HashMap、LRU、散列表
HashMap
Hash:从数据中提出摘要信息,数字指纹,验证唯一性,完整性。
- HashMap 的数据结构:HashMap 实际上是一个数组和链表(“链表散列”)的数据结构。底层就是一个数组结构,数组中的每一项又是一个链表。
entry 每个元素

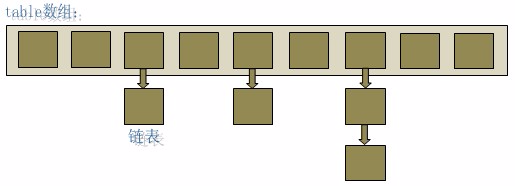
- 通过 hashCode 来算出指定数组的索引可以快速定位到要找的对象在数组中的位置,之后再遍历链表找到对应值,理想情况下时间复杂度为 O(1)
- 不同对象可以拥有相同的 hashCode(hash 碰撞),发生碰撞后会把相同 hashcode 的对象放到同一个链表里,但是在数组大小不变的情况下,存放键值对越多,查找的时间效率也会降低
- 扩容可以解决该问题,而负载因子决定了什么时候扩容,负载因子是已存键值对的数量和总的数组长度的比值。默认情况下负载因子为0.75,我们可在初始化 HashMap 的时候自己修改。阀值 = 当前数组长度✖负载因子
- hashmap 中默认负载因子为0.75,长度默认是16,默认情况下第一次扩容判断阀值是16 ✖ 0.75 = 12;所以第一次存键值对的时候,在存到第13个键值对时就需要扩容了, 变成16X2=32。Hashmap 的 hash 算法?
- 每次扩容是至少是当前大小的2倍,扩容的大小一定是2^n,;另外,扩容后还需要将原来的数据都 transfer 到新的 table,这是耗时操作。
- Java8中链表长度超过8时会把长度超过8的链表转化成红黑树;说说红黑树的优点
