
Self-Attention GAN学习笔记
Motivation
-
以往的模型都严重依赖卷积来建模不同区域之间的依赖关系。然而卷积核的大小是有限的,每次卷积操作只能够覆盖像素点周围很小的一块领域。对于一些距离比较远的特征,要捕获到这些特征,就需要多次卷积,计算效率较低;其次,现有的一些优化算法可能无法发现仔细协调多个层来捕获这些依赖性的参数值,阻碍了学习长期依赖性。(例如最先进的ImageNet GAN,擅长合成一些结构约束很少的图像,例如天空海洋等,但是对一些需要捕捉一致出现的地理度量或者结构模式的图像,就难以合成了。)
Contribution
-
提出Self-Attention与GAN相结合(之前的AttnGAN是在输入序列的处理上使用了Self-Attention,而不是在内部的模型中使用。)能够通过直接计算图像中任意两个像素点之间的关系,一步到位地获取图像的全局几何特征。
-
首次对GAN的生成器运用了spectral normalization,提高了动态训练的稳定性。
Self-Attention module

x:C*N
f(x)、g(x):(c/8)*N
f(x)^T: N*(c/8)
h(x):(c/8)*N
attention map: N*N
把前隐藏层的输入分为两个特征空间,x可以看做是C×N的矩阵,其中C表示通道数,N代表前一层中所得到的的特征位置数量。
分成的两个特征空间为f和g用于计算注意力。
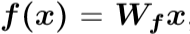
g(x)表达式同上。
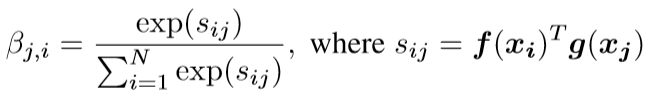
上式表达在合成第j个区域的时候,模型对第i个区域的关注程度(即注意力系数)
注意层的输出:
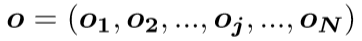
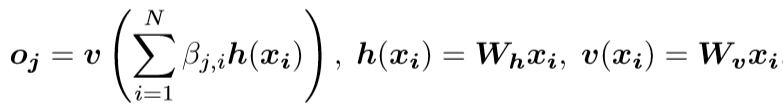
参数说明:Wg,Wf,Wh,Wv都是矩阵,其中前三个矩阵行数为C/8,(为什么除8?把通道数由C减少到C/8对训练的结果并没有显著影响,除8是经过训练之后作者得出的一个比较合适的数,也可以是1,2,4……)
把注意层的输出乘以一个比例参数,并且添加一个输入的future map,最终得到
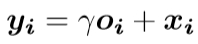
其中γ是可学习的标量,初值设置为0,使得网络受限依赖于本地领域的信息,然后逐渐学会给非本地领域的信息分配更多的权重。
总结:
(1) f(x),g(x),h(x)都是1×1的卷积,差别在于输出通道的大小不同。
(2) 将f(x)的输出进行转置,并且和g(x)的输出相乘,再经过softmax归一化得到一个attention map;
(3) 将得到的attention map和h(x)进行逐像素点相乘,得到自适应的注意力feature maps.
