

2025年重磅发布:腾讯混元图像3.0完全指南 - 全球最大开源文生图模型深度解析
🎯 核心要点 (TL;DR)
- 历史突破:腾讯开源了全球最大的文生图模型,总参数量达80B,推理时激活13B参数
- 技术创新:采用MoE架构结合Transfusion方法,统一多模态理解和生成能力
- 商用级效果:图像生成质量媲美业界顶级闭源模型,支持中英文精准渲染和超长文本理解
- 完全开源:提供完整源代码、模型权重和商用许可,个人和企业均可免费使用
- 强大功能:支持世界知识推理、千字级复杂语义理解、精确文字生成
目录
什么是混元图像3.0
混元图像3.0(HunyuanImage 3.0)是腾讯于2025年9月28日正式开源的革命性文生图模型。这是全球首个开源商用级原生多模态生图模型,也是目前参数量最大的开源图像生成模型。
关键数字
| 指标 | 数值 | 说明 |
|---|---|---|
| 总参数量 | 80B | 全球最大开源文生图模型 |
| 激活参数 | 13B | 推理时实际使用的参数量 |
| 专家数量 | 64个 | MoE架构的专家模块数 |
| 训练数据 | 50亿图文对 + 6万亿token | 海量多模态训练数据 |
| 模型大小 | 160GB | 完整模型权重文件大小 |
💡 技术突破
与传统DiT架构不同,混元图像3.0采用统一的自回归框架,实现了文本和图像模态的深度融合,这是该模型能够进行世界知识推理的关键所在。
核心技术特性解析
1. 世界知识推理能力
混元图像3.0最大的亮点是具备基于世界知识推理的能力,这意味着模型不仅能理解用户的描述,还能结合常识和专业知识来生成更准确、更丰富的图像。
典型应用场景:
- 教育插图:生成九宫格素描教程、算法流程可视化
- 科普图解:解释物理原理、历史事件、生物过程
- 创意设计:基于文学作品、诗词创作视觉作品
2. 超长文本理解
模型支持千字级别的复杂语义理解,这在同类开源模型中极为罕见。
支持的文本长度:1000+ 字符
语言支持:中文、英文
语义理解:复杂场景描述、多层次细节要求
3. 精确文字渲染
混元图像3.0在图像中生成文字的能力表现突出,支持:
- 海报设计中的标题文字
- 信息图表中的标注文字
- 品牌logo和标识
- 多语言文字混排
4. 多样化艺术风格
模型训练涵盖了丰富的艺术风格:
| 风格类型 | 具体表现 | 适用场景 |
|---|---|---|
| 摄影写实 | 胶片质感、专业打光 | 人像摄影、产品拍摄 |
| 插画设计 | 扁平化、手绘风格 | 品牌设计、儿童读物 |
| 艺术创作 | 油画、水彩、素描 | 艺术创作、教学展示 |
| 3D渲染 | 材质表现、光影效果 | 产品可视化、建筑设计 |
模型架构与创新
MoE + Transfusion 架构
混元图像3.0的核心创新在于将混合专家模型(MoE)与Transfusion方法相结合:
训练范式创新
模型采用渐进式训练策略:
- 预训练阶段:低分辨率→高分辨率,低质量→高质量
- 指令微调:构造思维链生图数据,激发推理能力
- 监督微调:使用高质量、高美感数据
- 强化学习:结合DPO、GRPO算法提升美学效果
⚠️ 技术要求
由于模型规模庞大,推荐配置:
- GPU显存:≥3×80GB(推荐4×80GB)
- 存储空间:170GB
- 系统要求:Linux + CUDA 12.8
安装部署指南
环境准备
# 1. 安装PyTorch (CUDA 12.8版本)
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128