- hashCode 是一个对象的标识,Java 中对象的 hashCode 是一个 int 类型值。
在不考虑哈希冲突的情况下,在哈希表中的增减、查找操作的时间复杂度为的 O (1)。HashMap 是如何做到这么优秀的 O (1)呢?核心在于哈希函数能将 key 直接转换成哈希表中的存储位置,而哈希表本质是一个数组,在指定下标的情况下查找数组成员是一步到位的。
红黑树只是做到了近似平衡(通过旋转和变色),并不是严格的平衡,所以在维护平衡的成本上,要比 AVL 树要低。
红黑树是一种平衡二叉查找树。它是为了解决普通二叉查找树在数据更新的过程中,复杂度退化的问题而产生的。红黑树的高度近似 log2n,所以它是近似平衡,插入、删除、查找操作的时间复杂度都是 O (logn)。
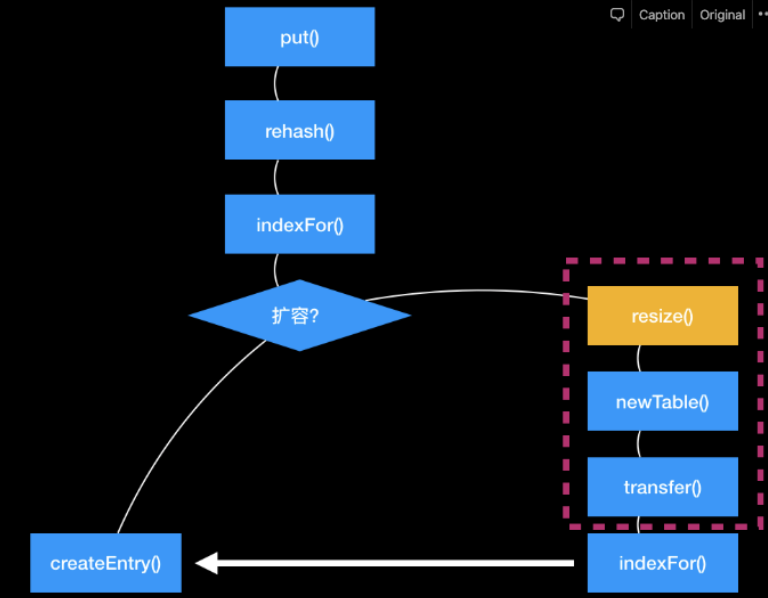
put 流程
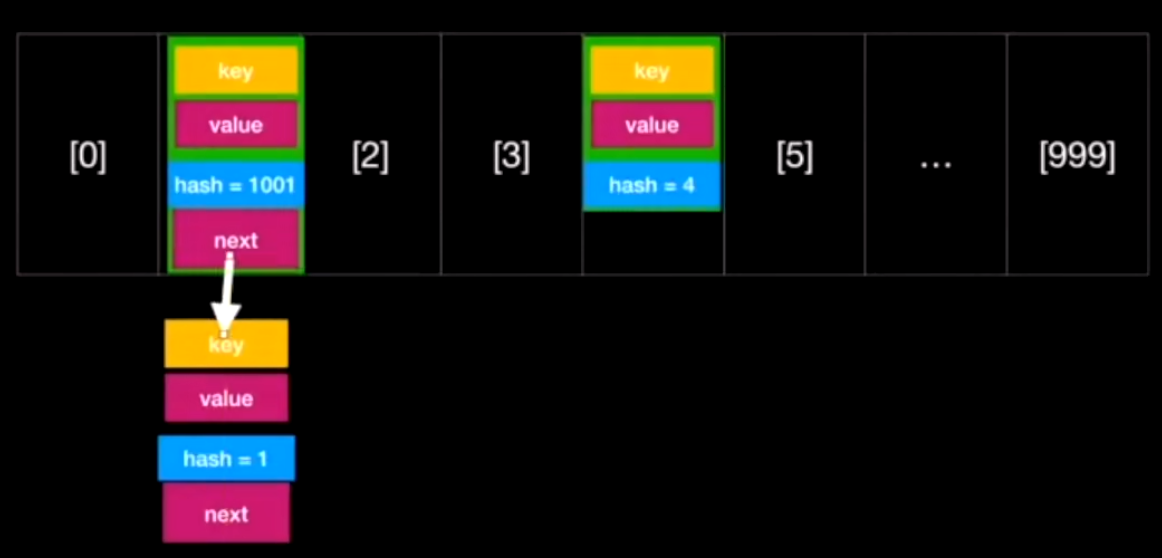
Map. Entry 里就这四个数据
- 对 key hash,二次 hash,hash 扰乱函数,减少 hash 碰撞
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capitity -1); //capicity表示散列表的大小
}
获取对象的 hashcode 以后,先进行移位运算,然后再和自己做异或运算,即:hashcode ^ (hashcode >>> 16),这一步甚是巧妙,是将高16位移到低16位,这样计算出来的整型值将“具有”高位和低位的性质.
