

ContentLengthInputStream 提前结束
插曲:
amazon S3 只有 http 协议
make sense,因为http协议无非是多几个sciii头而已,二进制在body里直传
0 background
GZipInputStream接入Http response的InputStream一直提前返回数据不全
猜测是socket IO available提前返回,在java.util.zip.GZIPInputStream#readTrailer中确实调用了available
if (this.in.available() > 0 || n > 26) {
1 socket IO available提前返回
https://www.cnblogs.com/FlyAway2013/p/15546337.html
InputStream.available() 可以获取InputStream的总的长度吗
答案是不确定。总结如下:
处理文件输入流: 可以
处理网络流(socket):不可以

总之,尽量还是别使用它来获取流的长度, 如果是文件, 我们完全可以使用 file对象的.length() 方法啊! 其他流 也应该有对应的方式获取流的长度,实在没有,那怎么办? 只能读流完之后再获取。
有些 InputStream 的实现将返回流中的字节总数,但也有很多实现不会这样做。试图使用此方法的返回值分配缓冲区,以保存此流所有数据的做法是不正确的。
JDK的解释意味着,我们不能通过该方法来获取InputStream的字节大小进而据此大小来初始化缓冲区的大小。
那么我们只能while循环read:
OutputStream out = new BufferedOutputStream(response.getOutputStream());
byte[] bytes = new byte[1024];
int len;
while ((len = in.read(bytes)) != -1) {
out.write(bytes, 0, len);
}
in.close();
out.flush();
out.close();
有人说:
所以调用网络流(socket)的available()方法前,一定记得要先调用read()方法,这样才能避免获取为0的不正确情况。
int firstByte = inputStream.read();
int length = inputStream.available();
没试过,感觉是行不通的,因为 网络缓存的原因, 并不是说你调用一次inputStream.read(); 就能够把 inputStream所有的数据加载到tcp缓存区。
---- 下面是转载 https://www.cnblogs.com/zjfjava/p/10829241.html
在处理文件输入流时,可以通过调用available()方法来获取还有多少字节可以读取,根据该数值创建固定大小的byte数组,从而读取输入流的信息。
但是在处理网络流(socket)时,通过available()方法对输入流进行长度判断,数值为0,这意味着对方发送的流中无数据,但实际上并非如此。
文件读取时read()一般是不会受阻的,因为文件流的可用字节数 available = file.length(),而文件的内容长度在创建File对象时就已知了。
在文件上载和表单提交的过程中,可以使用 request.getContentLength()方法代替InputStream.available()方法,通过调用 request.getContentLength() 得到 Content-Length ,并定义一个与 Content-Length 大小相等的字节数组 buffer
https://www.cnblogs.com/renjiaqi/p/11411915.html
InputStream.available()方法,这个方法可以在读写操作前先得知数据流里有多少个字节可以读取。需要注意的是,如果这个方法用在从本地文件读取数据时,一般不会遇到问题,但如果是用于网络操作,就经常会遇到一些麻烦。这是因为网络通讯往往是间断性的,一串字节往往分几批进行发送。例如对方发来字节长度100的数据,本地程序调用available()方法有时得到0,有时得到50,有时能得到100,大多数情况下是100。
https://www.cnblogs.com/alvinscript/p/16966592.html
InputStream的不同子类对InputStream.available()可能会有不同的实现,一些实现会返回当前可一次无阻塞读入的字节数,另一些实现会返回这个输入流可读入的字节总数, 因此应尽量避免使用该返回值作为开辟能容纳该输入流所有数据的缓冲大小依据。
解决方案
方案一:
public static byte[] streamToByteArray(InputStream in) throws IOException {
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[4096];
int n;
while (-1 != (n = in.read(buffer))) {
output.write(buffer, 0, n);
}
return output.toByteArray();
}
借助ByteArrayOutputStream,通过循环去读取流,直到读取完成,如果返回-1,表示全部读取完成。
方案二:
public static byte[] streamToByteArray(InputStream in) throws IOException {
byte[] bytes = new byte[bufferlength];
BufferedInputStream bis = new BufferedInputStream(is);
