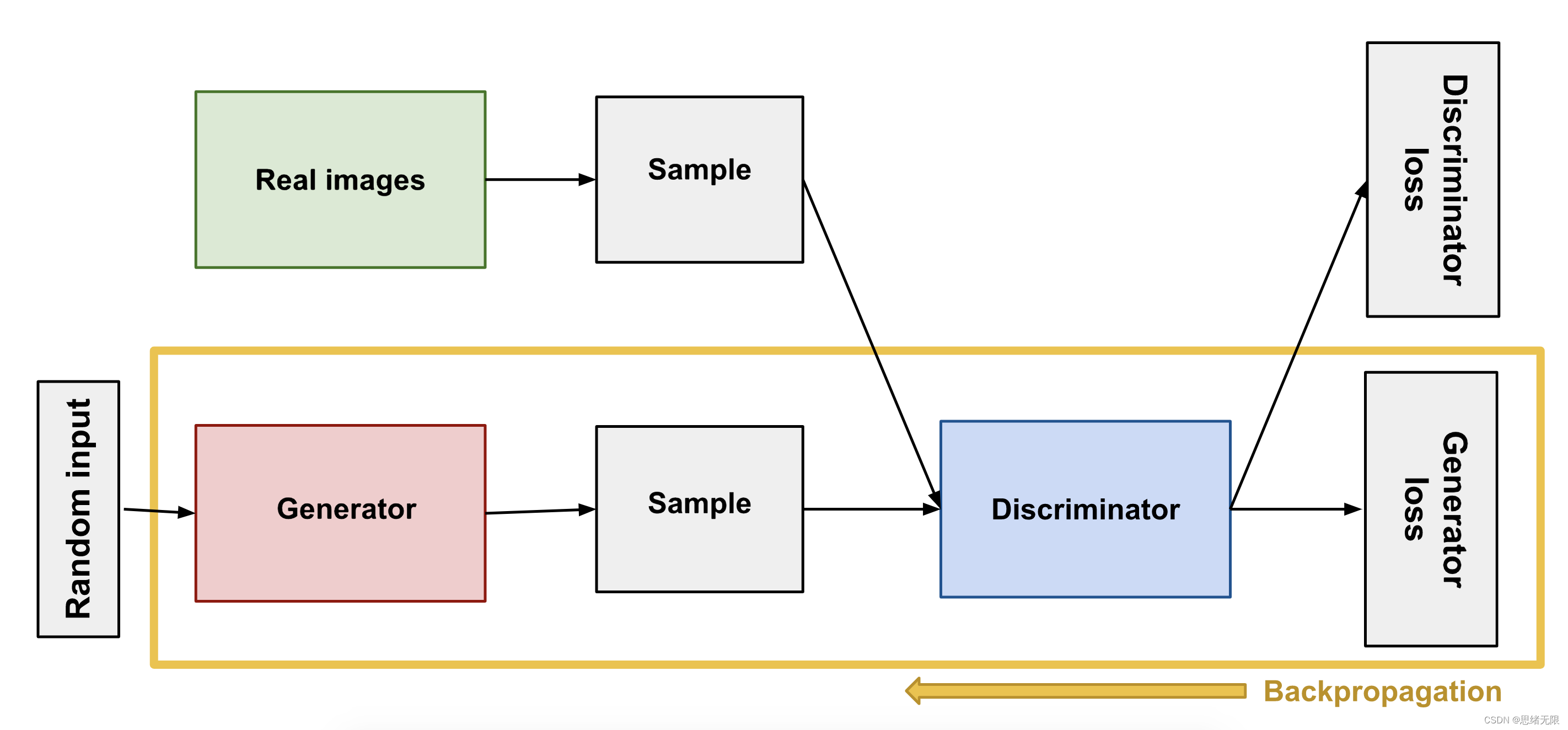
上图中生成网络和判别网络的主要功能:(1)生成网络(Generator),它通过某种特定的网络结构以及目标函数来生成图像;(2)判别网络(Discriminator),判别一张图片是不是“真实的”,即判断输入的照片是不是由Generator生成;Generator的作用就是尽可能的生成逼真的图像来迷惑Discriminator,使得Discriminator判断失败;而Discriminator的作用就是尽可能的挖掘Generator的破绽,来判断图像到底是不是由Generator生成的“假冒伪劣”。
GAN已经应用于图像补全、去噪,风格迁移,超分重建等图像领域,这里运用GAN能够减少损失函数的设计成本,从功能上看利用一定的基准,直接加上判别器,对抗训练会帮助我们解决很多问题。相比之前的简单模型,GAN可以产生更加清晰、真实的效果。
2.2 感知损失函数
在SRGAN中重新设计了新的损失函数——感知损失(Perceptual Loss),它由内容损失和对抗损失构成:1. 对抗损失:与一般GAN定义类似,即重建出的图像被判别器正确判断的损失;2. 内容损失:内容损失更加关注重建图片与真实高清图像的语义特征差异,而不是逐个像素之间的颜色亮度差异;SRGAN的作者考虑计算图像的固有特征差异,而固有特征提取其实早有专门模型被提出用于分类等任务。因此截取这些模型的特征提取模块,用于计算重建图像和真实图像的特征(语义特征)提取,然后在提取的特征层上再进行MSE计算。
值得一说的是,SRGAN在进行语义特征提取时,选取了VGG19模型,截取模型的有用部分后,截取的模型被称为truncated_vgg19模型。至此内容损失的计算总结如下:
- 根据SRResNet模型重建出超分图像(Super-Resolution,SR);
