Valse2019笔记——弱监督视觉理解
程明明(南开大学):面向开放环境的自适应视觉感知

(图片来自valse2019程明明老师ppt)
-
面向识别与理解的神经网络共性技术
-
深度神经网络通用架构 —— VggNet(ICLR’15)、ResNet(CVPR‘16)、DenseNet(CVPR’17)、DLA(CVPR‘18)、Res2Net()富尺度空间的深度神经网络通用架构
-
富尺度空间的深度神经网络通用架构
网络结构:
应用:检测任务、分类任务、分割任务
-
-
通用视觉基元属性感知
-
显著性物体检测技术
A Simple Pooling-Based Design for Real-Time Salient Object Detection;
Contrast Prior and Fluid Pyramid Integration for RGBD Salient Object Detection(RGBD显著性物体检测) 难点:深度图质量、多模态融合机制,利用对比度先验;
S4Net: Single Stage Salient-Instance Segmentation(显著性Instance检测)。
-
边缘检测技术
-
-
关键机器学习算法到多种行业应用
-
面向行业开放应用场景,而非传统实验环境下的高可靠、高通用性基础算法。
-
相关论文
Self-Erasing Network for Integral Object Attention](http://mmcheng.net/SeeNet)(视觉注意机制与弱监督语义分割);
Deeply supervised salient object detection with short connections(基元属性和互联网大数据的自主学习);
Associating Inter-Image Salient Instances for Weakly Supervised Semantic Segmentation(面向普适应用的关键机器学习方法);
Sketch2Photo: Internet Image Montage(利用互联网大数据的自主学习)
-
-
总结
- 通过引入层内分层递进残差链接,实现富尺度空间的深度神经网络通用架构,并通过多任务协同求解提高鲁棒性;
- 通过预先构建显著性物体检测、边缘提取等任务类别无关的基元属性感知能力,减少具体任务中的数据依赖,实现“举一反三”;
- 利用互联网海量多媒体数据,减少对人工标注数据的依赖,自主地学习目标类别的识别与检测模型,实现系统智能的自主发育。
叶齐祥(中国科学院大学):从弱监督到自学习视觉目标建模 —— weakly supervised object detection, localization, and instance segmentation
-
引子
-
存在问题:
有监督的目标检测和实例分割的主要流程
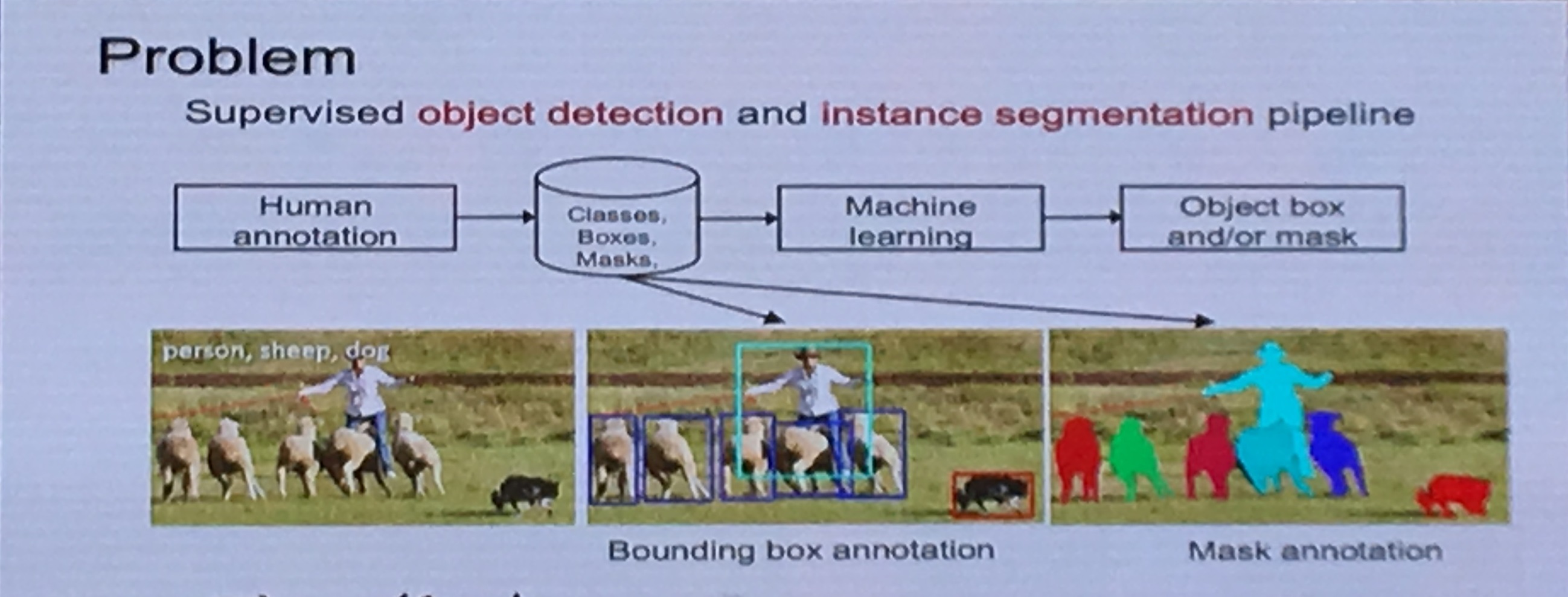
(图片来自valse2019叶齐祥老师ppt)
从上图看出,数据集的制作需要对大量数据从不同方面进行标注。
-
解决方法
如何实现 “ 图像数据库 → 训练数据集 ”?