每个槽(链表)里的数据比较平均,增加了哈希值的随机性和分布性。这有助于减少哈希冲突的可能性,即不同键具有相同哈希值的情况。
- 通过 hash 算出数组角标(indexfor())
- 如果 key 相同就把值覆盖;没有的话添加元素
- 添加元素,看是否需要扩容,需要的话变数组变成原来的2倍,把旧的拷贝到新的数组上去,然后旧的指针指向新的。
static int indexFor(int h, int length) {
return h & (length-1);
}
h(哈希码)和 length(数组长度)
位运算快于十进制运算
而按位与 计算的原则是两位同时为“1”,结果才为“1”,否则为“0”。所以 h& (length-1)运算从数值上来讲其实等价于对 length 取模(两个数相除的余数),也就是 h%length。
假设当前 table 的 length 是15,二进制表示为1111,那么 length-1就是1110,此时有两个 hash 值为8和9的 key 需要计算索引值,计算过程如下:
8的二进制表示:1000
8 &(length-1)= 1000 & 1110 = 1000,索引值即为8;
9的二进制表示:1001
9 &(length-1)= 1001 & 1110 = 1000,索引值也为8;
这样一来就产生了相同的索引值,也就是说两个 hash 值为8和9的 key 会定位到数组中的同一个位置上形成链表,这就产生了碰撞。
get 流程
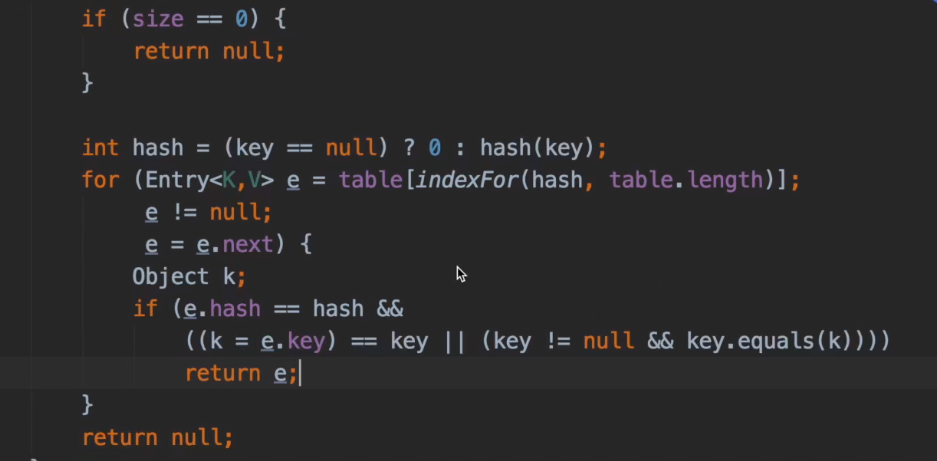
- get 对 key hash,找到数组角标(indexfor())
- 如果 hash 相同 key 相同就找到了
- 如果 hash 相同 key 不相同,找链表的下一个(通过值找)
其他问题
-
1.7 的 HashMap 怎么在链表上添加数据,在链表的前⾯还是链表的后⾯?
「头插法」 -
1.7 HashMap 是怎么预防和解决 Hash 冲突的。
「⼆次哈希」+「拉链法」 -
1.7 HashMap 默认容量是多少?为什么是 16 可以是 15 吗?
16,需要是 2 的幂次⽅ -
1.7 HashMap 的数组是什么时候创建的?
⾸次调⽤ put 时 -
1.7 和 1.8 数据结构有什么不同?
1.8 增加了转换为红⿊树 -
插⼊数据的⽅式
1.7 的链表从前⾯插⼊,1.8 的链表从后⾯插⼊ -
扩容后存储位置的计算⽅式
1.7 通过再次 indexFor () 找到数组位置,1.8 通过⾼低位的桶直接在链表尾部添加。 -
HashMap 什么时候会把链表转化为红⿊树?
链表⻓度超过 8 ,并且数组⻓度不⼩于 64
在 JDK1.8 版本中,为了对 HashMap 做进一步优化,我们引入了红黑树。而当链表长度太长(默认超过 8)时,链表就转换为红黑树。我们可以利用红黑树快速增删改查的特点,提高 HashMap 的性能。当红黑树结点个数少于 8 个的时候,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显。
HashMap 存对象
HashMap 是基于哈希表的 Map 接口的非同步实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。如果要用对象作为 key 的话需要重新该对象的 equals 方法和 hashCode 方法。
new 一个新的对象时,地址变了,不能保证 hash 值和 equals 结果还是一样。所以取不到对应的 value。
Map<People,Integer> map = new HashMap<People, Integer>();
map.put(new People("liu",18),5);
People p = new People("liu",18);
System.out.println(map.get(p)); //不重写的话就是null
优化 hashmap
第一种:
HashMap 默认的初始大小是 16,当然这个默认值是可以设置的,如果事先知道大概的数据量有多大,可以通过修改默认初始大小,减少动态扩容的次数,这样会大大提高 HashMap 的性能。
第二种:提高锁的粒度,精确锁的分布。
第三种:ConcurrentHashMap
第四种使用: [[SparseArray 和 ArrayMap]]
WeakValueHashMap
WeakReference 是“弱键”实现的哈希表。它这个“弱键”的目的就是:实现对“键值对”的动态回收。当“弱键”不再被使用到时,GC 会回收它,WeakReference 也会将“弱键”对应的键值对删除。
“弱键”是一个“弱引用 (WeakReference)”,在 Java 中,WeakReference 和 ReferenceQueue 是联合使用的。在 WeakHashMap 中亦是如此:如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。接着,WeakHashMap 会根据“引用队列”,来删除“WeakHashMap 中已被 GC 回收的‘弱键’对应的键值对”。
