大数据基础---Spark整体复习
一. Spark简介
1.1 前言
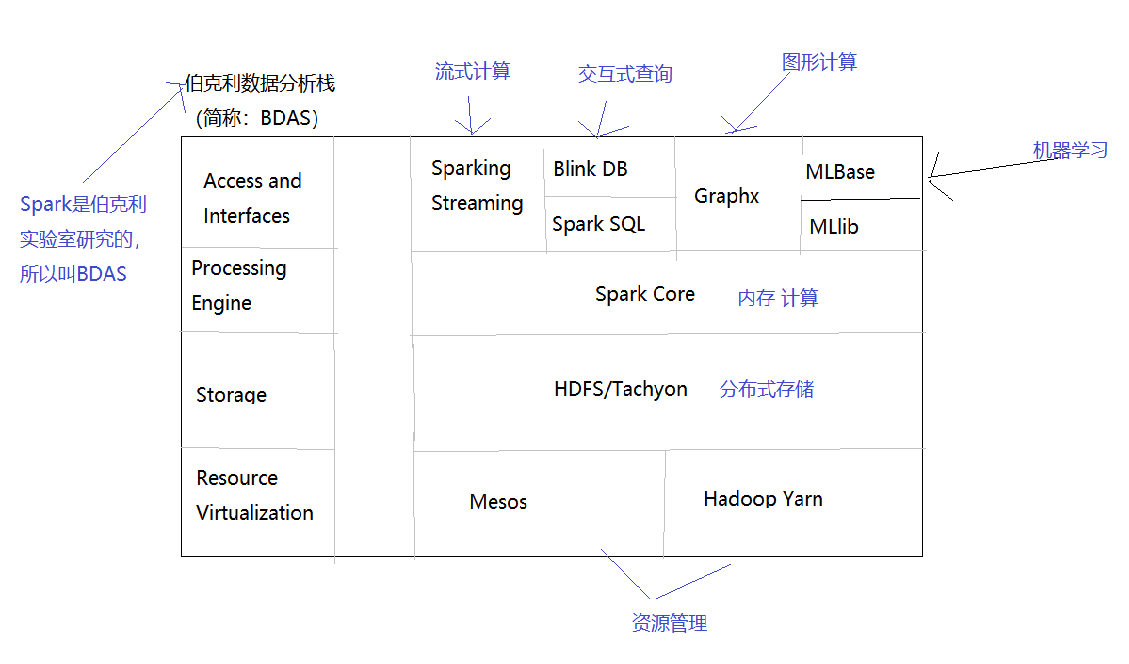
Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spark Streaming),交互式查询(Spark SQL),图形计算(GraphX),机器学习(MLLib)。
1.2 安全性
默认情况下Spark安全性是关闭的。(正式环境要开启)
1.3 版本兼容性
| Spark版本 | Java版本 | Python版本 | Scala版本 | R版本 |
|---|---|---|---|---|
| 2.4.1~2.4.5 | 8 | 2.7+/3.4+ | 2.12.x | 3.1+ |
二. 部署
2.1 Spark集群介绍
2.1.1 集群架构
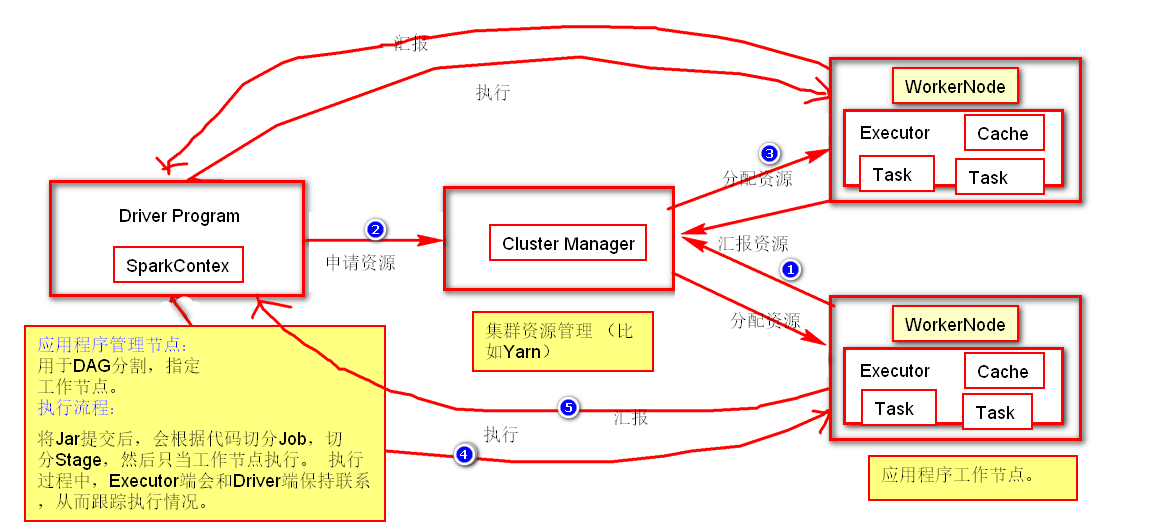
有关此结构的几点概要:
- 每个应用程序都有独立的进程,并且开启多个线程进行执行。这样应用程序的调度(每个Driver调度自己的Executer)和执行(在不同的JVM上执行)互不影响。因此只有把执行结果放在外部存储器里面才能被其它程序使用。
- Spark不受集群限制,只要Driver和应用程序能进行通信就能执行。
- Driver会监测每个执行的程序。
- Driver应靠近Executor,这样网络的不稳定性和带宽消耗。
PS:集群管理器类型包括:独立部署,Spark模式部署,Mesos模式部署,Kubernetes模式部署。
2.1.2 提交方式
使用spark-submit可以将应用程序提交到任何形势的集群。
2.1.3 监控UI
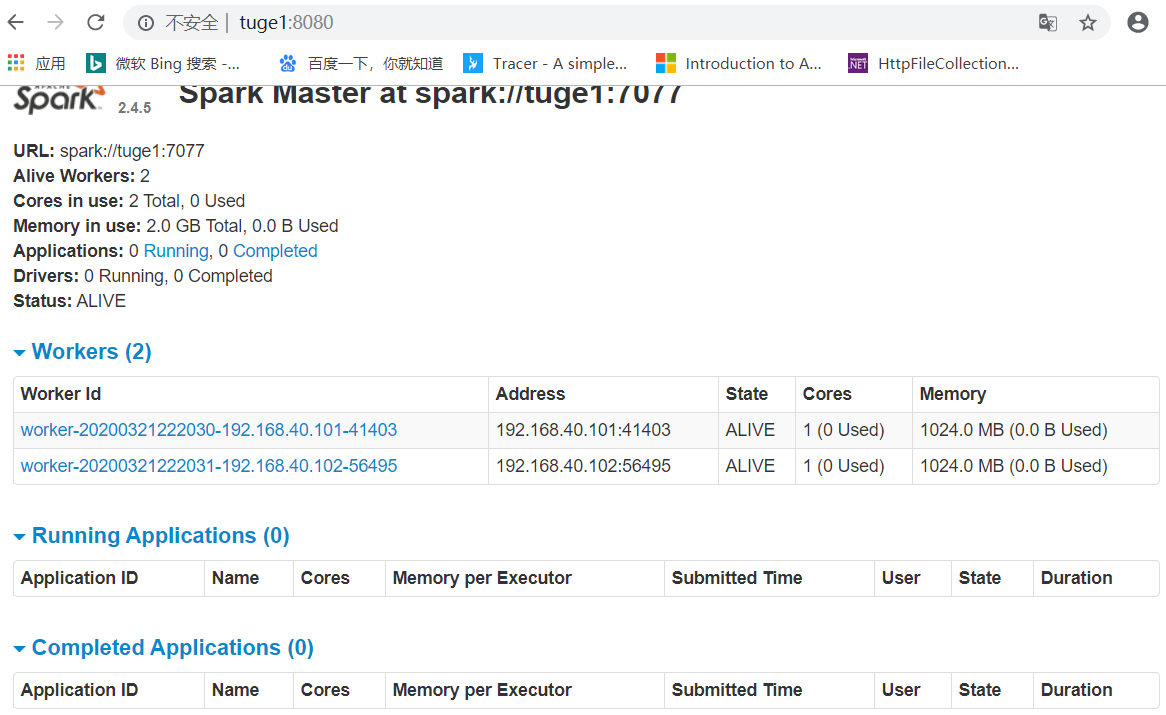
浏览端口4040查看任务。例如:http://node1:4040
浏览端口8080查看Master。例如:http://node1:8080
2.1.4 术语表
| 术语名 | 简介 |
|---|---|
| Application | 基于Spark的应用程序。 |
| Application jar | 一个包含Spark应用程序的jar。 |
| Driver program | 运行应用程序main(),并创建SparkContext的过程。 |
| Cluster manager | 用于获取外部集群资源的服务。(比如mesos,yarn) |
| Deploy mode | 部署方式:在“集群”模式下部署在集群内部,在“客户端”模式下,提交者在集群外部启动程序。 |
| Worker node | 工作节点(在集群中可以运行应用程序的节点。) |
| Job | 一个action触发对应一个job。 |
| Stage | 根据job中的shuffler操作划分多个stage。 |
| Task | 每个stage对应一个多多个task。 |
| Executor | executor可以执行多个task。 |
| DAG | 中文名,有向无环图。根据RDD之间的关系进行构建。 |
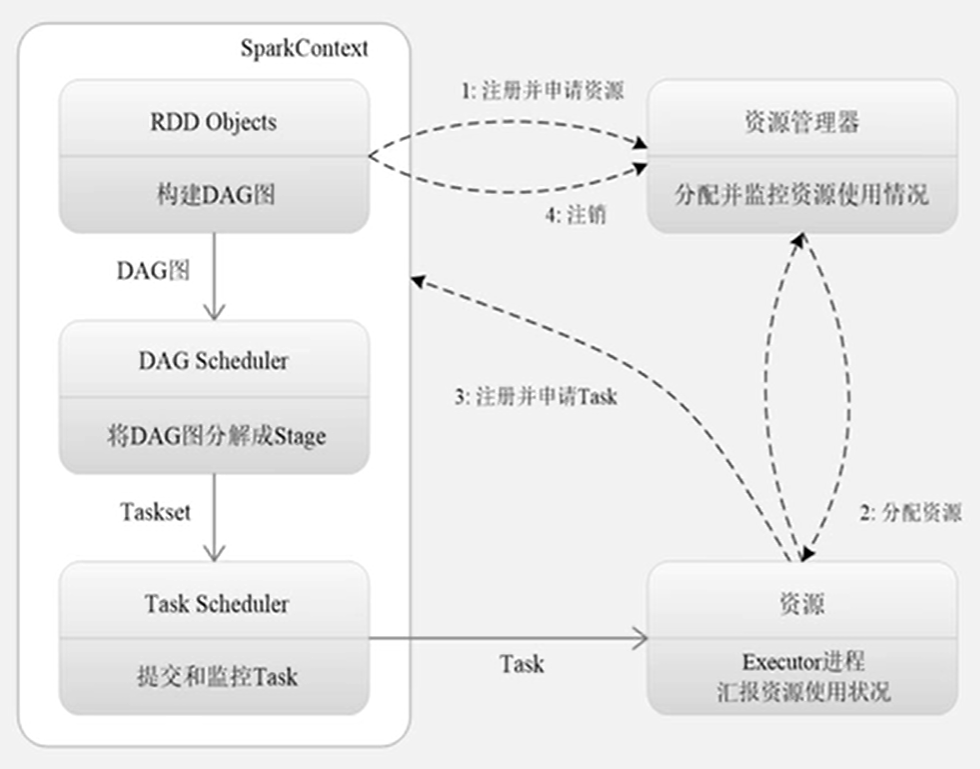
2.1.5 Spark程序执行流程图
2.1.6 Spark技术栈
2.2 Standalone部署
2.2.1 安全性
默认情况下Spark是关闭安全的,所以如果您不配置则可能会被攻击。如何设置安全,请参阅 Spark安全性 。
2.2.2 Standalone部署到集群
从官网下载对应版本放在服务器解压即可。这里我下载的2.4.5
在tuge1创建了一个/opt/spark目录,并将下载的压缩包放上去,然后分发到tuge2,tuge3。
服务器部署如下:
| 服务器名: | tuge1 | tuge2 | tuge3 |
|---|---|---|---|
| Spark版本: | Spark2.4.5 | Spark2.4.5 | Spark2.4.5 |
2.2.3 手工启动
在master服务器(tuge1)执行如下脚本启动:
# ./sbin/start-master.sh
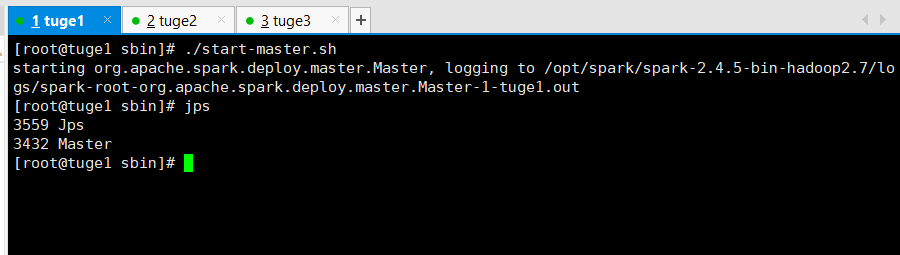
启动后就可以使用默认端口8080访问了。比如: http://tuge1:8080/
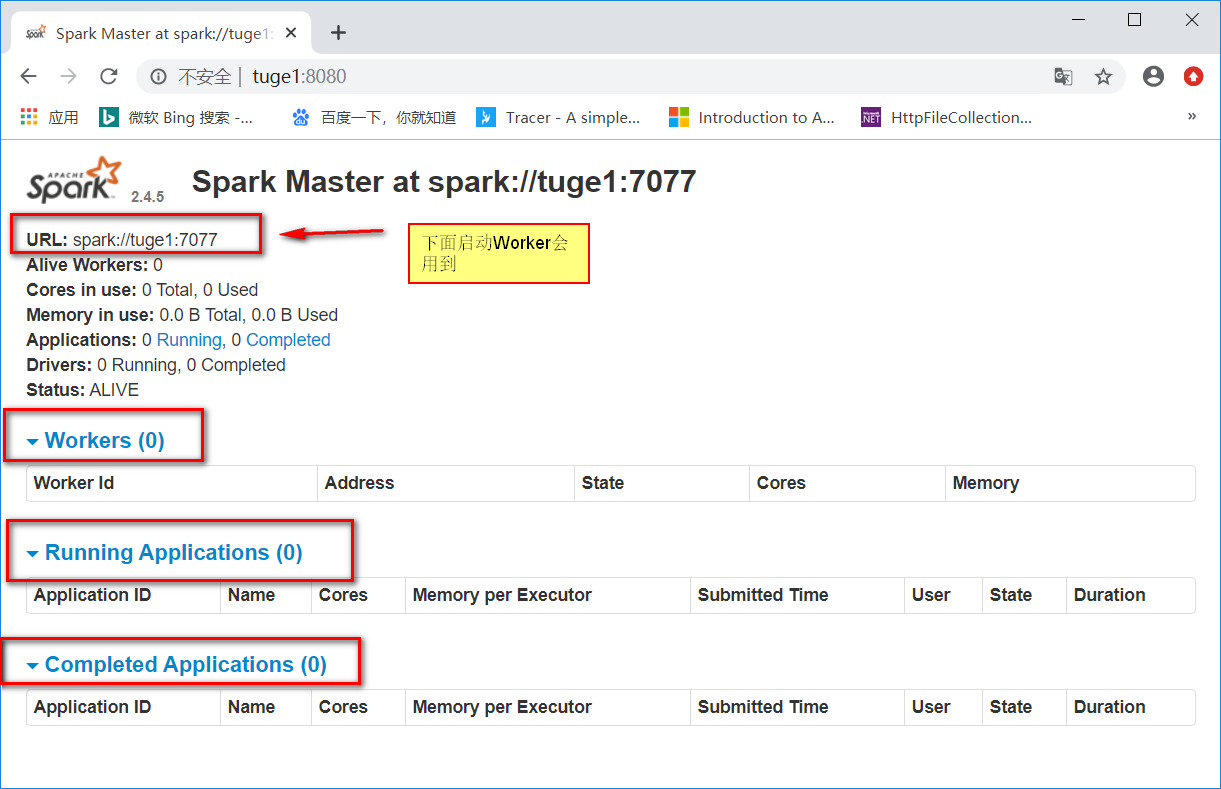
同样您可以启动一个或多个Worker,并通过以下方式连接到主节点:
./sbin/start-slave.sh <master-spark-URL>
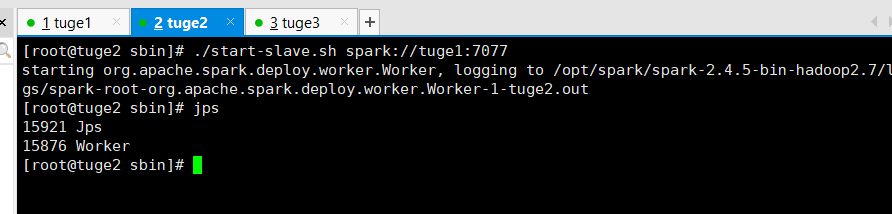
比如在tuge2,tuge3服务器执行: ./sbin/start-slave.sh spark://tuge1:7077 。这样就将worker服务连接到了master。