-
人工标注:耗时耗力
-
弱监督的数据标注 → 弱监督学习:高效低耗

-
-
-
弱监督学习
-
相关论文:
CVPR18: Min-entropy Latent Model (MELM)
PAMI2019: Recurrent Learning(MELM+RecurrentLearning)
CVPR19: Continuation Multiple Instance Learning(CMIL)
ICCV17: Soft Proposal Network(SPN)CVPR18:PeakResponseMapping(PRM)
CVPR19:InstanceActivationMap(IAM)
-
论文详解
问题提出:隐变量学习、多实例学习
往往无法学习到全局最优结果解决方法:
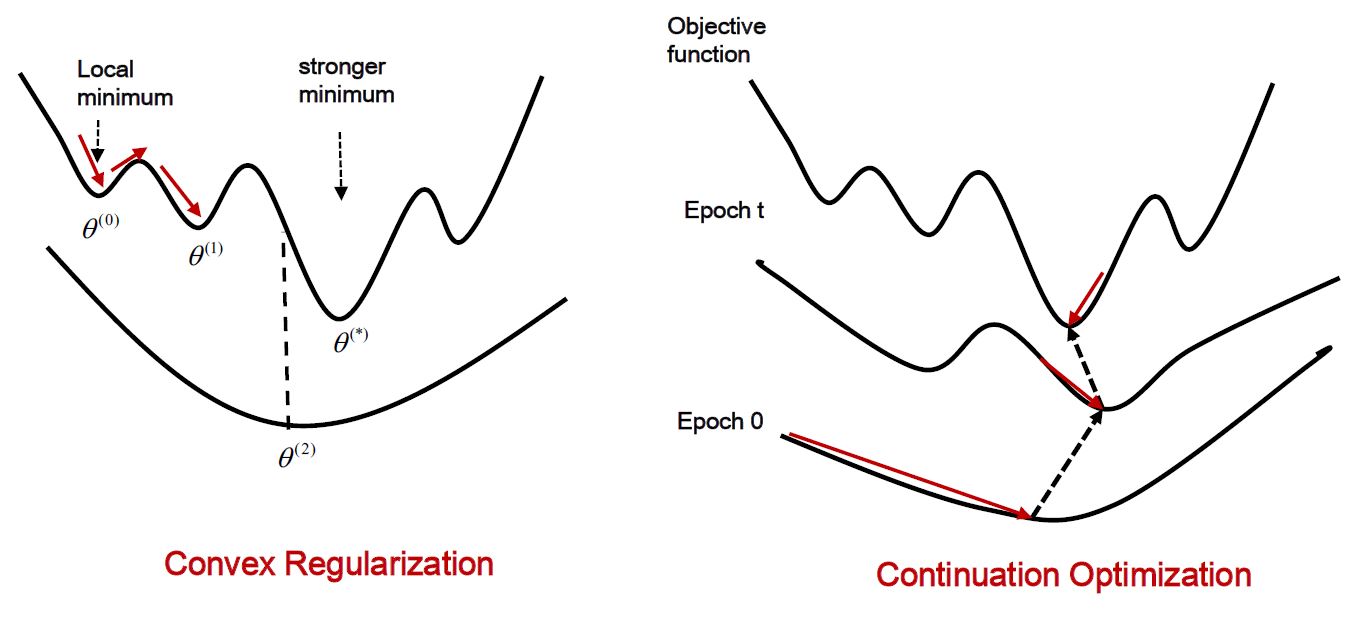
如上图所示,针对无法得到全局最优问题,提出了convex regularization和continuation optimization两种方法。
- convex regularization(Min-entropy Latent Model for Weakly Supervised object Detection CVPR2018)
