
总结
a.
String s = "abc"; JVM会根据实际情况决定是否有必要创建新的对象
String s = new String("abc"); 一概在堆中创建新的对象
==比较对象的地址,equals比较值
b. final关键字
为什么String类是final?因为不想它被继承,试想,如果可以继承,由于它是操作系统本地API,如果继承其中方法被重写了,注入了恶意代码,会很不安全,导致各种问题。所以,为了不可以被继承,String,Integer等类被设计为final
final字段,该字段值不可变
final方法,该方法不可覆盖
final类,该类不可继承
c.一般异常需要抛出或者编写try...catch... 代码,运行时异常由JVM处理
d.
concurrent包下提供了一些原子类,如AtomicInteger, AtomicLong, AtomicReference等
synchronized用在代码块的方式:synchronized(obj){},当线程运行到该代码块时,就会拥有obj对象的对象锁,如果多个线程共享同一obj对象,那么就会形成互斥。
当obj为this时,表示当前调用该方法的实例对象。此时,其效果等同于 synchronized用在方法签名上。
synchronized(obj) {
//do something...
//obj.notify(); 唤醒之前因调用对象wait而等待的线程
//obj.wait(); 阻塞自己
}
lock高并发时更好的性能
信号量-可以控制多个线程同时对某个资源的访问;而且还可以控制流程,一个线程完成某一个动作就通过信号量通知别的线程。
volatile-保证读取volatile类型的变量总会返回最新写入的值。因为JVM保证了每次读变量都从内存中读,跳过CPU Cache这一步。
volatile在一定程度上保证有序性。
volatitle使用场景:1)标记状态 2)多线程环境中,可见性(总会返回最新值)
JVM内存调优
对JVM内存的系统级的调优主要目的是减少GC的频率和Full GC的次数。调优手段主要是通过堆内存的各部分的比例和GC策略来实现。
我们在大部分情况下都会选择将对象分配在年轻代-Xmn。
但是,对于占用内存较多的大对象,如果出现在年轻代很可能会扰乱年轻代GC,很可能导致空间不足,为了足够的空间容纳大对象,JVM不得不将年轻代中的对象挪到年老代,这对GC相当不利。
基于以上原因,可以将大对象直接分配到年老代-XX:PetenureSizeThreshold,保持年轻代对象结构的完整性,提高GC效率。
设置对象进入年老代的年龄:-XX:MaxTenuringThrehold
Java 8
Stream借助于Lambda表达式,极大的提高编程效率和程序可读性。同时,提供串行和并行两种模式,并行模式能够充分利用多核处理器的优势。
是一个函数式语言+多核时代综合影响的产物。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。
峰值流量高并发的瓶颈在哪里?
1)可能web线程连接数不够,那么-前端接口层:只要接口层设计是无状态的,当容量达到预警线,可以通过快速水平扩容负载均衡解决。
2)可能数据库查询性能太低,那么-
a.数据缓存:缓存集群,进行副本冗余设计。另外,比如如果某个关键字的商品经常被搜,那就可以考虑这部分商品列表放到缓存。这样不用每次访问数据库,性能大大提高。
b.数据库层:读写分离,数据库水平扩容;分库,分表。分库后,原来的一个数据库变成了多个数据库,这时就要用到分布式事务。
c.sql语句优化, 数据库索引优化
d.能使用静态页面的地方尽量使用,减少容器的解析
传统架构,瓶颈通常在数据库。对于读,通过缓存可以解决大部分问题;对于写,分库、分表、等等。
通过分库分表,本来一台数据库服务器高峰时可能要承受10W的高并发写,如果我们把数据放到十台数据库服务器上,那每台机器只需要承担1W的写,相对于要承受10W的写,现在写1W就显得轻松很多了。所以,应该说数据存储对传统架构来说,也早已不再是瓶颈了。
分布式事务
两阶段提交:第一阶段,准备-把日志提交到本地,以便出故障时恢复;第二阶段,真正的提交
高并发分布式事务一般性能比较差,替代的解决方案是,本地事务,异步消息,幂萌等。。。。使用消息系统通知,保证最终一致性:A系统的本地操作+发消息, +B系统的本地操作,B系统操作由消息驱动,如果B操作失败,消息会重投。