# 2. 安装其他依赖
pip install -r requirements.txt
# 3. 性能优化组件(可选,提升3倍推理速度)
pip install flash-attn==2.8.3 --no-build-isolation
pip install flashinfer-python
模型下载
# 从HuggingFace下载模型
hf download tencent/HunyuanImage-3.0 --local-dir ./HunyuanImage-3
快速开始
方法1:使用Transformers库
from transformers import AutoModelForCausalLM
# 加载模型
model_id = "./HunyuanImage-3"
kwargs = dict(
attn_implementation="sdpa",
trust_remote_code=True,
torch_dtype="auto",
device_map="auto",
moe_impl="eager",
)
model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
model.load_tokenizer(model_id)
# 生成图像
prompt = "一只棕白相间的狗在草地上奔跑"
image = model.generate_image(prompt=prompt, stream=True)
image.save("image.png")
方法2:命令行使用
python3 run_image_gen.py --model-id ./HunyuanImage-3 --prompt "一只棕白相间的狗在草地上奔跑"
使用方法详解
提示词编写技巧
为了获得最佳效果,建议按以下结构编写提示词:
主体和场景 + 图像质量和风格 + 构图和视角 + 光照和氛围 + 技术参数
示例提示词:
电影画面,复古的土黄色汽车旁,一个男人身穿暗蓝色衬衫靠在车上,嘴里叼着烟,明亮的阳光,温暖的黄色和深沉的青色,细腻光影,细腻色彩
模型版本选择
| 模型版本 | 特点 | 适用场景 |
|---|---|---|
| HunyuanImage-3.0 | 基础版本,不自动重写提示词 | 专业用户,精确控制 |
| HunyuanImage-3.0-Instruct | 指令版本,支持提示词重写和推理 | 普通用户,智能优化 |
高级参数设置
# 完整参数示例
python3 run_image_gen.py \
--model-id ./HunyuanImage-3 \
--prompt "你的提示词" \
--seed 42 \
--diff-infer-steps 50 \
--image-size 1280x768 \
--attn-impl flash_attention_2 \
--moe-impl flashinfer \
--save output.png
效果展示与案例
世界知识推理案例
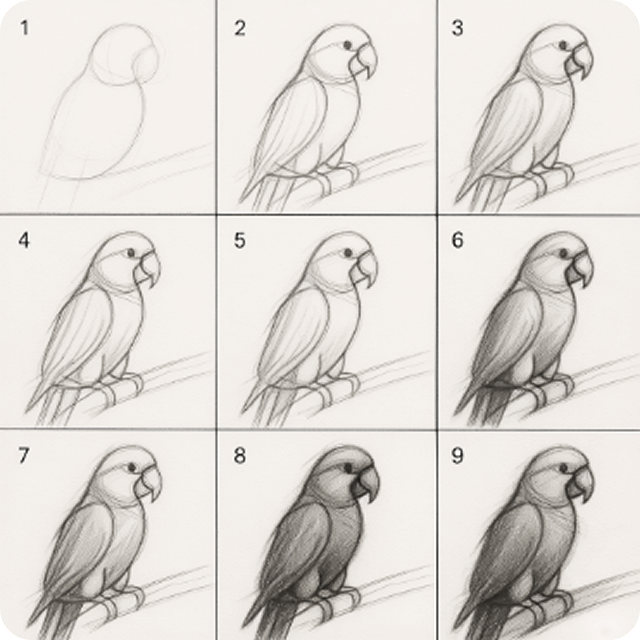
提示词: "生成一副九宫格教程,展现如何素描画一只鹦鹉"
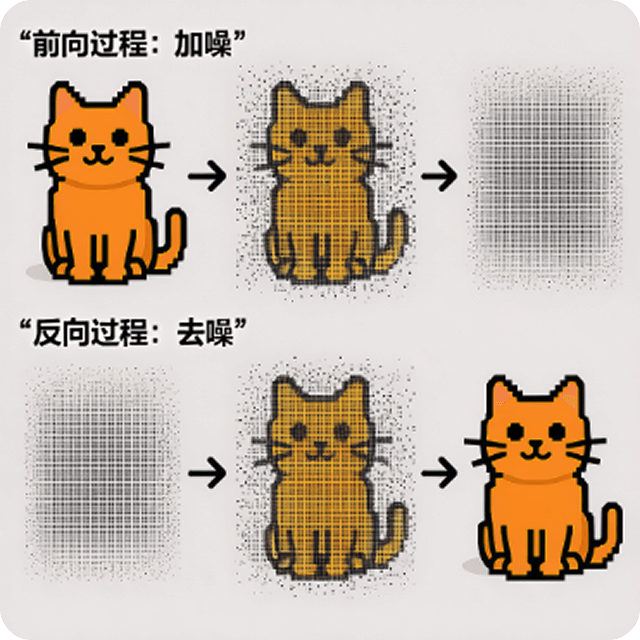
提示词: "创造一副插画和简单的文字介绍扩散生成模型的原理"
极致美学案例
提示词: "这是一幅极具视觉张力的杂志风海报,整体笼罩在暗黑幽灵般的神秘氛围中,背景采用简约高级的纯红色..."

