

Jigsaw Unintended Bias in Toxicity Classification
-
任务的目的
-
原文表述
-
Jigsaw Unintended Bias in Toxicity Classification
-
Training a model from data with these imbalances risks simply mirroring those biases back to users.
-
build a model that recognizes toxicity and minimizes this type of unintended bias with respect to mentions of identities.
-
-
自己理解
-
任务一:识别不良的对话
- 对于不良的解释:
- toxicity is defined as anything rude, disrespectful or otherwise likely to make someone leave a discussion
- 对于不良的解释:
-
任务二:消除语句的偏见
-
例如:犹太人很不幸的出现在了辱骂类的词语中,因此,此次任务还要消除这样的偏见,将犹太人这样的中性词,将辱骂因素去除。
-
会有专门的指标去评价歧义
-
optimizing a metric designed to measure unintended bias
-
-
-
-
任务中遇到的困惑
-
1、Training a model from data with these imbalances risks simply mirroring those biases back to users.
-
2、Note that the data contains different comments that can have the exact same text. Different comments that have the same text may have been labeled with different targets or subgroups.
-
-
评价指标
- ROC-AUC
- 低的值,说明模型的区分不良和正常对话的能力较弱
- Subgroup AUC
- 低的值,表明会对于正常对话识别能力低,表现为给正常的对话过高的不良得分(target)
- BPSN 𝐵𝑎𝑐𝑘𝑔𝑟𝑜𝑢𝑛𝑑𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒,𝑆𝑢𝑏𝑔𝑟𝑜𝑢𝑝𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒 AUC
-低的值,表明会对不良对话的识别能力低, 表现为会给不良的对话过低的不良得分 -
歧义的总得分
![]()
![]()
-
模型总得分
![]()
![]()
- ROC-AUC
-
数据集
-
内容
-
comment_text
- 每一个样本的内容,即被分析的内容
-
target(标签数据)
- 训练集中已知;测试集中未知,需要预测的部分;规定当target>=0.5时,该样本即为不良评论
-
关于不良评论的子属性,不作于预测部分,仅供额外研究使用
- severe_toxicity:非常不良
- obscene:淫秽
- threat:恐吓
- insult:辱骂
- identity_attack人身攻击
- sexual_explicit露骨的
-
样本评论中涉及的其它特征
-
性别
- male:男性的
- female:女性的
- transgender:变性的
- other_gender:其它性别
-
性取向
- heterosexual:异性恋的
- homosexual_gay_or_lesbian:同性恋的
- bisexual:双性恋的