ConcurrentHashMap
- Concurrent 作用是处理并发情况的 HashMap,多线程并发下 HashMap 是不安全的 (如死循环),更普遍的是多线程并发下,由于堆内存对于各个线程是共享的,而 HashMap 的 put 方法不是原子操作,假设 Thread1先 put 值,然后 sleep 2秒 (也可以是系统时间片切换失去执行权),在这2秒内值被 Thread2改了,Thread1“醒来”再 get 的时候发现已经不是原来的值了,这就容易出问题。
- 如何避免这种多线程“奥迪变奥拓”的情况呢?常规思路就是给 HashMap 的 put 方法加锁 (synchronized),保证同一个时刻只允许一个线程拥有对 hashmap 有写的操作权限即可。然而假如线程1中操作耗时,其他需要操作该 hashmap 的线程就需要在门口排队半天,严重影响用户体验 (HashTable 就是这么干的)。
- ConcurrentHashMap 所使用的锁分段技术,每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
- 对 ConcurrentHashMap 边遍历边删除或者增加操作不会产生异常 (可以不用迭代方式删除元素),因为其内部已经做了维护,遍历的时候都能获得最新的值。即便是多个线程一起删除、添加元素也没问题。
最近最少使用算法
什么时候用过
在存视频和对应的进度的时候用过
使用场景
临时的比较多的数据,就可以使用
private LRUCache<String, Long> mVideoPositionMap = new LRUCache<>(50);
public long getVideoPosition(String url) {
Long position = mVideoPositionMap.get(url);
if (position == null) {
long videoPosition = getVideoPositionFromLocal(url);
if (videoPosition > 0) {
mVideoPositionMap.set(url, position);
}
return 0L;
}
return position;
}
public void setVideoPosition(String url, long position) {
mVideoPositionMap.set(url, position);
saveToLocal();
}
最少最近使用算法,就是使用的 LinkedHashMap
- 会将内存控制在一定的大小内, 这个最大值可以自己定(一般使用最大可用内存的1/8作为缓存的大小),超出最大值时会自动回收。他内部是是一个 linkedhashmap 存储外界的缓存对象,提供了 get, put 方法来操作,当缓存满了,lru 会移除较早使用的缓存对象,把新的添加进来。
- HashMap 是无序的,而 LinkedHashMap 默认实现是按插入顺序排序的,怎么存怎么取。LinkedHashMap 每次调用 get (也就是从内存缓存中取图片),则将该对象移到链表的尾端。调用 put 插入新的对象也是存储在链表尾端,这样当内存缓存达到设定的最大值时,将链表头部的对象(近期最少用到的)移除。(hashmap 就是链表)
- 内存中使用 LRUCache 是最合适的。如果用 HashMap 来实现,不是不可以,但需要注意在合适的时候释放缓存。至于具体怎么释放,很难控制缓存的大小,也就是说,只有等到你的内存快要撑爆,你的图片缓存才会被回收。
public class BitmapCache implements ImageCache {
private LruCache<String, Bitmap> mCache;
public BitmapCache() {
long maxSize = Runtime.getRuntime().maxMemory() / 8;//主流都是分配16m的8/1
// int maxSize = 10 * 1024 * 1024;
mCache = new LruCache<String, Bitmap>(maxSize) {
@Override
protected int sizeOf(String key, Bitmap bitmap) {
//获取图片占用内存大小
return bitmap.getRowBytes() * bitmap.getHeight();
}
};
}
@Override
public Bitmap getBitmap(String url) {
return mCache.get(url);
}
@Override
public void putBitmap(String url, Bitmap bitmap) {
mCache.put(url, bitmap);
}
}
LinkedHashMap
散列表中数据是经过散列函数打乱之后无规律存储的,LinkedHashMap 是如何实现按照数据的插入顺序来遍历打印的呢?