- 对于原始高清图像H和重建出的超分图像SR,分别应用truncated_vgg19模型,计算得到两幅图像的特征图H_fea和SR_fea;
- 计算推理后的特征图H_fea和SR_fea的MSE值;
2.3 SRGAN网络结构
SRGAN 是由 Christian Ledig 和他的团队在 2017 年的论文 "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network" 中提出的。在这篇论文中,他们提出了一种新的超分辨率方法,不仅可以恢复高分辨率图像的细节,还能使得生成的图像在视觉上更接近于真实图像。这种方法结合了深度学习中的生成对抗网络(GAN)和残差网络(ResNet),两者的结合提高了超分辨率的效果。SRGAN的网络结构由两部分组成,分别为生成器模型(Generator)和判别器模型(Discriminator)。
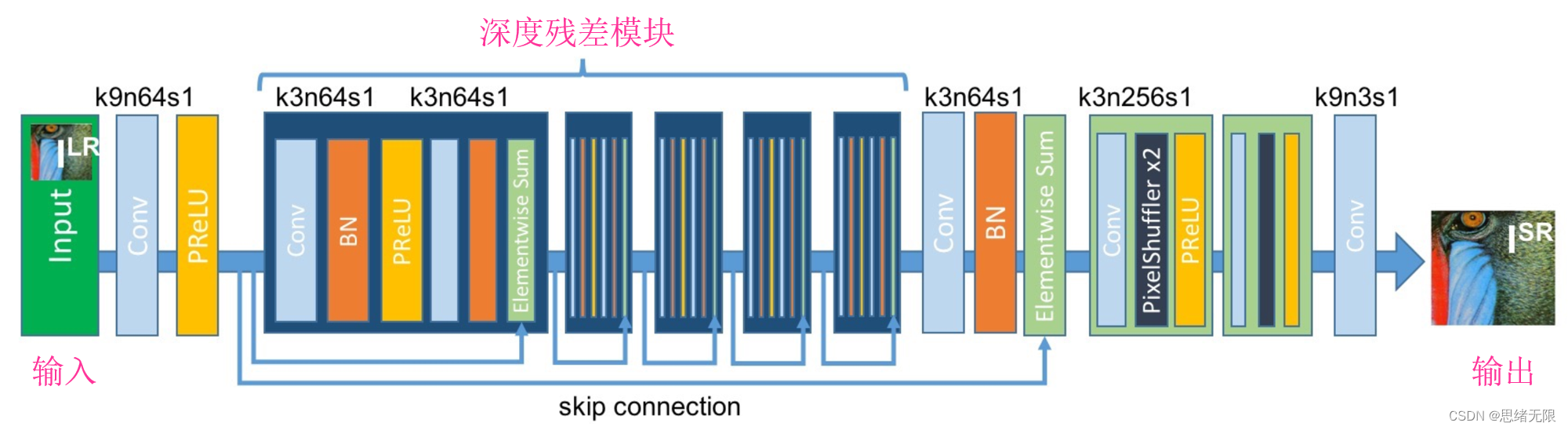
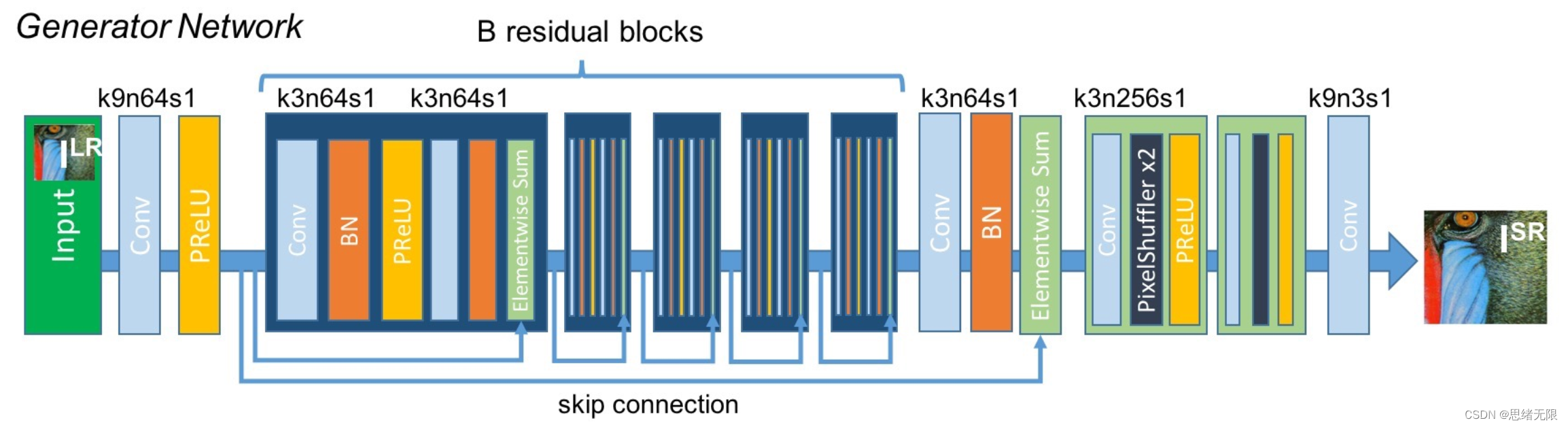
(1)生成器:生成器的目标是将低分辨率的输入图像变换为高分辨率图像。在 SRGAN 中,生成器是一个深度残差网络(Deep Residual Network)。其核心是一系列的残差块,每个残差块中包含两个卷积层,每个卷积层后面都跟有批量归一化(Batch Normalization)和参数化ReLU(PReLU)激活函数。在所有的残差块后,通过两个卷积层和一个像素级卷积层(PixelShuffle)将特征映射转换回高分辨率图像。这个结构允许模型学习低分辨率和高分辨率图像之间的残差映射,从而使得网络能够有效地重建高分辨率图像的细节。生成器的网络结构如下图所示:
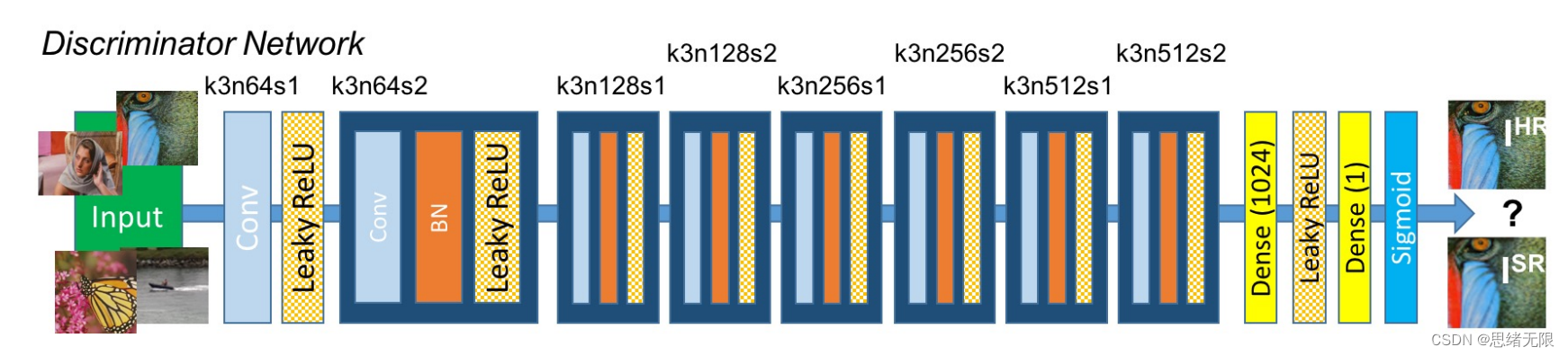
