a、爬虫简介
爬虫简介
参照千峰教育视频文档和weixin_49088841的博客,该文章仅供自己在线查阅
1、什么是爬虫
⽹络爬⾍(⼜被称为⽹⻚蜘蛛,⽹络机器⼈)就是模拟客户端发送⽹络请求, 接收请求响应,⼀种按照⼀定的规则,⾃动地抓取互联⽹信息的程序。 只要是浏览器能做的事情,原则上,爬⾍都能够做(可见即可爬)
1.1爬虫有哪些用途
①为其他数据提供数据源,像AI人脸识别、AI人工智能都要基于大数据的基础下才可以实现
②快速批量的获取想要的数据,不用手动的一个个下载(图片、文字音视频等)
③抓取想要的数据做数据分析,做商业预测(美团评论、股票涨跌等)
④抓取vip数据,不用购买vip就可以免费获得vip数据(慎用设计版权在法律的边缘)
⑤模拟人的点击行为,做一些实时的动作(抢票、短信轰炸等)
注意:不可获取个人信息,不可制造恶意程序,侵犯他人权益(要遵纪守法),优秀的爬虫工程师一定要学好法律,不然就凉凉
1.2用python做爬虫的优势
①在python没有火之前大家都是用的Java做的爬虫但是代码量⼤,代码笨重用且复杂,需要一定的基础。
②用Python做爬虫就相对简单,因为它⽀持模块多、代码简介、开发效率⾼ (scrapy框架),只要少量代码就可批量抓取数据,丰富的第三方库为他提供了很多遍历
③用PHP对多线程、异步⽀持不太好
④用C/C++做爬虫代码量⼤,难以编写
1.3爬虫的分类
①通用网络爬虫(传统搜索引擎百度、谷歌必须遵守robot协议)
②聚焦网络爬虫(有目的有选择的爬取数据):我们写的就是聚焦爬虫
③增量式网络爬虫(聚焦包括它,更新爬取信息)
④深层网络爬虫(看不见的数据)
2、浏览器的工作原理
2.1学爬虫为什么要了解它
google、firefox等都是常用的浏览器(程序员常用google因为它支持的js内核更轻量,访问同一个网站他最快加载出来,但国内被封了,也可以用),我们抓取数据就是模拟浏览器的行为去得到数据
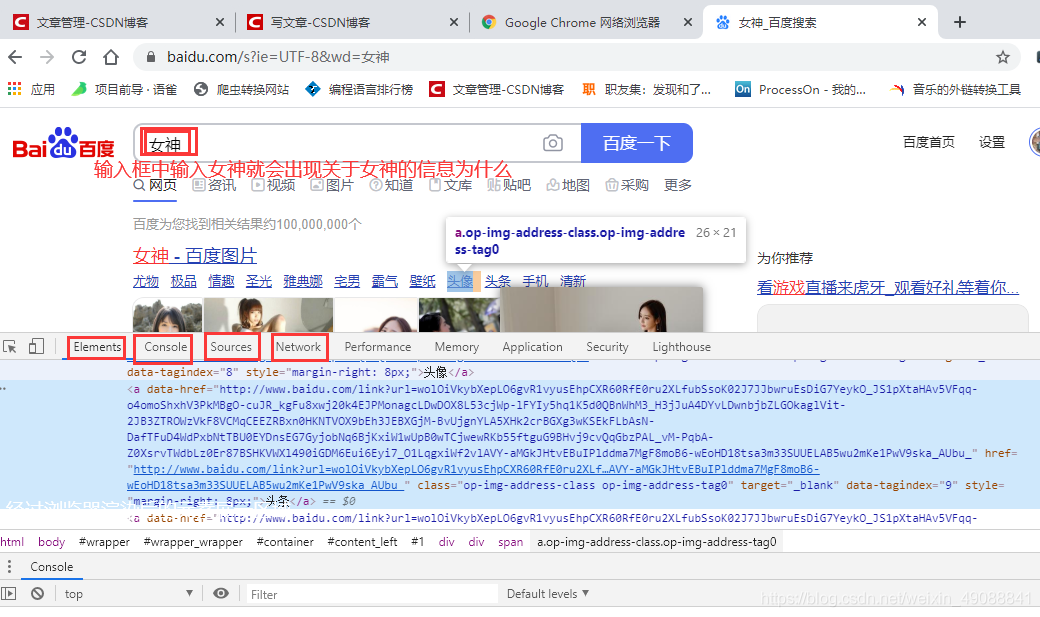
①经过浏览器渲染后的html代码,可能源码中没有
②控制台,调试前端代码用写的是javascript(这门语言爬虫工程师可以不会但要了解,往后看会逐渐涉及)
③资源,浏览器向服务器请求的所有资源都在这里但也写得是js代码,为什么可见即可爬就因为所有数据都可以获取到(但是有些数据要解密)
④网络,网络传输的各种api(应用程序接口)都可以在这里面找到,你想抓取数据,就要分析他在哪个api有的直接在源代码中就不用分析。
3、数据获得的过程
3.1流程
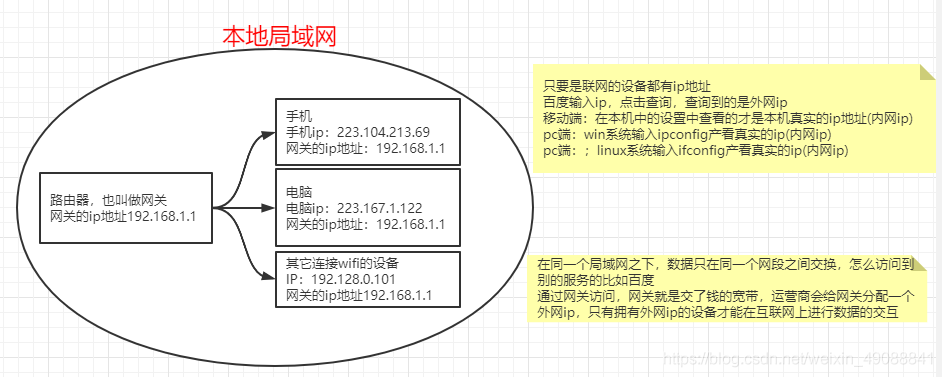
①找到对方ip(通过DNS找到ip发送请求)
