

1.union
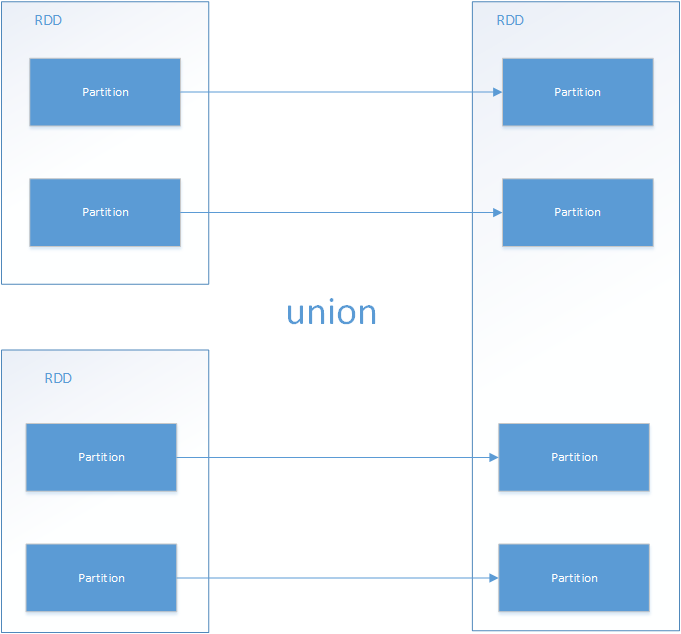
特点:
①、新的RDD,会将旧的两个RDD的partition原封不动的给挪过来。
② 、新的RDD的partition数量,是旧的partition数量之和。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2.groupByKey
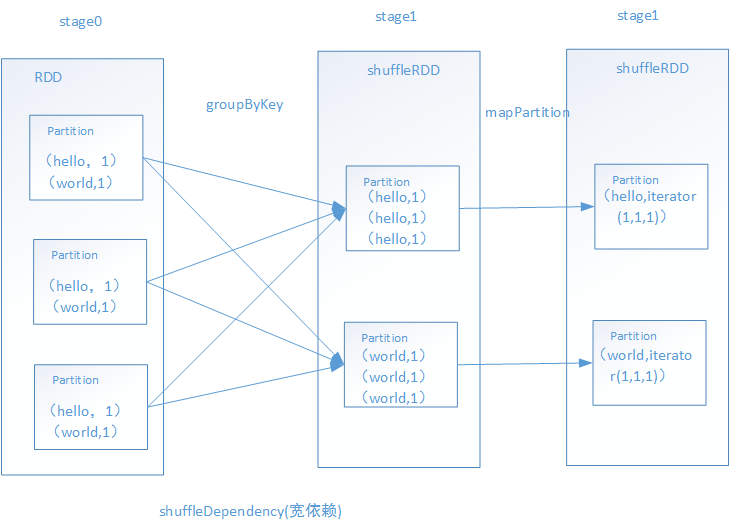
①、一般来说,在执行groupByKey、reduceByKey、join等shuffle算子时,算子内部会隐式的创建RDD,主要是作为这个操作的一些中间数据的表达,以及作为stage划分的边界。因为生成
的RDD可能是和上一个RDD的shuffleDependency的。
②、依赖这个shuffleRDD创建一个新的stage(上图中的stage1),shuffleRDD会去触发shuffle read操作,从上游stage的task所在节点拉取过来相同的key,做进一步操作。
