大数据基础---Elasticsearch是什么?
Elasticsearch是谁不重要,重要的是咱们都知道百度,谷歌这样的搜索巨头吧。它们的核心技术都利用了Elasticsearch,所以我们有必要对Elasticsearch了解下!
1.Elasticsearch简介
1.1 百度百科这样说
Elasticsearch是一个基于Lucense的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java,.NET(C#),PHP,Python,Apache Groovy,Ruby和许多其它语言都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是[Apache Solr]([https://baike.baidu.com/item/apache solr](https://baike.baidu.com/item/apache solr)),也是基于Lucense。
1.2 Elasticsearch和Solr对比
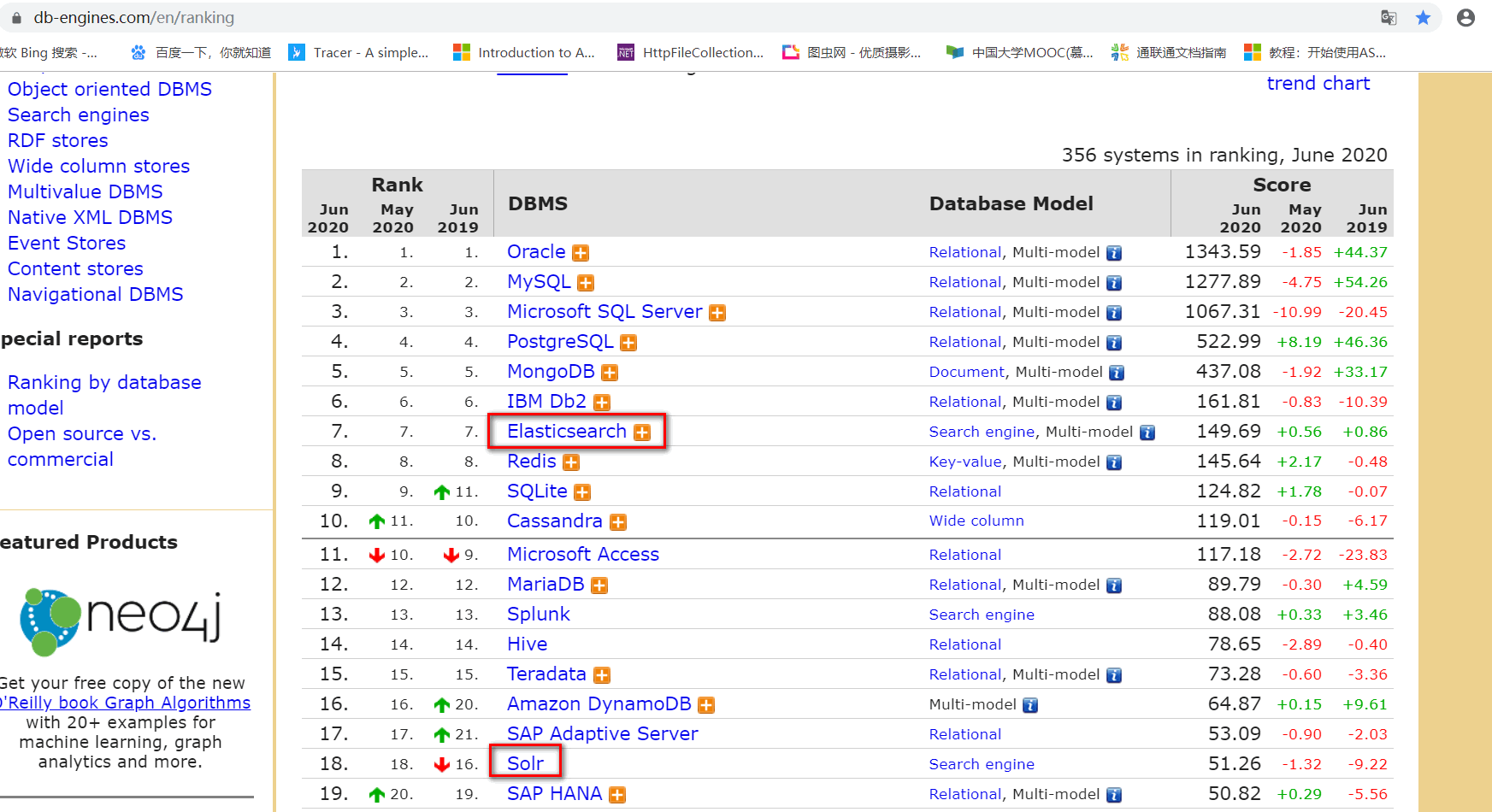
从上图可以了解到使用Solr的趋势逐渐被Elasticsearch取代。
那么为什么会被取代呢?网上找了个图可以参考下:
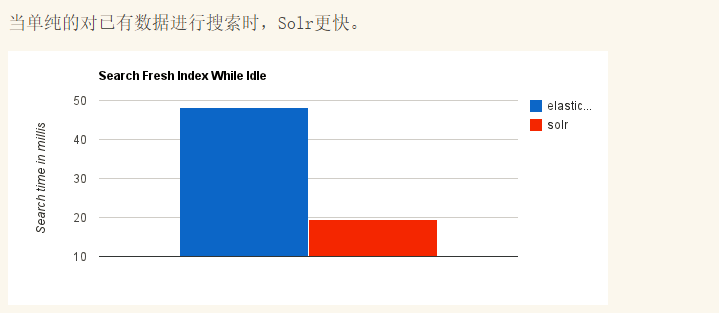
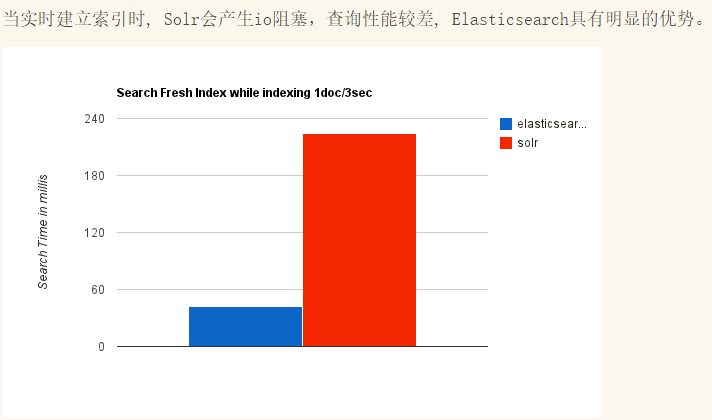
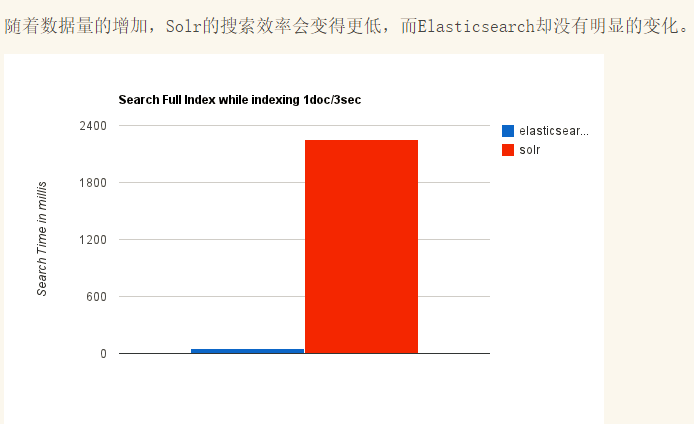
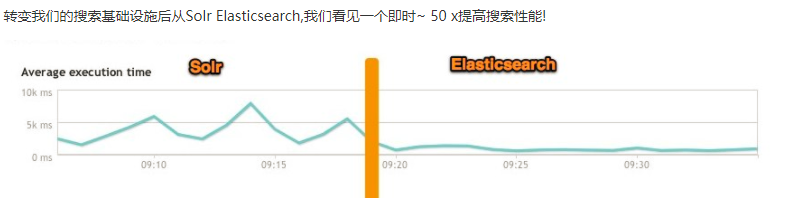
所以使用Elasticsearch的越来越多。