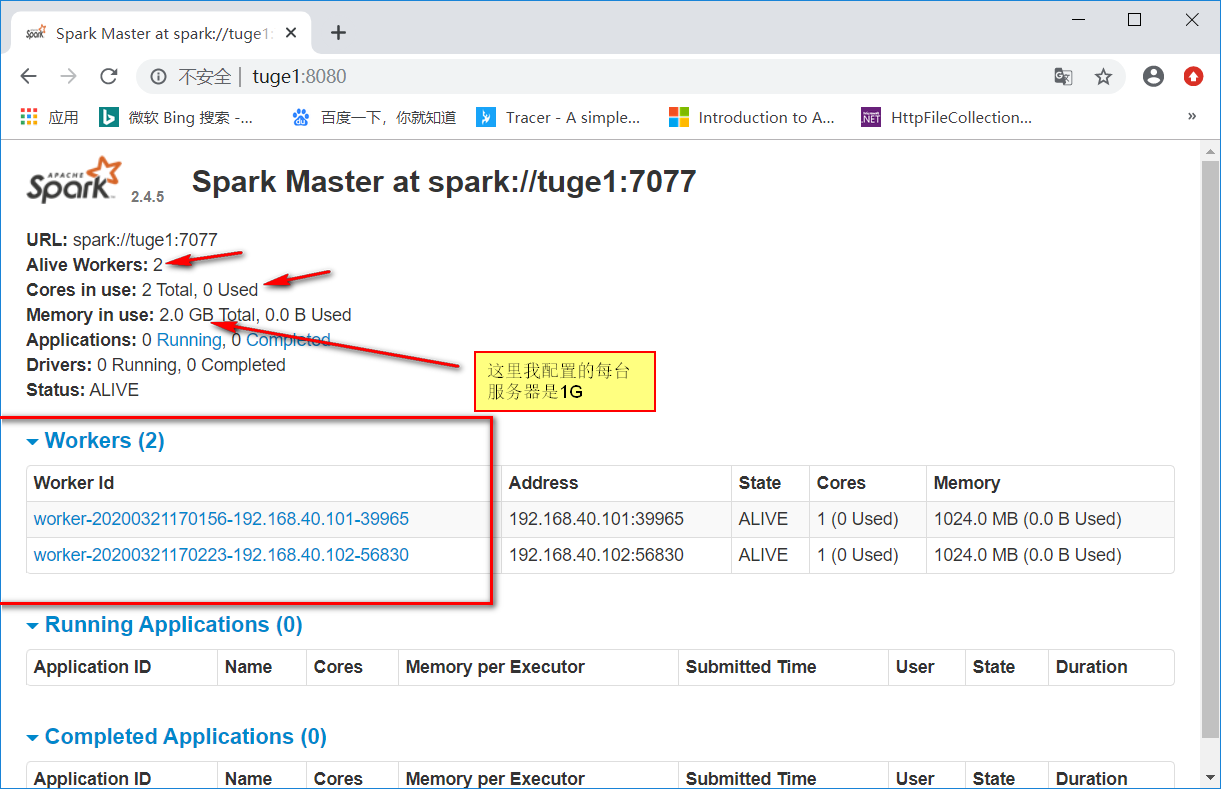
启动后再次浏览http://tuge1:8080/就可以看到新增了两个Worker。
2.2.4 使用脚本启动
要使用启动脚本启动Spark独立集群,您应该在Spark目录中创建一个名为conf / slaves的文件,该文件必须包含要启动Spark Worker的所有计算机的主机名,每行一个。如果conf / slaves不存在,则启动脚本默认为单台计算机(localhost),这对于测试非常有用。请注意,主计算机通过ssh访问每个工作计算机。默认情况下,ssh是并行运行的,并且需要设置无密码(使用私钥)访问权限。如果没有无密码设置,则可以设置环境变量SPARK_SSH_FOREGROUND并为每个工作线程依次提供一个密码。
您可以选择通过在中设置环境变量来进一步配置集群conf/spark-env.sh。通过模板conf/spark-env.sh.template创建文件,然后将其复制到所有工作计算机上以使设置生效。可以使用以下设置(必须配置的已经加粗):
| 环境变量 | 含义 |
|---|---|
| JAVA_HOME | 配置Java环境。(注:这个最好配置下,我就是因为没配置导致启动报了Unsupported major.minor version 52.0错误~!) |
| SPARK_MASTER_HOST | 将主机绑定到特定的主机名或IP地址,例如公共主机名或IP地址。 |
| SPARK_MASTER_PORT | 在另一个端口上启动主服务器(默认:7077)。 |
| SPARK_MASTER_WEBUI_PORT | 主Web UI的端口(默认值:8080)。 |
| SPARK_MASTER_OPT | 仅以“ -Dx = y”的形式应用于主服务器的配置属性(默认值:无)。请参阅下面的可能选项列表。 |
| SPARK_LOCAL_DIRS | 用于Spark中“临时”空间的目录,包括存储在磁盘上的地图输出文件和RDD。它应该在系统中的快速本地磁盘上。它也可以是不同磁盘上多个目录的逗号分隔列表。 |
| SPARK_WORKER_CORES | 允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用的核心)。 |
| SPARK_WORKER_MEMORY | 允许Spark应用程序在计算机上使用的内存总量,例如1000m,2g(默认值:总内存减去1 GB);请注意,每个应用程序的单独内存都是使用其spark.executor.memory属性配置的。 |
| SPARK_WORKER_PORT | 在特定端口上启动Spark worker(默认:随机)。 |
| SPARK_WORKER_WEBUI_PORT | 辅助Web UI的端口(默认值:8081)。 |
| SPARK_WORKER_DIR | 要在其中运行应用程序的目录,其中将包括日志和暂存空间(默认值:SPARK_HOME / work)。 |
| SPARK_WORKER_OPTS | 仅以“ -Dx = y”的形式应用于工作程序的配置属性(默认值:无)。请参阅下面的可能选项列表。 |
| SPARK_DAEMON_MEMORY | 分配给Spark主守护程序和辅助守护程序本身的内存(默认值:1g)。 |
| SPARK_DAEMON_JAVA_OPTS | Spark主服务器和辅助服务器守护程序的JVM选项以“ -Dx = y”的形式出现(默认值:无)。 |
| SPARK_DAEMON_CLASSPATH | Spark主守护程序和辅助守护程序本身的类路径(默认值:无)。 |
| SPARK_PUBLIC_DNS | Spark主服务器和辅助服务器的公共DNS名称(默认值:无)。 |
您可以基于Hadoop的部署脚本,使用以下shell启动或停止集群, 该脚本在SPARK_HOME/sbin下面:
sbin/start-master.sh-在执行脚本的计算机上启动主实例。sbin/start-slaves.sh-在conf/slaves文件中指定的每台计算机上启动一个从属实例。sbin/start-slave.sh-在执行脚本的计算机上启动从属实例。sbin/start-all.sh-如上所述,同时启动一个主机和多个从机。sbin/stop-master.sh-停止通过sbin/start-master.sh脚本启动的主机。sbin/stop-slaves.sh-停止conf/slaves文件中指定的机器上的所有从属实例。sbin/stop-all.sh-如上所述,停止主机和从机。
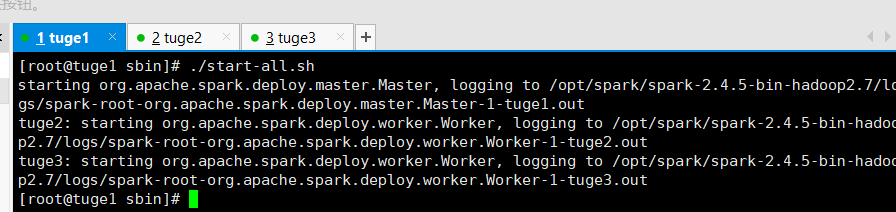
这里我就使用sbin/start-all.sh命令将Application和Worker启动了~!