③、对这个shuffleRDD中的数据执行一个map类的操作,主要是对每个partition中的数据,都进行一个映射和聚合。上图中主要是将每个key对应的数据都聚合到一个iterator集合中。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
3.reduceByKey
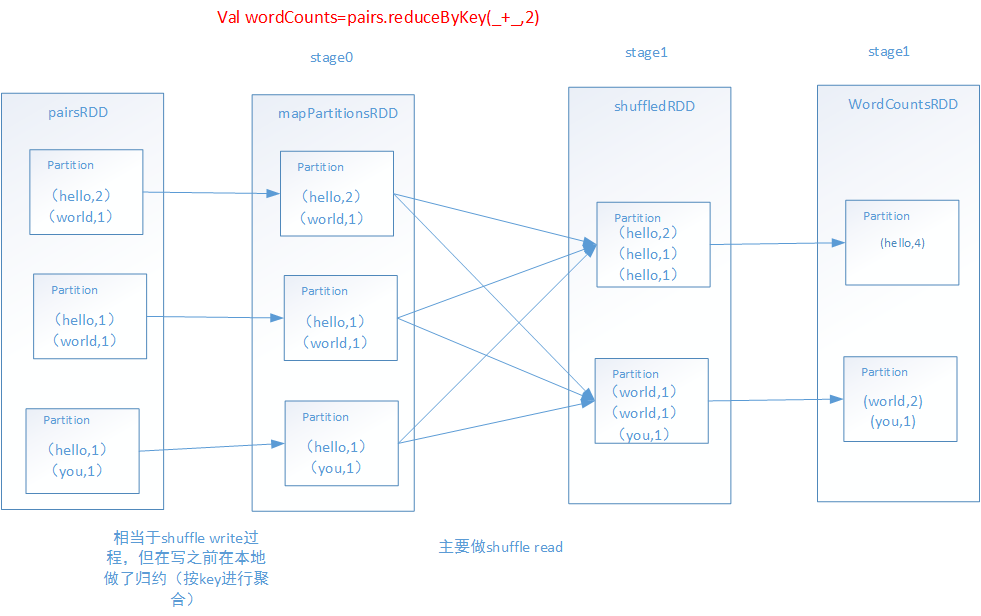
①、跟groupByKey的不同之处:多了一个mapPartitionRDD(在stage0),主要是代表了进行本地数据归约之后的RDD。---在本地进行归约。所以网络传输数据以及磁盘io等会减少,性能更高。
②、相同之处在于:后面进行shuffle read和聚合的过程基本一致。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
4.distinct
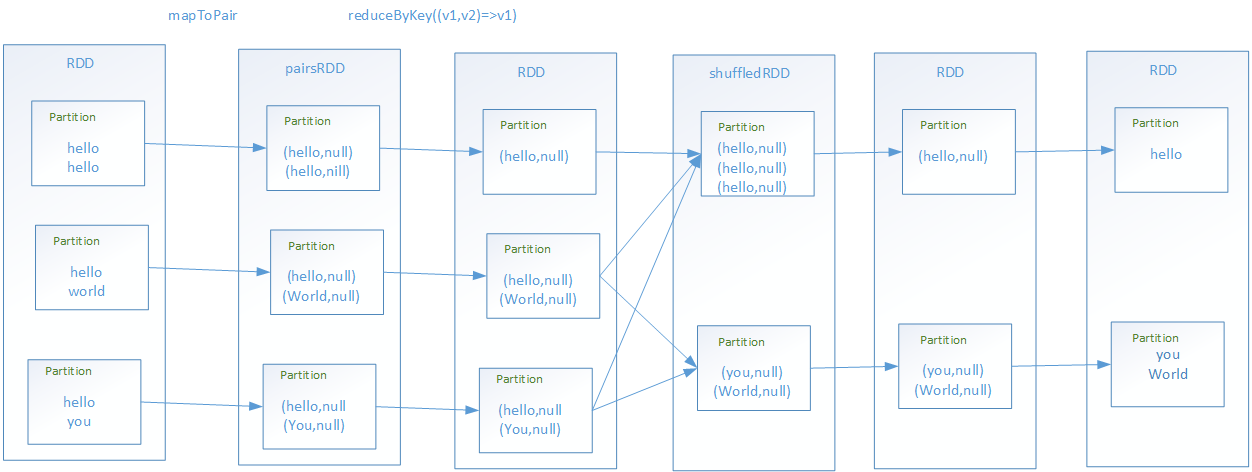
①、首先给每个值打上一个v2,变成tuple
②、通过reduceByKey,先进行一个本地的归约,再做shuffle,再做map....
