
使用kafka集群配置的原因也很简单,为orderer共识及排序服务提供足够的容错空间,当我们向peer节点提交Transaction的时候,peer节点会得到或返回(基于SDK)一个读写集结果,该结果会发送给orderer节点进行共识和排序,此时如果orderer节点突然down掉,致使请求服务失效而引发的数据丢失等问题,且目前的sdk对orderer发送的Transaction的回调会占用极长的时间,当大批量数据导入的时候该回调可认为不可用。
固此,在部署生产环境时,需要对orderer进行容错处理,而所谓的容错即搭建一个orderer节点集群,该集群会依赖于kafka和zookeeper。
一、排序服务原理(Order采用kafka共识引擎)
排序服务的基本工作原理是这样的:
1) 排序服务Client向OSN发送交易;
2) OSN节点对交易进行相关检查,符合条件之后会将交易发送给Kafka集群;
3) OSN节点从Kafka集群拉取交易消息并对交易消息进行打包将打包之后的交易batch写入本地数据库;
4) OSN节点按客户端Deliver请求从本地数据库读取区块返回;
这种设计主要利用了Kafka的两个特性(如下图所示),
1. 发送到Kafka的消息会按序存储并且保证消费者能够按序消费;
2. Kafka允许对消息进行分类按照消息的Topic进行分区,分区内部消息依然有序;
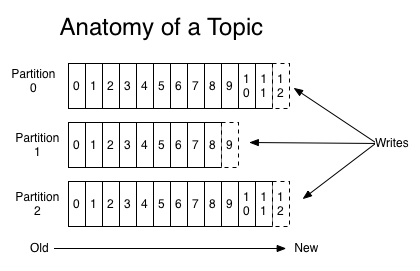
图2. Kafka分区排序
其中特性1帮助Fabric实现了多节点交易的顺序一致性,特性2帮助Fabric实现了多通道架构(Kafka的消费者可以选择订阅其感兴趣的Topic);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号