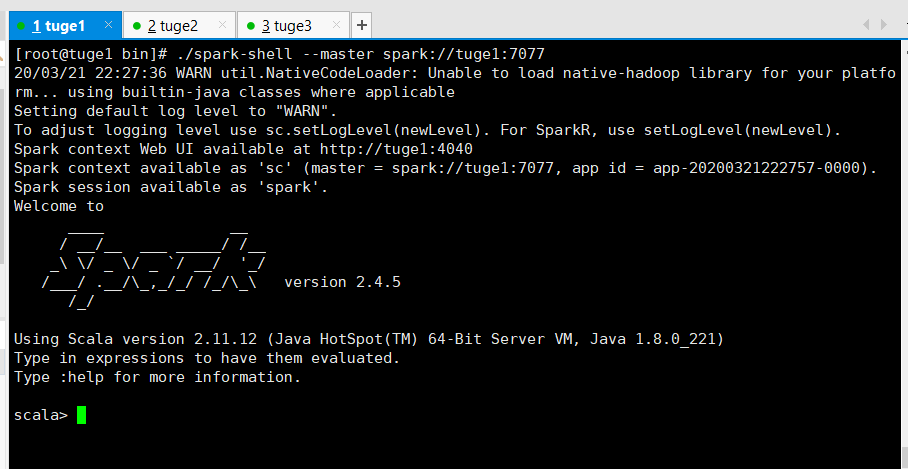
2.2.5 使用shell链接集群
执行如下命令进行链接(spark://IP:PORT)
# ./spark-shell --master spark://tuge1:7077
您还可以传递一个选项,比如--total-executor-cores 来控制spark-shell在集群上使用的核心数量。
(控制台)
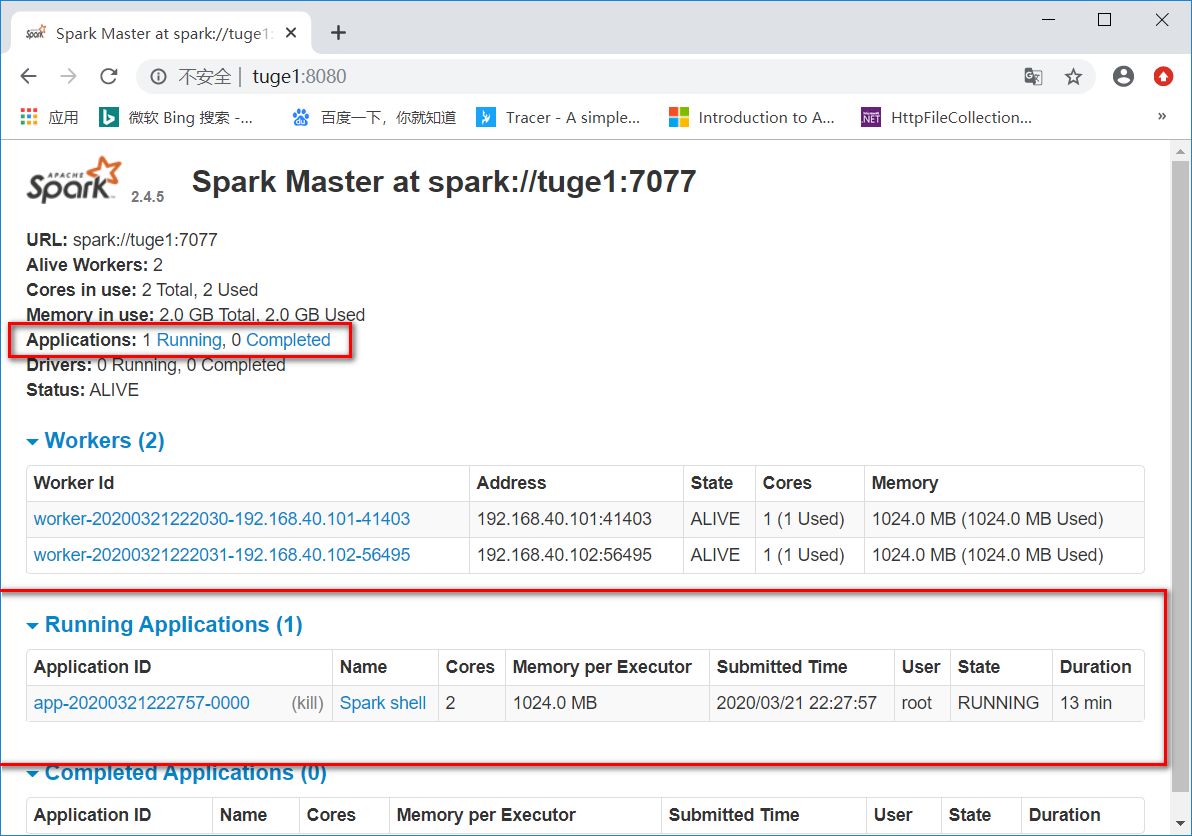
(WebUI)
2.2.6 将程序submit到集群
使用spark-submit脚本进行提交。
就拿官方自带程序进程演示吧,下载好Spark2.4.5到本地后进行解压,可以在
examples\src\main\java\org\apache\spark\examples 看到java示例程序。
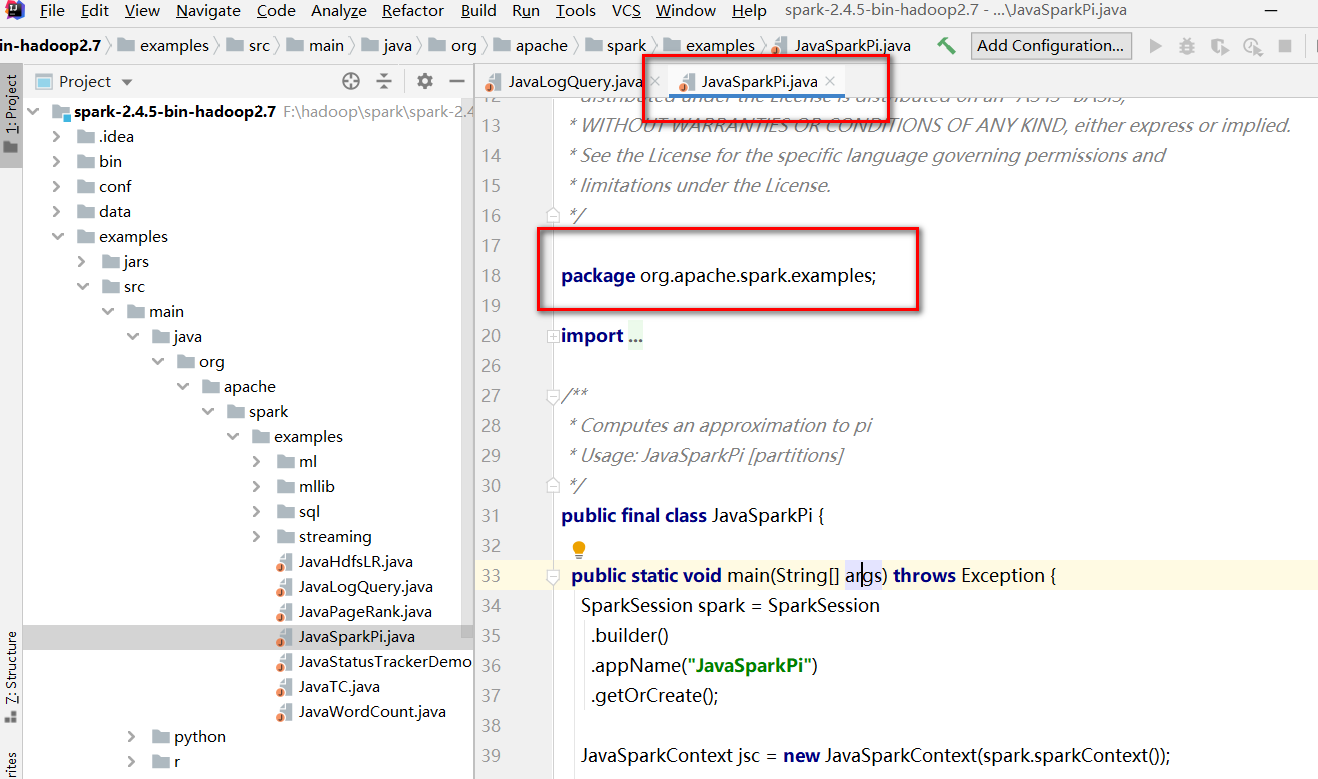
然后整个项目的压缩包可以在examples\jars下找到:
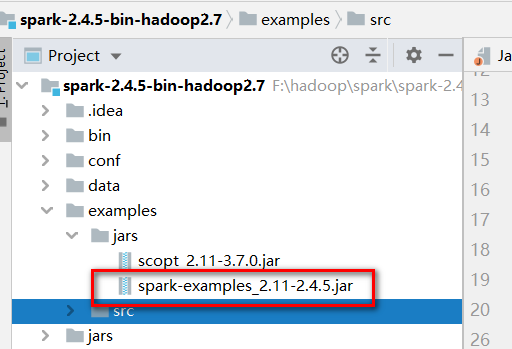
就拿JavaSparkPi举例:
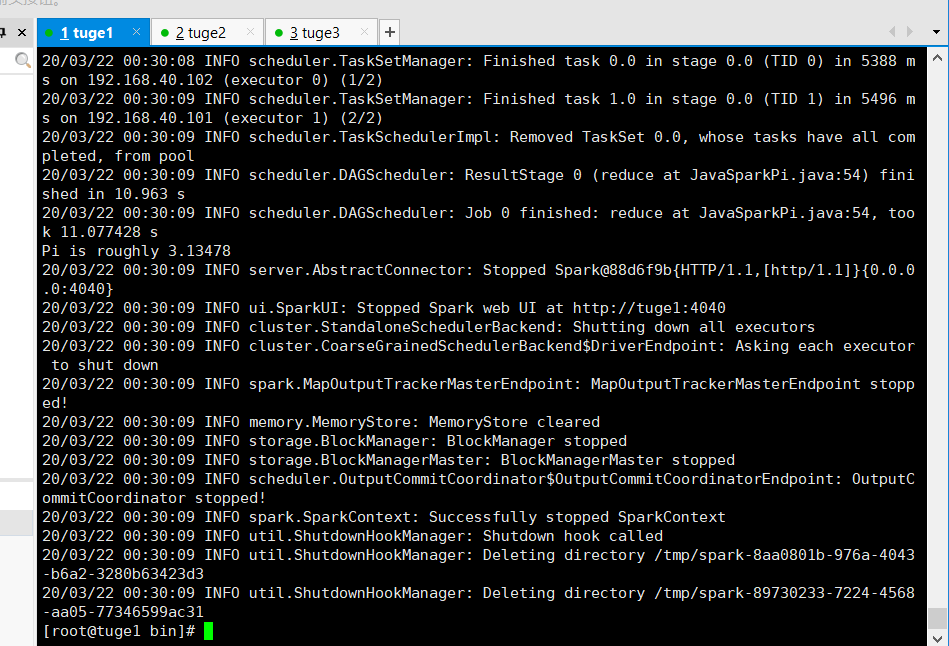
# ./bin/spark-submit \
> --class org.apache.spark.examples.JavaSparkPi \
> --master spark://tuge1:7077 \
> /opt/spark/spark-2.4.5-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.5.jar
执行结果:
2.2.7 通过代码设置资源
standalone遵循的是先进先出原则,默认情况下 ,它将获取所有内核,这仅在您一次只运行一个程序才有意义。要过要同时运行多个,必须要限制内核,如下:
val conf=new SparkConf()
conf.setMaster("....")
