python--正则表达式
匹配所有符合规则的IP地址:
正则表达式为:(([01]?\d?\d|2[04]\d|25[0-5])\.){3}([01]?\d?\d|2[04]\d|25[0-5])
黄色匹配是:0-199 == [01]?\d?\d
绿色匹配是:200-249 == 2[04]\d
蓝色匹配是:250-255 == 25[0-5]
红色匹配的是:. 点号 == \.
{3} 是匹配前面的三次
举例:匹配"192." 三次 == 192.192.192.
紫色是 和前面的一样,只不过只匹配数字,不包含点号。
举例:匹配“192” 一次 == 192
"""
# 字符匹配(普通字符,元字符)
普通字符:大多数字符和字母都会和自身匹配
2、元字符:. ^ $ * + ? { } [] | () \
. : 代表除了换行符以外的任意一个字符,只能匹配一个
^ : 代表以什么开头,^abc 必须以abc开头才能匹配
$ : 代表以什么结尾,^abc 必须以abc结尾才能匹配
* + ? {} :在做一个事情就是重复
* : 匹配 0 到多次前面的字符。(默认是贪婪模式) {0,}
+ : 匹配 1 到多次前面的字符。(默认是贪婪模式) {1,}
? : 匹配 0 到 1 次前面的字符 。 {0,1}
{} : 匹配前面字符固定次数{}
c{3}: 匹配c3次
c{3,5}: 闭区间,(两个边上的结果都能起作用)匹配3到5次
[] : 字符集, 或者的意思 ,元字符在字符集里面失去特殊意义。
注:有几个特殊的还会保持意义" - " , "\"
re.findall('a[bc]d','wwwabd') -> [abd]
re.findall('a[bc]d','wwwabc') -> [abc]
' - ' 在 [] 中是连续或者是区间的意思
re.findall('[a-z]','wwwa.d') -> ['w', 'w', 'w', 'a', 'd']
re.findall('[0-9]','www3wa0i8.d') -> ['3', '0', '9']
' ^ ' 在[] 是取反的意思,是非的意思。
re.findall('[^0-9]','www3wa0i8.d') -> ['w', 'w', 'w', 'w', 'a', 'i', '.', 'd'] # 除了0-9 的数字都取出来了
| :
() : 作为一个组,就是一个整体,把一个整体当做一个概念去处理
\ : 1、反斜杠后边跟元字符则去除特殊功能,
2、反斜杠后面很普通字符实现特殊功能。
3、引用序列号对应的组所匹配的字符串
print(re.search(r'(alex)(eric)com\2\1',"alexericcomericalex").group())
注: 以下都是默认是匹配一个:如果想要匹配多个,必须要加上+ 或者 *
\d :匹配任何十进制数; 它类似于[0-9]
\D :匹配任何非数字字符; 它类似于[^0-9]
\s :匹配任何空白字符;它类似于[\t\n\r\f\v]
\S :匹配非任何空白字符;它类似于[^t\n\r\f\v]
\w :匹配任何字母数字字符和下划线;它类似于[a-zA-z0-9_]
\W :匹配非任何字母数字字符和下划线;它类似于[^a-zA-z0-9_]
\b :匹配一个单词边界,也就是指单词和空格间的位置。
re.findall() # 完全对应的,匹配所有的 ,注:如果存在()组,则拿的是组里的内容
re.search() # 是找到一个就ok了,剩下的不去找了
re.match() # 是指在开头去寻找,只去匹配开头的内容
"""
* :匹配 0 到多次。
下图指的是:匹配0次x或者是多次x
默认是贪婪匹配

+ :匹配 1 到 多次,最少有一个。
如下图第二条就匹配不出来了。





# 贪婪模式 与 非贪婪模式
# + = {1,} + 号就是 1到无限
# ? = {0,1} ? 号就是 0,1
# * = {0,} * 号就是 0到无限
# 注:加上?后,就指的是非贪婪模式,修饰前面的元字符 < + * ?>使其匹配最少的。
# 特殊情况:当两边都有限定的时候就不会区分贪婪和非贪婪模式了。如'a(\d+?)b' 这里的 a和 b就相当于限定条件
# print(re.search('a(\d+?)', "a23444bvv").group()) # a2
# print(re.search('a(\d+?)b', "a23444bvv").group()) # a23444b
print("-----> +")
print(re.search('a(\d+)', "a23444bvv").group()) # a23444
print(re.search('a(\d{1,})', "a23444bvv").group()) # a23444
print(re.search('a(\d+?)', "a23444bvv").group()) # a2
print(re.search('a(\d+?)b', "a23444bvv").group()) # a23444b
print("-----> ?")
print(re.search('a(\d?)', "a23444bvv").group()) # a2
print(re.search('a(\d{0,1})', "a23444bvv").group()) # a2
print(re.search('a(\d{0,1}?)', "a23444bvv").group()) # a
print(re.search('a(\d??)b', "a2bvv").group()) # a2b
print("----> *")
print(re.search('a(\d*)', "a23444bvv").group()) # a23444
print(re.search('a(\d{0,})', "a23444bvv").group()) # a23444
print(re.search('a(\d*?)', "a23444bvv").group()) # a
print(re.search('a(\d*?)b', "a23444bvv").group()) # a23444b
# 分组匹配
print(re.search(r'(alex)(eric)com\2\1',"alexericcomericalex").group()) # alexericcomericalex
# 此中的 \2 代表的是第二个括号里的内容, \1 代表第一个括号里的内容


修饰符描述
re.I使匹配对大小写不敏感
re.L做本地化识别(locale-aware)匹配
re.M多行匹配,影响 ^ 和 $
re.S使 . 匹配包括换行在内的所有字符
re.U根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。






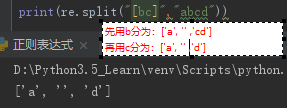


r:表示原生字符串,在python中就没有特殊意义了

我的目标是每天厉害一点点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号