2.扒一扒Elasticsearch的祖先Lucene
2.1 百度百科这样说
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
3.全文检索和普通检索的区别
当我们使用关系型数据库时,要查询包含某个关键字的文章,通常需要使用like %关键字 这种形式。如果仅仅是普通搜索的话,它会一行行遍历去找。如果抛开建立索引的合法性,我们对文章建立了索引,这个时候查询速度相对快一些,先去索引找,找到后再去找对应文章。 但是我们知道数据库中索引采用的B+树结构,这种结构是不适合建立大型索引的,而且文章较多的话,一个一个文章遍历,想想都会花费很长时间,少则几分钟,多则无上限。
针对这种情况于是乎产生了全文检索,也就是上面我们提到的包括Lucene和Elasticsearch都是全文检索的一种实现。全文检索采用的是倒排索引算法,它将文章的所有数据进行分割,分割成一个个词汇,这些词汇建立索引库,这些索引库里面的内容是不重复的,并且索引库存放在了文件系统里面,索引库不仅记录了关键字,而且记录了索引对应的文章和关键字偏移量。这样当我们再次检索时,就能从索引库中快速找到关键字所对应的文章。
通常这些全文检索引擎采用了分布式,大大提高了查询效率和容错性。
4.Elasticsearch的生态以及核心内容有哪些?
通过进入官网,我们即可了解到它的一些生态信息。
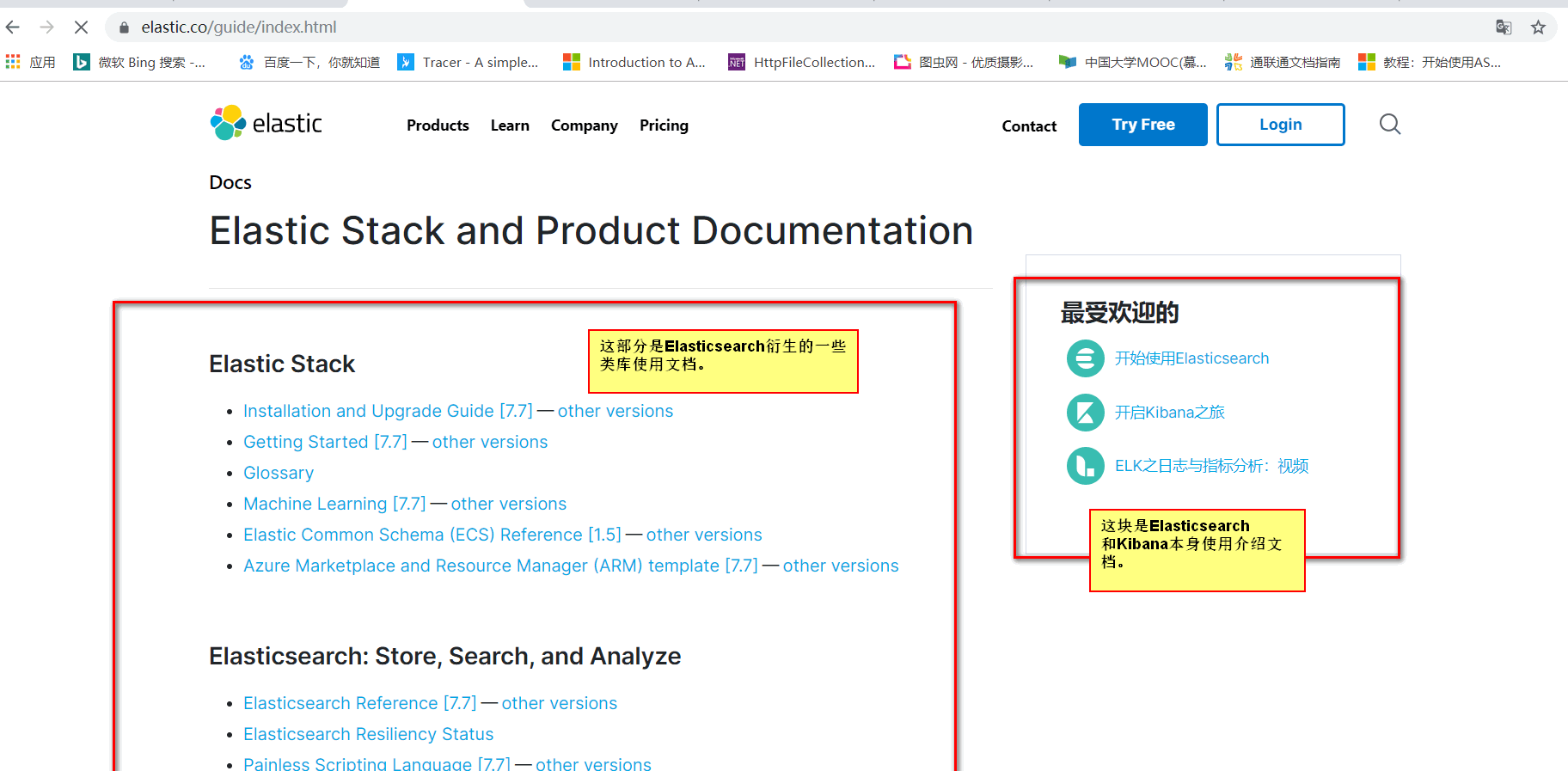
4.1 核心生态
通过浏览我们可以了解到Elasticsearch,Kibana和Logstash(简称:ELK)构成了ES检索的核心生态。
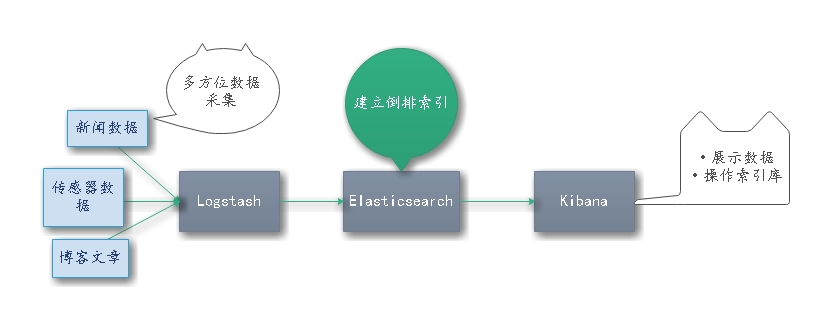
- Logstash用于多渠道数据收集。