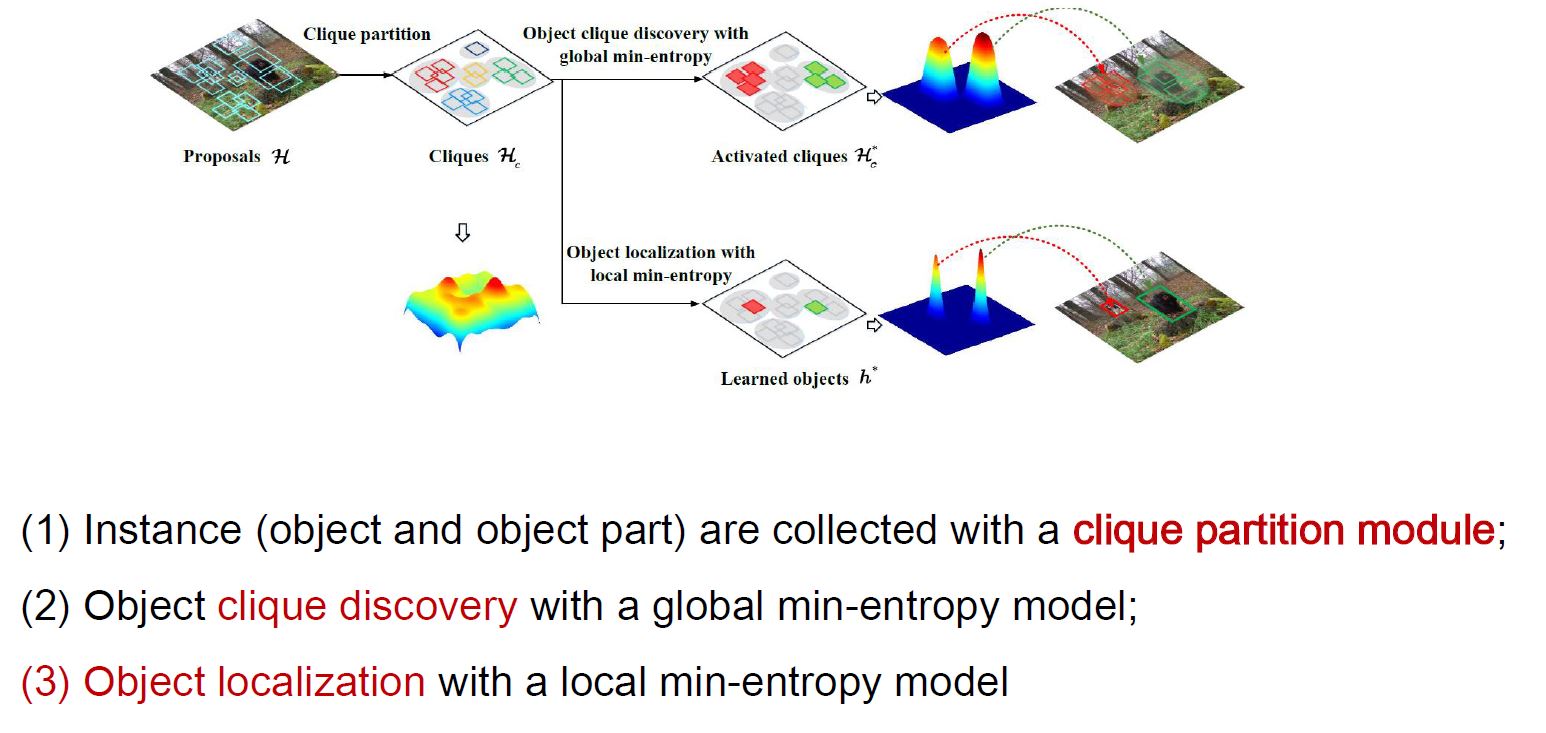
- continuation optimization(CMIL: Continuation Multiple Instance Learningfor Weakly Supervised object Detection CVPR2019)
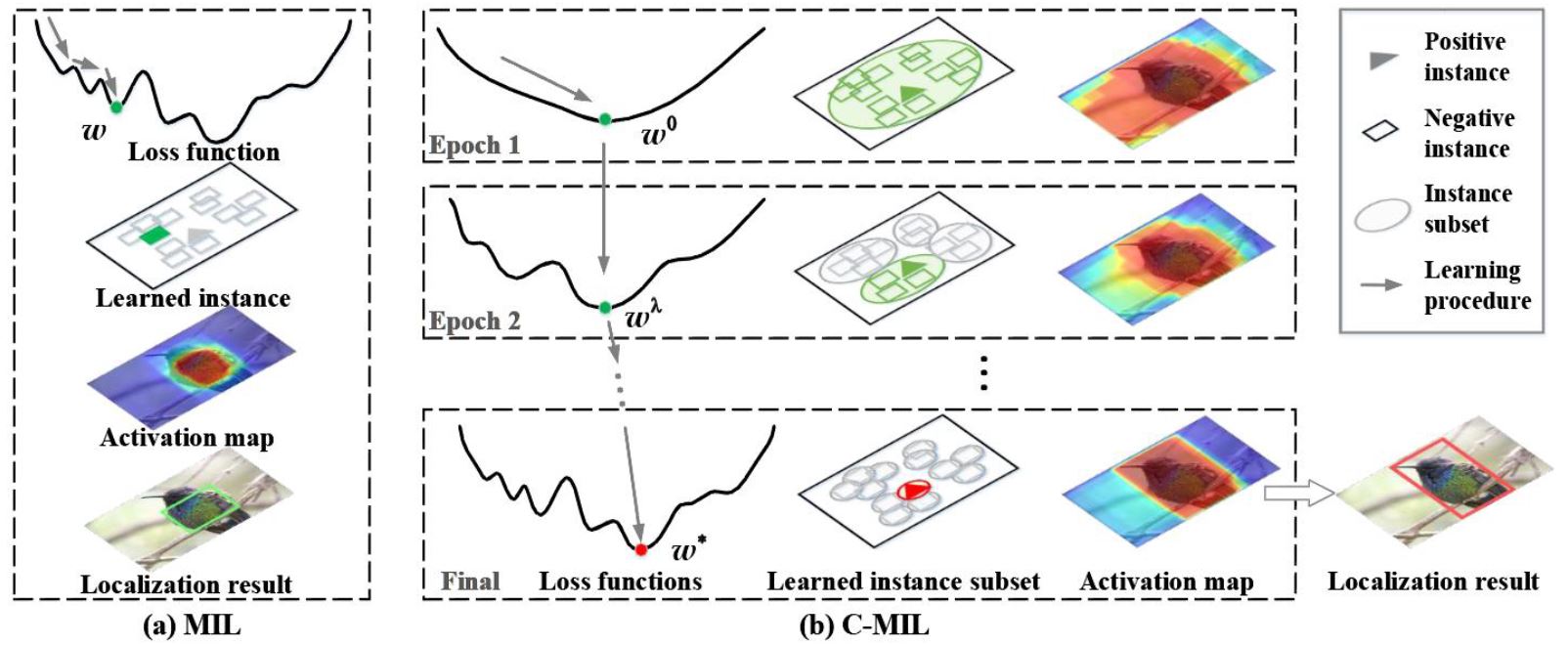
- Recurrent Learning(Min-entropy Latent Model for Weakly Supervised object Detection PAMI2019)
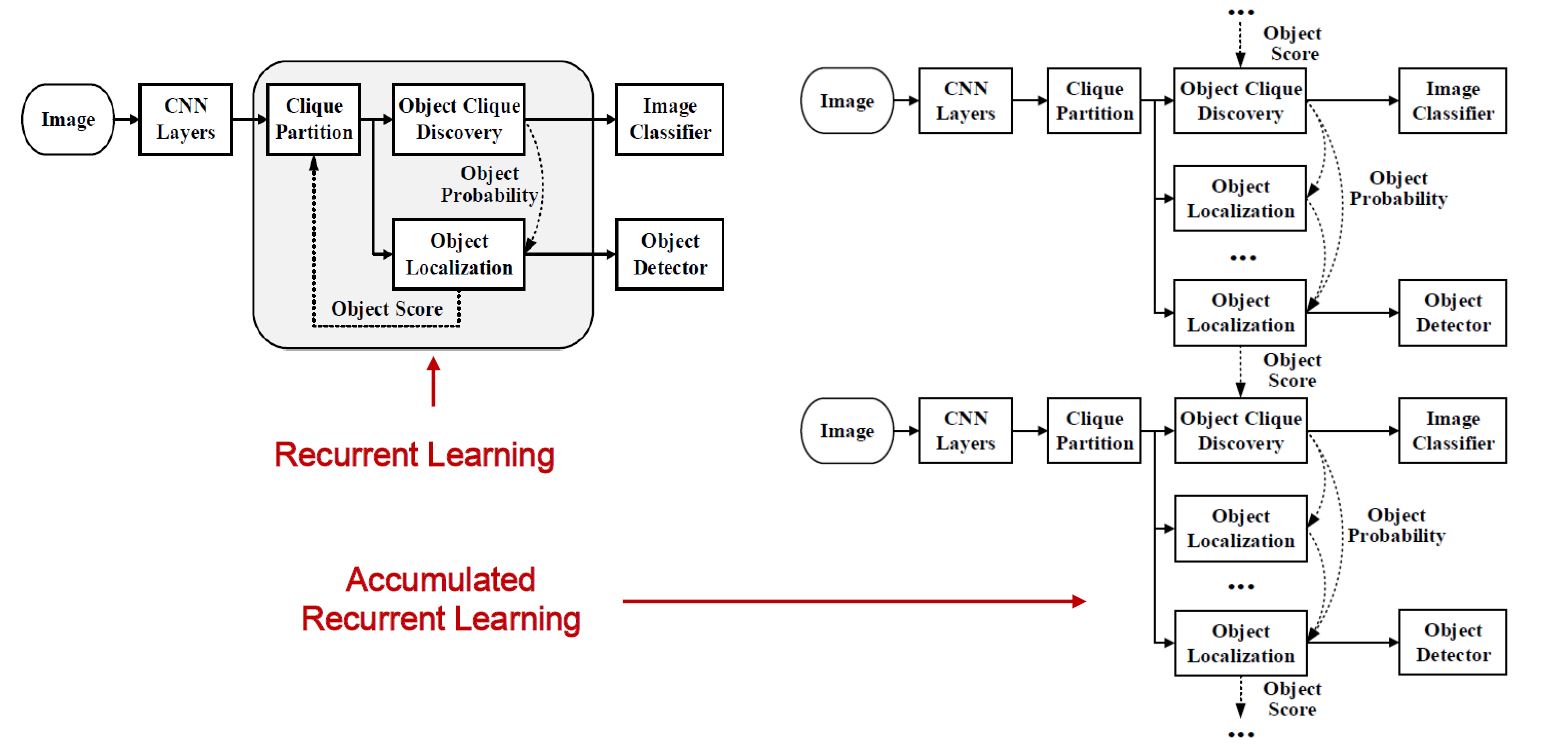
- soft proposal network(Soft Proposal Network for Weakly Supervised Object Localization ICCV2017)