② 数据要发送到对⽅指定的应⽤程序上。为了标识这些应⽤程序,所以给这些⽹络应⽤程序都⽤数字进⾏了标识。这个数字就叫做端⼝。(每个操作系统只有65535个端口,常见端口要记住)端口号可以自己修改但是建议不要
③定义通讯规则。这个通讯规则我们⼀般称之为协议
3.2 通讯协议
①国际组织定义了通⽤的通信协议 TCP/IP协议。
②所谓协议就是指计算机通信⽹络中两台计算机之间进⾏通信所必须共同遵守的规定或规则。
③HTTP⼜叫做超⽂本传输协议(是⼀种通信协议) HTTP 它的端⼝是 80。https就是一种更加安全的加密协议http+ssl(secure socket layer)
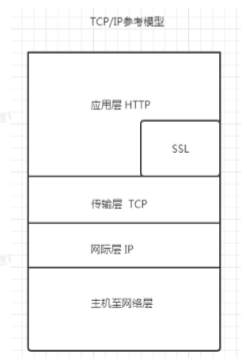
4、网络模型
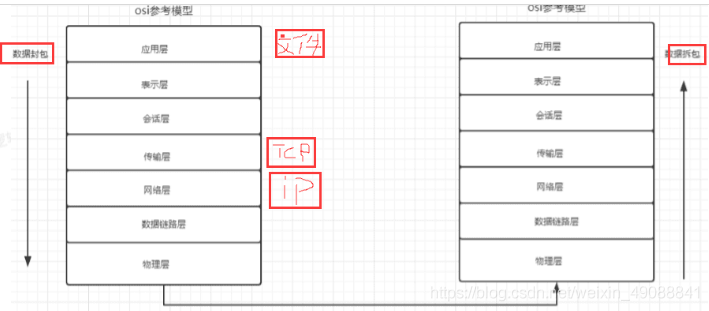
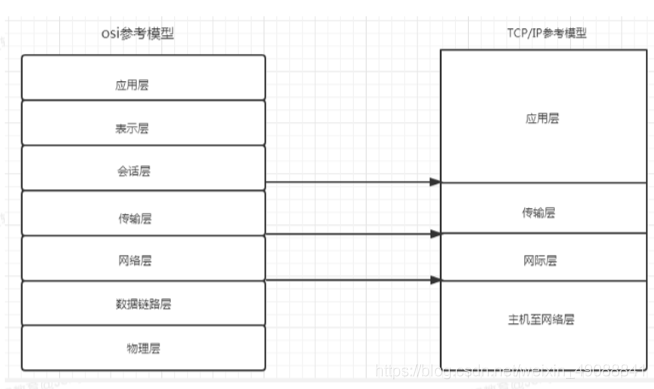
4.1什么是HTTPS
①https=http+ssl,顾名思义,https是在http的基础上加上了SSL保护壳,信息的加密过程就是在SSL中完成的
②https,是以安全为⽬标的HTTP通道,简单讲是HTTP的安全版。即HTTP下 加⼊SSL层,HTTPS的安全基础是SSL
4.2SSL怎么理解
SSL也是⼀个协议主要⽤于web的安全传输协议(secure socket layer)
4.3Http请求与响应
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息
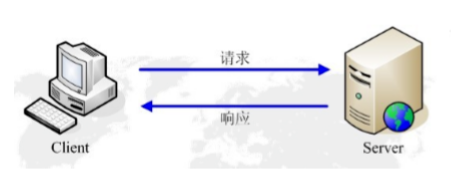
①当⽤户在浏览器的地址栏中输⼊⼀个URL并按回⻋键之后,浏览器会向HTTP 服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种⽅法。
②. 当我们在浏览器输⼊URL http://www.baidu ,com 的时候,浏览器发送⼀个 Request请求去获取 http://www.baidu.com 的html⽂件,服务器把 Response⽂件对象发送回给浏览器。
③浏览器分析Response中的 HTML,发现其中引⽤了很多其他⽂件,⽐如 Images⽂件,CSS⽂件,JS⽂件。 浏览器会⾃动再次发送Request去获取 图⽚,CSS⽂件,或者JS⽂件。
④ 当所有的⽂件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
5、常用的几个概念
5.1请求方法GET和POST
GET:查询的参数会在URL上显示出来