必须从支持事务的数据源中获得的数据库连接才支持分布式事务。
实现接口:XADataSource,getXAResource, XAConnection
现在来看看MySQL数据库为我们提供的四种事务隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
而事务传播机制,特别是在嵌套事务中,可以使被嵌套的内部事务自我控制事务,REQUIRE_NEW,从而不影响外部上层事务。
MySQL锁
尽量用较低的隔离级别;
InnoDB的行锁是基于索引实现的,所以精心设计索引,使用索引访问数据;
选择合理的事务大小,小事务发生锁冲突的几率也更小;
NIO 在服务端
NIO由原来的 多线程BIO阻塞 读写变成了 单线程轮询事件,找到可以进行读写的网络描述符进行读写。
由于线程的节约,大量线程切换带来的问题也随时解决,进而为处理海量连接提供了可能。
单线程处理IO的效率确实非常高,没有线程切换,只是拼命的读、写、选择事件。
现在的服务器都是多核服务器,可以利用多核进行IO,提高效率。所以可创建如下线程:
1)单线程选择就绪的事件 2)IO处理-连接、读、写 3)其它业务线程,如DB操作
NIO在Redis
Redis服务器使用单线程处理客服端请求。
基于IO多路复用模型,即操作系统提高的select/kqueue/epoll这样的系统调用。这些系统调用的功能:你告知一批socket,当socket的可读或可写事件发生时,获得通知信息。Reactor框架就实现了这个-
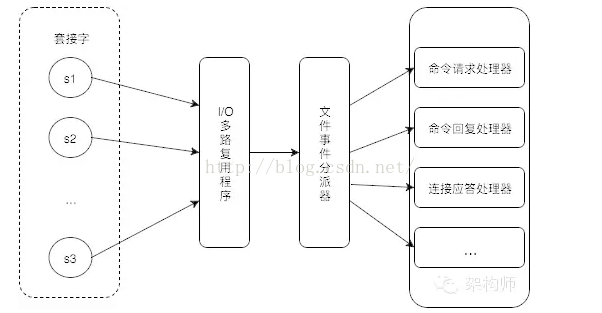
NIO在Dubbo
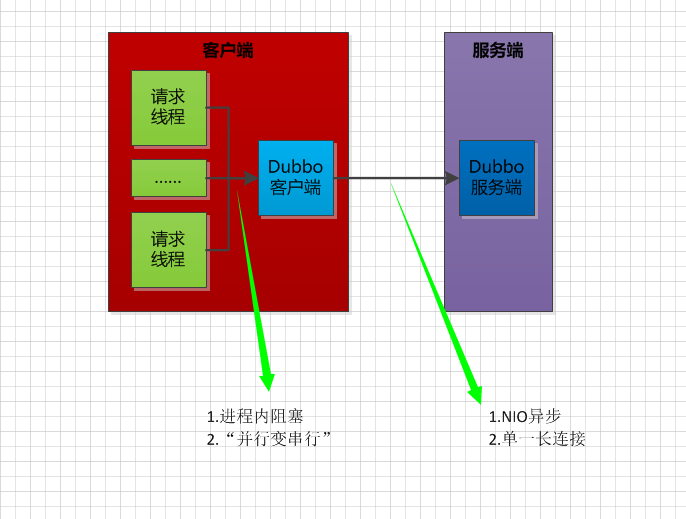
Dubbo在NIO的实现上默认依赖的是Netty,也就是说真正在长连接两端发包和接包的苦力是netty。
Dubbo
1. 集群容错
查询服务与写操作服务隔离:查询接口配置 retries="2",写接口操作配置retries="0", 如果不设置为0,超时,会重新连接,出现重复写的情况。
2.并发控制配置
服务端 executes/actives 并发执行(或占用线程池线程数): 当执行方法的线程超出了最大限制,就可以等待一个timeout时间,如果过了时间,就抛出异常
accepts限制服务端的连接数
3. 协议配置
对于众多的消费者,为了避免压垮几个有限的服务提供者,需单一连接,NIO,长连接的方式解决,即dubbo协议。
有一种场景,频繁的文件传输,比较大的数据传输, 则需要短链接同步传输比较合适,即RMI协议。
Redis 使用场景
1.session存储
2.队列:支持push/pop,以及发布订阅模式
3.排行榜,用有序集合sorted set,withscores
4.不经常变动的数据,如几万个客户信息,很多的数据字典
Redis AOF
appendonly yes
appendfsync everysec
重启或宕机后,还可以恢复
分布式调度/定时任务
Spring Quartz 集群, 配置configLocation,内部使用数据库表
乐观锁和悲观锁
乐观锁,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断在此期间别人有没有去更新这个数据。乐观锁适用于多读的应用类型。其实就像SVN一样地。
悲观锁,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次拿数据的时候都会上锁,这样别人想拿的时候就会阻塞直到他拿到锁。传统的关系型数据库里面用到很多这种锁机制,比如行锁,表锁,读写,写锁等,都是在操作之前先上锁。
Docker
对操作系统内核进行虚拟化,而虚拟机是对设备虚拟化。
1.更轻量级的虚拟化,减轻了虚拟机的性能损耗。
2.搞定了环境依赖问题,docker image中包含了运行环境和配置,方便部署和持续集成。
Spring Boot
优点:Auto Configuration Loading; fat jar让部署变的很美丽; Devtools改动代码重启..
自动化确实方便,做微服务再合适不过了,单一jar包部署和管理都非常方便。只要架构设计合理,大型项目也能用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号