- Peak Response Mapping(Weakly Supervised Instance Segmentation using Class Peak Response CVPR2018)
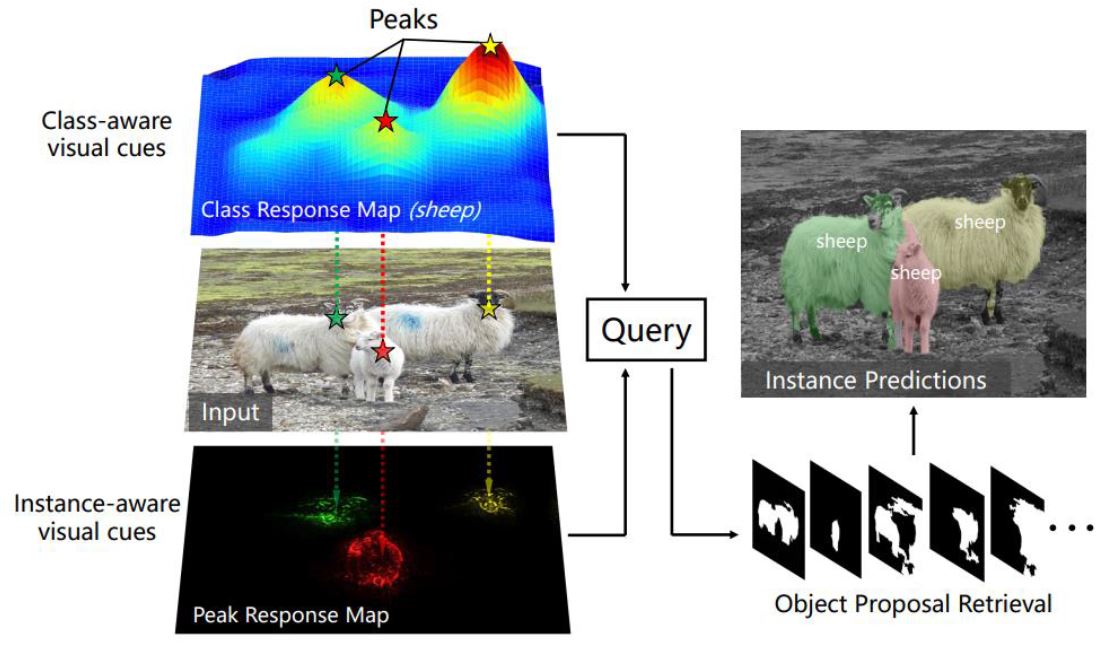
- learning Instance Activation Maps(Learning Instance Activation Maps for Weakly Supervised Instance Segmentation CVPR2019)
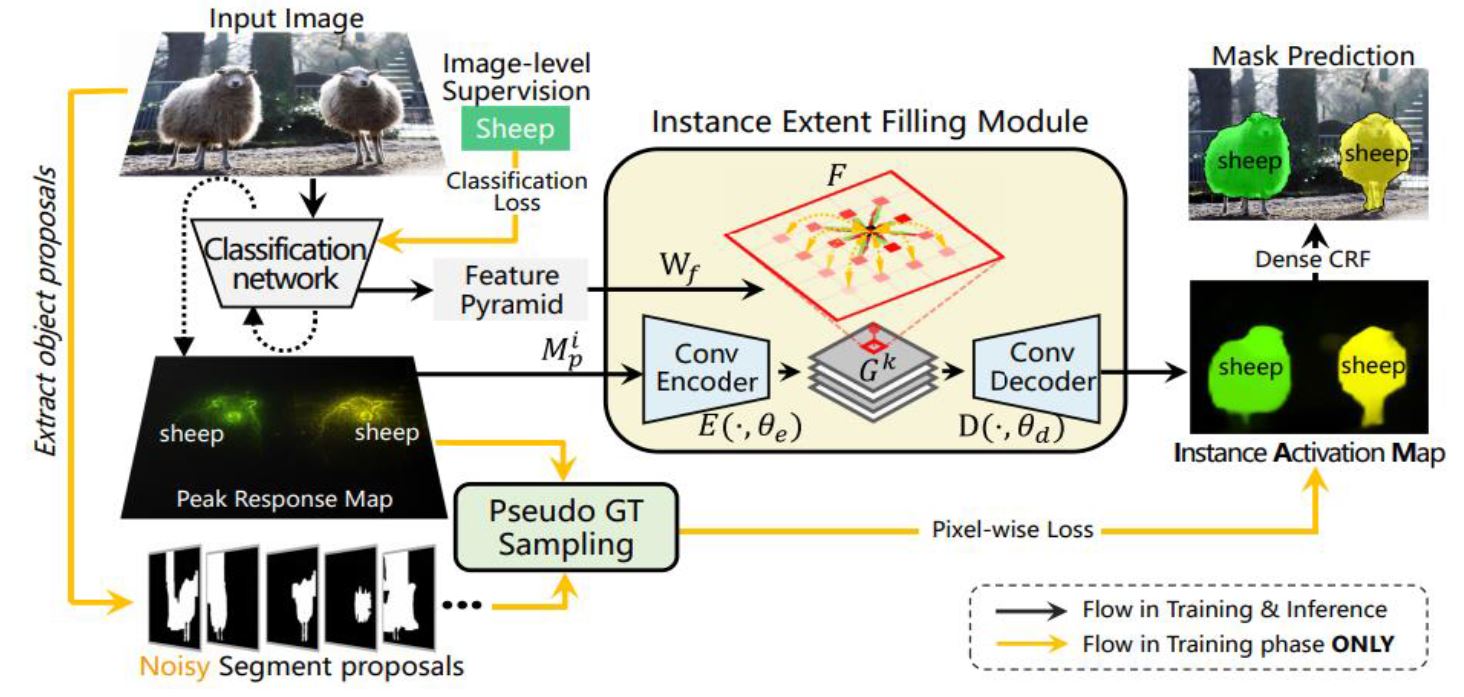
-
未来发展方向:
- Beyond regularization and continuation optimization
- Beyond weakly supervised detection and segmentation
- Fill the gap of supervised and weakly supervised methods
- Weakly supervised detection meets X (Self-learning Scene-specific Pedestrian Detectors using a Progressive Latent Model)