- Elasticsearch(简称:ES)将收集的数据建立倒排索引存储。
- Kibana则提供了图形化数据展示,以及针对Elasticsearch索引库的操作。
崇尚授人以渔的思想,说说怎么去找上面的官方文档。
紧随上面的截图往下拉即可看到Kibana和Logstash文档入口。
Elasticsearch文档相对隐蔽一些:

4.2相关API
对于程序员来讲,最关心的当然是如何使用代码进行实现。那么就满足你,看下面:


4.3 其它生态
除了官方提供,还衍生了一些其它的开源项目。比如IK分词,head UI展示,本地化社区等。
IK分词项目:由于官方仅仅提供了英文和德文分词,这个项目作为中文分词很好了弥补了空缺。
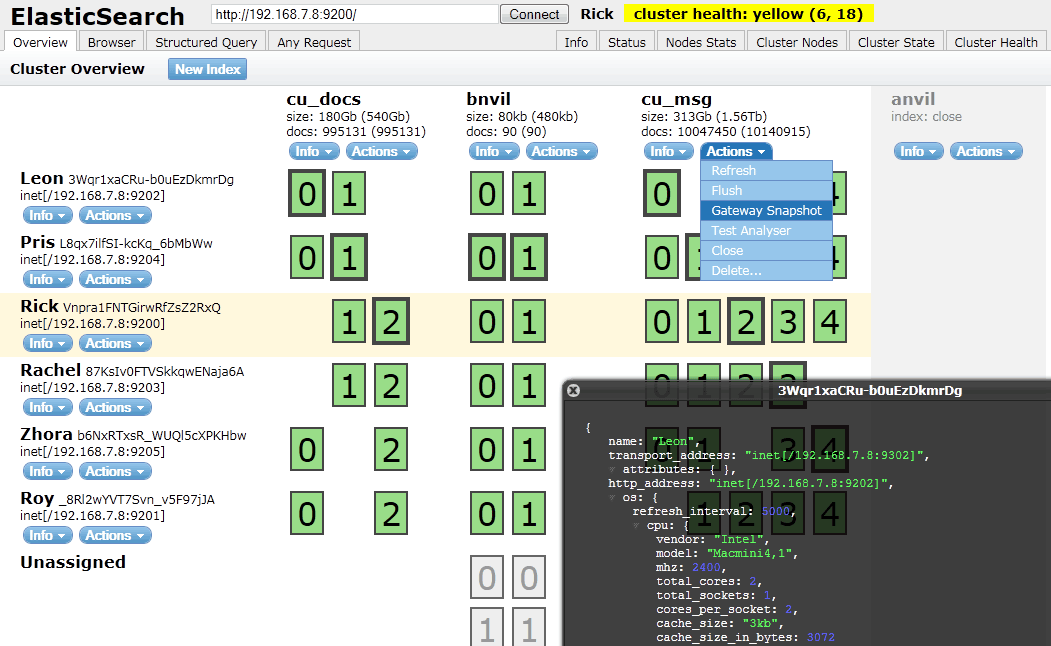
head UI项目:和Kibana似的也能对ES进行操作,但是这个项目还能展示有哪些节点在运行以及节点的信息。项目是基于node运行,所以要提前搭建好node环境。
界面展示效果如下:
中文交流社区:这个是IK分词medcl大神建立的,有问题可以提问。但是最近貌似因为灌水的太多,做了一些限制,新人必须达到浏览时长才能发帖。
中文翻译组织:这个也是medcl大神创建的,提供ES中文翻译,有兴趣的都可以申请加入。
4.4 ElasticSearch一些基本概念
在正式学习之前下面的基本概念是需要了解的。
term
term是一个被索引的精确的值。terms:foo, Foo, FOO 是不等价的。Terms可以使用term query查询。例如:"我爱中国"被分词为,我/爱/中国 ,那么有3个term,分别是:我,爱,中国 。
analysis
