

正则表达式学习
正则表达式学习
推荐两个学习正则表达式的网站
-
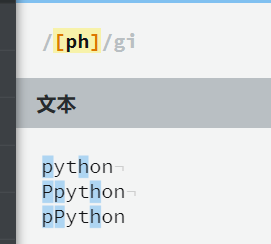
[]中括号中表示字符
如果只有一个[],后面没有其他字符了,那么就把[]中的字符全部匹配,每一个字符都会匹配需要的字符,
如果[]后面又其他字符,那么就把[]中的字符集和后面内容结合起来
-
还有[]中加-表示范围(比如[a-z],表示26个小写字母被匹配,[0-9a-z]在之前基础上,加上10个数字)
-
-
匹配特殊字符
使用-表示区间,使用\表示转义
-
取反
有时候我们可能希望根据不会出现的字符定义字符组,所以在[]中使用 ^就可以排除




快捷模式
快速匹配
| 数字 | \d |
|---|---|
| 字母 | \w |
| 空白 | \s |
| 单词边界 | \b |
快捷方式取反只需要将 比如 \w大写
在正则表达式中^表示一个字符串的开始,$表示一个字符串的结束
-
任意字符
.字符代表匹配任何单个字符,它只能出现在方括号以外。注:只有一个字符不能匹配,就是\n换行符
-
可选字符
在可选字符后加?,
?符号指定一个字符、字符组或其他基本单元可选,这意味着正则表达式引擎将会期望该字符出现零次或一次。
重复
大括号{}表示重复几遍
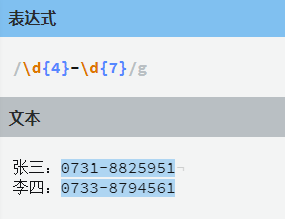
在大括号中间的两个数字表示上限和下限,语法:{M,N},M是下界而N是上界。

有时候我们可能遇到字符组的重复次数没有边界

也可以简写,可以使用 + 匹配1个到无数个,使用 *代表0个到无数个。

遇到的两个常见的写法
.*贪婪匹配
.*?非贪婪匹配
多种匹配模式
| 实例 | 描述 |
|---|---|
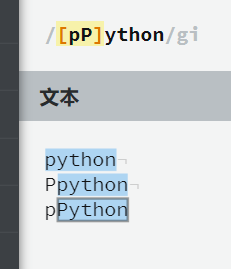
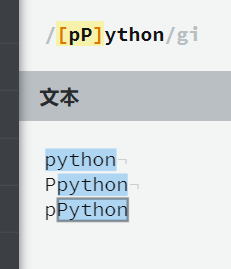
[Pp]ython |
匹配 “Python” 或 “python”。 |
rub[ye] |
匹配 “ruby” 或 “rube”。 |
[abcdef] |
匹配中括号内的任意一个字母。 |
[0-9] |
匹配任何数字。类似于 [0123456789]。 |
[a-z] |
匹配任何小写字母。 |
[A-Z] |
匹配任何大写字母。 |
[a-zA-Z0-9] |
匹配任何字母及数字。 |
[^au] |
除了au字母以外的所有字符。 |
[^0-9] |
匹配除了数字外的字符。 |
| 实例 | 描述 |
|---|---|
. |
匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式。 |
? |
匹配一个字符零次或一次,另一个作用是非贪婪模式 |
+ |
匹配1次或多次 |
* |
匹配0次或多次 |
\b |
匹配一个长度为0的子串 |
\d |
匹配一个数字字符。等价于 [0-9]。 |
\D |
匹配一个非数字字符。等价于 [^0-9]。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
\w |
匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]’。 |
\W |
匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]‘。 |
\b |
匹配一个长度为0的子串 |
python正则表达式匹配字符串前面加的字母意思
1、字符串前加 u
例:u"我是含有中文字符组成的字符串。"
作用:
后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
2、字符串前加 r
例:r"\n\n\n\n” # 表示一个普通生字符串 \n\n\n\n,而不表示换行了。
作用:
去掉反斜杠的转义机制。
(特殊字符:即那些,反斜杠加上对应字母,表示对应的特殊含义的,比如最常见的”\n”表示换行,”\t”表示Tab等。 )
应用:
常用于正则表达式,对应着re模块。
3、字符串前加 b
例: response = b'
Hello World!
' # b' ' 表示这是一个 bytes 对象作用:
b" "前缀表示:后面字符串是bytes 类型。
用处:
网络编程中,服务器和浏览器只认bytes 类型数据。
如:send 函数的参数和 recv 函数的返回值都是 bytes 类型
附:
在 Python3 中,bytes 和 str 的互相转换方式是
str.encode('utf-8')
bytes.decode('utf-8')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号