conf.setAppName("...")
conf.set("spark.cores.max","3")//限制最大内核数量是3
val sc=new SparkContext(conf)
此外还可以在集群上进行配置。因此将以下内容添加到conf/spark-env.sh
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=<value>"
2.2.8 通过命令设置资源
执行/bin/spark-submit 会显示可以使用的命令:
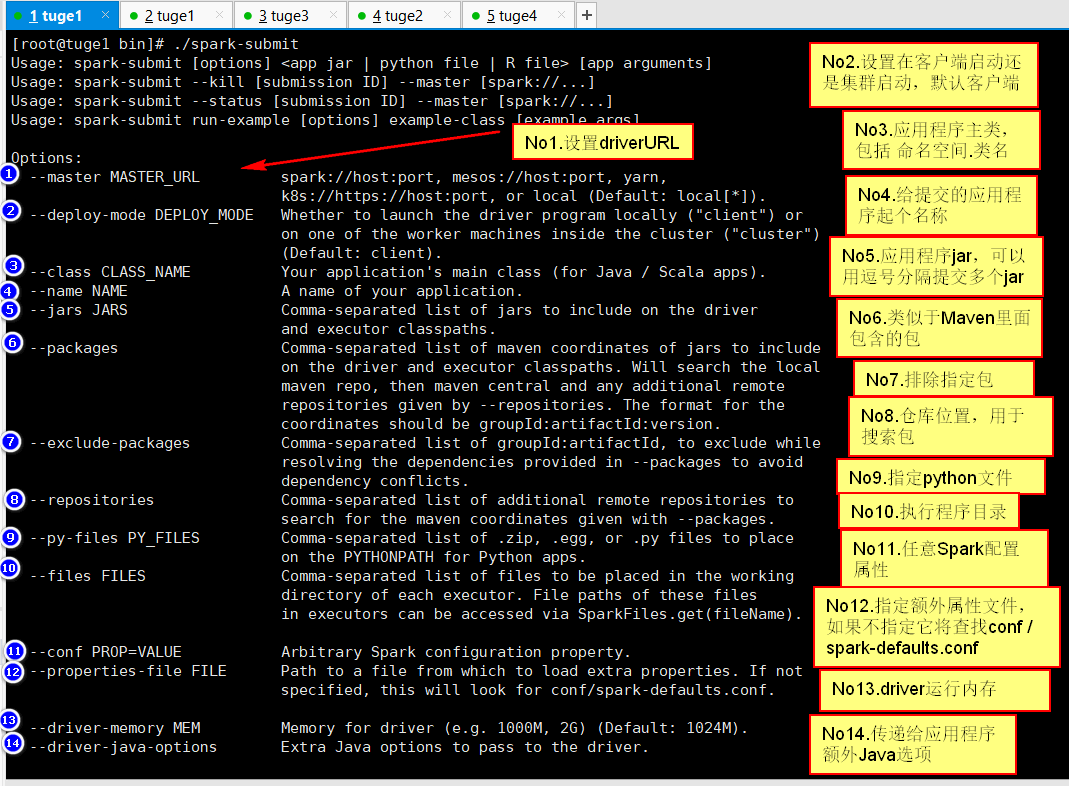
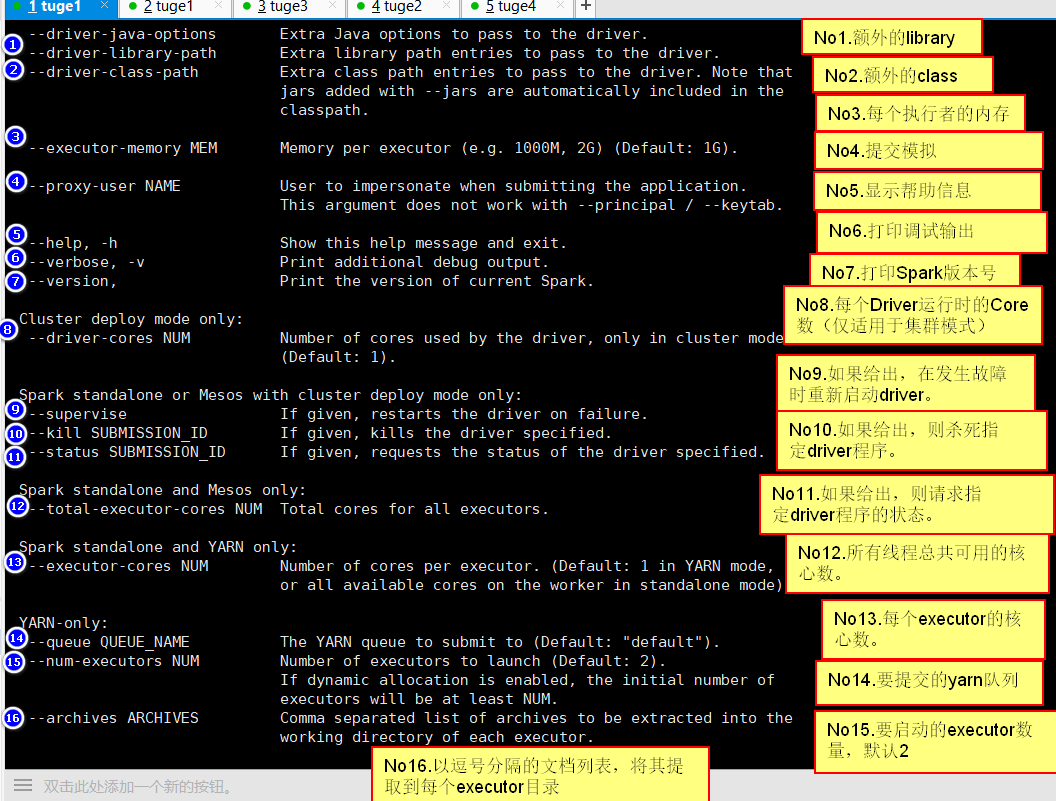
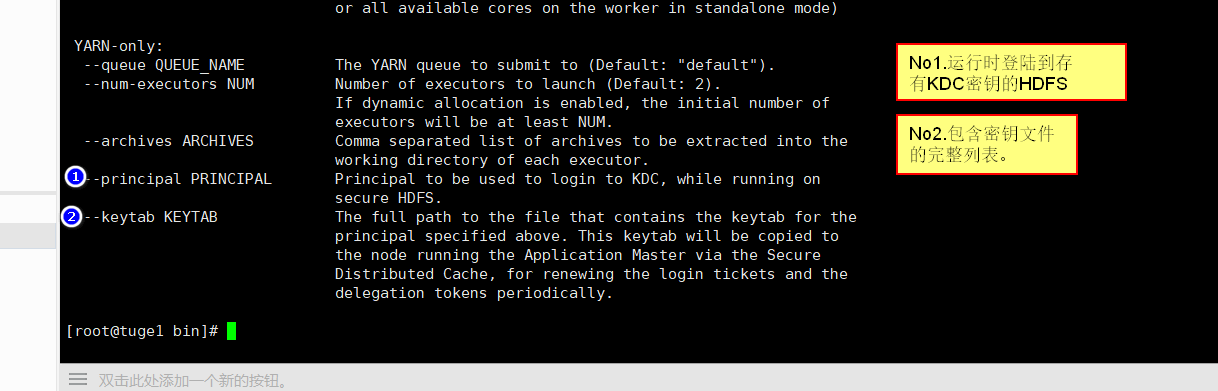
2.2.9 与Hadoop部署在一起
与Hadoop一起部署,这样就可以通过HDFS获取资源,而不仅仅是本地磁盘。这样做的好处,就是集群中所有节点都能够访问资源。
2.2.10 通过配置端口实现安全性
Spark默认部署在内网环境中。如果要进行安全设置参考 安全性页面
2.2.11 通过Zookeeper实现Master高可用
- 使用Zookeeper实现高可用
总览
利用Zookeeper实现高可用:会存在一个主服务器和多个备用服务器,当主服务器挂掉之后,Zookeeper会通过心跳进行感知,从而通过选举机制选举一台从服务器当新的主。
组态
为了启用此恢复模式,您可以通过配置spark.deploy.recoveryMode及相关的spark.deploy.zookeeper。在spark-env.sh中设置SPARK_DAEMON_JAVA_OPTS 。有关这些配置的更多信息,请参阅配置文档
| 物业名称 | 默认 | 含义 |
|---|---|---|
| spark.deploy.recoveryMode | none | 设置为ZOOKEEPER代表发生故障使用zookeeper。 |
| spark.deploy.zookeeper.url | none | zookeeper主机的名字。 |
| spark.deploy.zookeeper.dir | none | spark要在zookeeper上写数据时的保存目录 |
例如我的配置如下:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=tuge1:2181,tuge2:2181,tuge3:2181 -Dspark.deploy.zookeeper.dir=/opt/spark"
然后修改slaves文件(先修改一台,然后分发)
# vim slaves
tuge1
tuge2
tuge3
zookeeper默认和spark端口都是8080,有冲突,所以要么修改zookeeper端口,要么修改spark端口,这里我修改的zookeeper端口。
在conf/zoo.cfg里面添加自定义端口:admin.serverPort=9999
如果上面配置完后,开始启动:
先启动zookeeper, 在每台机器上执行该命令:
# zkServer.sh start
启动Spark
# sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/spark-2.4.5-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-tuge1.out
tuge2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.4.5-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-tuge2.out
tuge3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.4.5-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-tuge3.out
tuge1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-2.4.5-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-tuge1.out
# jps
6402 QuorumPeerMain
7797 Master
7868 Worker
7948 Jps
在第二台机器上单独启动master