- other_sexual_orientation:其它性取向
-
宗教信仰
- christian:基督徒
- jewish:犹太教徒
- muslim:穆斯林
- hindu:印度教的
- buddhist:佛教徒
- atheist:无神论者
- other_religion:其他宗教
-
人种
- black:黑种人
- white:白种人
- asian:亚洲人
- latino:拉丁美洲人
- other_race_or_ethnicity:其它种族或民族
-
残障
- physical_disability:生理缺陷
- intellectual_or_learning_disability:智力缺陷
- psychiatric_or_mental_illness:精神病
- other_disability:其他缺陷
-
-
评分含义
-
评分者主观对评论与相应特征之间的匹配程度作出的评分
-
取值范围:0.0~1.0
-
-
-
数据集文件
- train.csv:带有标签的集合
- test.csv:不带有标签的集合
- sample_submission.csv:提交的格式样例
- all_data:所有样本
-
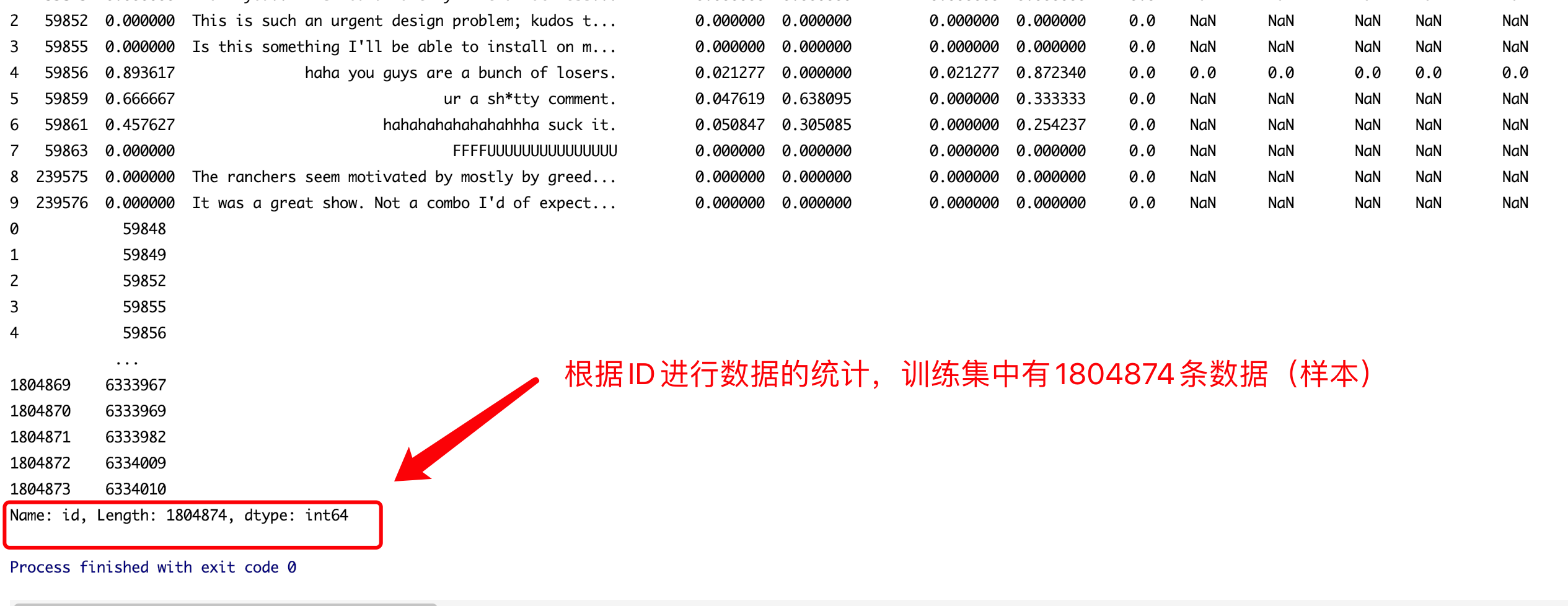
通过pycharm统计出训练集与测试集中的样本数量
-
训练集中
-
测试集中
-
-
数据可视化
- 由于数据的差距较大,样本未处理,图形效果不理想
- X轴:标签值
- Y轴:人身攻击评分
- 目的:显示人身攻击评分与样本标签的关系
![]()
- 由于数据的差距较大,样本未处理,图形效果不理想
-
-
流程
-
数据预处理
-
加载数据
- 读取数据集
- 转换为小写
- 替换简写字符串
- 待训练文本与待预测文本中的字符用token2id中的下标表示
- 通过正则表达式替换所有数字为空隔(‘’)
- 通过str.strip()函数去除头尾空格
- 将所有空格替换为nan
- nan预测