(2)判别器:判别器是一个卷积神经网络,其目标是区分生成的图像是否来自真实的高分辨率图像。在 SRGAN 中,判别器的网络结构是一个深度卷积神经网络,其中包括一系列的卷积层、批量归一化层和LeakyReLU激活函数。最后通过全连接层和sigmoid激活函数输出图像的真实性概率。判别器的网络结构如下图所示:
这两个网络相互对抗:生成器尝试生成越来越真实的图像以欺骗判别器,而判别器则努力提高其区分真实图像和生成图像的能力。通过这种对抗过程,模型最终可以生成出具有高质量细节的超分辨率图像。在实际操作中,SRGAN 需要大量的训练数据和计算资源,且训练过程需要一定的技巧和经验。尽管如此,SRGAN 仍然是图像超分辨率领域的一种重要技术,为生成逼真的高分辨率图像提供了一种有效的方法。
2.4 SRGAN网络训练
SRGAN 的训练主要分为两个阶段:预训练阶段和对抗训练阶段。
预训练阶段:这个阶段主要是为了训练生成器。SRGAN 中的生成器是一个深度残差网络,其目标是学习一个从低分辨率图像到高分辨率图像的映射。在预训练阶段,我们主要使用均方误差(MSE)作为损失函数,这样可以确保网络可以学习到一个相对精确的映射。这个阶段的训练可以使用高分辨率图像和对应的低分辨率图像作为训练数据。
对抗训练阶段:在预训练阶段结束后,我们得到了一个可以生成相对准确的高分辨率图像的生成器。然后,我们进入对抗训练阶段,这个阶段的目标是训练生成器和判别器进行对抗。在这个阶段,生成器的目标是生成尽可能真实的高分辨率图像以欺骗判别器,而判别器的目标是尽可能准确地区分真实的高分辨率图像和生成器生成的高分辨率图像。对抗训练的损失函数通常包括对抗损失和内容损失两部分。对抗损失来自判别器对生成图像的判别结果,内容损失则是生成图像和真实高分辨率图像在特征空间上的差异。
SRGAN 的损失函数主要包括两部分:对抗损失(Adversarial Loss)和感知损失(Perceptual Loss)。
对抗损失(Adversarial Loss):对抗损失主要用于衡量生成器生成的图像和真实图像在判别器中的判别结果的差距。对抗损失的目标是鼓励生成器生成能够欺骗判别器的图像。在 SRGAN 中,使用了交叉熵损失(Cross-Entropy Loss)作为对抗损失,其公式如下:
其中,G 是生成器,D 是判别器,\(I_{hr}\)是真实的高分辨率图像,\(I_{lr}\) 是低分辨率图像。
感知损失(Perceptual Loss):感知损失则用于衡量生成图像和真实图像在特征空间上的差距。在 SRGAN 中,感知损失包括内容损失(Content Loss)和纹理损失(Texture Loss)。内容损失是通过预训练的 VGG19 网络提取出的特征图之间的欧几里得距离,纹理损失则是生成图像和真实图像的 Gram 矩阵之间的差距。感知损失的公式如下:
其中,𝜙 是 VGG19 的特征提取函数,\(\phi_{gram}\) 是 Gram 矩阵的计算函数,λ 是纹理损失的权重。
总的损失函数就是这两部分的加权和:
其中,α 是感知损失的权重。
3. 代码编写
这里我们使用pytorch实现以上的SRGAN网络,模型代码如下:
class SRResNet(nn.Module):
"""
SRResNet模型
"""
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=4):
"""
:参数 large_kernel_size: 第一层卷积和最后一层卷积核大小
:参数 small_kernel_size: 中间层卷积核大小
:参数 n_channels: 中间层通道数
:参数 n_blocks: 残差模块数
:参数 scaling_factor: 放大比例
"""
super(SRResNet, self).__init__()
# 放大比例必须为 2、 4 或 8
scaling_factor = int(scaling_factor)
assert scaling_factor in {2, 4, 8}, "放大比例必须为 2、 4 或 8!"