③、将去重后的数据,从tuple还原为单值
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
5.cogroup
cogroup算子比较少见,但它是很多算子的基础,比如join。

把相同的key进行聚合,按照partition的个数生成n个集合,最后再生成ierator的形式。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
6.intersection(交集)
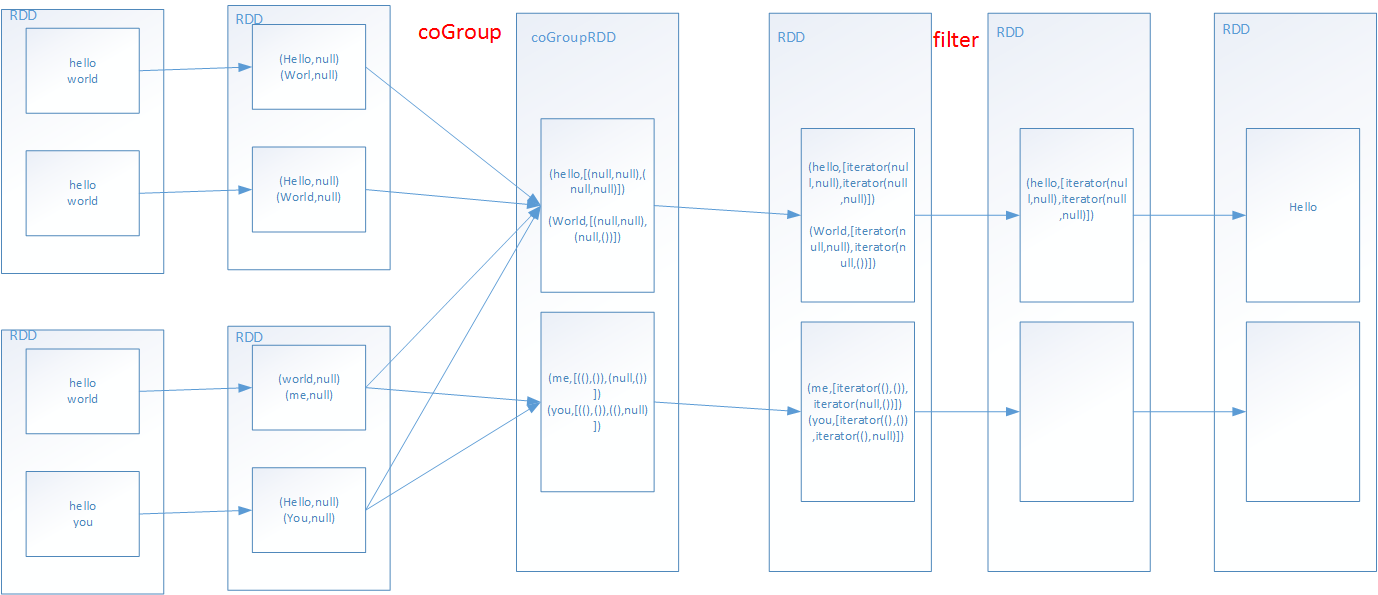
①、首先进行map操作,映射成tuple
②、其次通过cogroup操作,聚合两个RDD的key
③、然后进行filter,过滤掉两个集合(指定的partition个数)中任意一个集合为空的key
④、map操作,还原出单值。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
7.join
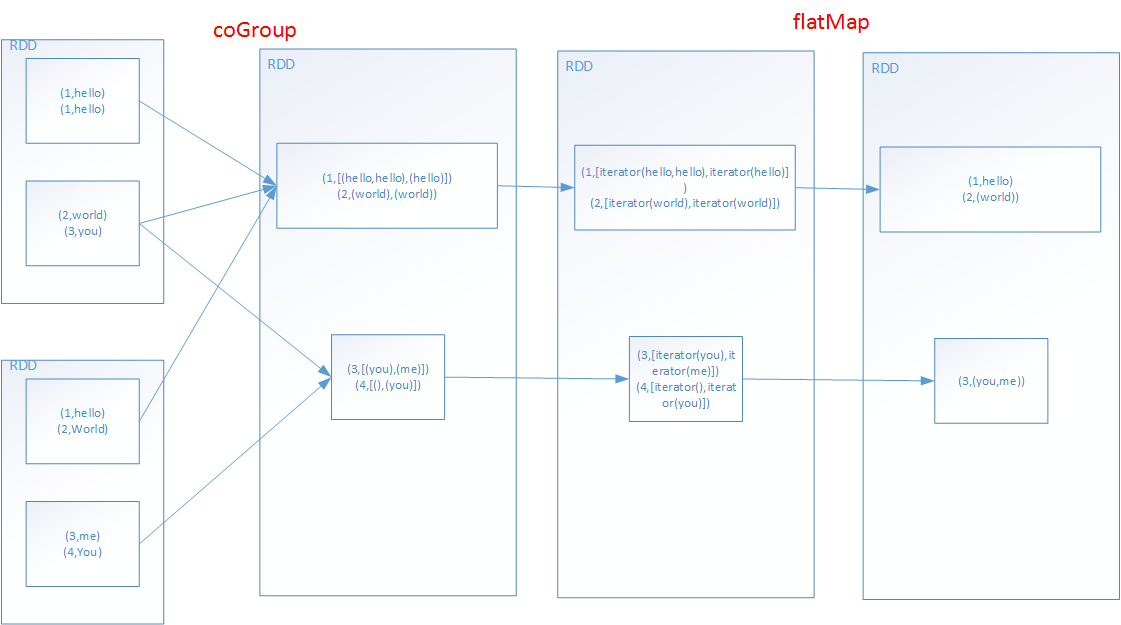
①、进行coGroup,聚合两个RDD的key
②、进行flatMap,聚合后的每条数据,都可能返回多条数据,将每个key对应的两个集合的所有元素,做笛卡尔乘积。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