# sbin/start-master.sh
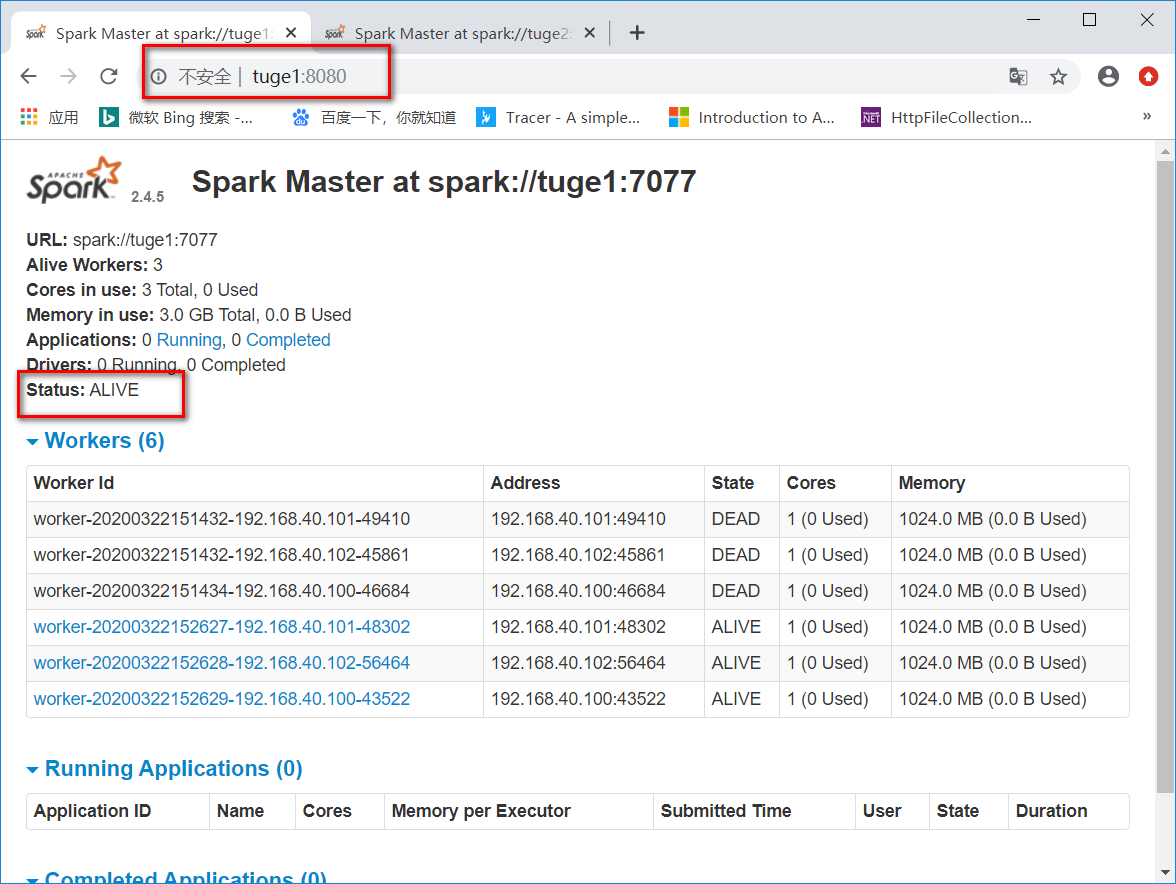
查看web端口
第一个master为
Status: ALIVE
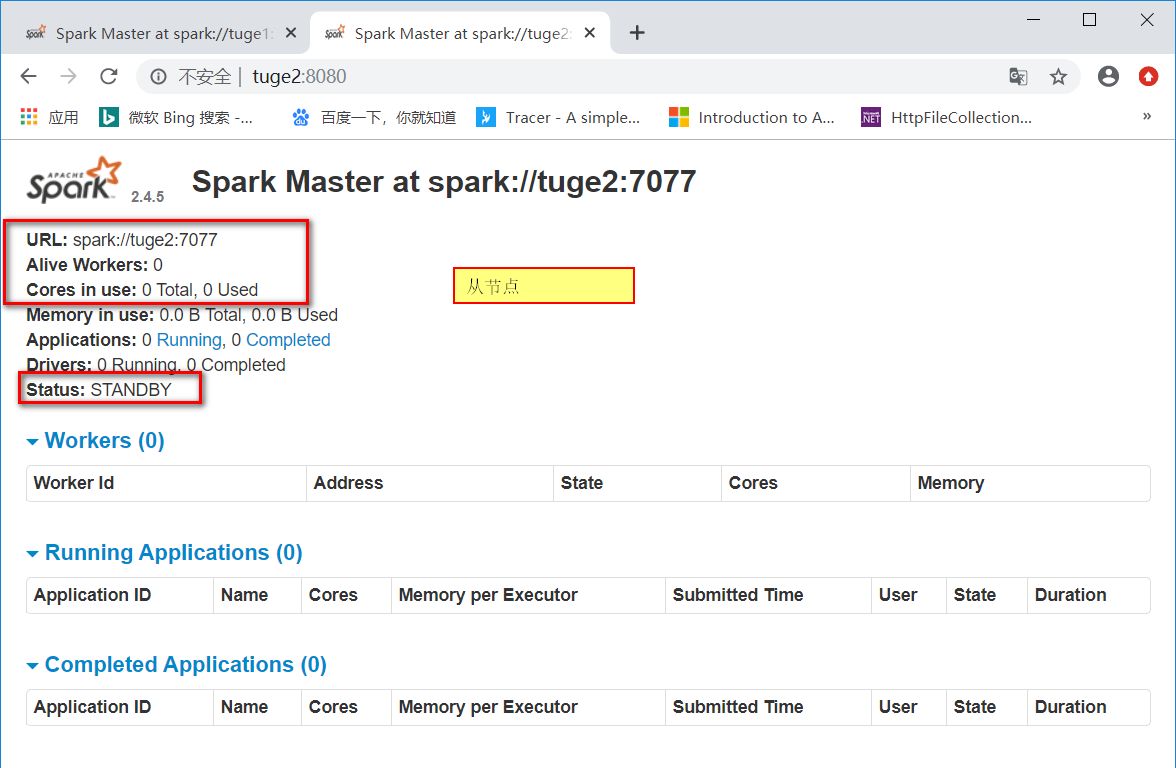
第二个master为
Status: STANDBY
这个时候如果把tuge1杀死,然后再看下tuge2是否转为ALIVE。
通过jps可知,tuge1的masterpid为8365。这里我就接简单粗暴了 :
# kill 8365
然后查看页面,可以看出tuge1已经无法访问,tuge2成为了新的leader。
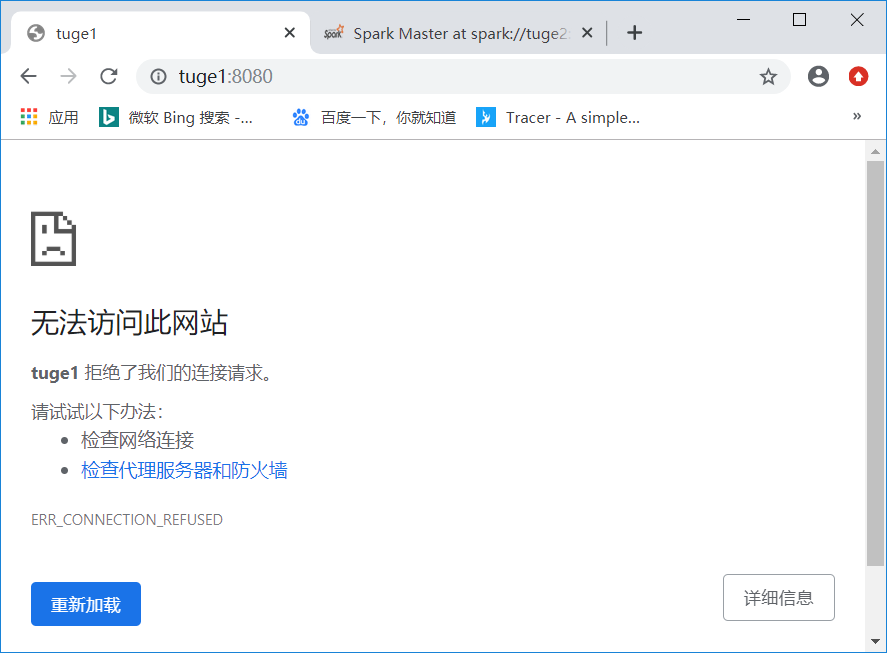
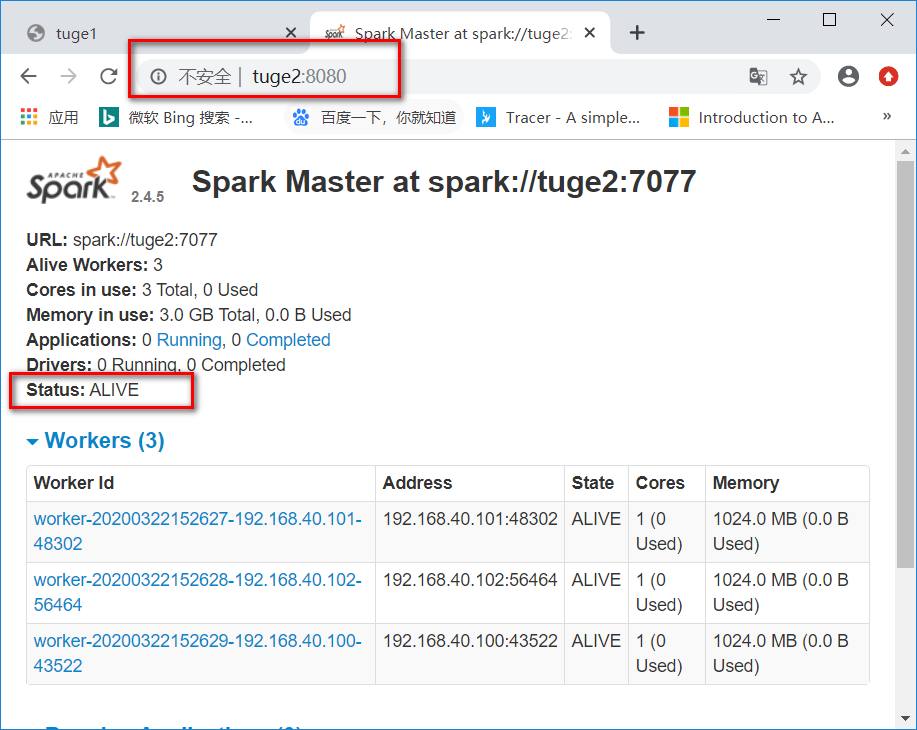
搭建成功~
- 使用本地文件恢复
总览
zookeeper是生产级高可用方法,但是如果您只想在主服务器出现故障时启动它,则 FILESYSTEM模式可以解决这一问题。当Application和Worker注册时,它们可以将状态写入到下面配置的目录里面,以便重新启动主进程时恢复它们。
您可以通过在spark-env设置开启本地文件恢复。
| 系统属性 | 含义 |
|---|---|
| spark.deploy.recoveryMode | 设置为FILESYSTEM以启用单节点恢复模式(默认值:NONE)。 |
| spark.deploy.recoveryDirectory | 从主服务器的角度来看,Spark将存储恢复状态的目录。 |
2.3 Yarn部署
2.3.1 安全性
默认情况下Spark是关闭安全的,所以如果您不配置则可能会被攻击。如何设置安全,请参阅 Spark安全性 。
2.3.2 Spark在Yarn上启动
确保HADOOP_CONF_DIR或YARN_CONF_DIR指向包含Hadoop集群的(客户端)配置文件的目录。 这些配置用于写入HDFS,并链接到Yarn。
# vim spark-env.sh
加入如下配置(将Hadoop里面的配置文件引入进来)(tuge1,tuge2,tuge3服务器都要修改)
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
从上面介绍可以得知,这个是基于HDFS和Yarn的,所以在运行Spark程序之前要先启动HDFS和Yarn。
# cd /opt/hadoop/hadoop-2.6.5/sbin/
# ./start-dfs.sh
# ./start-yarn.sh
以cluster模式启动Spark应用程序:
$ ./spark-submit --class path.to.your.Class --master yarn --deploy-mode cluster [options] <app jar> [app options]
例如:
$ ./spark-submit --class org.apache.spark.examples.JavaSparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
/opt/spark/spark-2.4.5-bin-hadoop2.7/examples/jars/spark-examples*.jar \
10
以client模式启动Spark应用程序:
$ ./spark-shell --master yarn --deploy-mode client
添加其它JAR
在cluster模式下,驱动程序与客户端运行在不同的计算机上,因此SparkContext.addJar对于客户端本地的文件而言,开箱即用。要使客户机上的文件可用于SparkContext.addJar,请将它们包含--jars在启动命令中的选项中。
$ ./bin/spark-submit --class my.main.Class \
--master yarn \
--deploy-mode cluster \
--jars my-other-jar.jar,my-other-other-jar.jar \
my-main-jar.jar \
app_arg1 app_arg2
2.3.3 设置网络授权(Kerberos)
2.3.4 配置外部Shuffle服务
2.3.5 Spark通过oozie工作流启动
我们可以使用Apache Oozie来启动Spark应用程序,如果Spark配置了安全启动,则使用Spark安全令牌,如果没配置,则通过Oozie设置安全性。
有关Oozie安全设置参考网站.