LinkedHashMap 是通过散列表和链表组合在一起实现的。实际上,它不仅支持按照插入顺序遍历数据,还支持按照访问顺序来遍历数据。你可以看下面这段代码:
// 10是初始大小,0.75是装载因子,true是表示按照访问时间排序
HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
m.put(3, 26);
m.get(5);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
这段代码打印的结果是 1,2,3,5、
每次调用 put () 函数,往 LinkedHashMap 中添加数据的时候,都会将数据添加到链表的尾部,所以,在前四个操作完成之后,链表中的数据是下面这样:
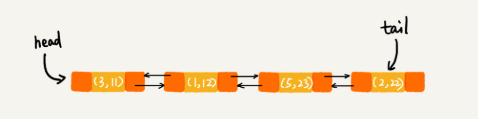
在第 8 行代码中,再次将键值为 3 的数据放入到 LinkedHashMap 的时候,会先查找这个键值是否已经有了,然后,再将已经存在的 (3,11) 删除,并且将新的 (3,26) 放到链表的尾部。所以,这个时候链表中的数据就是下面这样:
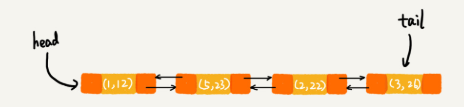
当第 9 行代码访问到 key 为 5 的数据的时候,我们将被访问到的数据移动到链表的尾部。所以,第 9 行代码之后,链表中的数据是下面这样:
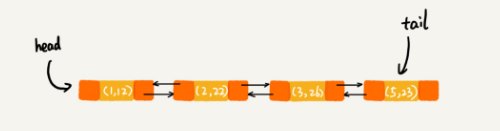
从上面的分析,你有没有发现,按照访问时间排序的 LinkedHashMap 本身就是一个支持 LRU 缓存淘汰策略的缓存系统?实际上,它们两个的实现原理也是一模一样的。我也就不再啰嗦了。
LinkedHashMap 是通过双向链表和散列表这两种数据结构组合实现的。LinkedHashMap 中的“Linked”实际上是指的是双向链表,并非指用链表法解决散列冲突。
散列表这种数据结构虽然支持非常高效的数据插入、删除、查找操作,但是散列表中的数据都是通过散列函数打乱之后无规律存储的。也就说,它无法支持按照某种顺序快速地遍历数据。如果希望按照顺序遍历散列表中的数据,那我们需要将散列表中的数据拷贝到数组中,然后排序,再遍历。
因为散列表是动态数据结构,不停地有数据的插入、删除,所以每当我们希望按顺序遍历散列表中的数据的时候,都需要先排序,那效率势必会很低。为了解决这个问题,我们将散列表和链表(或者跳表)结合在一起使用。
散列表
散列表的英文叫“Hash Table”,我们平时也叫它“哈希表”或者“Hash 表",其实 HashMap 就是实现一个散列表。
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
其中,参赛选手的编号我们叫作键(key)或者关键字。我们用它来标识一个选手。我们把参赛编号转化为数组下标的映射方法就叫作散列函数(或“Hash 函数”“哈希函数”),而散列函数计算得到的值就叫作散列值(或“Hash 值”“哈希值”)
