

hash一致性
HASH取余算法问题
节点数量越多时,迁移数据造成的未命中越高;

hash一致性
-
介绍:
数学模型,经过代码的应用转化成的一种常见常用的计算算法;
数学模型,是基于散列算法完成(key不变,散列结果的整数不变);1997年美国麻省理工;大二学生研发的数学模型;
散列算法,将任意的内存对象数据转化成整数;整数区间0-2^32次方(43亿,无符号的int);称这个区间为hash环;利用这个hash环,能够实现,数据的切分处理逻辑计算;
-
基本原理
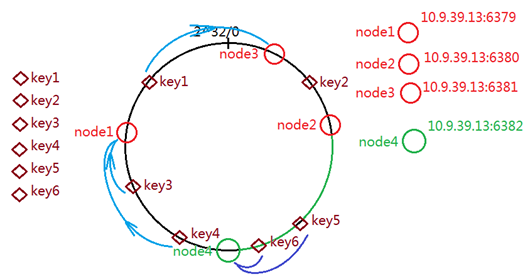
key值和节点node的对应关系可以通过hash环计算获取
![]()

node节点信息,作为字符串数据,进行散列计算映射到环中的某个整数位置;
key值作为字符串数据,散列计算映射到环中某个位置;
key值的整数,顺时针寻找最近的节点整数,对应处理存储;
上图内容:
node1:key3,4,5,6
node2:key2
node3:key1
-
扩容时
能够解决扩容是,迁移量的问题?
![]()
节点扩容时,数据被切分成若干个弧线整数对应关系;节点数量越多,弧线越小,需要迁移的数据量越少;
-
数据平衡性
直接对应真是节点整数,会非常有可能造成某个节点数据倾斜严重;
hash一致性中,引入了虚拟节点,解决数据平衡性,每个真实节点有默认的若干个虚拟节点(jedis中虚拟节点个数160*weight权重值,权重默认是1)
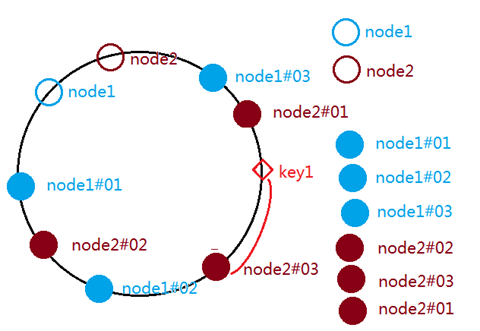
真实节点信息
node1:10.9.39.13:6379
node2:10.9.39.13:6380
虚拟节点:
node1-1:10.9.39.13:6379#01
node1-2:10.9.39.13:6379#02
node1-3:10.9.39.13:6379#03
node2-1:
node2-2:
node2-3:
key值依然完成散列计算,实现对应环上某个整数,依然顺时针寻找最近节点整数,如果对应的真实节点整数,直接处理,如果对应到了虚拟节点,根据虚拟节点绑定的真实节点对应;
结论:虚拟节点越多,数据越均衡;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号