用前缀数制作敏感词过滤器
用前缀数制作敏感词过滤器
何为前缀树
前缀数又成Trie、字典树和查找树,其特点是查找效率较高,但是消耗的内存较大,其常应用于字符串检索、字频统计和字符串排序等。
此处我们使用其来制作敏感词过滤器。
用前缀树来记录敏感词,假设此时的敏感词:abc、bd、bg
先画好一个前缀树:
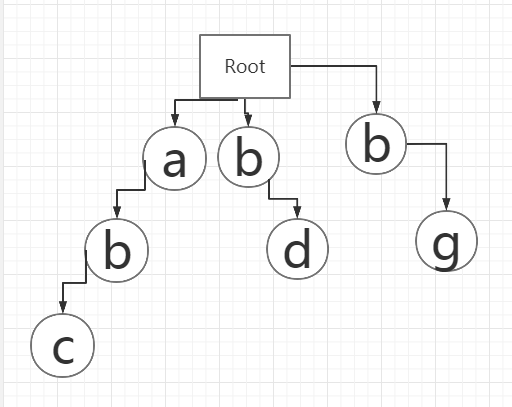
Root为其根,不记录字符。
然后我们再对假设一个字符串,对该字符串进行敏感词识别。
假设该字符串为“asdabcbdaas”。
我们有三个箭头,分别如下:
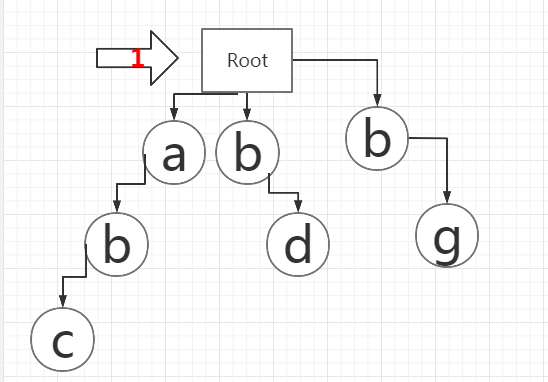
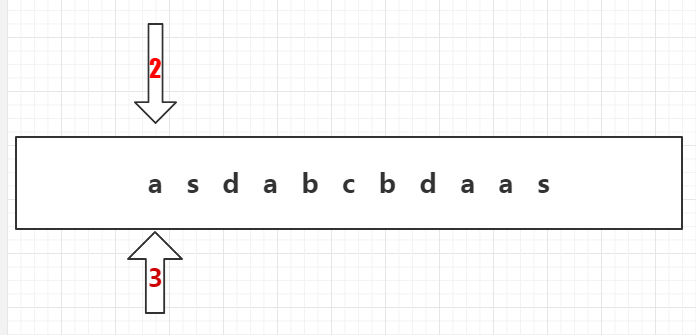
同时准备一个StringBuilder存储过滤后的字符串。
分别称为1号箭头、2号箭头、3号箭头。
我们开始对该文段进行敏感词过滤。
1、2号箭头指向a,我们可以在前缀树的第一行节点里面查找是否存在a。
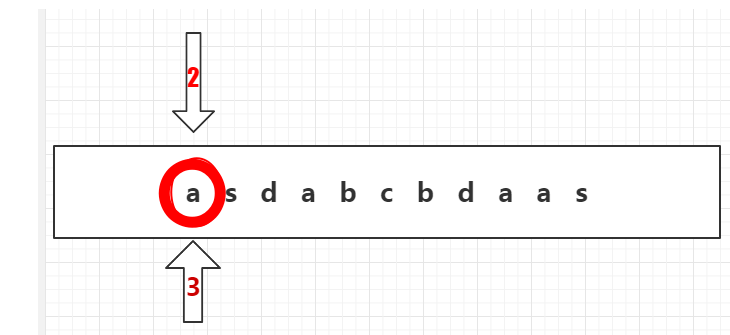
2、1号箭头往下走,发现存在a。
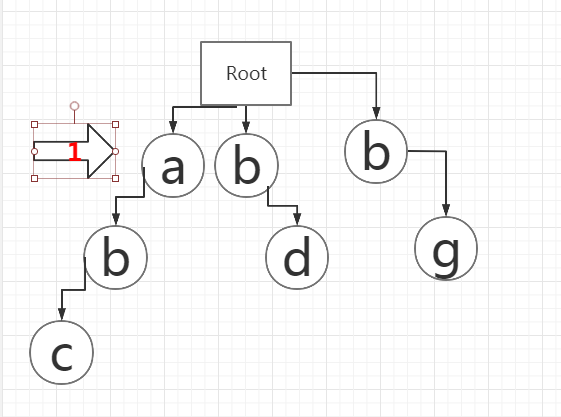
3、2号箭头静止不动,3号箭头往下一字符移动,3号指到s。
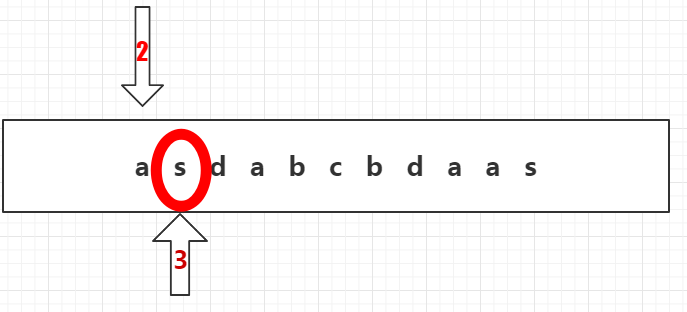
4、1号箭头往下走,在前缀树a的下一行节点中寻找s,没有找到。
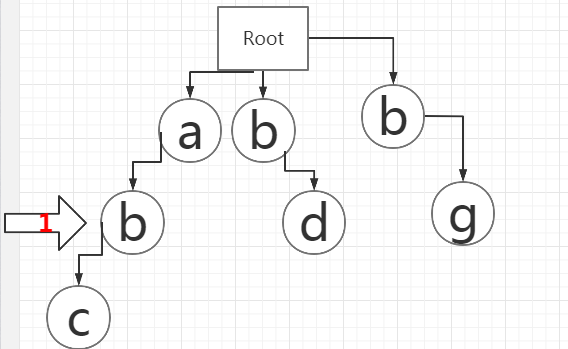
5、说明此时2号箭头和3号箭头之间的字符串as不是敏感词。2号和3号箭头都移到下一位d。并把“as”加入到过滤后的字符串StirngBuilder。
此时StringBuilder=“as”;
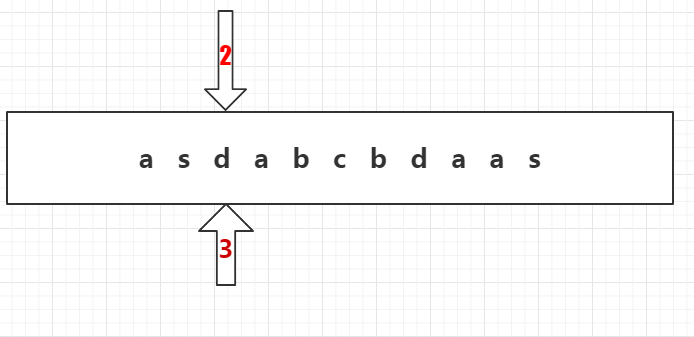
6、1号箭头移回第一行节点,发现并没有d,继续检索下一个字符。
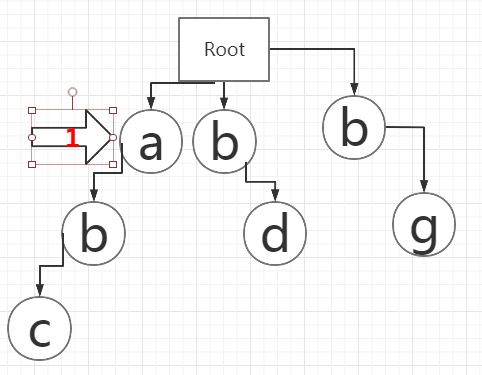
7、2号节点继续往前走,遇到a。
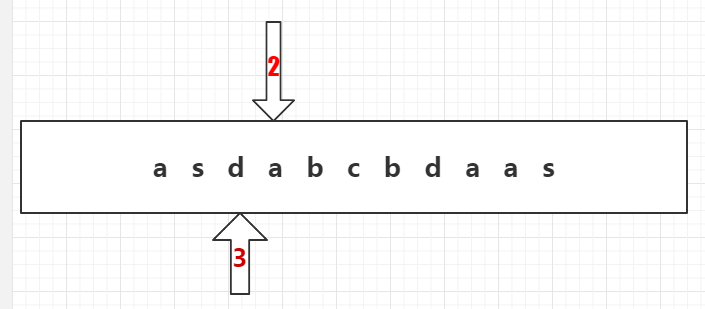
8、前缀树里第一行节点中有a。
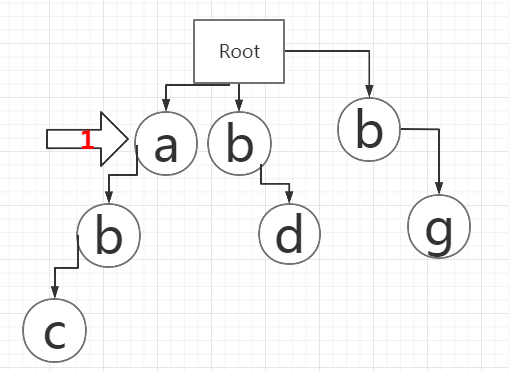
9、3号指针移到2号指针的下一个字符,读取字符b。
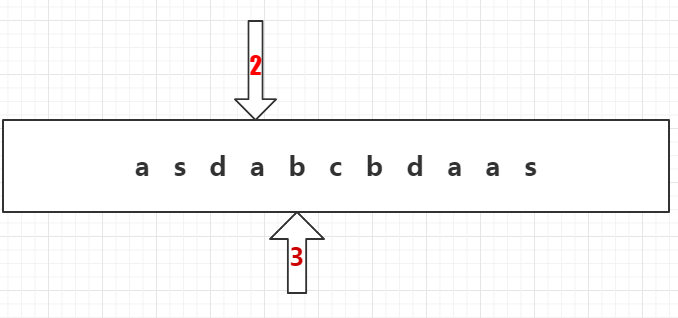
10、同样在前缀树a的第二行节点中寻找b,找到。
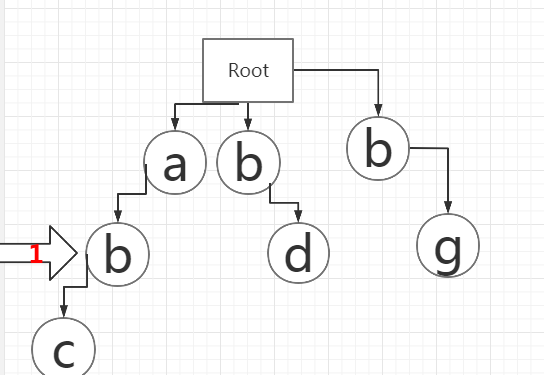