对于Spark应用程序,必须为Oozie设置Oozie工作流,以请求该应用程序需要的所有令牌,包括:
- YARN资源管理器。
- 本地Hadoop文件系统。
- 任何用作I / O源或目标的远程Hadoop文件系统。
- Hive-如果使用的话。
- HBase-如果使用的话。
- YARN时间轴服务器(如果应用程序与此交互)。
为了避免Spark尝试(然后失败)获取Hive,HBase和远程HDFS令牌,必须将Spark配置设置为禁用服务的令牌收集。
Spark配置必须包括以下几行:
spark.security.credentials.hive.enabled false
spark.security.credentials.hbase.enabled false
spark.yarn.access.hadoopFileSystems必须取消配置选项。
2.3.5 用Spark History Server替换Spark Web UI
禁用应用程序UI时,可以将Spark History Server应用程序页面用作运行应用程序的跟踪URL。在安全群集上或减少Spark驱动程序的内存使用量可能是理想的。要通过Spark History Server设置跟踪,请执行以下操作:
- 在应用程序端,
spark.yarn.historyServer.allowTracking=true在Spark的配置中进行设置。如果禁用了应用程序的UI,这将告诉Spark使用历史服务器的URL作为跟踪URL。 - 在Spark History Server上,添加
org.apache.spark.deploy.yarn.YarnProxyRedirectFilter到spark.ui.filters配置中的过滤器列表。
请注意,历史记录服务器信息可能不是与应用程序状态有关的最新信息。
2.4 Kubernetes(k8s)上部署
参考文档
http://spark.apache.org/docs/latest/running-on-kubernetes.html
这个功能属于实验阶段,后面有可能会有修改。这里不演示了,有兴趣的自行查阅。
2.5Apache Mesos部署
参考文档
http://spark.apache.org/docs/latest/running-on-mesos.html
这个功能公司用的不多,学习的话直接参考官网文档就行了,我这里先不安装了。
三.编程
3.1 快速入门
3.1.1 安全性
默认情况下Spark是关闭安全的,所以如果您不配置则可能会被攻击。如何设置安全,请参阅 Spark安全性 。
3.1.2 使用Spark Shell交互
3.1.2.1 简单交互
这里主要以Scala语言进行介绍。
准备数据集(可以通过Hdfs和其它数据集来准备)
- 在本地创建一个数据文件
# mkdir -p /data/spark
# vim sparkData1.txt
#填写如下内容
hello world
What are you doing?
Nice to meet you~
hello YiMing
你好啊 一明
#按Esc ,然后输入:wq保存并退出
- 将数据提交到Hdfs的/user/root目录下
# hdfs dfs -put sparkData1.txt /user/root
启动:
# ./bin/spark-shell
scala> val textFile = spark.read.textFile("sparkData1.txt")
注意:使用spark.read.textFile()默认读取的是hdfs文件,也可以显示指定hdfs:// ,如果要读取本地文件加上file:// ,比如file:///data/spark/sparkData,或者使用 ./data/spark/sparkData
操作
scala> textFile.count()
res0: Long = 5 //计算出行数是5行
scala> textFile.first()
res2: String = hello world //查询出第一行的内容
我们可以通过过滤操作创建新的数据集
scala> val linesWithSpark = textFile.filter(line => line.contains("hello world"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
scala> linesWithSpark.count()
res4: Long = 1 //可以看到存在一行
我们可以将过滤动作和计算count链接在一起
scala> textFile.filter(line => line.contains("hello world")).count()
res5: Long = 1
3.1.2.2 数据集交互
scala> textFile.map(line=>line.split(" ").size).reduce((a,b)=>if(a>b) a else b)
res8: Int = 4
通过导入类库,来实现计算
scala> import java.lang.Math
import java.lang.Math
scala> textFile.map(line=>line.split(" ").size).reduce((a,b)=>Math.max(a,b))
mapList: Int = 4
使用spark实现MapReduce流
scala> val wordCounts=textFile.flatMap(line=>line.split(" ")).groupByKey(identity).count()
wordCounts: org.apache.spark.sql.Dataset[(String, Long)] = [value: string, count(1): bigint]
scala> wordCounts.collect()//把结果打印出来
res4: Array[(String, Long)] = Array((doing?,1), (Nice,1), (你好啊,1), (you,1), (一明,1), (YiMing,1), (hello,2), (are,1), (meet,1), (What,1), (world,1), (to,1), (you~,1))
指定缓存数据
scala> textFile.cache()
res6: textFile.type = [value: string]
scala> textFile.count()
res7: Long = 5
scala> textFile.count()
res8: Long = 5
3.1.3 Spark计算Demo
建立一个sbt项目,起名SimpleApp,并在build.sbt里面配置如下内容
name := "SimpleApp"
version := "0.1"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.5"
右键scala文件夹->New->Scala Class 选择Object,起名Simple 确定
添加如下代码
def main(args: Array[String]): Unit = {
val rootPath= System.getProperty("user.dir")//获取项目根目录
var bookFilePath = System.getProperty("user.dir") + "\\data\\Book"; //拼接路径
val spark = SparkSession.builder.appName("SimpleApp").getOrCreate()//获取SparkSession
val bookData = spark.read.textFile(bookFilePath).cache() //获取文件内容并缓存
val hei = bookData.filter(line => line.contains("黑")).count() //计算文件中包含“黑”的行数
println(hei)
spark.stop()
}
在项目根目录下创建一个data文件夹,并在里面添加一个Book文件,注意没有后缀哦。在 Book里面添加如下内容:
这世界既残酷也温柔 22
唐骏转 44
增长黑客 11
蓝筹孩子 55
富爸爸穷爸爸 21
未来世界的幸存者 44
智慧农业 13
工业4.0 81
厚黑学 66
配置本地运行:
选择Run->Edit Configuratioins,在VM Options添加-Dspark.master=local参数。
然后运行就可以看到结果了,结果是2就没问题了。
3.2 RDD编程指南
3.2.1 前言
Spark提供了弹性分布式集(RDD)和共享变量。
RDD是一种分布式的跨节点的数据集,可以通过HDFS,文件系统转换得到。
共享变量就是将一个变量的副本分发给运行的任务。共享变量共有两种,一种是广播变量(broadCast),一种是累加器(accumulator)。
RDD中有个概念叫宽依赖,窄依赖。如果父RDD和子RDD是一对一或者多对一,则是窄依赖,窄依赖之间的RDD属于同一个Stage。如果父RDD对应多个子RDD,这个时候就发生了Shuffler操作,这样的两个RDD叫宽依赖,宽依赖会执行断开操作,及两个RDD属于不同Stage。
Stage分为ShuffleMapStage和ResultStage,当发生Shuffle时才会有ShuffleStage。
3.2.2 配置代码环境
PS:Spark 2.4.5所兼容的Scala是2.12.X。
使用maven依赖添加以下内容:
spark依赖
groupId=org.apache.spark
artifactId=spark-core_2.12
version=2.4.5
haddop hdfs依赖
groupId=org.apache.hadoop
artifactId=hadoop-client
version=2.6.5
程序中导入
Scala导入
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
Java导入:
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.SparkConf;
3.2.3 初始化Spark
在使用Spark的第一件事当然是创建SparkContext,但是在创建SparkContext之前,要先创建SparkConf对集群进行配置。
Scala初始化:
val conf=new SparkConf().setAppName("RDDDemo1").setMaster("local")
new SparkContext(conf)
Java初始化:
SparkConf conf = new SparkConf().setAppName("RDDDemo1").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
setAppName里面填写应用显示的名字,setMaster填写Standalone,Spark,Kubernetes的链接,但是一般都在使用submit命令的时候手动指定,而不是写死。在本地测试的话,填写'local'就行了。
3.2.3.1 Spark Shell介绍
在Spark Shell中,默认为您创建了一个特殊的可识别解释器的SparkContext sc。制作自己的SparkContext将不起作用。
另外上面2.2.8已经做了详细介绍,可以参考。
3.2.4 弹性分布式数据集(RDDs)
3.2.4.1 并行执行Array
通过sparkcontext的parallelize方法创建并行集合。
Scala实现:
val data=Array(1,2,3,4)
val distData=sc.parallelize(data,10)
Java实现:
List<Integer> data = Arrays.asList(1, 2, 3, 4);
JavaRDD<Integer> distData = sc.parallelize(data);
创建后分布式数据集(distData)就可以并行操作。 例如,我们可能会调用distData.reduce((a, b) => a + b)以添加数组的元素。Spark将为每一个分区运行一个任务,默认每个CPU是2-4个分区,通常Spark会根据您的集群手动设置分区数,当然了也可以手动指定,比如上面我指定的10。
3.2.4.2 使用外部数据集
Spark可以从Hadoop支持的任何存储(hdfs,cassandra,hbase,本地文件)创建分布式数据集。
比如:
scala实现:
scala> val distFile = sc.textFile("data.txt")
distFile: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[10] at textFile at <console>:26
Java实现:
JavaRDD<String> distFile = sc.textFile("data.txt");
有关使用Spark读取文件的一些注意事项。
- 如果使用本地文件路径,还必须在Worker上访问该文件。则必须将文件复制到所有Worker服务器,或者安装网络共享文件系统。
- 文件路径可以使用通配符:比如:/data/*.txt
- 该txtFile还可以使用第二个参数控制分区数。默认情况,Spark为每个块创建一个分区(HDFS块默认值为128M),但是您可以设置更大的值来请求更大数量的分区。
除了文本文件,Spark的API还支持其它几种数据格式:
-
SparkContext.wholeTextFiles使您可以读取包含多个文本文件的目录。
-
读取序列化文件使用sequenceFile
-
对于其它Hadoop InputFormat,还可以使用SparkContext.hadoopRDD方法
-
RDD操作
RDD支持两种类型的操作:transformation和action。例如map是一个转换,将每个数据集传递给一个函数。reduce是一个动作,需要将计算结果返回。
Spark所有的transformation都是惰性的,因为它不会立即计算结果。仅当应用程序需要将结果返回时,才进行转换。
-
基本
为了说明RDD基础,请考虑下面程序
Scala版:
val conf = new SparkConf().setAppName("test").setMaster("local") val sc = new SparkContext(conf) val data = sc.textFile("file:///F:\\Code\\Scala\\SparkTest\\data\\words") val lineLength = data.map(line => line.length).persist() val totalLength = lineLength.reduce((a, b) => a + b) println(totalLength)
上面的程序给words里面的所有字数做了一个汇总。persist是对数据进行缓存,这个时候还没真正执行,当时候reduce的时候需要返回结果了,这个时候才会去执行map。
-
将函数传递给Spark
例如:
Scala实现:
val data = sc.textFile("file:///F:\\Code\\Scala\\SparkTest\\data\\words") val lineLengths = data.map(line => line.length).map(line=>addOne(line))//计算每行的长度,并且每行都加1 val totalLength=lineLengths.reduce((a,b)=>a+b)//统计总的长度def addOne(n: Integer): Integer = { n + 1 }Java实现:
JavaRDD<String> lines = sc.textFile("file:///F:\\Code\\Scala\\SparkTest\\data\\words"); JavaRDD<Integer> addOneLine = lines.map(line -> addOne(line));//计算每行的长度,并且每行都加1 int totalLength = addOneLine.reduce((a, b) -> a + b);//统计总的长度public static Integer addOne(String str) { return str.length() + 1; }-
闭包
Spark的难点之一就是跨集群执行时了解它的作用范围和生命周期。如下面例子:
-
例子
Scala代码:
var counter = 0 var rdd = sc.parallelize(data) // Wrong: Don't do this!! rdd.foreach(x => counter += x) println("Counter value: " + counter)Java代码:
int counter = 0; JavaRDD<Integer> rdd = sc.parallelize(data); // Wrong: Don't do this!! rdd.foreach(x -> counter += x); println("Counter value: " + counter);上面的例子运行得到的结果还是0,因为集群执行时,它分发的是副本,做的是副本累加。