X= Few-shot Active Learning | Online Feedback | Temporal
-
魏秀参(旷视科技):Weakly-supervised object discovery based on pre-trained deep CNNs
-
引子
Deep learning三驾马车
许多可用的预训练好的深度学习模型
深度学习模型的训练还需要大量标记的数据
-
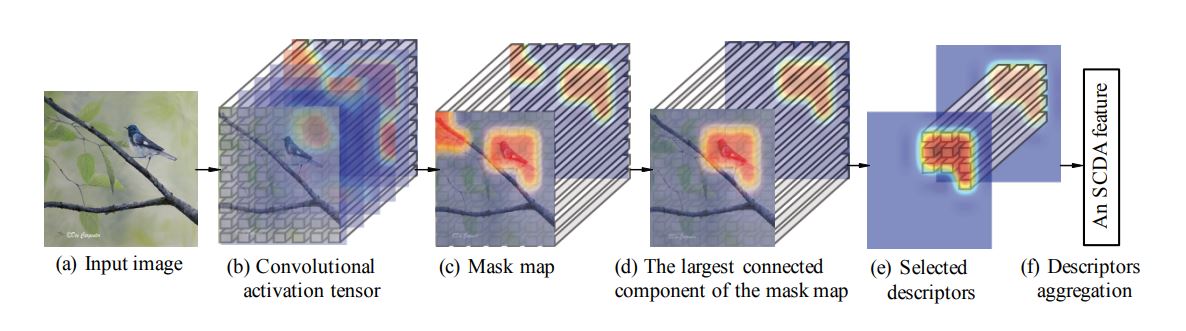
图像检索(Image Retrieval)
一般图像检索流程:

(图片来自valse2019魏秀参老师ppt)
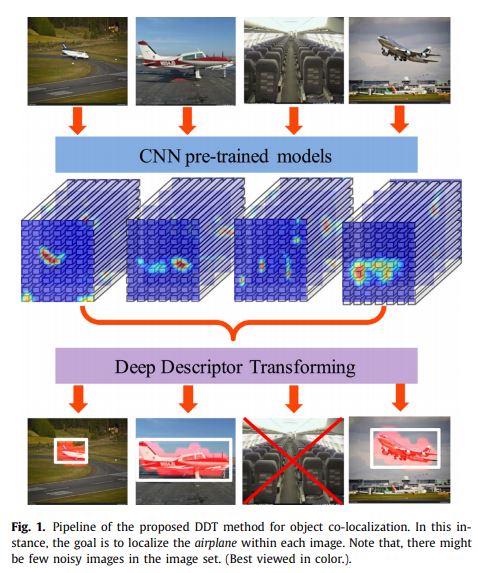
黄圣君(南京航空航天大学):Cost-Sensitive Active Learning
-
引子
- 一个传统的有监督学习
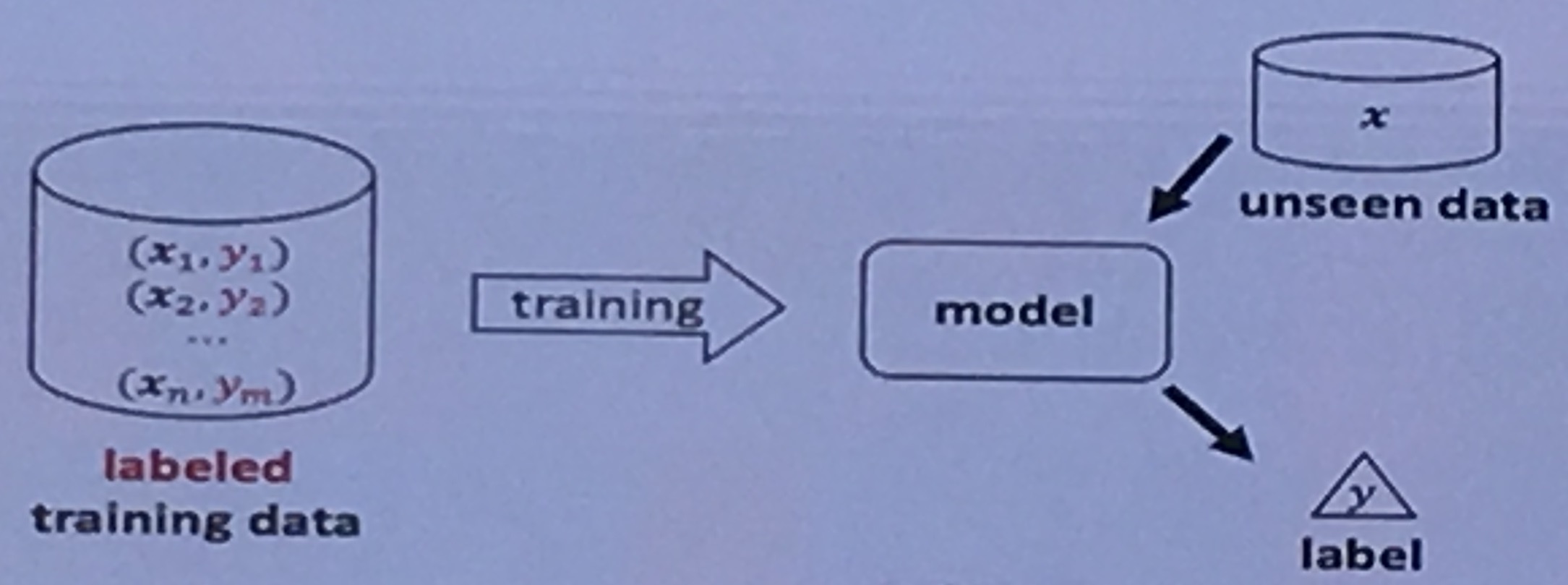
- 有标签的数据非常重要
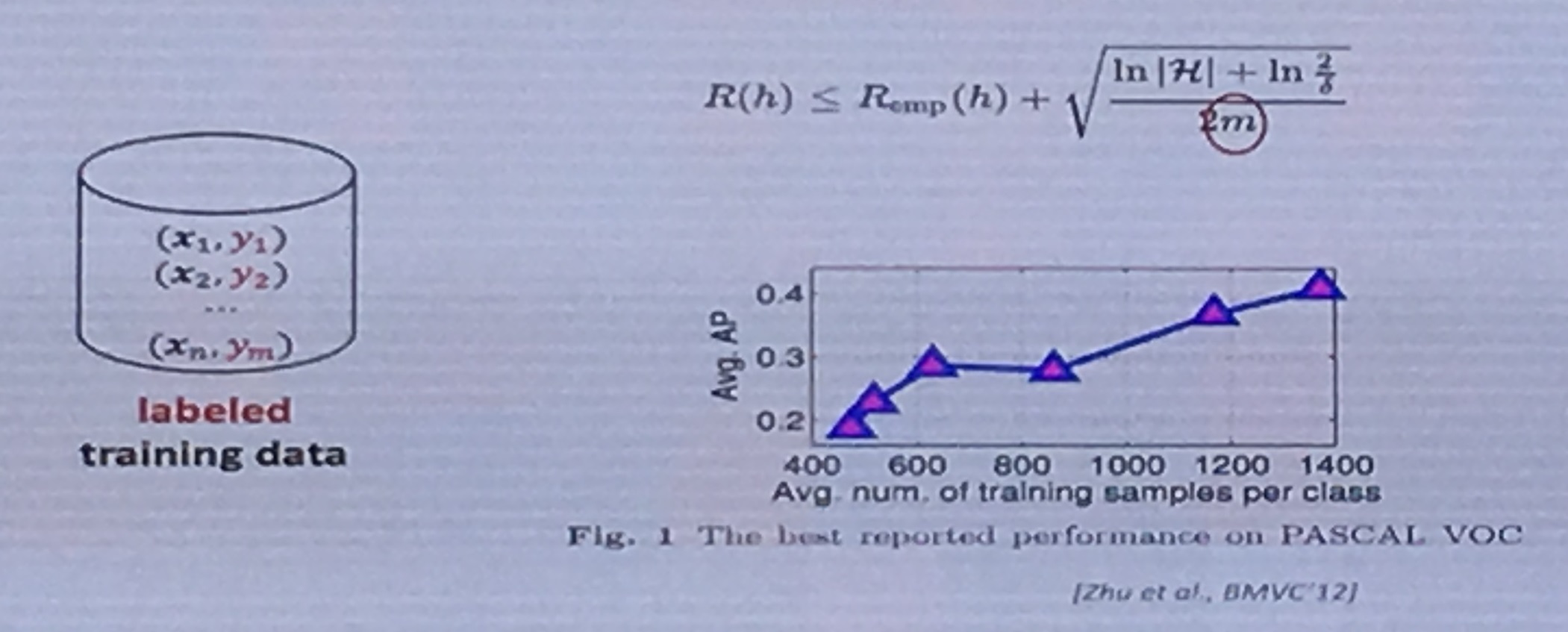