提示词: "胶片摄影,动态模糊,湖边一个英俊的中国青年快速奔跑,微笑,蓬松的头发,白色衬衫..."

精确文字生成案例
提示词: "大师级排版 + 极繁主义,融入半调纹理、杂色颗粒与暖系同位色渐变..."

提示词: "3D渲染风格宣传海报,整体以绿色和白色为主色调,充满青春活力..."

性能评测对比
SSAE机器评测
SSAE(结构化语义对齐评估)是基于多模态大语言模型的智能评测指标,从12个类别的3500个关键点进行评估。
| 模型 | Mean Image Accuracy | Global Accuracy |
|---|---|---|
| HunyuanImage-3.0 | 85.2% | 87.4% |
| DALL-E 3 | 82.1% | 84.6% |
| Midjourney v6 | 81.8% | 83.9% |
| Stable Diffusion 3 | 78.5% | 80.2% |
GSB人工评测
采用Good/Same/Bad评估方法,由100+专业评估师对1000个提示词生成的图像进行评估:
| 对比模型 | Good | Same | Bad |
|---|---|---|---|
| vs DALL-E 3 | 52% | 31% | 17% |
| vs Midjourney v6 | 48% | 35% | 17% |
| vs Flux.1 | 61% | 28% | 11% |
✅ 评测结论
混元图像3.0在多项评测中均表现优异,特别是在文字渲染、复杂场景理解和艺术风格表现方面具有明显优势。
🤔 常见问题解答
Q: 混元图像3.0与其他开源模型相比有什么优势?
A: 主要优势包括:
- 规模最大:80B参数量,远超其他开源模型
- 世界知识推理:能够基于常识和专业知识生成图像
- 超长文本理解:支持1000+字符的复杂描述
- 商用级质量:效果媲美闭源模型
- 完全开源:提供完整源代码和商用许可
Q: 运行混元图像3.0需要什么硬件配置?
A: 推荐配置:
- GPU:3×80GB或4×80GB显存(如A100、H100)
- 存储:170GB可用空间
- 内存:64GB以上系统内存
- 系统:Linux + CUDA 12.8
Q: 是否支持商业使用?
A: 是的,混元图像3.0采用开源许可证,个人和企业均可免费使用,包括商业用途。
Q: 如何优化推理速度?
A: 建议安装性能优化组件:
pip install flash-attn==2.8.3 --no-build-isolation
pip install flashinfer-python
这可以将推理速度提升最多3倍。
Q: 模型支持哪些图像分辨率?
A: 支持多种分辨率:
- 自动模式:模型根据提示词自动预测最适合的分辨率
- 指定模式:支持常见比例如16:9、4:3等
- 自定义:可指定具体像素尺寸如1280x768
Q: 如何获得更好的生成效果?
A: 建议:
- 详细描述:提供丰富的场景和细节描述
- 结构化提示词:按主体→风格→构图→光照的顺序组织
- 使用Instruct版本:支持自动提示词优化
- 参考官方案例:学习优秀提示词的写法
总结与展望
腾讯混元图像3.0的发布标志着开源AI图像生成领域的重大突破。作为全球最大的开源文生图模型,它不仅在技术上实现了多项创新,更重要的是为整个AI社区提供了一个强大的基础工具。
核心价值
- 技术民主化:让更多开发者和研究者能够使用顶级的图像生成技术
- 商业友好:完全开源的商用许可降低了企业应用门槛
- 创新推动:MoE+Transfusion架构为未来多模态模型发展指明方向
- 生态建设:丰富的文档和社区支持促进技术普及
下一步行动建议
对于开发者:
- 下载模型进行技术验证和集成测试
- 参与社区讨论,贡献优化建议
- 基于模型开发创新应用
对于企业:
- 评估模型在具体业务场景中的应用潜力
- 考虑将模型集成到现有产品和服务中
- 制定基于开源AI的技术发展策略
对于研究者:
- 深入研究MoE+Transfusion架构的技术细节
- 探索多模态统一建模的新方向
- 推动相关领域的学术研究
🚀 未来展望
根据官方路线图,混元图像3.0后续还将推出图生图、多轮交互、蒸馏版本等功能,进一步扩展应用场景和降低使用门槛。
相关资源:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号