Character level language model - Dinosaurus Island脉络总结
-
1、打开数据集
- 读取恐龙名字,并创建字符列表
- 创建 char_to_ix 与 ix_to_char,作用:将softmax结果转换成字母
-
2、初始化参数
- 输入X-----------0向量
- 隐藏层状态a------0向量
- 循环:
- 前向传播计算损失
- 反向传播计算关于损失的梯度
- 修剪梯度以免梯度爆炸
- 用梯度下降更新规则更新参数。
- 返回学习后了的参数
-
3、两个模块
-
梯度修剪模块------处理梯度爆炸
- 方法:通过设定Maxvalue阈值,将梯度控制在阈值范围内
- 核心函数:np.clip(gradient, -maxValue, maxValue, out=gradient)
-
抽样模块---------按模型输出概率逐个抽取字符,生成恐龙名字
- 核心函数:
-
#设置随机数种子
np.random.seed(0)
#设置概率
p = np.array([0.1, 0.0, 0.7, 0.2])
#依据概率分布p,从列表中抽样
index = np.random.choice([0, 1, 2, 3], p = p.ravel())
#含义:
#P(index=0)=0.1 , P(index=1)=0.0 , P(index=2)=0.7 , P(index=3)=0.2
-
随机梯度下降(优化过程,并且加入了上面的梯度修剪功能):
def optimize(X, Y, a_prev, parameters, learning_rate ):
# X -- 整数列表,其中每个整数映射到词汇表中的字符。
# Y -- 整数列表,与X完全相同,但向左移动了一个索引。
# a_prev -- 上一个隐藏状态
# parameters -- 字典,包含了以下参数:
# Wax -- 权重矩阵乘以输入,维度为(n_a, n_x)
# Waa -- 权重矩阵乘以隐藏状态,维度为(n_a, n_a)
# Wya -- 隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
# b -- 偏置,维度为(n_a, 1)
# by -- 隐藏状态与输出相关的权重偏置,维度为(n_y, 1)
# learning_rate -- 模型学习的速率
return loss, gradients, a[len(X)-1]
# loss -- 损失函数的值(交叉熵损失)
# gradients -- 字典,包含了以下参数:
# dWax -- 输入到隐藏的权值的梯度,维度为(n_a, n_x)
# dWaa -- 隐藏到隐藏的权值的梯度,维度为(n_a, n_a)
# dWya -- 隐藏到输出的权值的梯度,维度为(n_y, n_a)
# db -- 偏置的梯度,维度为(n_a, 1)
# dby -- 输出偏置向量的梯度,维度为(n_y, 1)
# a[len(X)-1] -- 最后的隐藏状态,维度为(n_a, 1)
-
模型结构
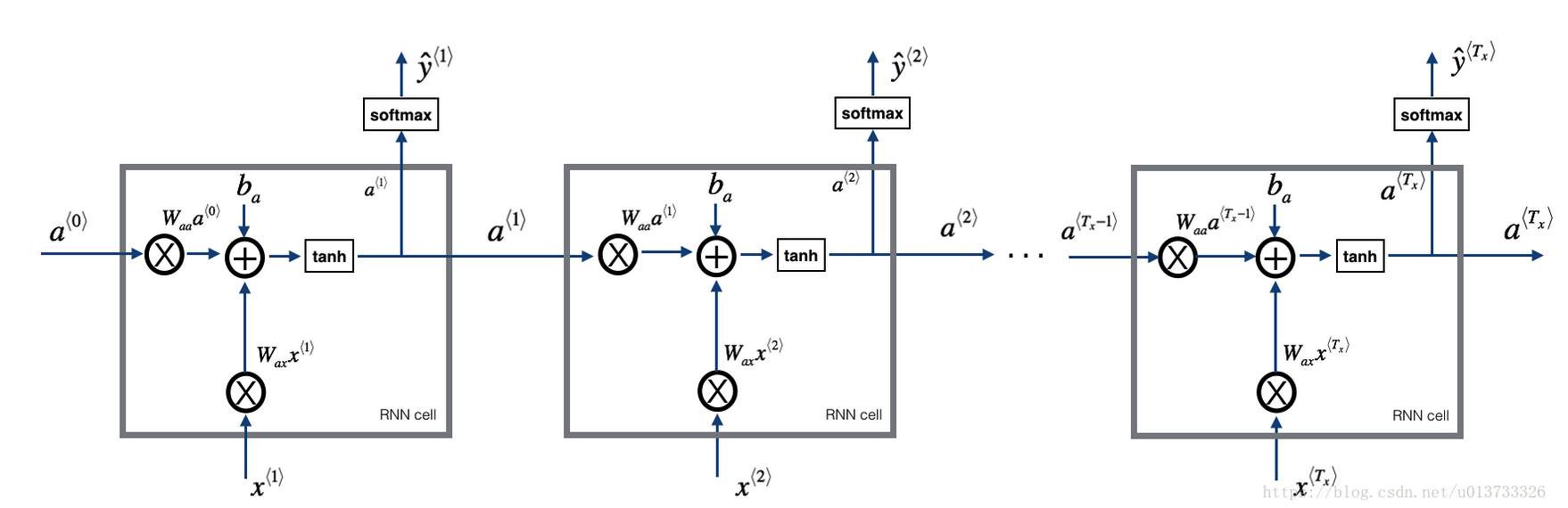
-
小技巧
- 1、将一个函数当作是参数传入另一个函数,传入的时候只需将函数名写入,可以在函数里定义变量,将变量传入参数函数里,将参数函数的结果作为变量并使用。
坚持学习,坚持记录Simbanana

 浙公网安备 33010602011771号
浙公网安备 33010602011771号