当m越大,表示估计的模型越接近真实模型。
- 有标签的数据非常稀少
- 有标签的数据非常昂贵:耗时、专业知识人才、耗资
-
Active Learning —— 可以用更少的标注数据进行学习
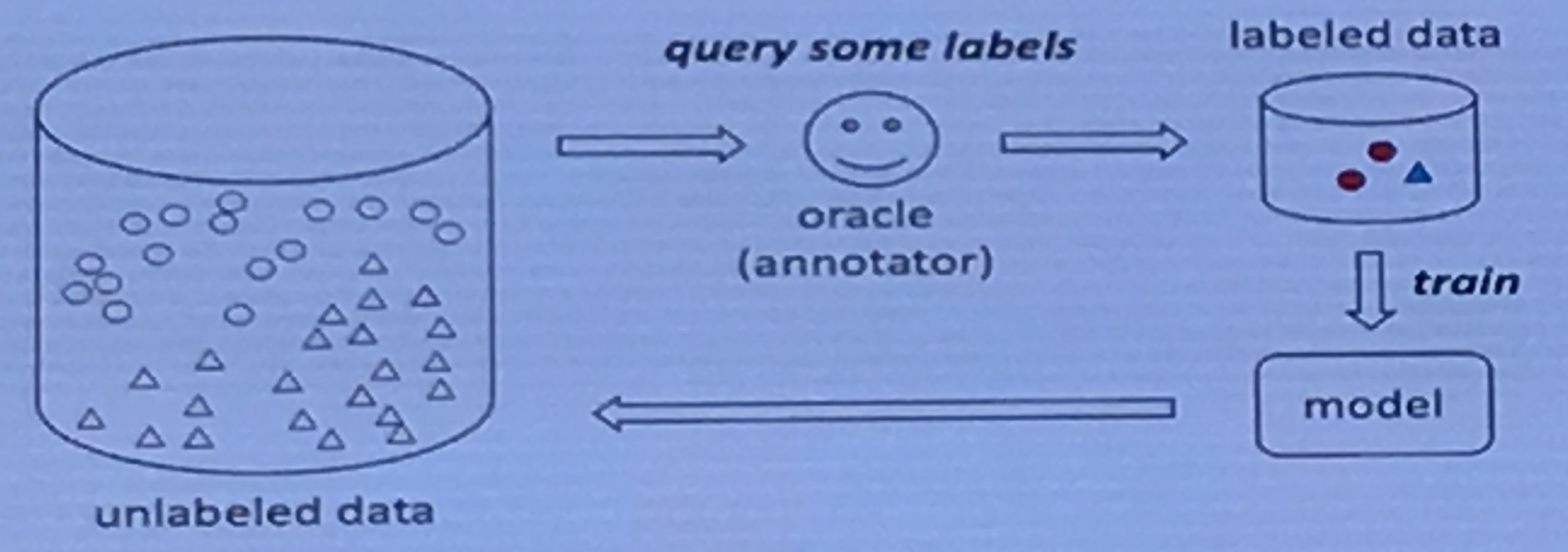
-
Cost Sensitive Active Learning
标记代价 ≠ 查询数量 (查询次数越多不代表所查的东西代价越大)
影响标记代价因素:实例——用于视频推荐的多视角主动学习(instances ——multi-view active learning for video recommendation)
特征——有监督矩阵补全的主动特征获取(features——active feature acquisition with supervised matrix completion) 标签——主动查询分层多标签学习(labels——active querying for hierarchical multi-label learning) oracles- 积极学习各种不完美的oracles(Oracles——active learning from diverse and imperfect oracles)
