---sql server--删除重复记录
想必每一位SQL SERVER开发人员都有过类似的经历,在对数据库进行查询或统计的时候不时地会碰到由于表中存在重复的记录而导致查询和统计结果不准确。
解决的办法就是将这些重复的记录删除,只保留其中的一条。
在SQL Server中除了对拥有十几条记录的表进行人工删除外,实现删除重复记录一般都是写一段代码,用游标的方法一行一行检查,删除重复的记录。因为这种方法需要对整个表进行遍历,所以对于表中的记录数不是很大的时候还是可行的,如果一张表的数据达到上百万条,用游标的方法来删除简直是个噩梦,因为它会执行相当长的一段时间。
首先假设存在一个产品信息表Products,其表结构如下:
(
ProductID int,
ProductName nvarchar (40),
Unit char(2),
UnitPrice money
)
表中的数据如图1:
|
ProductID |
ProductName |
Unit |
UnitPrice |
|
1 |
Northwoods Cranbery |
Bottle |
9.90 |
|
2 |
Chang |
Bottle |
20.00 |
|
2 |
Chang |
Bottle |
20.00 |
|
3 |
Aniseed Syrup |
G |
1.00 |
|
4 |
Tofu |
Kg |
2.80 |
|
4 |
Tofu |
Kg |
2.80 |
|
4 |
Tofu |
Kg |
2.80 |
图1中可以看出,产品Chang和Tofu的记录在产品信息表中存在重复。现在要删除这些重复的记录,只保留其中的一条。步骤如下:
图1中可以看出,产品Chang和Tofu的记录在产品信息表中存在重复。现在要删除这些重复的记录,只保留其中的一条。步骤如下:
第一板斧——建立一张具有相同结构的临时表
(
ProductID int,
ProductName nvarchar (40),
Unit char(2),
UnitPrice money
)
第二板斧——为该表加上索引,并使其忽略重复的值
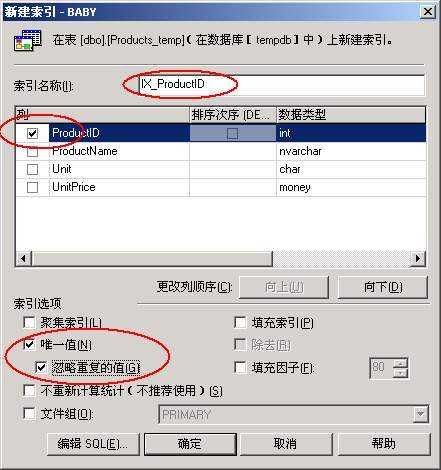
方法是在企业管理器中找到上面建立的临时表Products _temp,单击鼠标右键,选择所有任务,选择管理索引,选择新建。如图2所示。
按照图2中圈出来的地方设置索引选项。
第三板斧——拷贝产品信息到临时表
insert into Products_temp Select * from Products
此时SQL Server会返回如下提示:
服务器: 消息 3604,级别 16,状态 1,行 1
已忽略重复的键。
它表明在产品信息临时表Products_temp中不会有重复的行出现。
第四板斧——将新的数据导入原表
将原产品信息表Products清空,并将临时表Products_temp中数据导入,最后删除临时表Products_temp。
delete Products
insert into Products select * from Products_temp
drop table Products_temp
这样就完成了对表中重复记录的删除。无论表有多大,它的执行速度都是相当快的,而且因为几乎不用写语句,所以它也是很安全的。
小提示:上述方法中删除重复记录取决于创建唯一索引时选择的字段,在实际的操作过程中读者务必首先确认创建的唯一索引字段是否正确,以免将有用的数据删除。
==========================================
Oracle::::::::
在Oracle中,可以通过唯一rowid实现删除重复记录;还可以建临时表来实现...这个只提到其中的几种简单实用的方法,希望可以和大家分享(以表employee为例)。
SQL> desc employee
Name Null? Type
emp_id NUMBER(10)
emp_name VARCHAR2(20)
salary NUMBER(10,2)
可以通过下面的语句查询重复的记录:
SQL> select * from employee;
EMP_ID EMP_NAME SALARY
1 sunshine 10000
1 sunshine 10000
2 semon 20000
2 semon 20000
3 xyz 30000
2 semon 20000
SQL> select distinct * from employee;
EMP_ID EMP_NAME SALARY
1 sunshine 10000
2 semon 20000
3 xyz 30000
SQL> select * from employee group by emp_id,emp_name,salary having count (*)>1
EMP_ID EMP_NAME SALARY
1 sunshine 10000
2 semon 20000
=================
(
select max(rowid) from employe e2
where e1.emp_id=e2.emp_id
and e1.emp_name=e2.emp_name
and e1.salary=e2.salary
);
==================
EMP_ID EMP_NAME SALARY
1 sunshine 10000
3 xyz 30000
2 semon 20000
2. 删除的几种方法:
(1)通过建立临时表来实现
SQL>create table temp_emp as (select distinct * from employee)
SQL> truncate table employee; (清空employee表的数据)
SQL> insert into employee select * from temp_emp; (再将临时表里的内容插回来)
( 2)通过唯一rowid实现删除重复记录.在Oracle中,每一条记录都有一个rowid,rowid在整个数据库中是唯一的,rowid确定了每条记录是在Oracle中的哪一个数据文件、块、行上。在重复的记录中,可能所有列的内容都相同,但rowid不会相同,所以只要确定出重复记录中那些具有最大或最小rowid的就可以了,其余全部删除。
SQL>delete from employee e2 where rowid not in (
select max(e1.rowid) from employee e1 where
e1.emp_id=e2.emp_id and e1.emp_name=e2.emp_name and e1.salary=e2.salary);--这里用min(rowid)也可以。
SQL>delete from employee e2 where rowid <(
select max(e1.rowid) from employee e1 where
e1.emp_id=e2.emp_id and e1.emp_name=e2.emp_name and e1.salary=e2.salary);
(3)也是通过rowid,但效率更高。
SQL>delete from employee where rowid not in (
select max(t1.rowid) from employee t1 group by t1.emp_id,t1.emp_name,t1.salary);--这里用min(rowid)也可以。
EMP_ID EMP_NAME SALARY
1 sunshine 10000
3 xyz 30000
2 semon 20000


 浙公网安备 33010602011771号
浙公网安备 33010602011771号