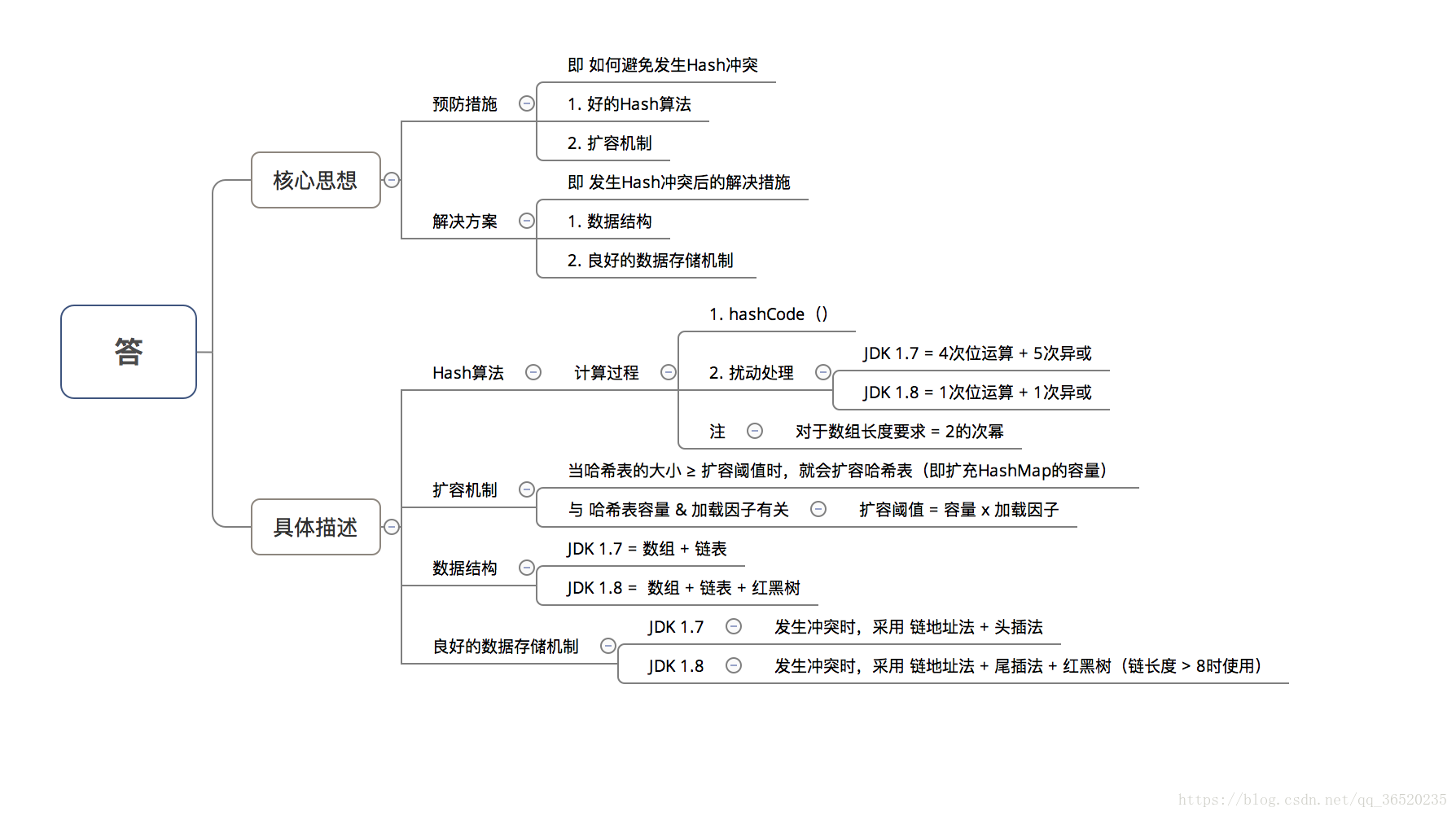
jdk1.7 1.8 hash map 区别及一些细节
1 扩容
1.7
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);重点
}
int i = indexFor(e.hash, newCapacity);重点
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
1.8
do {
next = e.next;
if ((e.hash & oldCap) == 0) { 重点
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;重点
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;重点
}
2 jdk8 引入红黑树
3 1.7 先扩容再插入,1.8先插入再决定是否扩容
4 1.7头插(
同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部
),1.8尾插
细节:为什么是8
1)treenodes的大小大约是常规节点的两倍——决定了不能直接用,有优势也有开销
2)红黑树平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要
3)还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。
细节:为什么0.75
如果是0.5 , 那么每次达到容量的一半就进行扩容,默认容量是16, 达到8就扩容成32,达到16就扩容成64, 最终使用空间和未使用空间的差值会逐渐增加,空间利用率低下。 如果是1,那意味着每次空间使用完毕才扩容,在一定程度上会增加put时候的时间及hash冲突的可能,提高读写的成本
空间使用率和性能的折中
红黑树根据什么排序:
如果key没有实现Comparable接口
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // bypass checks
return c;
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) {
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
}
}
return null;
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
先根据类名,再根据identityHashCode
identityHashCode根据对象的内存地址来计算hashcode,不管对象是不是重写了hashcode
https://blog.csdn.net/weixin_41725090/article/details/82147576
https://blog.csdn.net/qq_36520235/article/details/82417949

 浙公网安备 33010602011771号
浙公网安备 33010602011771号