对抗损失运用的是
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #对每个维度的每行进行softmax计算
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # 矩阵相乘
attention = self.softmax(energy) # BX (N) X (N) 按行进行归一化得到attention map
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
"""
总结:
可以把 self attention 看成是 feature map 和它自身的转置相乘,让任意两个位置的像素直接产生关系,这样就可以学习到任意两个像素之间的依赖关系,从而得到全局特征。
"""
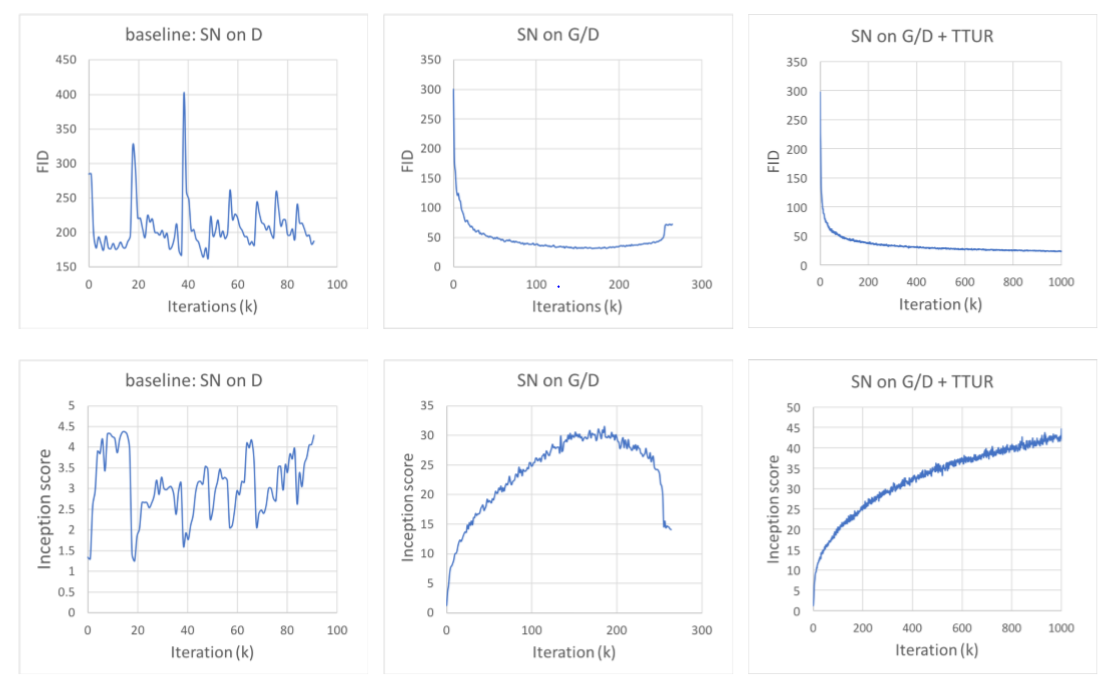
Some tricks to stabilize the training of GANs
-
Spectral Normalization
什么是谱归一化?
让每层网络的网络参数除以该层参数矩阵的谱范数满足Lipschitz=1的约束,求得每层参数矩阵的谱范数,求得谱范数后,每个参数矩阵上的参数皆除以它,以达到归一化目的。与其他归一化技巧相比,谱归一化不需要其他超参数。另外一点就是它的计算代价相对比较少。
作者认为,对生成器使用谱归一化也能够提高GANs的性能,可以防止参数幅度的上升,避免异常的梯度。
-
Imbalanced Learning Rate
GAN的训练都存在这个问题,容易模式崩塌。D能够很好地判别真假,训练的很快。而G的生成效果训练远远落后于D.(D训练的快能够过早的判别真伪,之后G生成的图片与真的差距越来越大。)所以传统的判别器正则化也是为了使D训练的慢一点。
因为之前的给判别器加正则项,整体减速了训练GAN的过程。D要更新许多次,G才能更新一次。为了解决这个问题,作者提出TTUR,对判别器和生成器采用不同的学习速率,作为判别器正则化学习慢的补偿。使得让D用更少的更新次数,G更新一次,成为相对更稳定的训练过程,努力使D的学习和G的学习同步。
How about the result?