# 第一个卷积块
self.conv_block1 = ConvolutionalBlock(in_channels=3, out_channels=n_channels, kernel_size=large_kernel_size,
batch_norm=False, activation='PReLu')
# 一系列残差模块, 每个残差模块包含一个跳连接
self.residual_blocks = nn.Sequential(
*[ResidualBlock(kernel_size=small_kernel_size, n_channels=n_channels) for i in range(n_blocks)])
# 第二个卷积块
self.conv_block2 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels,
kernel_size=small_kernel_size,
batch_norm=True, activation=None)
# 放大通过子像素卷积模块实现, 每个模块放大两倍
n_subpixel_convolution_blocks = int(math.log2(scaling_factor))
self.subpixel_convolutional_blocks = nn.Sequential(
*[SubPixelConvolutionalBlock(kernel_size=small_kernel_size, n_channels=n_channels, scaling_factor=2) for i
in range(n_subpixel_convolution_blocks)])
# 最后一个卷积模块
self.conv_block3 = ConvolutionalBlock(in_channels=n_channels, out_channels=3, kernel_size=large_kernel_size,
batch_norm=False, activation='Tanh')
def forward(self, lr_imgs):
"""
前向传播.
:参数 lr_imgs: 低分辨率输入图像集, 张量表示,大小为 (N, 3, w, h)
:返回: 高分辨率输出图像集, 张量表示, 大小为 (N, 3, w * scaling factor, h * scaling factor)
"""
output = self.conv_block1(lr_imgs) # (16, 3, 24, 24)
residual = output # (16, 64, 24, 24)
output = self.residual_blocks(output) # (16, 64, 24, 24)
output = self.conv_block2(output) # (16, 64, 24, 24)
output = output + residual # (16, 64, 24, 24)
output = self.subpixel_convolutional_blocks(output) # (16, 64, 24 * 4, 24 * 4)
sr_imgs = self.conv_block3(output) # (16, 3, 24 * 4, 24 * 4)
return sr_imgs
在SRGAN模型中,SRResNet是核心的一部分,也就是生成器模型。生成器的任务是从低分辨率图像生成高分辨率图像。以下是 SRResNet 模型的主要结构:
- 第一卷积块(conv_block1):这个模块用于接收输入的低分辨率图像,并进行初始的特征提取。这里使用了预激活的ReLU (PReLU)
作为激活函数,并且不使用批归一化。卷积核的大小是大核大小(large_kernel_size),默认为9。 - 残差块(residual_blocks):这是一系列的残差模块。每个残差模块都包含两个卷积层和一个跳跃连接。这里默认使用了16个残差模块。
- 第二卷积块(conv_block2):这个模块用于提取特征图的更深层次的信息。这里使用了批归一化和ReLU激活函数,但是没有使用偏置项。
- 子像素卷积块(subpixel_convolutional_blocks):这些模块用于将图像放大到目标的高分辨率。每个子像素卷积模块都能将图像的分辨率放大两倍。根据我们设置的放大比例(scaling_factor),可能会有多个子像素卷积模块串联在一起。
- 最后的卷积块(conv_block3):这个模块用于生成最后的高分辨率图像。这里使用了tanh作为激活函数,可以将像素值约束在-1到1之间。
其中forward 函数描述了模型的前向传播过程。首先,我们通过第一卷积块处理输入的低分辨率图像,然后将结果保存在residual变量中,作为跳跃连接的参考。将处理后的结果送入残差模块进行特征提取和非线性变换。然后再次使用卷积操作对特征图进行处理,并将结果与residual变量相加,实现了特征图的跳跃连接。通过子像素卷积模块进行上采样操作,将图像的分辨率提升到目标的高分辨率。最后通过最后的卷积块生成最终的高分辨率图像。
3.1 生成器模型代码
生成器(Generator)模型是 SRGAN 中的一个关键部分,其核心任务是从低分辨率图像生成高分辨率图像。在这段代码中,生成器的结构与 SRResNet 完全一致,其主要代码如下:
class Generator(nn.Module):
"""
生成器模型,其结构与SRResNet完全一致.
