
1. 概述
Distro协议是阿里自研的一个最终一致性协议,继承了 Gossip 以及 Eureka 通信(PeerEurekaNodes)的优点并做进一步优化而出来的:
对于原生的Gossip,由于随机选取发送消息的节点,也就不可避免存在消息重复发送给同一节点的问题,这白白浪费了网络的传输带宽,也给消息节点带来额外的处理负载,Distro算法引入了权威Server的概念,每个节点负责一部分数据以及将自己的数据同步给其他节点,有效降低了消息冗余的问题。
Distro协议保证了在某些Nacos节点宕机后,整个临时实例处理系统依旧可以正常工作,保证了各个Nacos节点对于海量注册请求的统一协调和存储。
2. 设计思想
- Nacos 每个节点是平等的都可以处理写请求, 同时把新数据同步到其他节点。
- 每个节点只负责部分数据, 定时发送自己负责数据的校验值到其他节点来保持数据⼀致性。
- 每个节点独立处理读请求, 及时从本地发出响应。
- 数据存储在缓存中,并且会在启动时进行全量数据同步,并定期进行数据校验。
3. 原理说明
在 Distro 协议的设计思想下, 每个 Distro 节点都可以接收到读写请求。 所有的 Distro 协议的请求场景主要分为三种情况:
1)数据初始化:
新加入的 Distro 节点会进行全量数据拉取。 具体操作是轮询所有的 Distro 节点, 通过向其他的机器发送请求拉取全量数据。

在全量拉取操作完成之后, Nacos 的每台机器上都维护了当前的所有注册上来的非持久化实例数据。
2)数据校验
在Distro集群启动之后,各台机器之间会定期的发送心跳。心跳信息主要为各个机器上的所有数据的元信息(之所以使用元信息,是因为需要保证网络中数据传输的量级维持在⼀个较低水平)。这种数据校验会以心跳的形式进行,即每台机器在固定时间间隔会向其他机器发起⼀次数据校验请求。
⼀旦在数据校验过程中,某台机器发现其他机器上的数据与本地数据不⼀致,则会发起⼀次全量拉取请求,将数据补齐。
3)写操作
对于⼀个已经启动完成的Distro集群,在⼀次客户端发起写操作的流程中,当注册非持久化的实例的写请求打到某台Nacos服务器时,Distro集群处理的流程图如下。
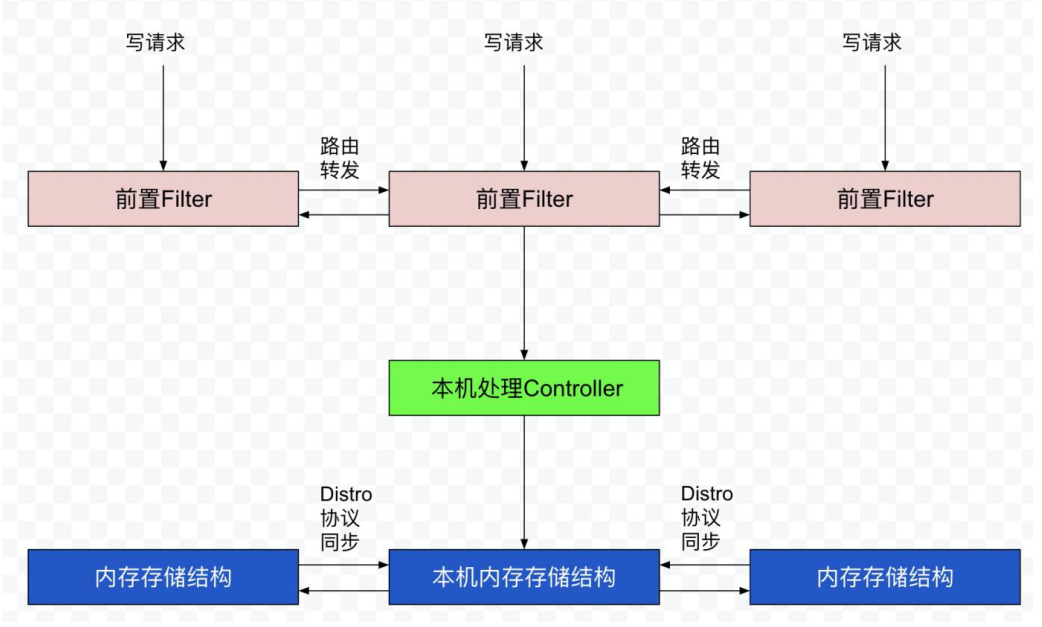
整个步骤包括几个部分(图中从上到下顺序):
① 前置的Filter拦截请求,并根据请求中包含的IP和port信息计算其所属的Distro责任节点,并将该请求转发到所属的Distro责任节点上。
② 责任节点上的Controller将写请求进行解析。
③ Distro协议定期执行Sync任务,将本机所负责的所有的实例信息同步到其他节点上。
4)读操作
由于每台机器上都存放了全量数据,因此在每⼀次读操作中,Distro机器会直接从本地拉取数据,快速响应。
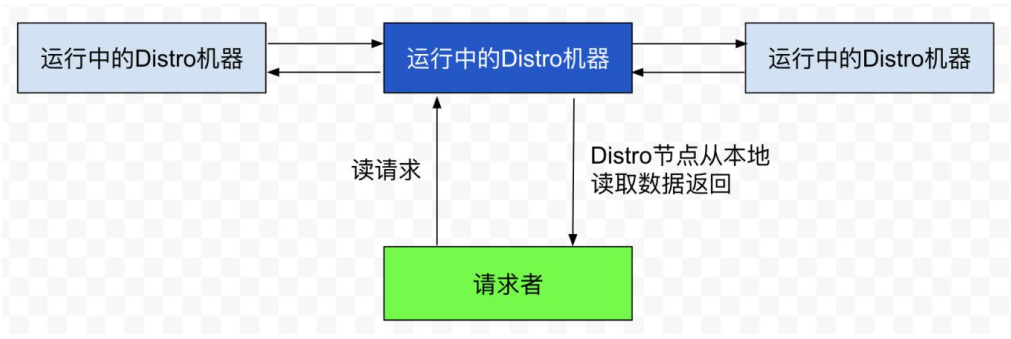
这种机制保证了Distro协议可以作为⼀种AP协议,对于读操作都进行及时的响应。在网络分区的情况下,对于所有的读操作也能够正常返回;当网络恢复时,各个Distro节点会把各数据分片的数据进行合并恢复。
4. 应用场景
1)当该节点接收到属于该节点负责的实例的写请求时, 直接写入。
2)当该节点接收到不属于该节点负责的实例的写请求时, 将在集群内部路由, 转发给对应的节点,从而完成读写。
3)当该节点接收到任何读请求时, 都直接在本机查询并返回(因为所有实例都被同步到了每台机器上) 。
5. 小总结
Distro 协议作为 Nacos 的内嵌临时实例⼀致性协议, 保证了在分布式环境下每个节点上面的服务信息的状态都能够及时地通知其他节点, 可以维持数十万量级服务实例的存储和⼀致性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号