POST:查询的参数和需要提交的数据是隐藏在From表单里的,不会在URL地址上显现出来
5.2URL组成部分
URL: 统⼀资源定位符 https://new.qq.com/omn/TWF20200/TWF2020032502924000.html
https: 协议
new.qq.com: 主机名可以将主机理解为⼀台名叫 news.qq.com 的机器。这台主机在 qq.com 域名下 port 端⼝号: 43/new.qq.com
在他的后⾯有个 :80是http的端口号,43可以省略
TWF20200/TWF2020032502924000.html 访问资源的路径
#anchor: 锚点⽤前端在做⻚⾯定位的
在浏览器请求⼀个url,浏览器会对这个url进⾏⼀个编码。(除英⽂字 ⺟、数字和部分标识其他的全部使⽤% 加⼗六进制码进⾏编码)
例如 : https://tieba.baidu.com/f?ie=utf8&kw=海贼王&fr=search海贼王=海贼王
5.3 User-Agent
记录⽤户的浏览器、操作系统等,为了让⽤户更好的获取HTML⻚⾯效果
5.4Refer
表明当前这个请求是从哪个url过来的。⼀般情况下可以⽤来做反爬的技术数据来源
5.5状态码
200 : 请求成功
301 : 永久重定向
302 : 临时重定向
403 : 服务器拒绝请求
404 : 请求失败(服务器⽆法根据客户端的请求找到资源(⽹⻚))
500 : 服务器内部请求
6、爬虫与Web后端服务之间的关系
爬虫使用网络请求库,相当于客户端请求, Web后端服务根据请求响应数据。
爬虫即向Web服务器发起HTTP请求,正确地接收响应数据,然后根据数据的类型(Content-Type)进行数据的解析及存储。
爬虫程序在发起请求前,需要伪造浏览器(User-Agent指定请求头),然后再向服务器发起请求, 响应200的成功率高很多。
7、Python爬虫技术的相关库
网络请求:
- urllib
- requests / urllib3
- selenium(UI自动测试、动态js渲染)
- appium(手机App 的爬虫或UI测试)
数据解析:
- re正则
- xpath
- bs4
- json
数据存储:
- pymysql
- mongodb
- elasticsearch
多任务库:
- 多线程 (threading)、线程队列 queue
- 协程(asynio、 gevent/eventlet)
爬虫框架
- scrapy
- scrapy-redis 分布式(多机爬虫)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号