"""
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=4):
"""
参数 large_kernel_size:第一层和最后一层卷积核大小
参数 small_kernel_size:中间层卷积核大小
参数 n_channels:中间层卷积通道数
参数 n_blocks: 残差模块数量
参数 scaling_factor: 放大比例
"""
super(Generator, self).__init__()
self.net = SRResNet(large_kernel_size=large_kernel_size, small_kernel_size=small_kernel_size,
n_channels=n_channels, n_blocks=n_blocks, scaling_factor=scaling_factor)
def forward(self, lr_imgs):
"""
前向传播.
参数 lr_imgs: 低精度图像 (N, 3, w, h)
返回: 超分重建图像 (N, 3, w * scaling factor, h * scaling factor)
"""
sr_imgs = self.net(lr_imgs) # (N, n_channels, w * scaling factor, h * scaling factor)
return sr_imgs
以上代码将 SRResNet 作为一个内部网络 (self.net),并在 forward 方法中调用它来执行超分辨率转换,包括以下生成器模型的主要部分:
(1)内部网络(net):这个模块是我们之前定义的 SRResNet 模型。其参数,如大核尺寸(large_kernel_size)、小核尺寸(small_kernel_size)、通道数(n_channels)、残差模块数量(n_blocks)和放大比例(scaling_factor),都会直接传递给 SRResNet 模型。
(2)forward 方法描述了模型的前向传播过程。它接收低分辨率图像,然后通过 SRResNet 模型生成超分辨率图像。其中,lr_imgs 是输入的低分辨率图像,形状为 (N, 3, w, h);sr_imgs 是输出的超分辨率图像,形状为 (N, 3, w * scaling_factor, h * scaling_factor)。
3.2 判别器模型代码
判别器(Discriminator)是 SRGAN 模型的另一个关键部分,其任务是判断输入图像是否为真实的高分辨率图像。在训练过程中,判别器和生成器进行博弈,共同推动模型的进步,其主要代码如下:
class Discriminator(nn.Module):
"""
SRGAN判别器
"""
def __init__(self, kernel_size=3, n_channels=64, n_blocks=8, fc_size=1024):
"""
参数 kernel_size: 所有卷积层的核大小
参数 n_channels: 初始卷积层输出通道数, 后面每隔一个卷积层通道数翻倍
参数 n_blocks: 卷积块数量
参数 fc_size: 全连接层连接数
"""
super(Discriminator, self).__init__()
in_channels = 3
# 卷积系列,参照论文SRGAN进行设计
conv_blocks = list()
for i in range(n_blocks):
out_channels = (n_channels if i is 0 else in_channels * 2) if i % 2 is 0 else in_channels
conv_blocks.append(
ConvolutionalBlock(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=1 if i % 2 is 0 else 2, batch_norm=i is not 0, activation='LeakyReLu'))
in_channels = out_channels
self.conv_blocks = nn.Sequential(*conv_blocks)
# 固定输出大小
self.adaptive_pool = nn.AdaptiveAvgPool2d((6, 6))
self.fc1 = nn.Linear(out_channels * 6 * 6, fc_size)
self.leaky_relu = nn.LeakyReLU(0.2)
self.fc2 = nn.Linear(1024, 1)
# 最后不需要添加sigmoid层,因为PyTorch的nn.BCEWithLogitsLoss()已经包含了这个步骤
def forward(self, imgs):
"""
前向传播.