- 填补缺失值
- 获取特征值
- 打乱顺序
-
建立词表
- 参数类型
- 字典
- 参数
- token2id(
用0表示、 用max_features + 1表示) - id2token()
- token2id(
- 参数类型
-
建立词嵌入矩阵
-
待训练文本与待预测文本中的字符用token2id中的下标表示
-
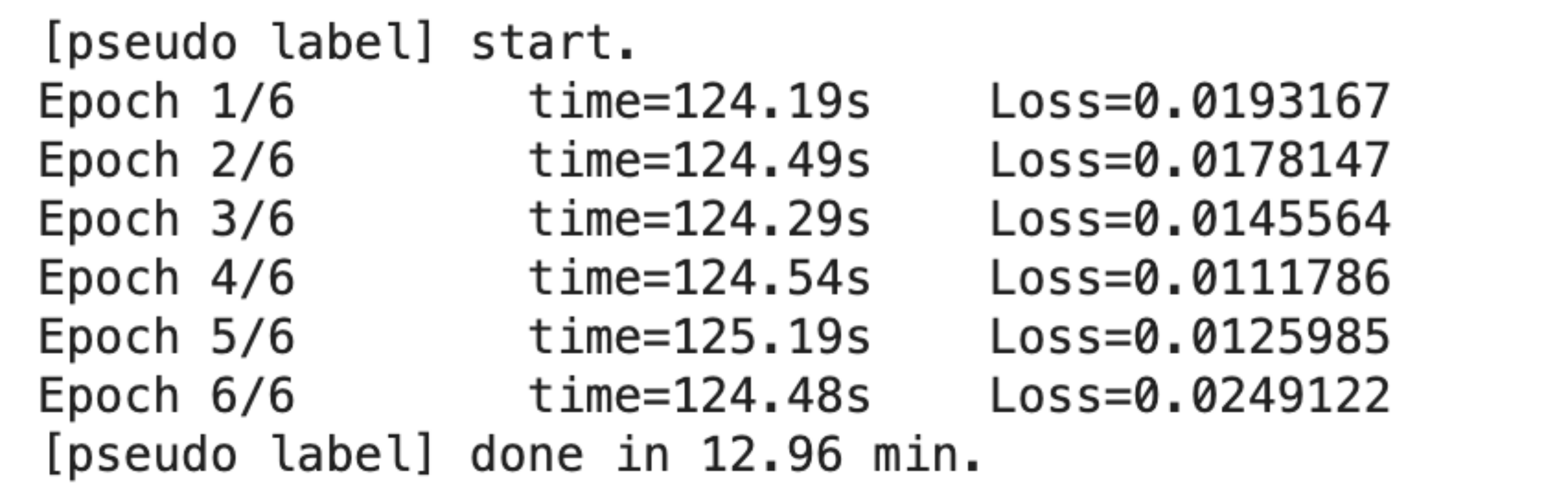
得到伪标签
- 伪标签训练过程:
- 通过预先标记好的训练集训练模型,将测试集在训练后的模型上做预测,是的测试集成为带有伪标签的数据集。将训练集与带有伪标签的测试集合并后继续训练模型。
- 作用
- 增强模型的泛化能力
- EMA:
- 滑动平均,可以看作是变量在过去一段时间内的均值
- 采用EMA的作用:
- 减少脏数据最整体数据的影响,是整体数据更加平滑
![]()
- 上图为伪标签的迭代次数,及每次迭代产生的Loss值。
- 分析:
- 前四次的Loss逐渐降低,后两次却开始升高,可能与学习率rate的取值有关。
- 措施:
- 减小rate值,或减小训练次数
- 伪标签训练过程:
-
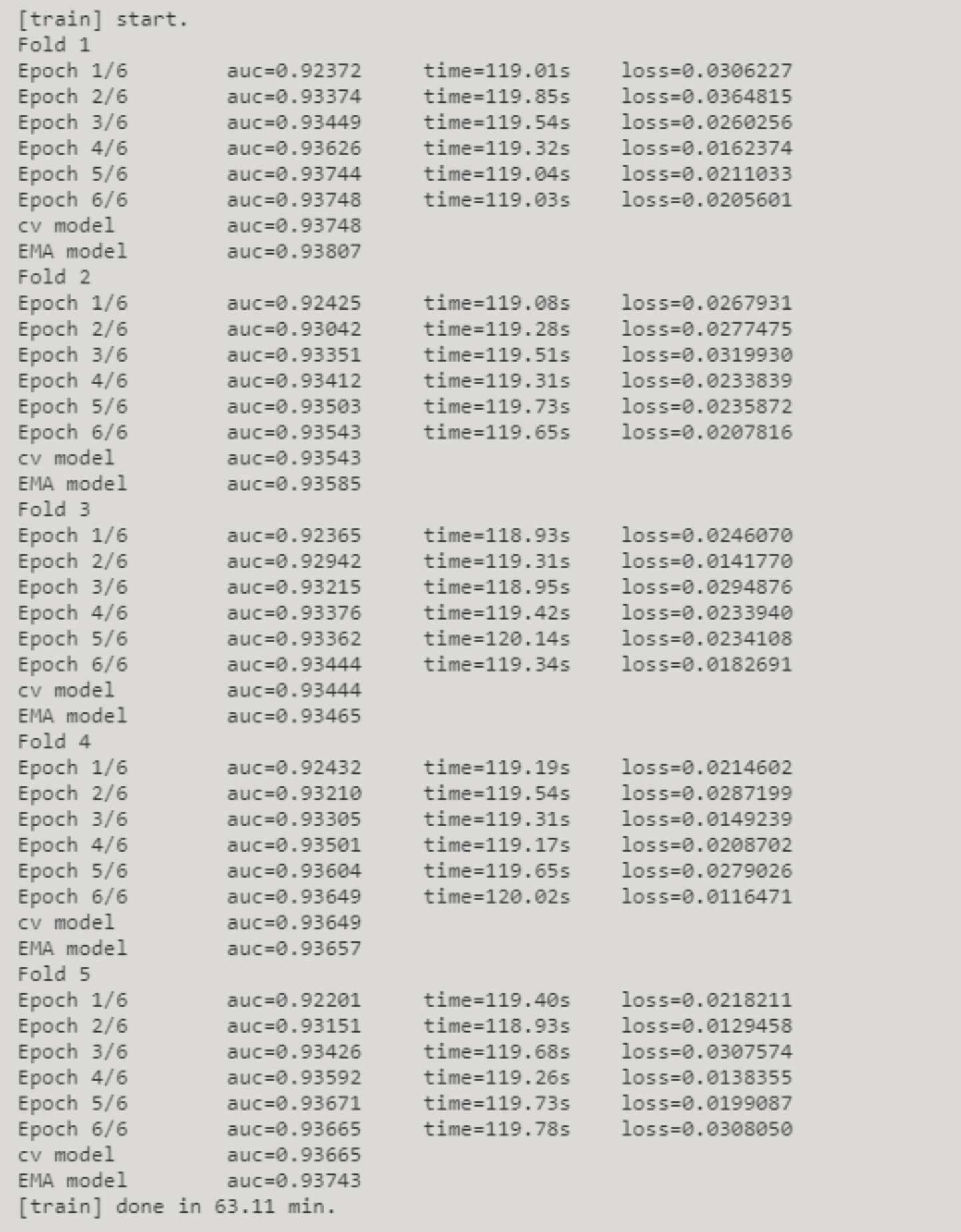
最终训练
- 训练集:
- 采用StratifiedKFold,将训练集分为测试集与验证集,并设置每一折的大小。
- 测试集:
- 采用KFold
- 过程:
- 最终训练过程与获取伪标签的过程基本类似,使用的优化器及损失函数均相同。
- 最终训练过程及每步的损失函数值如下表所示
![]()
- 训练集:
-
得出预测结果
-
-
参考
-
完整代码
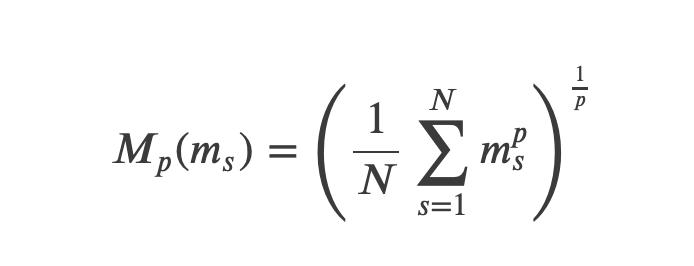

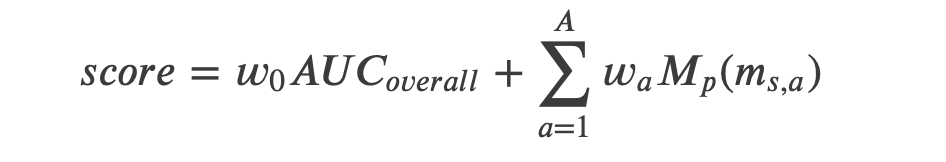




 浙公网安备 33010602011771号
浙公网安备 33010602011771号