Evaluation metrics
-
Incepetion score
用于计算条件类分布和边际类分布的KL散度,初始分数越高,图像质量越好。
-
Frechet Inception distance
更加完善的评价方式,评估生成样本的真实性的变化方面与人类评估一致。除了计算特征空间中生成图像和真实图像的Wasserstein-2距离,还计算整个数据分布和真实数据分布之间的距离。
Implement details
图像设计成128*128,使用Adam optimizer,鉴别器学习率设置为0.0004,生成器学习率设置为0.0001。
Evaluating the proposed stabilization techniques

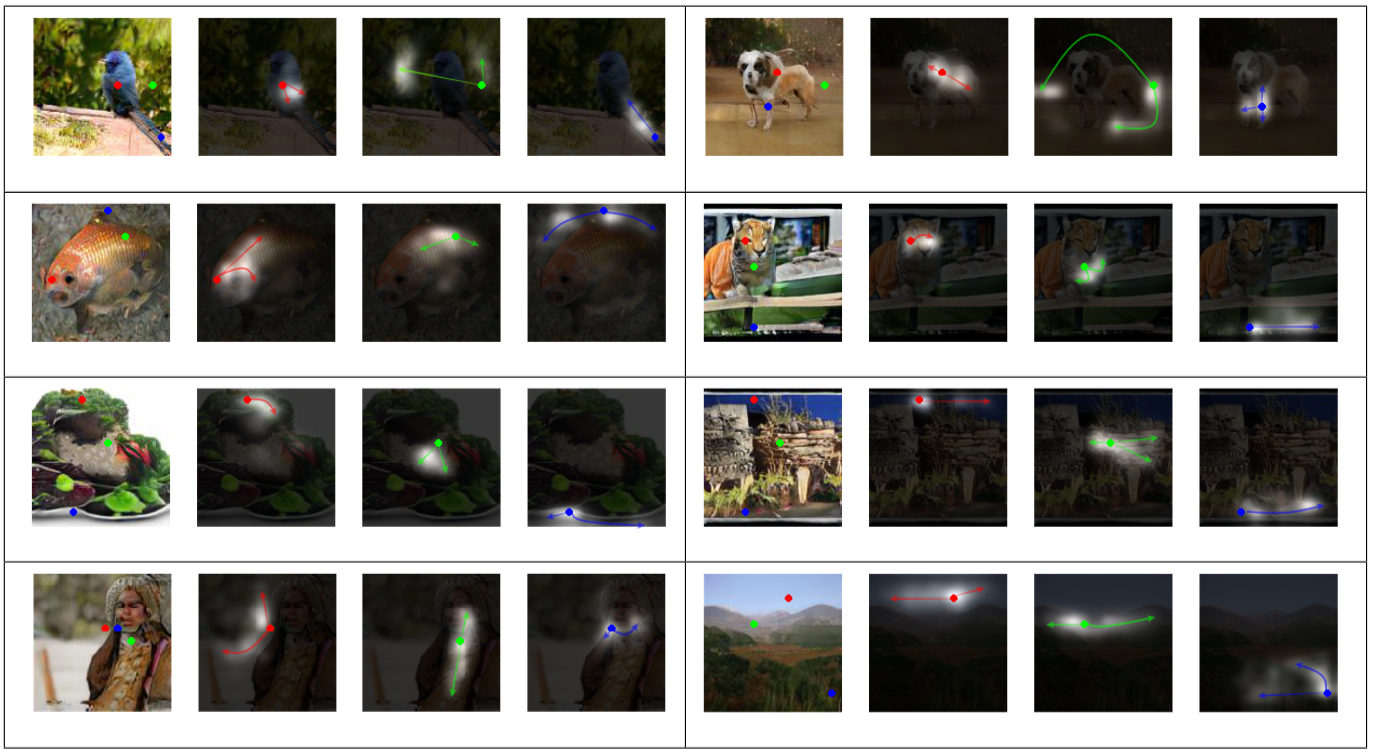
Evaluating the self-attention module

Compared to the state of art


Inspiration
引入Self-Attention是为了更加关注局部区域与全局之间的依赖关系,虽然本文是用于图像合成,但是在一些图像分割任务中,区域之间的分割也需要考虑到它们的依赖关系,尤其是在一些具有多样特征的分割任务,如何在尽可能保留所需分割区域的同时不破坏到区域之间潜在的联系是一个挑战。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号