
HashCode 解析
前言
Object提供给我们了一个Native的方法“public native int hashCode();”,本文讲讲Hash是什么以及HashCode的作用
Hash
先用一张图看下什么是Hash
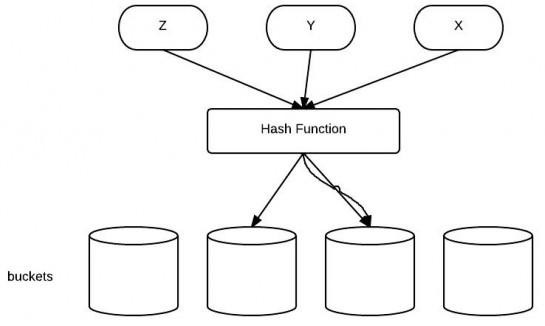
Hash是散列的意思,就是把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。关于散列值,有以下几个关键结论:
1、如果散列表中存在和散列原始输入K相等的记录,那么K必定在f(K)的存储位置上
2、不同关键字经过散列算法变换后可能得到同一个散列地址,这种现象称为碰撞
3、如果两个Hash值不同(前提是同一Hash算法),那么这两个Hash值对应的原始输入必定不同
HashCode
然后讲下什么是HashCode,总结几个关键点:
1、HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的
2、如果两个对象equals相等,那么这两个对象的HashCode一定也相同
3、如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写
4、如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
HashCode有什么用
回到最关键的问题,HashCode有什么用?不妨举个例子:
1、假设内存中有0 1 2 3 4 5 6 7 8这8个位置,如果我有个字段叫做ID,那么我要把这个字段存放在以上8个位置之一,如果不用HashCode而任意存放,那么当查找时就需要到8个位置中去挨个查找
2、使用HashCode则效率会快很多,把ID的HashCode%8,然后把ID存放在取得余数的那个位置,然后每次查找该类的时候都可以通过ID的HashCode%8求余数直接找到存放的位置了
3、如果ID的HashCode%8算出来的位置上本身已经有数据了怎么办?这就取决于算法的实现了,比如ThreadLocal中的做法就是从算出来的位置向后查找第一个为空的位置,放置数据;HashMap的做法就是通过链式结构连起来。反正,只要保证放的时候和取的时候的算法一致就行了。
4、如果ID的HashCode%8相等怎么办(这种对应的是第三点说的链式结构的场景)?这时候就需要定义equals了。先通过HashCode%8来判断类在哪一个位置,再通过equals来在这个位置上寻找需要的类。对比两个类的时候也差不多,先通过HashCode比较,假如HashCode相等再判断equals。如果两个类的HashCode都不相同,那么这两个类必定是不同的。
举个实际的例子Set。我们知道Set里面的元素是不可以重复的,那么如何做到?Set是根据equals()方法来判断两个元素是否相等的。比方说Set里面已经有1000个元素了,那么第1001个元素进来的时候,最多可能调用1000次equals方法,如果equals方法写得复杂,对比的东西特别多,那么效率会大大降低。使用HashCode就不一样了,比方说HashSet,底层是基于HashMap实现的,先通过HashCode取一个模,这样一下子就固定到某个位置了,如果这个位置上没有元素,那么就可以肯定HashSet中必定没有和新添加的元素equals的元素,就可以直接存放了,都不需要比较;如果这个位置上有元素了,逐一比较,比较的时候先比较HashCode,HashCode都不同接下去都不用比了,肯定不一样,HashCode相等,再equals比较,没有相同的元素就存,有相同的元素就不存。如果原来的Set里面有相同的元素,只要HashCode的生成方式定义得好(不重复),不管Set里面原来有多少元素,只需要执行一次的equals就可以了。这样一来,实际调用equals方法的次数大大降低,提高了效率。
为什么重写Object的equals(Object obj)方法尽量要重写Object的hashCode()方法
我们在重写Object的equals(Object obj)方法的时候,应该尽量重写hashCode()方法,这是有原因的,下面详细解释下:
1 public class HashCodeClass 2 { 3 private String str0; 4 private double dou0; 5 private int int0; 6
(obj HashCodeClass hcc = (hcc.str0.equals(.str0) && hcc.dou0 == .dou0 && hcc.int0 == }
System.out.println( System.out.println( System.out.println( System.out.println( System.out.println( System.out.println( }
打印出来的值是:
1901116749 1807500377 355165777 1414159026 1569228633 778966024
我们希望两个HashCodeClass类equals的前提是两个HashCodeClass的str0、dou0、int0分别相等。OK,那么这个类不重写hashCode()方法是有问题的。
现在我的HashCodeClass都没有赋初值,那么这6个HashCodeClass应该是全部equals的。如果以HashSet为例,HashSet内部的HashMap的table本身的大小是16,那么6个HashCode对16取模分别为13、9、1、2、9、8。第一个放入table[13]的位置、第二个放入table[9]的位置、第三个放入table[1]的位置。。。但是明明是全部equals的6个HashCodeClass,怎么能这么做呢?HashSet本身要求的就是equals的对象不重复,现在6个equals的对象在集合中却有5份(因为有两个计算出来的模都是9)。
那么我们该怎么做呢?重写hashCode方法,根据str0、dou0、int0搞一个算法生成一个尽量唯一的hashCode,这样就保证了str0、dou0、int0都相等的两个HashCodeClass它们的HashCode是相等的,这就是重写equals方法必须尽量要重写hashCode方法的原因。看下JDK中的一些类,都有这么做:
Integer的
1 public int hashCode() { 2 return value; 3 } 4 5 public boolean equals(Object obj) { 6 if (obj instanceof Integer) { 7 return value == ((Integer)obj).intValue(); 8 } 9 return false; 10 }
String的
1 public int hashCode() { 2 int h = hash; 3 if (h == 0) { 4 int off = offset; 5 char val[] = value; 6 int len = count; 7
8 for (int i = 0; i < len; i++) { 9 h = 31*h + val[off++]; 10 } 11 hash = h; 12 } 13 return h; 14 } 15
16 public boolean equals(Object anObject) { 17 if (this == anObject) { 18 return true; 19 } 20 if (anObject instanceof String) { 21 String anotherString = (String)anObject; 22 int n = count; 23 if (n == anotherString.count) { 24 char v1[] = value; 25 char v2[] = anotherString.value; 26 int i = offset; 27 int j = anotherString.offset; 28 while (n-- != 0) { 29 if (v1[i++] != v2[j++]) 30 return false; 31 } 32 return true; 33 } 34 } 35 return false; 36 }
HashMap中的实体类Entry
public final int hashCode() { return (key==null ? 0 : key.hashCode()) ^ (value==null ? 0 : value.hashCode()); } public final boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; Object k1 = getKey(); Object k2 = e.getKey(); if (k1 == k2 || (k1 != null && k1.equals(k2))) { Object v1 = getValue(); Object v2 = e.getValue(); if (v1 == v2 || (v1 != null && v1.equals(v2))) return true; } return false; }
ps: HashCode个人理解是一个对象的所在位置的存储地方,而不是实际在内存中的内存地址(所以说两个相同的HashCode不一样顶是同一个对象),HashCode可以人为生成,HashCode是用来解决快速命对象在某一区域的位置的一串根据相应算法生成的code,根据生成code的算法快速命中需要的对象区域,然后使用equals比较真实的对象地址


 浙公网安备 33010602011771号
浙公网安备 33010602011771号