-
-
影响标记代价因素详细介绍
-
instances ——multi-view active learning for video recommendation
视频推荐:协同过滤(冷门启动问题)/基于内容的过滤(需要大量数据训练)
多视角视频表示:视觉特征、文本特征、用户特征、标签
motivation:在视频推荐任务中,文本特征(即评论)获取需要很大代价,视觉特征不需要人力代价。
idea: Visual to text Mapping
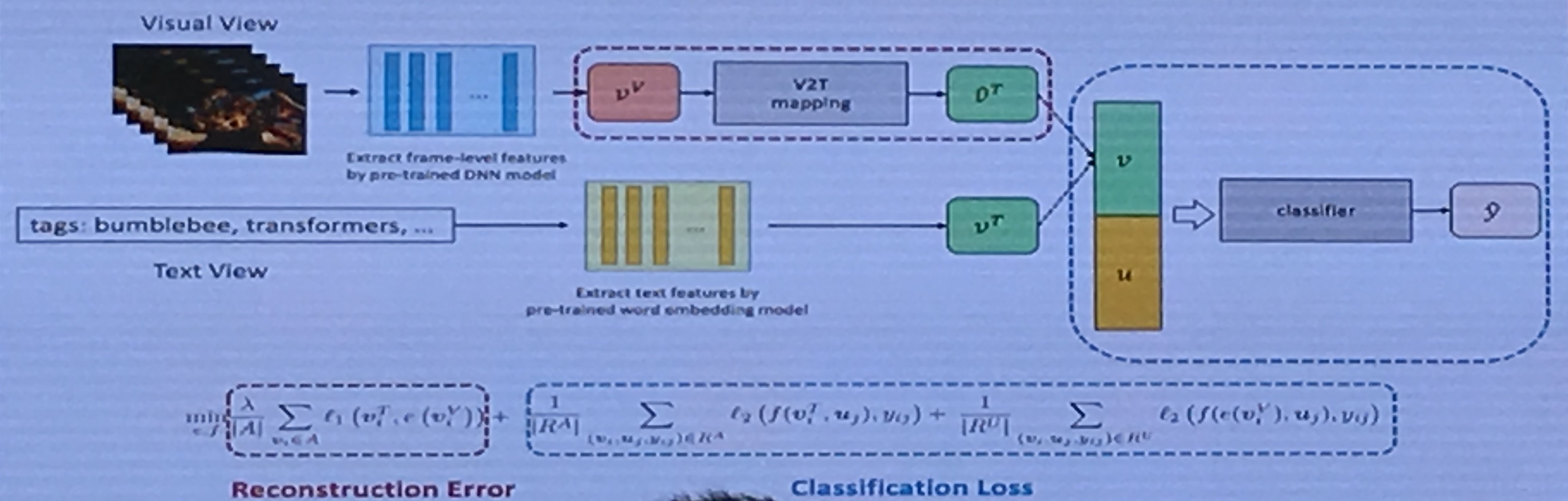
-
features——active feature acquisition with supervised matrix completion
问题:现实应用中往往会出现特征丢失现象,通常导致学习性能下降
motivation: SMC——supervised matrix completion(exploit the label information / Trace-norm for low-rank assumption)
