
1.1. Hadoop hdfs架构
hadoop分布式文件系统(hdfs)被设计成适合运行在通用硬件上的分布文件系统。hdfs是一个高度容错性的系统,适合部署在廉价的机器上(题外话:其实一点都不廉价,企业的服务器都挺贵的,所谓的廉价都是相对来说),能提供高吞吐的数据访问,适合大规模数据集上的应用。
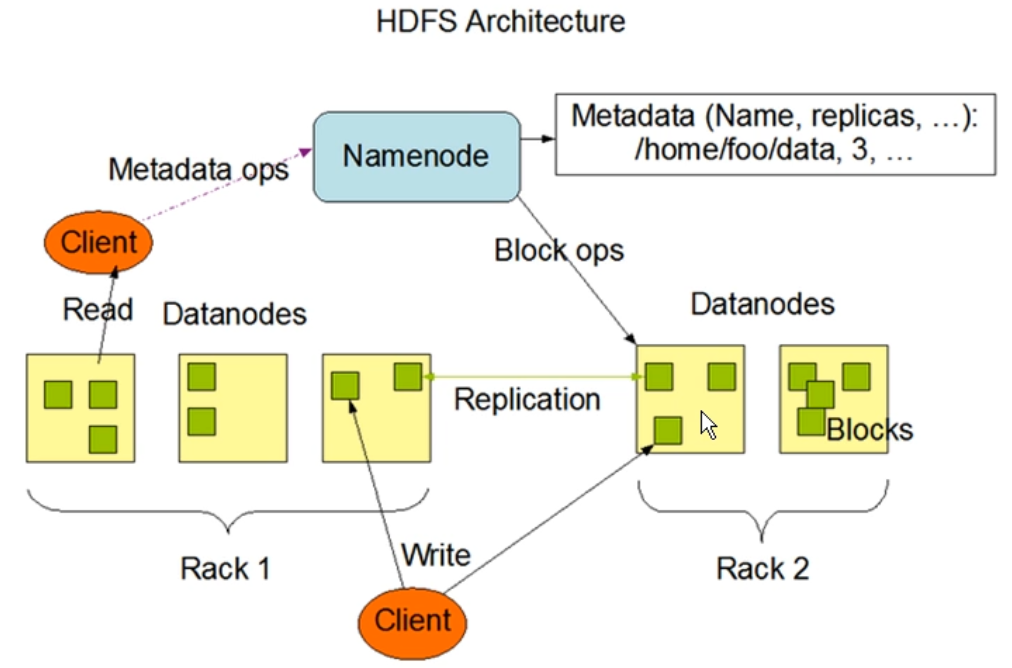
图1.1-1hdfs 架构图
HDFS采用的MASTER/SLAVE架构。一个hdfs集群有一个namenode 和一定数目的DataNode组成。NAMENODE 是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中datanode 一般是一个节点一个,负责管理它所在节点的存储。HDFS暴露的文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或者多个数据块,这些块存储在一组datanode 上。NameNode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或者目录。它负责确定数据块到具体datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在namenode的统一调度下进行数据库的创建、删除和复制。
HDFS数据上传原理参考上图:
1)client端发送一个添加文件到hdfs的请求给namenode
2)namenode告诉client端如何来分发数据块以及分发的位置
3)客户端把数据分为块,然后把这些分发到datanode中
4)datanode在namenode的指导下复制这些块,保持冗余。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号