8.sortByKey
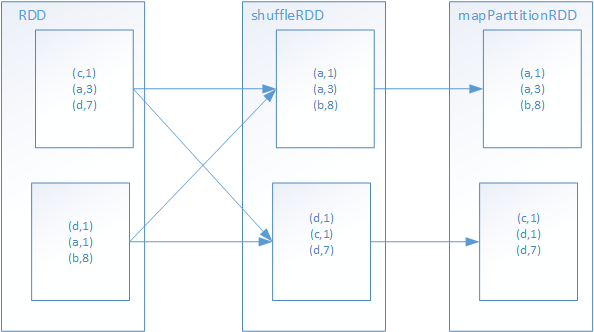
①、通过shuffledRDD,做shuffle read,将相同的key拉到一个partition中来
②、mapPartition,对每个partitions内的key进行全局排序。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
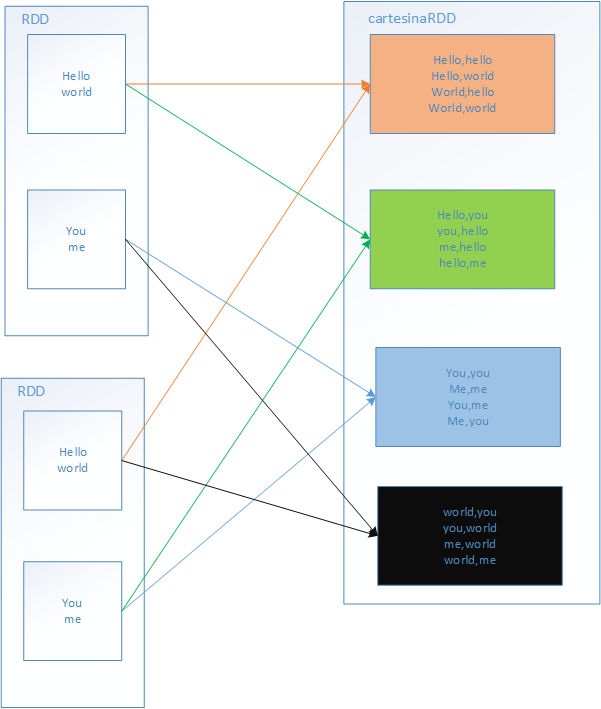
9.cartesian(笛卡尔乘积)
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
10.coalesce
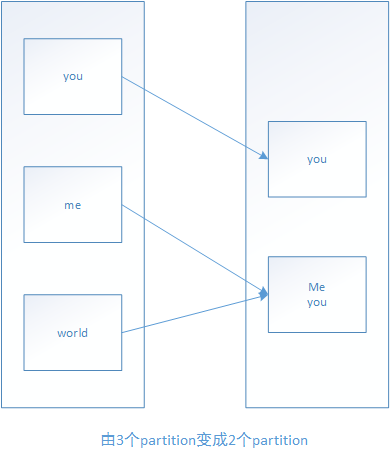
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
11.repartition
repartition算子=coalesce(true)

①、通过map,增加了前缀,根据要重分区成几个分区,计算前缀
②、shuffle后进行coalesce
③、去掉前缀,得到最终重分区好的RDD。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号