int length = bis.read(bytes, 0, bufferlength)
return bytes;
}
采用BufferedInputStream,它底层其实也是循环读取。
https://www.cnblogs.com/awkflf11/articles/5179156.html
available
public int available()
throws IOException
所以说要从网络中下载文件时,我们知道网络是不稳定的,也就是说网络下载时,read()方法是阻塞的,说明这时我们用
inputStream.available()获取不到文件的总大小。
但是从本地拷贝文件时,我们用的是FileInputStream.available(),难道它是将先将硬盘中的数据先全部读入流中?
然后才根据此方法得到文件的总大小?
好吧,我们来看看FileInputStream源代码吧
这里重写了inputStream中的available()方法
关键是:fileSystem.ioctlAvailable(fd.descriptor);
调用了FileSystem这是java没有公开的一个类,JavaDoc API没有。
其中
fileSystem 是一个IFileSystem对象,IFileSySTEM是java没有公开的一个类,JavaDoc API中没有;
fd是一个FileDescriptor对象,即文件描述符
说明这句代码应该是通过文件描述符获取文件的总大小,而并不是事先将磁盘上的文件数据全部读入流中,再获取文件总大小
搞清楚了这些,但是我们的主要问题没有解决,怎么获得网络文件的总大小?
我想原理应该都差不多,应该也是通过一个类似文件描述符的东西来获取。
网络下载获取文件总大小的代码:
HttpURLConnection httpconn = (HttpURLConnection)url.openConnection(); httpconn.getContentLength();
关键:getHeaderFieldInt("Content-Length", -1);
意思是从http预解析头中获取“Content-length”字段的值
其实也是类似从文件描述符中获取文件的总大小
https://www.jb51.net/program/288974vjz.htm
上代码:
InputStream in = new URL("http://www.apache.org").openStream();
System.out.println(in.available());
FileOutputStream out = new FileOutputStream("F://1.html");
//这里返回的i可以认为是流的大小
int i = IOUtils.copy(in, out);
System.out.println(i);
IOUtils.closeQuietly(out);
IOUtils.closeQuietly(in);
输出结果:
10660
60787
很显然,按照我们之前的理解,这两个输出得到的数据应该是一样的。后一个输出的文件大小是没有问题的,写入到硬盘上就是那么多字节。那么前一个输出的问题到底在哪呢?
通过查看api,发现了些端倪。该方法的描述是这样的:返回可以不受阻塞地从此文件输入流中读取的字节数
这个方法可以在读写操作前先得知数据流里有多少个字节可以读取。
- 需要注意的是,如果这个方法用在从本地文件读取数据时,一般不会遇到问题,
- 但如果是用于网络操作,就经常会遇到一些麻烦。比如,Socket通讯时,
- 对方明明发来了1000个字节,但是自己的程序调用available()方法却只得到900,
- 或者100,甚至是0,感觉有点莫名其妙,怎么也找不到原因。
- 其实,这是因为网络通讯往往是间断性的,一串字节往往分几批进行发送。
- 本地程序调用available()方法有时得到0,这可能是对方还没有响应,也可能是对方已经响应了,
- 但是数据还没有送达本地。对方发送了1000个字节给你,也许分成3批到达,
- 这你就要调用3次available()方法才能将数据总数全部得到。
所以在进行网络数据传输时候,不能使用InputStream.available(),这个方法导致系统出现长时间暂停状态
3 方案
3.1 统统读到Byte数组
文件太长,超过java数组最长允许长度咋办?
available返回值int,而大文件最初的长度肯定大于int界限,咋办?
搞一个复合ByteArrayInputStream,有点像Netty的0拷贝
@Override
public int available() throws IOException {
long i = 0;
for(ByteArrayInputStream byteArrayInputStream : list) {
i += byteArrayInputStream.available();
}
int res = i > Integer.MAX_VALUE ? Integer.MAX_VALUE : Integer.parseInt(String.valueOf(i));
print("available " + i + ":" + res);
return res;
}
最终没采纳,没必要复制一份,关键是available要处理好
3.2 多次调用available,如果avaialbe返回0,则反复调用
不采用,1)这个方法会阻塞,2)也不是100%靠谱,假如真的连续3次就返回0呢
3.3 拿contentlength
好
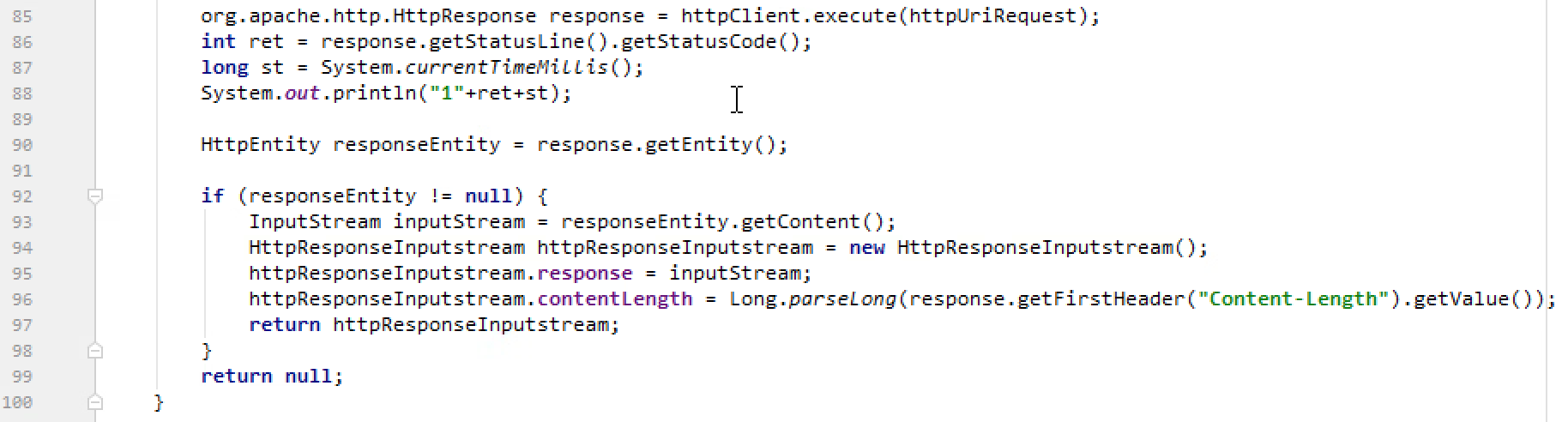

4 available有可能是系统调用,应当注意尽量override

 浙公网安备 33010602011771号
浙公网安备 33010602011771号