把字符串转换为terms的过程。基于它使用可那些分词器,短语:FOO BAR, Foo-Bar, foo,bar有可能分词为terms:foo和bar。这些terms会被存储在索引中。全文索引查询(不是term query)“FoO:bAR”,同样也会被分词为terms:foo,bar,并且也匹配存在索引中的terms。分词过程(包括索引或搜索过程)使es可以执行全文查询。
cluster
集群由一个或多个节点组成,它们都使用同一个集群名。每个集群都有单个master节点,他是自动被集群选举的,如果当前master节点发生故障,可以用候选master节点代替它。
document
文档是一个json文档,它存储在es中。它就好像是关系数据库中table中的一行。每个文档都保存在索引中,并且属于一个type和有一个id字段。文档是一个json对象(在其他语言中是hash/hashmap/管关联数组)它包含0个或多个字段,或key-value对。被索引的原始的json文档会被保存在_source字段,当执行getting或searching操作时会默认返回该字段。
id
识别文档的id。文档的index/type/id必须是唯一的,如果没有提供id,将会自动生成id
field
文档包含一系列的字段,或者key-value 对。每个值都有可以是单个值(string,intger,date)或者是一个像数组的nested 结构或者对象。字段和关系数据库中的列类似。不要和文档type混淆。
index
索引就像关系数据库中的一个表,它包含一个mapping,mapping定义索引的字段,它由多个type组成。索引是一个逻辑命名空间,它映射到一个或多个主分片和0个或多个复制分片。
mapping
mapping就像关系数据库中的schema。每个索引都有一个mapping,它定义了index中的type,和一系列索引level的选项。mapping可以显示定义或者在索引文档时自动生成。