要实现累加,我们可以使用累加器(accumulator),
val acc=sc.longAccumulator() rdd.foreach(x=>acc.add(x)) println(acc.value)上面就能正确打印结果了。当使用Accumulator的时候,注意使用一次action或者使用cache,persist切断之前的依赖。否则,累加器会持续累加。参考:( https://blog.csdn.net/zhaojianting/article/details/80228093 )
-
打印RDD
本地打印的时候,直接foreach循环就打印了,而在集群上打印,则需要把数据进行一次收集,要不计算的结果不会主动返回给Driver的。
-
-
3.2.4.2.1转换键值对并使用
以打印每行出现的次数为例:
Scala实现:
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:///F:\\Code\\Scala\\SparkTest\\data\\words")
val mapLine = lines.map(line => (line, 1))//得到一个key,value数组
val reduceLine = mapLine.reduceByKey((a, b) => a + b)//得到一个key,value数组
reduceLine.foreach(println)
Java实现:
JavaPairRDD<String, Integer> mapPairLine = lines.mapToPair(s -> new Tuple2(s, 1));//得到一个key,value数组
JavaPairRDD<String, Integer> reducePairLine = mapPairLine.reduceByKey((Integer a, Integer b) -> a + b);//得到一个key,value数组
Map<String, Integer> countMap = reducePairLine.collectAsMap();
for (Map.Entry<String, Integer> entry : countMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
3.2.4.2.2Transformations(算子)
| TransFormation | 说明 |
|---|---|
| map(func) | 返回一个新的数据集,该数据集通过执行fun函数形成的。 |
| filter(func) | 返回一个新的数据集,该数据集返回执行fun函数为true的数据形成的。 |
| flatMap(func) | 与map相似,但是每行都可以映射到0或多个输出项。 |
| mapPartitions(func) | 与map相似,但是分别在RDD的每个分区上运行,因此fun在类型T的RDD上运行必须为Iterator |
| mapPartitionsWithIndex(func) | 与mapPartitions相似,但它还为func提供表示分区索引的整数值,因此当在类型T的RDD上运行时,func必须为(Int,Iterator |
| sample(withReplacement, fraction, seed) | 对数据进行随机采样。withReplacementde代表是否有放回抽样。fraction如果是0.几那么就代表抽中百分比,如果是1,2之类的整数,代表每个元素随机抽中的次数。 |
| union(otherDataset) | 并集 |
| intersect(otherDataset) | 交集 |
| distinct([numPartitions]) | 返回不同的元素 |
| groupByKey([numPartitions]) | 根据key进行分组。例如:val rdd = sc.parallelize(List((1, 3), (4, 7), (1, 86))) val groupData = rdd.groupByKey() 这样将3和86归为1,7归为4 |
| reduceByKey(func, [numPartitions]) | 根据key合并分组。例如:val rdd = sc.parallelize(List((1, 3), (4, 7), (1, 86))) val reduceData = rdd.reduceByKey((a, b) => a + b) 这样就会得到1,89 4,7 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | 设定一个初始值和两个函数,在初始值的基础上结合两个函数对原始数据进行操作。例如:val rdd = sc.parallelize(List(1, 2, 3, 4)) val result = rdd.aggregate(1)(add1, add2) //会先通过初始值1+值1,2,3,4计算出值为11,然后11带入add2初始值1+11=12 def add1(p1: Int, p2: Int) = { p1 + p2 } def add2(p1: Int, p2: Int) = |
| sortByKey([ascending], [numPartitions]) | 根据key进行排序 |
| join(otherDataset, [numPartitions]) | 将两组相同key的值链接到一起组成新的键值对。 |
| cogroup(otherDataset, [numPartitions]) | 在(K,V)和(K,W)类型的数据集上调用时,返回(K,(Iterable |
| cartesian(otherDataset) | 在类型T和U的数据集上调用时,返回(T,U)对(所有元素对)的数据集。比如:(1,2)和(3) 会返回(1,3)(2,3)组合 |
| pipe(command, [envVars]) | 可以进行外部程序调用。比如调用python:val scriptpath="/tmp/test/test.py" println(rddData.pipe(scriptpath).collect().toList) |
| coalesce(numPartitions) | 将RDD分区减少到numPartitions。 |
| repartition(numPartitions) | 在RDD中随机重排以获得更多或更少的分区。 |
| repartitionAndSortWithinPartitions(partitioner) | 根据给定的分区程序对RDD进行重新分区,并在每个分区结果中,按其键进行排序。 |
3.2.4.2.3Actions(算子)
| Action | 说明 |
|---|---|
| reduce(func) | 使用func函数聚合数据集元素。 |
| collect() | 在driver中收集所有元素并返回。通常收集较小数据集时候用。 |
| count() | 返回数据集中的元素数。 |
| first() | 返回第一个元素,类似于(take(1)) |
| take(n) | 返回n个元素。 |
| takeSample(withReplacement, num, [seed]) | 返回带有num个元素的随机取样数据。withReplacement代表是否重复提取。 |
| takeOrdered(n, [ordering]) | 获取排序后的前几个数据 |
| saveAsTextFile(path) | 将数据以文本文件的形势写入到本地文件系统,HDFS或其它支持Hadoop的系统中。 |
| saveAsSequence(path) | 将数据以SequenceFile形势保存在本地文件系统,HDFS或其它支持Hadoop的系统中。 |
| saveAsObjectFile(path) | 将数据以Object的形势保存。 |
| countByKey() | 作用于k,v类型,返回k,int统计value的数量。 |
| foreach(func) | 在数据集每个函数上运行func。 |
3.2.4.2.4PV例子
val conf = new SparkConf().setAppName("PVCalc").setMaster("local")
val sc = new SparkContext(conf)
val data = sc.textFile("./data/ipData")
val pv = data.map(line => (line.split(" ")(0), 1)).countByKey()
pv.foreach(println)
3.2.4.2.5UV例子
val conf = new SparkConf().setMaster("local").setAppName("uv")
val sc = new SparkContext(conf)
val data = sc.textFile("./data/ipData")
val uv = data.map(line => (line.split(" ")(0) + "_" + line.split(" ")(1))).distinct().map(line => (line.split("_")
(0), 1)).reduceByKey(_ + _).sortBy(_._2, false) //按照倒序进行排列,如果参数仅仅使用一次,可以用"_"代替,如上面的写法按照常规的应该写为.sortBy(line=>line._2)
// ,如果有多个参数出现一次,可以使用"_*"代替,比如sum(1 to 5:_*)
uv.foreach(println)
参考资料:
idea如何设置自动换行: https://blog.csdn.net/zwj_jyzl/article/details/98473864
Scala中的_ 和 _*分别代表什么?: https://blog.csdn.net/wyz0516071128/article/details/81042667
3.2.4.2.6 Shuffle操作
-
背景
运行reduceBykey等操作需要在集群上拉取数据。
-
性能影响
由于大量的磁盘操作,于是考虑使用内存,但是内存容量达到一定级别就会持久化,这样还是很浪费性能的。
3.2.4.2.7 持久化RDD
- 存储级别
提供了几种持久化级别。
| Storage Level | 说明 |
|---|---|
| MEMORY_ONLY(默认) | 将RDD作为反序列化存在RDD中。如果RDD不能完全缓存,则缓存一部分。 |
| MEMORY_AND_DISK | 将RDD作为反序列化存在RDD中。如果RDD不能完全缓存,则都存在磁盘中。 |
| MEMORY_ONLY_SER (Java and Scala) | 将RDD序列化为JAVA对象。这样会更节省时间,但是读取时很耗费CPU。 |
| MEMORY_AND_DISK_SER (Java and Scala) | 与MEMORY_ONLY_SER类似,但是内存存不开会都存入磁盘。 |
| DISK_ONLY | 将RDD分区存在磁盘。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 与DISK_ONLY类似,但是在两个集群节点上复制每个分区,及存两份。 |
| OFF_HEAP (experimental) | 与MEMORY_ONLY_SER类似,但是将数据存的是堆外存。 |
- 删除数据
可以等待LRU规则自动释放,也可以调用RDD.unpersist()手动释放。
3.2.5 共享变量
- 广播变量
对所有集群进行广播数据。
Sava实现:
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.value
Java实现:
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3});
broadcastVar.value();
这样就能在任何节点上获取。
- 累加器
可以对集群中的数据进行累加。
Scala案例:
val accum=sc.longAccumulator
data.map{x=>accum.add(x);}
Java案例:
LongAccumulator accum = jsc.sc().longAccumulator();
data.map(x -> { accum.add(x); return f(x); });
3.2.6单元测试
Spark非常适合使用任何流行的单元测试框架进行单元测试。 只需在测试中创建一个SparkContext,并将主URL设置为local,运行您的操作,然后调用SparkContext.stop()将其拆解。 确保您在finally块或测试框架的tearDown方法中停止上下文,因为Spark不支持在同一程序中同时运行的两个上下文。
3.2.7SparkConfig(配置)
-
Spark属性配置
-
通过编程配置(主要设置SparkConf),举例:
val conf = new SparkConf() .setMaster("local[2]") .setAppName("CountingSheep") -
提交的时候进行指定,举例:
./bin/spark-submit --name "My App" --master local[4] -
在conf/spark-defaults.conf 中进行配置,每行包含一个键和一个由空格分隔的值,举例:
spark.master spark://5.6.7.8:7077 spark.executor.memory 4g spark.eventLog.enabled true spark.serializer org.apache.spark.serializer.KryoSerializer
-
-
Spark环境变量配置
在./conf/spark-env.sh中进行配置,举例:
export JAVA_HOME=/opt/java/jdk1.8.0_221 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=tuge1:2181,tuge2:2181,tuge3:2181 -Dspark.deploy.zookeeper.dir=/opt/spark" export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} -
Spark日志配置
在log4j.properties中配置。
我们可以直接复制 ./conf/log4j.properties.template进行配置。举例:
mc log4j.properties.template log4j.properties
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR
3.3 Spark SQL,Datasets和DataFrames编程指南
PS:Spark SQL是在Shark Hive上面改进,底层完全自己实现,依赖于Hive的部分有MetaStore和SQL转换为Spark的一些内容。
3.3.1入门
3.3.1.1 SparkSession
SparkSession是所有功能的入口点,要创建SparkSession,只需要使用SparkSession.builder();即可
Scala举例:
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
Java举例:
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
在examples / src / main / scala / org / apache / spark / examples / sql / SparkSQLExample.scala” 可以找到示例源码。
3.3.1.2 创建DataFrames
使用SparkSession可以从现有的RDD,Hive或Spark数据流中读取数据。
例如从JSON文件中读取数据。
Scala举例:
val spark = SparkSession.builder.appName("sparkSession Study").master("local").getOrCreate()
val txtData= spark.read.textFile("./data/words")
txtData.show()//打印结果
Java举例:
SparkSession spark = SparkSession.builder().appName("SparkSession案例").master("local").getOrCreate();
Dataset<String> txtData = spark.read().textFile("./data/words");
txtData.show();//打印结果
显示结果:
+-------------+
| value|
+-------------+
| hello YiMing|
|hello XiaoBei|
| hi LiSi|
| hello|
| hello|
+-------------+
可以在 "examples/src/main/java/org/apache/spark/examples/sql/JavaSparkSQLExample.java" 找到案例。