参数 imgs: 用于作判别的原始高清图或超分重建图,张量表示,大小为(N, 3, w * scaling factor, h * scaling factor)
返回: 一个评分值, 用于判断一副图像是否是高清图, 张量表示,大小为 (N)
"""
batch_size = imgs.size(0)
output = self.conv_blocks(imgs)
output = self.adaptive_pool(output)
output = self.fc1(output.view(batch_size, -1))
output = self.leaky_relu(output)
logit = self.fc2(output)
return logit
在以上代码中,定义了判别器模型的主要部分:
- 卷积块序列(conv_blocks):这是一个由多个卷积块组成的序列。每个卷积块都包含一个卷积层,然后可能跟随一个批归一化层,最后是一个LeakyReLU 激活函数。这些卷积块的参数(比如卷积核大小、输入/输出通道数、是否使用批归一化等)都是根据 SRGAN论文中的说明进行设置的。
- 自适应平均池化层(adaptive_pool):这一层的作用是将卷积块序列的输出调整到固定的大小(6x6),以便接下来可以连接全连接层。
- 全连接层(fc1和fc2):第一个全连接层(fc1)用于将自适应平均池化层的输出扁平化,并通过线性变换降低维度到指定的尺寸(fc_size,这里设置为1024)。然后经过LeakyReLU激活函数,再连接到第二个全连接层(fc2),最终输出一个分数值,用于判断输入的图像是否为真实的高分辨率图像。
forward 函数描述了模型的前向传播过程。它接收输入的图像,首先经过卷积块序列进行特征提取,然后经过自适应平均池化层将特征调整到固定的大小,接着通过两个全连接层输出一个评分值。其中,imgs 是输入的图像,形状为 (N, 3, w * scaling_factor, h * scaling_factor);logit 是输出的评分值,形状为 (N)。
需要注意的是,这里并没有在模型的最后添加 Sigmoid 层,因为在计算损失时,我们会使用 PyTorch 的 nn.BCEWithLogitsLoss() 函数,这个函数内部已经包含了 Sigmoid 函数的计算步骤。
3.3 测试生成图像代码
以下代码介绍了如何使用训练好的 SRGAN 生成器模型进行图像的超分辨率恢复。先贴上代码然后我后面再详细解释这个过程:
# -*- coding: utf-8 -*-
import time
from models import Generator
from utils import *
# 测试图像
imgPath = './images/girl1.jpg'
# 模型参数
large_kernel_size = 9 # 第一层卷积和最后一层卷积的核大小
small_kernel_size = 3 # 中间层卷积的核大小
n_channels = 64 # 中间层通道数
n_blocks = 16 # 残差模块数量
scaling_factor = 4 # 放大比例
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == '__main__':
# 预训练模型
srgan_checkpoint = "./models/checkpoint_srgan.pth"
# 加载模型SRResNet 或 SRGAN
checkpoint = torch.load(srgan_checkpoint, map_location=device)
generator = Generator(large_kernel_size=large_kernel_size,
small_kernel_size=small_kernel_size,
n_channels=n_channels,
n_blocks=n_blocks,
scaling_factor=scaling_factor)
generator = generator.to(device)
generator.load_state_dict(checkpoint['generator'])
generator.eval()
model = generator
# 加载图像
img = Image.open(imgPath, mode='r')
img = img.convert('RGB')
# 双线性上采样
Bicubic_img = img.resize((int(img.width * scaling_factor), int(img.height * scaling_factor)), Image.BICUBIC)
