20182216郭格 2020-2021-2 《Python程序设计》实验四报告
***实验二补交:当时写在了自己博客里未提交博客链接进作业:20182216郭格 2020-2021-2 《Python程序设计》实验二报告 - silencewilliam - 博客园 (cnblogs.com)
20182216 2020-2021-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1822
姓名: 郭格
学号:20182216
实验教师:王志强
实验日期:2021年6月30日
必修/选修: 公选课
实验四:
- 实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
批阅:注意本次实验不算做实验总分,前三个实验每个实验10分,累计30分。本次实践算入综合实践,打分为25分。
评分标准:
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
爬虫应用:
我选取了中国天气网抓取最近7天的天气以及最高/最低气温
http://www.weather.com.cn/weather/101190401.shtml
获取网页中的html代码:
def get_content(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
}
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout)
rep.encoding = 'utf-8'
# req = urllib.request.Request(url, data, header)
# response = urllib.request.urlopen(req, timeout=timeout)
# html1 = response.read().decode('UTF-8', errors='ignore')
# response.close()
break
# except urllib.request.HTTPError as e:
# print( '1:', e)
# time.sleep(random.choice(range(5, 10)))
#
# except urllib.request.URLError as e:
# print( '2:', e)
# time.sleep(random.choice(range(5, 10)))
except socket.timeout as e:
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
return rep.text
# return html_text
用开发者工具查看网页源码,并找到所需字段的相应位置
找到我们需要字段都在 id = “7d”的“div”的ul中。日期在每个li中h1 中,天气状况在每个li的第一个p标签内,最高温度和最低温度在每个li的span和i标签中。
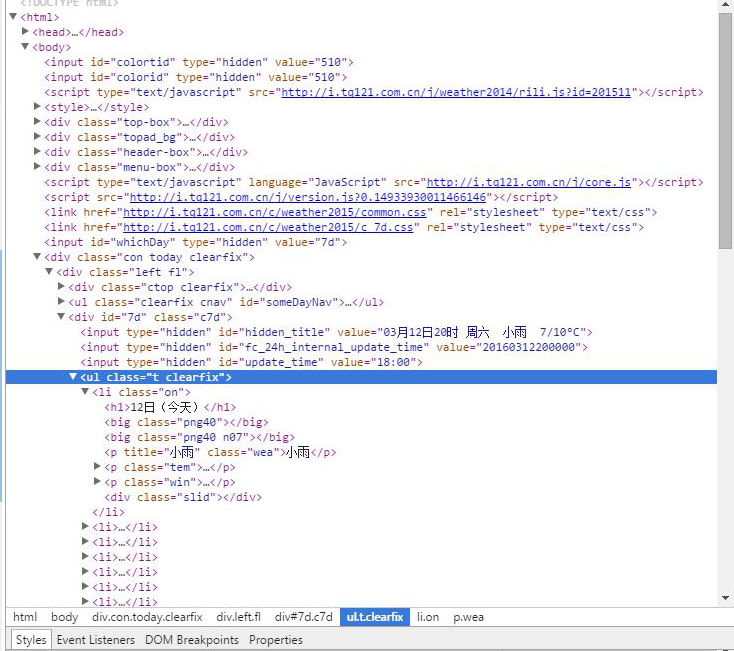
def get_data(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body # 获取body部分
data = body.find('div', {'id': '7d'}) # 找到id为7d的div
ul = data.find('ul') # 获取ul部分
li = ul.find_all('li') # 获取所有的li
for day in li: # 对每个li标签中的内容进行遍历
temp = []
date = day.find('h1').string # 找到日期
temp.append(date) # 添加到temp中
inf = day.find_all('p') # 找到li中的所有p标签
temp.append(inf[0].string,) # 第一个p标签中的内容(天气状况)加到temp中
if inf[1].find('span') is None:
temperature_highest = None # 天气预报可能没有当天的最高气温(到了傍晚,就是这样),需要加个判断语句,来输出最低气温
else:
temperature_highest = inf[1].find('span').string # 找到最高温
temperature_highest = temperature_highest.replace('℃', '') # 到了晚上网站会变,最高温度后面也有个℃
temperature_lowest = inf[1].find('i').string # 找到最低温
temperature_lowest = temperature_lowest.replace('℃', '') # 最低温度后面有个℃,去掉这个符号
temp.append(temperature_highest) # 将最高温添加到temp中
temp.append(temperature_lowest) #将最低温添加到temp中
final.append(temp) #将temp加到final中
return final
写入文件csv:
def write_data(data, name):
file_name = name
with open(file_name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
主函数:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101190401.shtml'
html = get_content(url)
result = get_data(html)
write_data(result, 'weather.csv')
生成的weather.csv文件如下:

git:pythoncode: 20182216公选课用 (gitee.com)
实验感悟
在本学期的课程学习中我受益匪浅,不仅掌握了python语言的基础并通过课堂与查找资料接触到了许多其他领域以及应用的知识。通过多次实验,我也有了最基本的动手编写python程序的能力。课堂上老师对知识的讲解与散发也面面俱到。刚开始听课时确实有种不知所云的感觉。但经过一段时间的学习再结合之前c语言的学习基础,前面的疑团都迎刃而解,达成了知识的融会贯通,这让我对python的学习更有信心。在这门课程上获得的宝贵经历将对我后续的学习有极大帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号