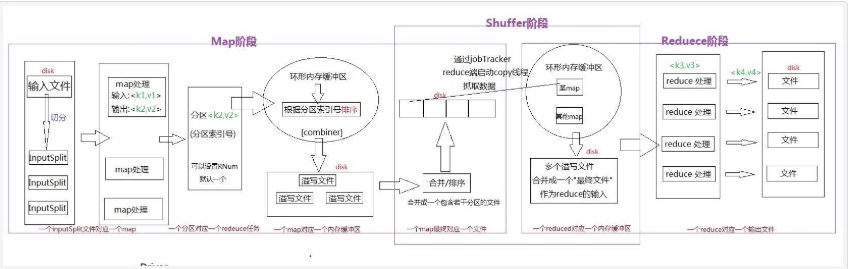
MapReduce 包括Mapper(Mapper类)阶段和Reducer(Reducer类)阶段,其中Map阶段和Reduce阶段都包含部分Shuffle阶段工作。
Map阶段
1.输入分片 input split: 一个大的文件会根据block块切分成多个分片,每个输入分片会让一个map进程来处理
2.Map任务: i. 初始化: 创建context,map.class实例,设置输入输出,创建mapper的上下文
Map 任务把分片传递给 TaskTracker 里面的 InputFormat类的 createRecordReader() 方法 以便获取分片的 RecordReader 对象,由RecordReader读取分片数据并转成键值对形式。
ii. 执行: 执行 Mapper class.的run()方法,这个方法可以被重写,对每个分片里的数据执行一样的方 法。(比如说 给每个key生成一个value=1)
3.shuffle(Map端):
i.溢写:map会使用Mapper.Context.write()将map函数的输出溢写到内存中的环形缓冲区,同时调用 Partitioner类对数据分区,每一个分区对应一个reducer。当缓冲区即将充满(80%),溢写会被执 行(并行,缓冲区可以继续写入,当溢写未完成而缓冲区已满,map会停止写入内存)
具体过程 a.创建一个溢写记录SpillRecord 和一个FSOutputStream 文件输出流(本地文件系统)
b.内存内排序缓冲中的块:输出的数据会使用快排算法按照partitionIdx, key排序
c.分区序列化写到磁盘,序列化(快排)之前可进行combiner(可选),方便排序
d.merge合并溢写文件,如果合并后文件较大,可以再进行一次combiner
e.再进行一次Partitioner对数据分区 (为什么要两次呢,因为这个时候可能进行了两次 combiner,应该分配到每个reducer上的数据出现变化)
ii. combiner合并阶段(可选,有两次触发时机):简单地合并key值
a.减少传到reducer的数据量(即通过减少key-value对减少网络传输)
b.减轻reducer的负担
c.缺点 job没有依赖,有磁盘io开销
iii.Partitioner(补充):
a.Hadoop Mapreduce 默认的Partitioner是Hash Partitioner,对key计算hash值并分区
b.TotalOrderPartitioner 按照数据大小分区 常用于全局排序 按照大小将数据分成多个区 间,后一个区间的数据一定大于前一个区间
c. Partitioner可以被重写,克服低效分区,解决数据倾斜和全局排序问题
iv. 排序原因:
a.方便reducer找到自己分区的数据
b.减轻reducer中排序负担
Reduce阶段
1.shuffle(Reduce端):
i.copy: Reduce端并行的从多个map下载该reduce对应的partition部分数据(通过HTTP)
ii.merge(内存到磁盘): Reduce将map结果下载到本地时,需要把多个mapper输入流合并成一个,一 直在进行,知道从map下载数据完毕。
iii.split: Reduce对下载下来的map数据,会先缓存在内存中,当内存达到一定用量时写入硬盘(这里也 可以进行combiner)
iv.merge(磁盘到磁盘):map数据下载过程中,一个后台线程把这些文件合并为更大的,有序的文 件,也就是进行全局排序,为最后的最终合并减少工作量(多轮)
v. 最终merge(方式不确定): map数据下载完毕后,所有数据被合并成一个整体有序的文件作为 Reduce的输入。有可能是都来自于硬盘,有可能都来自于内存,也有可能两边都有
2.Reduce任务:
i.自己实现逻辑 Map阶段的map方法类似 通常做聚合操作
ii.OutputCollector.collect() 方法把 reduce 任务的输出结果写到 HDFS

 浙公网安备 33010602011771号
浙公网安备 33010602011771号