11、3号指针继续往前走,找到c。
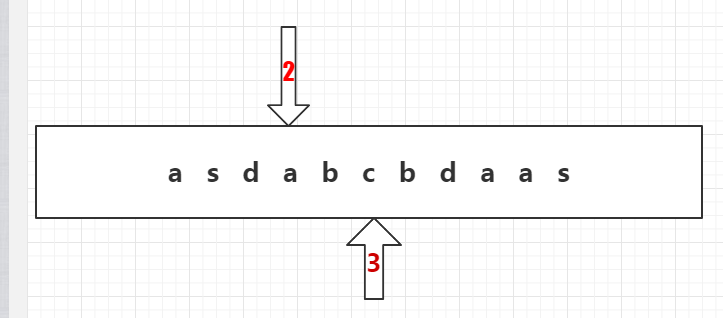
12、1号指针继续往b的下一行节点寻找c,找到c。
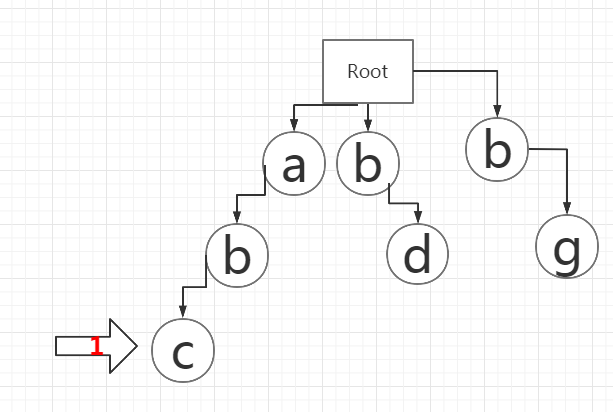
此时,字符串“abc”全部查找完成,可以判断2号指针到3号指针之间“abc”为敏感词,更换为***并加入StringBuilder。
StringBuilder=“as***”;
此后的字符以此类推,直到最后StringBuilder=“as*** ***aas”;
下面我们来编写Java。
先新建一个敏感词文件txt,我们给其命名为sensitive-word.txt。往里面按照一行一个词语的格式输入敏感词。如下:
赌博
嫖娼
吸毒
开票
然后实现一个Java过滤器。
package com.nowcoder.community.util;
import org.apache.commons.lang3.CharUtils;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
// 替换符
private static final String REPLACEMENT = "***";
// 根节点
private TrieNode rootNode = new TrieNode();
@PostConstruct
public void init() {
try (
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
while ((keyword = reader.readLine()) != null) {
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword) {
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if (subNode == null) {
// 初始化子节点
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指向子节点,进入下一轮循环
tempNode = subNode;
// 设置结束标识
if (i == keyword.length() - 1) {
tempNode.setKeywordEnd(true);
}
}
}
/**
* 过滤敏感词
*
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public String filter(String text) {
if (StringUtils.isBlank(text)) {
return null;
}
// 指针1
TrieNode tempNode = rootNode;
// 指针2
int begin = 0;
// 指针3
int position = 0;
// 结果
StringBuilder sb = new StringBuilder();
while (position < text.length()) {
char c = text.charAt(position);
// 跳过符号
if (isSymbol(c)) {
// 若指针1处于根节点,将此符号计入结果,让指针2向下走一步
if (tempNode == rootNode) {
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
continue;
}
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
} else if (tempNode.isKeywordEnd()) {
// 发现敏感词,将begin~position字符串替换掉
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = rootNode;
} else {
// 检查下一个字符
position++;
}
}
// 将最后一批字符计入结果
sb.append(text.substring(begin));
return sb.toString();
}
// 判断是否为符号
private boolean isSymbol(Character c) {
// 0x2E80~0x9FFF 是东亚文字范围
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
// 前缀树
private class TrieNode {
// 关键词结束标识
private boolean isKeywordEnd = false;
// 子节点(key是下级字符,value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node) {
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c) {
return subNodes.get(c);
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号