node
节点是一个运行中的es实例,它属于一个集群。可以在一个服务器启动多个节点用于测试,但通常都是一个服务器一个节点。在启动的时候节点会使用单播查找一个具有相同集群名并且已存在的集群,并尝试加入它。
primary shard
每个文档都保存在单个主分片中。当你索引一个文档,他首先会在主分片索引,然后告诉所有该主分片的复制分片。默认,索引有5个主分片,你可以根据你的文档数量指定更小或更多的主分片。当索引创建之后,你不能改变主分片的数量。
replica shard
每个主分片都有一个或多个复制分片。复制分片是主分片的副本,用于以下两个目的:
- 提升容错能力,复制分片提升为主分片,如果主分片不可用。
- 提升性能,get和search请求可以被主分片或者复制分片处理。默认,每个主分片都有一个复制分片,可以动态修改复制分片的数量。永远不要在相同的节点同时存放主分片和复制分片。
routing
当你索引一个文档,它被保存在单个主分片,并基于对routing的值进行hash计算映射到对应的分片。默认被hash的值来自文档id或者文档的父文档id(确保父文档和子文档存储在同一个分片)。这个值可以在索引期间指定routing参数或在mapping中使用routing字段修改。
shard
分片是单个lucene索引实例。ta是一个底层的“woker”单位,它由es自动管理。一个索引是一个逻辑的命名空间,它指向主分片和复制分片。而不是定义主分片和复制分片的数量,你从来都不需要直接引用主分片。相反,你的代码仅仅需要引用索引。es会在集群的所有节点中分发分片,并可以自动在节点之间移动分片,当节点出现故障时或者添加额外的节点。
source field