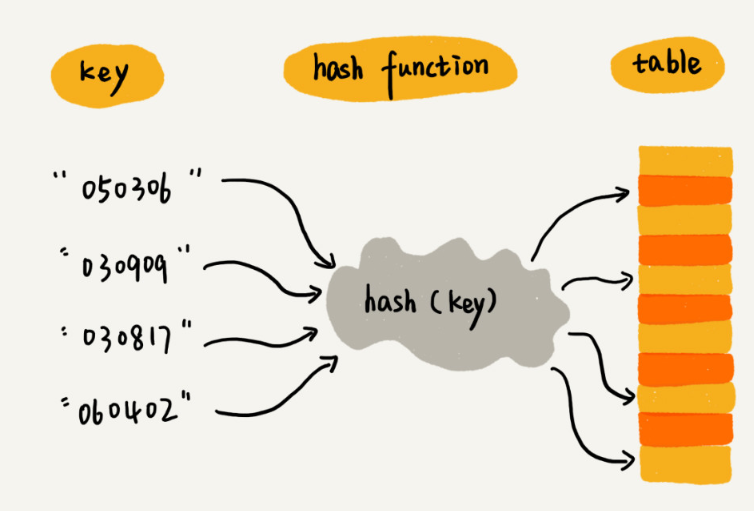
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O (1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。
时间复杂度
插入一个数据,最好情况下,不需要扩容,最好时间复杂度是 O (1)。最坏情况下,散列表装载因子过高,启动扩容,我们需要重新申请内存空间,重新计算哈希位置,并且搬移数据,所以时间复杂度是 O (n)。用摊还分析法,均摊情况下,时间复杂度接近最好情况,就是 O (1)
然后遍历链表查找或者删除。那查找或删除操作的时间复杂度是多少呢?实际上,这两个操作的时间复杂度跟链表的长度 k 成正比,也就是 O (k)。对于散列比较均匀的散列函数来说,理论上讲,k=n/m,其中 n 表示散列中数据的个数,m 表示散列表中“槽”的个数。
散列函数
散列函数,顾名思义,它是一个函数。我们可以把它定义成 hash (key),其中 key 表示元素的键值,hash (key) 的值表示经过散列函数计算得到的散列值。
该如何构造散列函数呢?我总结了三点散列函数设计的基本要求:
- 散列函数计算得到的散列值是一个非负整数;
- 如果 key1 = key2,那 hash (key1) == hash (key2);
- 如果 key1 ≠ key2,那 hash (key1) ≠ hash (key2)
我来解释一下这三点。其中,第一点理解起来应该没有任何问题。因为数组下标是从 0 开始的,所以散列函数生成的散列值也要是非负整数。第二点也很好理解。相同的 key,经过散列函数得到的散列值也应该是相同的。
第三点理解起来可能会有问题,我着重说一下。这个要求看起来合情合理,但是在真实的情况下,要想找到一个不同的 key 对应的散列值都不一样的散列函数,几乎是不可能的。即便像业界著名的 MD5、SHA、CRC 等哈希算法,也无法完全避免这种散列冲突。而且,因为数组的存储空间有限,也会加大散列冲突的概率。
散列冲突
- 开放寻址法
线性探测
我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中的 ThreadLocalMap 使用开放寻址法解决散列冲突的原因。
ThreadLocalMap 是通过线性探测的开放寻址法来解决冲突
散列表的装载因子=填入表中的元素个数/散列表的长度
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降
- 链表法
Java 中 LinkedHashMap 就采用了链表法解决冲突
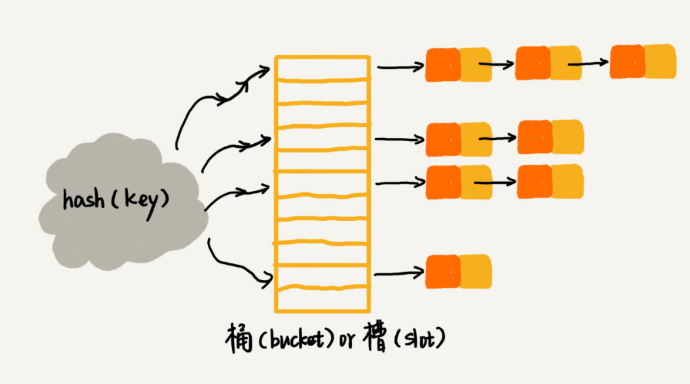
如何设计散列函数?