Bicubic_img.save('./results/test_bicubic.jpg')
# 图像预处理
lr_img = convert_image(img, source='pil', target='imagenet-norm')
lr_img.unsqueeze_(0)
# 记录时间
start = time.time()
# 转移数据至设备
lr_img = lr_img.to(device) # (1, 3, w, h ), imagenet-normed
# 模型推理
with torch.no_grad():
sr_img = model(lr_img).squeeze(0).cpu().detach() # (1, 3, w*scale, h*scale), in [-1, 1]
sr_img = convert_image(sr_img, source='[-1, 1]', target='pil')
sr_img.save('./results/test_srgan.jpg')
print('用时 {:.3f} 秒'.format(time.time() - start))
以上代码给出了如何使用 SRGAN 进行图像超分辨率恢复的整个过程,你可以通过改变测试图像或模型的参数来看看模型的效果如何变化,这段代码包括了以下环节。
-
设置参数:首先定义了一些模型和测试图像的参数,包括图像的路径,模型的参数(如卷积核大小,通道数,残差模块数量和放大比例等)和设备(优先使用 GPU,如果没有则使用 CPU)。
-
加载模型:使用 torch.load() 函数加载预训练的 SRGAN 模型,并把模型移到相应的设备上。之后设置模型为评估模式,这意味着模型中的某些层(如批归一化和丢弃)会根据需要更改行为。
-
加载和处理图像:使用 PIL 库加载测试图像,并将其转换为 RGB 格式。然后使用双线性插值方法将图像大小调整到目标大小,并保存结果。接下来,对图像进行预处理,将其从 PIL 图像转换为适合模型输入的张量,并增加一个批处理维度。
-
模型推理:首先记录推理开始的时间,然后将预处理后的图像移到相应的设备上。然后,使用 torch.no_grad() 上下文管理器禁止梯度计算(因为在推理过程中不需要计算梯度,这样可以节省内存),并将图像输入模型进行超分辨率恢复。最后,将模型输出的张量转换回 PIL 图像,并保存结果。
-
打印推理时间:计算模型推理的时间,并打印结果。
运行出来的结果如下图所示,可以对比一下效果,当然不同的图片可能恢复的效果不一样。

4. 下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,py文件等,如下图),这里已打包上传至博主的csdn下载频道获取。
完整代码下载地址:https://download.csdn.net/download/qq_32892383/87953641
COCO训练数据集:https://pan.baidu.com/s/18xiqkK2m34TKo1FcKo0RJw?pwd=y5gf 提取码:y5gf
Python版本:3.8,请勿使用其他版本,需要安装的依赖请见requirements.txt文件
安装环境步骤如下:
(1)首先打开系统的cmd终端(不要用powershell),使用以下命令将命令行路径切换到你的代码所在的文件夹(.../你的路径/SRGAN)下:
cd G:\BlogCode\SRGAN
G:
上面我的代码在G盘,你应该切换到自己的文件夹路径,然后再次输入"G:"命令防止没切换过来:
(2)输入conda命令创建一个python 3.8的环境,代码如下:
conda create -n env_rec python=3.8
等待环境创建完毕后,使用以下命令激活环境:
conda activate env_rec
(3)激活环境后可以使用pip读取requirements.txt中的依赖库版本进行安装:
pip install -r requirements.txt
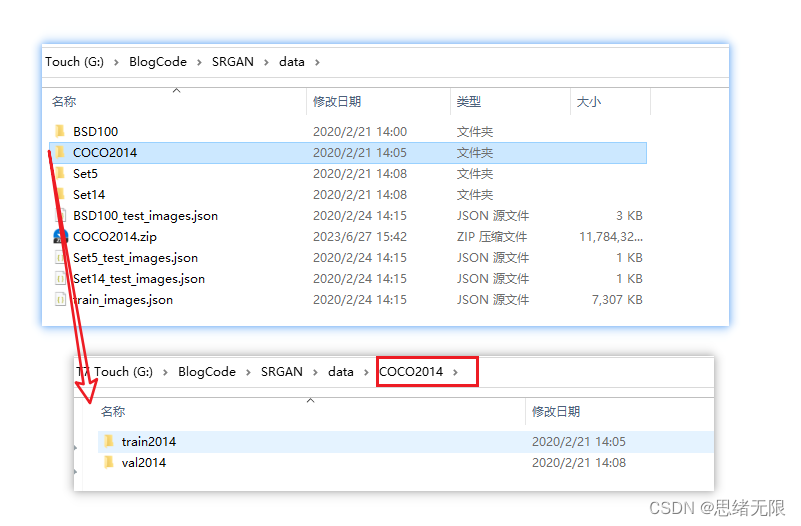
等待完全安装完毕,此时你可以在pycharm的环境配置中选择刚刚新建的环境运行了。如果需要重新训练模型,你需要先下载COCO数据集然后解压到SRGAN文件夹下的data文件夹中,我已经打包好该数据集其网盘地址如下:
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号