
过拟合问题及其解决方法
方差(Variance):Variance的对象是多个模型,是相同分布的不同数据集训练出模型的输出值之间的差异。它刻画的是数据扰动对模型的影响。方差描述的是训练数据在不同迭代阶段的训练模型中,预测值变化的波动情况(或称为离散情况)。在数学的角度上,表示为:每个预测值与预测均值之差的平方和再求平均数。
偏差(Bias):Bias的对象是单个模型,是期望输出与真实标记的差别。它描述了模型对本训练集的拟合程度。偏差衡量模型的预测值与实际值之间的偏离关系。预测值与实际值的匹配度越强,偏差越小,反之偏差越大。
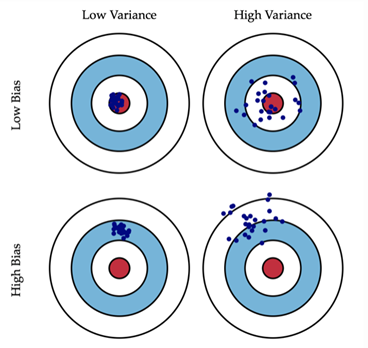
低偏差,低方差:这是训练的理想模型,蓝色点集基本落在靶心区域,数据离散程度小。
低偏差,高方差:深度学习面临的最大问题,也就是过拟合问题。模型太贴合训练数据,泛化能力弱,若遇到测试集,准确度下降地厉害。
高偏差,低方差:训练的初始阶段。
高偏差,高方差:训练最糟糕的情况。
数学定义:
我们从简单的回归模型来入手,对于训练数据集S = {(xi , yi)},令yi = f(xi) + ε,假设为实际方程,其中ε是满足正态分布均值为0,标准差为σ的值。
我们再假设预测方程为h(x) = wx + b,这时我们希望总误差
E (x) = ∑i [yi - h(xi)]2
能达到最小值。给定某集合样本(x, y),我们可以展开误差公式,以生成用方差、偏差和噪音组合的方式。
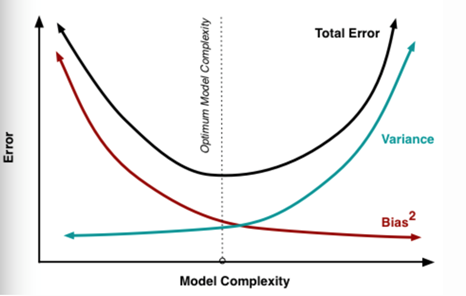
由上图可知,函数模型越来越复杂,会造成方差的变大,偏差会减少。
?为何训练初始阶段是低方差,训练后期易是高方差?
从方差的数学公式出发。
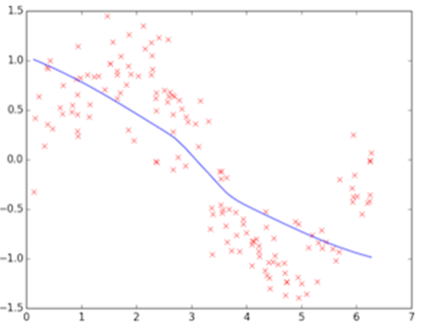
上图为训练初始阶段,我们的模型(蓝线)对训练数据(红点)拟合度很差,是高偏差,但蓝线近似线性组合,其波动变化小,套用数学公式也可知数值较小,故为低方差,这个阶段也称之为欠拟合(underfitting),需要加大训练迭代数。
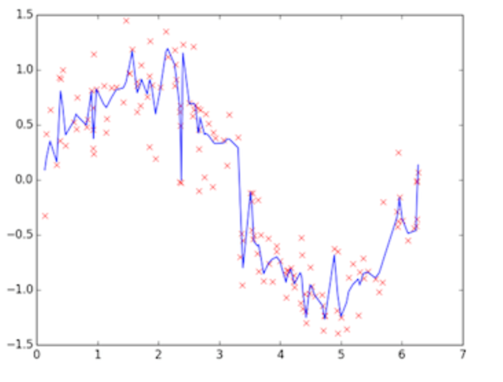
上图为训练的后期阶段,可明显看出模型的拟合度很好,是低偏差,但蓝线的波动性非常大,为高方差,这个阶段称之为过拟合(overfitting),问题很明显,蓝线模型很适合这套训练数据,但如果用测试数据来检验模型,就会发现泛化能力差,准确度下降。
再来看一个例子:
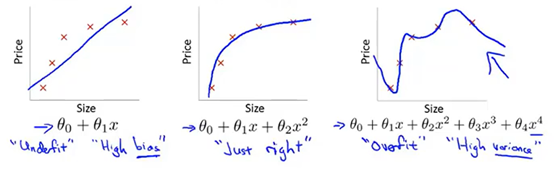
由以上可得:
过拟合将会在变量过多的时候出现,这个时候的训练出来的假设函数虽然能够很好地拟合训练集,但得到的曲线波动非常明显,由于它千方百计地拟合训练集,导致它无法很好地泛化在新的样本数据中。
解决过拟合问题的一些方法:
数据集扩增:
由于过拟合时往往是针对非常少量的Training Data进行训练的,得到的函数模型虽然能够很好的拟合,但是泛化能力非常差,增大训练数据集,能够适当的提高函数模型的泛化能力。