默认,你索引的JSON文档会被存储在_source字段,并会在所有的get和search请求中返回。这允许你直接从搜索结果中直接访问原始的对象,而不需要先查询id然后再获取文档。
text
text是普通非结构化的文本,例如段落。默认,text会被分词成terms,索引实际上储存的是terms。text 字段需要在索引期间进行分词,这样才可以进行全文搜索,查询字符串在搜索期间也需要被分词。 fuzhi
type
type呈现文档的类型,例如 email,user,或weet。search API 可以根据type过滤文档。索引可以包含多个type,每个type包含一系列的字段。同一个索引不同type字段名相同的字段必须具有相同的mapping。
docvalues
它保存某一列的数据,并索引它,用于加快聚合和排序的速度。
fileddata
它保存某一列的数据,并索引它,用于加快聚合和排序的速度。和docvalues不一样的是,fielddata保存的是text类型的字段分词后的terms,而不是保存源字段数据。
shardcopies
分片副本集合,包含主分片和复制分片
segment
每个分片都分为多个segment存储。小的segment和定期合并成大的segment
master
master 节点用于执行轻量的集群操作,例如:创建删除索引,跟踪节点,决定分片分发到哪个节点等。每个集群同时只有一个master节点和0个或多个master候选节点。
基本的介绍就到这里,下一章是讲解如何搭建,以及踩过的地雷。
本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/13045812.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号