AFA——Active Feature Acquisition(minimize the feature acquisition cost / contribute to both recovering missing entries and classification)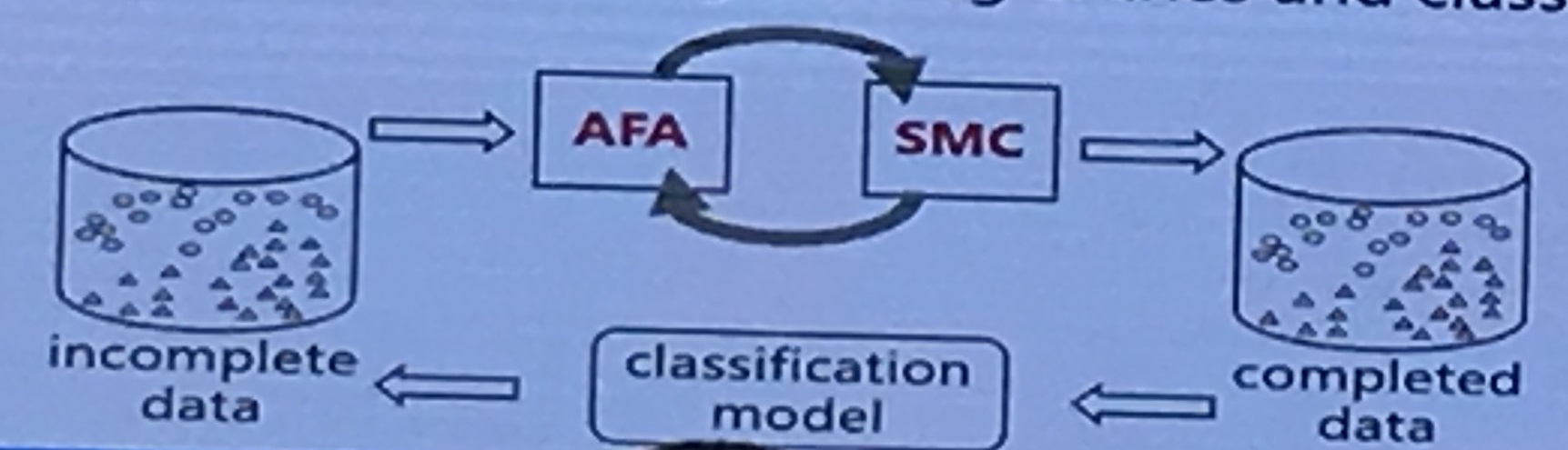
idea:(这部分设计太多专业基础知识,不太明白)


-
labels——active querying for hierarchical multi-label learning
标签有层次结构
平衡成本和信息
-
Oracles——active learning from diverse and imperfect oracles
不同的oracles有不同的价格
同时选择instance和oracle
准确而便宜的标签
-
-
总结
主动学习:用最少的标签代价训练一个高效的模型
代价和不同的 instances/features/labels/oracles 有关系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号