如何设计一个可以应对各种异常情况的工业级散列表,来避免在散列冲突的情况下,散列表性能的急剧下降,并且能抵抗散列碰撞攻击?
首先,散列函数的设计不能太复杂。过于复杂的散列函数,势必会消耗很多计算时间,也就间接的影响到散列表的性能。其次,散列函数生成的值要尽可能随机并且均匀分布,这样才能避免或者最小化散列冲突,而且即便出现冲突,散列到每个槽(链表)里的数据也会比较平均,不会出现某个槽内数据特别多的情况。
装载因子过大了怎么办?
装载因子越大,说明散列表中的元素越多,空闲位置越少,散列冲突的概率就越大。不仅插入数据的过程要多次寻址或者拉很长的链,查找的过程也会因此变得很慢。
扩容解决
实际上,对于动态散列表,随着数据的删除,散列表中的数据会越来越少,空闲空间会越来越多。
避免低效地扩容
我举一个极端的例子,如果散列表当前大小为 1GB,要想扩容为原来的两倍大小,那就需要对 1GB 的数据重新计算哈希值,并且从原来的散列表搬移到新的散列表,听起来就很耗时,是不是?
为了解决一次性扩容耗时过多的情况,我们可以将扩容操作穿插在插入操作的过程中,分批完成。当装载因子触达阈值之后,我们只申请新空间,但并不将老的数据搬移到新散列表中。
当有新数据要插入时,我们将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表。每次插入一个数据到散列表,我们都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了。这样没有了集中的一次性数据搬移,插入操作就都变得很快了。
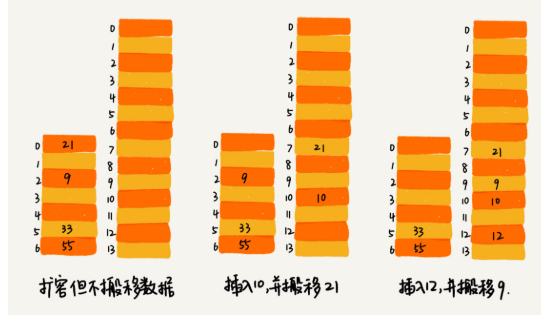
这期间的查询操作怎么来做呢?对于查询操作,为了兼容了新、老散列表中的数据,我们先从新散列表中查找,如果没有找到,再去老的散列表中查找。
线程安全
要保证HashMap线程安全,可以采取以下几种方法:
- 使用Collections.synchronizedMap()方法:这个方法会返回一个线程安全的Map,它通过装饰器模式为原始的HashMap提供了一个同步的包装器。这个包装器在调用任何Map操作时都会进行同步,从而保证线程安全。
- 使用ConcurrentHashMap:ConcurrentHashMap是Java提供的一个线程安全的Map实现。它通过分段锁技术来提高并发性能,只锁定Map中的一部分而不是整个Map,这样可以减少线程之间的竞争,提高并发访问的效率。
- 使用Hashtable:Hashtable是一个古老的线程安全的Map实现,它通过在每个方法上使用synchronized关键字来确保线程安全。但是,由于它在执行任何操作时都会锁定整个表,所以并发性能较差。
- 使用volatile关键字:虽然将HashMap声明为volatile可以保证变量的可见性,但是它并不能保证复合操作的原子性,因此无法完全保证线程安全。这种方法通常不推荐使用。
- 使用CopyOnWriteArrayList:如果你的使用场景主要是读操作远多于写操作,可以考虑使用CopyOnWriteArrayList。这是一个线程安全的List实现,它在每次写入时都会创建一个新的副本,读操作则在原始数据上进行,不会产生冲突。
总的来说,在选择哪种方法时,需要根据具体的应用场景和对性能的要求来决定。如果对并发性能要求较高,推荐使用ConcurrentHashMap。如果对性能要求不是特别高,或者需要一个比较简单的解决方案,可以使用Collections.synchronizedMap()方法。而Hashtable则适用于那些对性能要求不高,但需要完全线程安全的场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号