但是在扩增数据集的时候,我们需要得到符合要求的数据,即和已有的训练集数据时同分布的,或者是近似独立同分布,这样一来,就可以采用以下方法扩增数据集。
1.从数据源头采集更多数据。
2.复制原有数据并加上随机噪声。
3.重采样。
4.根据当前数据集估计数据分布,使用该分布产生更多数据。
Early Stopping(早停法)
所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合:当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差。使用Early Stopping的方法,就可以通过在模型训练的整个过程中截取保存结果最优的参数模型,防止过拟合。
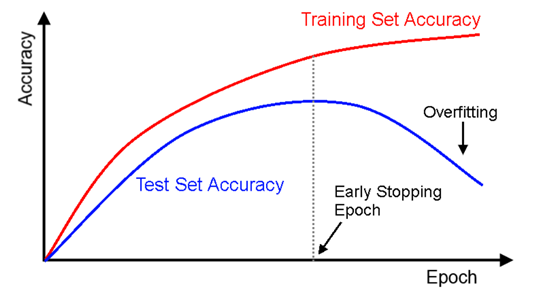
Epoch:1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被完整遍历的次数。
Earlystopping的工作原理:
·将数据分为训练集和验证集
·每个epoch结束后,在验证集上获取测试结果,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练。
·将停止之后的权重作为网络的最终参数。
怎样才能认为验证集精度不能再提高呢?
—>并不是说验证集的精度一下降就认为精度不能再提高了,而是通过一定的epoch之后,验证集精度连续降低,在这个时候我们才能认为验证集的精度不能在提高。一般在训练过程中,10次epoch后没有达到最佳精度,就实施截取。
正则化
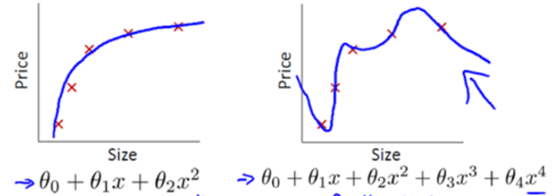
从上图中我们可以得知,右图的函数实际上是过拟合的,泛化能力不好。但是如果在函数中加入惩罚项,使得参数θ3和θ4的值非常小(接近0),得到的函数其实是类似于二次函数的。
参数值小意味着这个函数模型的复杂程度越小,得到的函数就越平滑越简单,越不容易出现过拟合问题。
正则化方法是指在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。采用正则化方法会自动削弱不重要的特征变量,自动从许多的特征变量中‘提取’重要的特征变量,减小特征变量的数量级。
但在实际中,我们不知道哪些参数对整个函数模型的作用最小。
因此我们修改了代价函数。
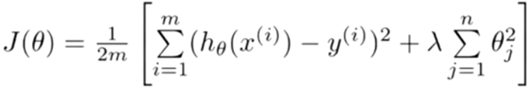
λ这个正则化参数需要控制的是这两者之间的平衡,即平衡拟合训练的目标和保持参数值较小的目标。从而来保持假设的形式相对简单,来避免过度的拟合。
我们没有去惩罚 θ0,因此 θ0 的值是大的。这就是一个约定从 1 到 n 的求和,而不是从 0 到 n 的求和。无论你是否包括这 θ0 这项,在实践中这只会有非常小的差异。但是按照惯例,通常情况下我们还是只从 θ1 到 θn 进行正则化。
那么如何使得θ3和θ4尽可能地接近0呢?那就是对参数施加惩罚项。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号