3.3.1.3 DataSet操作
people文件内容:
{"name":"Michael"}{"name":"Andy", "age":30}{"name":"Justin", "age":19}
Scala演示:
val spark = SparkSession.builder.appName("sparkSession Study").master("local").getOrCreate()
import spark.implicits._ //使用$符号需要此导入
val df = spark.read.json("./data/people")
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
Java演示:
SparkSession spark = SparkSession.builder().appName("SparkSession案例").master("local").getOrCreate();
Dataset<String> df = spark.read().textFile("./data/people");
df.printSchema();
df.groupBy("age").count().show();
df.select("name").show();
df.filter(col("age").gt(21)).show();
df.select(col("name"),col("age").plus(2)).show();
更多代码可在 examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala 找到。
3.3.1.4 以编程方式SQL查询
Scala演示:
val spark = SparkSession.builder().appName("spark SQL Demo").master("local").getOrCreate()
val data = spark.read.json("./data/people")
data.createOrReplaceTempView("person")
val dfSql = spark.sql("select age from person")
dfSql.show()
// +----+
// | age|
// +----+
// |null|
// | 30|
// | 19|
// +----+
Java演示:
SparkSession ss = SparkSession.builder().appName("spark demo ").master("local").getOrCreate();
Dataset<Row> ds = ss.read().text("./data/people");
ds.createOrReplaceTempView("people");
Dataset<Row> dsSql = ss.sql("select *from people");
dsSql.show();
3.3.1.5 全局临时视图
SparkSQL是临时视图作用域的,如果创建它的会话终止,它将消失。如果要在所有会话中共享一个临时视图,直到Spark程序终止,则可以创建全局临时视图。全局临时视图数据库与global_temp关联。例如,选择select *from global_temp view1。
Scala演示:
val spark = SparkSession.builder().appName("spark SQL Demo").master("local").getOrCreate()
val data = spark.read.json("./data/people")
data.createGlobalTempView("people")
spark.sql("select *from global_temp.people").show() //打印结果
spark.newSession().sql("select *from global_temp.people").show()//打印结果
Java演示:
SparkSession ss = SparkSession.builder().appName("spark demo ").master("local").getOrCreate();
Dataset<Row> ds = ss.read().text("./data/people");
ds.createGlobalTempView("people");
ss.sql("select *from global_temp.people").show();
ss.newSession().sql("select *from global_temp.people").show();
在examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala查看示例。
3.3.1.6 创建Datasets
Dataset和RDD相似,但是不是使用Java和Kryo序列化,而是有专门的Encoder对象进行序列化。虽然Encoder和通常的序列化一样将对象转换为字节,但是Encoder是动态生成的代码,并使用一种格式,该格式允许过滤,排序,哈希处理等,并且处理过程中无需反序列化。
Scala举例:
val spark = SparkSession.builder().appName("spark SQL Demo").master("local").getOrCreate()
import spark.implicits._
//示例1:将集合转换为DataSet
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect().foreach(println)
// 2
// 3
// 4
//示例2:将文件内容转换为对象
val peopleData = spark.read.json("./data/people")
val peopleDS = peopleData.as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
3.3.1.7 与RDD互操作
Spark SQL支持两种将现有的RDD转换为Dataset的方法。一种是通过反射,这种代码简洁,适用于运行前就了解架构。另一种是通过编程接口指定,这种代码比较长,这种适用于运行时才了解架构的数据集。
-
使用反射推断架构
words文件内容:
张三 23
小贝 24
王五 55
小明 16
小强 11Scala实现:
val spark = SparkSession.builder().appName("spark SQL Demo").master("local").getOrCreate() import spark.implicits._ val peopleDF = spark.sparkContext .textFile("./data/words") .map(_.split(" ")) .map(attributes => Person(attributes(0), attributes(1).toInt)) .toDF() peopleDF.createOrReplaceTempView("people") val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19") teenagersDF.map(teenager => "Name: " + teenager(0)).show() teenagersDF.map(teenager => "Name:" + teenager.getAs("name")).show() // +---------+ // | value| // +---------+ // |Name:小明| // +---------+ println("映射完后打印") implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]] //指定编码 teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect().foreach(println) //Map(name -> 小明, age -> 16) -
以编程接口方式指定架构
val spark = SparkSession.builder().appName("spark demo").master("local").getOrCreate() //首先创建一个RDD //根据第一步创建的RDD创建struct //将struct应用于RDD val wordRDD = spark.sparkContext.textFile("./data/words") val structString = "name age" val structRDD = structString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true)) val schema = StructType(structRDD) val rowRDD = wordRDD.map(line => line.split(" ")).map(line => Row(line(0), line(1))) val wordsDF = spark.createDataFrame(rowRDD, schema) wordsDF.createOrReplaceTempView("people") val select = spark.sql("select name,age from people") implicit val encoder=org.apache.spark.sql.Encoders.STRING//添加字符串类型编码器 select.map(attributes => "Name: " + attributes(0)).show()结果:
+----------+ | value| +----------+ |Name: 张三| |Name: 小贝| |Name: 王五| |Name: 小明| |Name: 小强| +----------+
3.3.1.8 自定义聚合函数
-
定义未类型化的聚合函数
Java演示:
MyAverage.class
import java.util.ArrayList; import java.util.List; import org.apache.spark.sql.Row; import org.apache.spark.sql.expressions.MutableAggregationBuffer; import org.apache.spark.sql.expressions.UserDefinedAggregateFunction; import org.apache.spark.sql.types.DataType; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; /** * 求年龄的平均数 * 这里我们使用自定义的聚合函数实现,自定义函数仅仅需要继承UserDefinedAggregateFunction * 然后告诉输入参数类型,以及中间运行参数类型 */ public class MyAverage extends UserDefinedAggregateFunction { private StructType inputSchema; //输入参数结构 (参数:年龄) private StructType bufferSchema; //运行时参数结构(参数1:年龄加权,参数2:人数) public MyAverage() { List<StructField> inputFields = new ArrayList<>(); inputFields.add(DataTypes.createStructField("inputColumn", DataTypes.LongType, true)); inputSchema = DataTypes.createStructType(inputFields); List<StructField> bufferFields = new ArrayList<>(); bufferFields.add(DataTypes.createStructField("sum", DataTypes.LongType, true)); bufferFields.add(DataTypes.createStructField("count", DataTypes.LongType, true)); bufferSchema = DataTypes.createStructType(bufferFields); } /** * 输入参数类型 * * @return */ @Override public StructType inputSchema() { return inputSchema; } /** * 中间运行参数类型 * * @return */ @Override public StructType bufferSchema() { return bufferSchema; } /** * 返回值类型 * * @return */ @Override public DataType dataType() { return DataTypes.DoubleType; } /** * 确定的结构 * * @return */ @Override public boolean deterministic() { return true; } /** * 初始化中间运行参数都为0 * * @param buffer */ @Override public void initialize(MutableAggregationBuffer buffer) { buffer.update(0, 0L); buffer.update(1, 0L); } /** * 更新中间运行参数,进行加权 * * @param buffer 中间数据 * @param input 输入的一行行数据 */ @Override public void update(MutableAggregationBuffer buffer, Row input) { if (!input.isNullAt(0)) { long updatedSum = buffer.getLong(0) + input.getLong(0); long updatedCount = buffer.getLong(1) + 1; buffer.update(0, updatedSum); buffer.update(1, updatedCount); } } /** * 合并多个分区数据 * * @param buffer1 * @param buffer2 */ @Override public void merge(MutableAggregationBuffer buffer1, Row buffer2) { long mergedSum = buffer1.getLong(0) + buffer2.getLong(0); long mergedCount = buffer1.getLong(1) + buffer2.getLong(1); buffer1.update(0, mergedSum); buffer1.update(1, mergedCount); } /** * 计算最终结果 * 年龄总和/人数 * * @param buffer * @return */ @Override public Object evaluate(Row buffer) { return ((double) buffer.getLong(0)) / buffer.getLong(1); } }调用:
public static void main(String[] args) { SparkSession spark = SparkSession.builder().appName("spark demo ").master("local").getOrCreate(); spark.udf().register("myAverage", new MyAverage()); Dataset<Row> df = spark.read().json("./data/people.json"); df.createOrReplaceTempView("employees"); df.show(); // +----+-------+ // | age | name | //+----+-------+ // | null | Michael | //|30 | Andy | //|19 | Justin | //|20 | RYJ | //|17 | Justin | //+----+-------+ Dataset<Row> result = spark.sql("SELECT myAverage(age) as average_salary FROM employees"); result.show(); //|average_salary| // +--------------+ // | 21.5| // +--------------+ }people.json内容:
{"name":"Michael"} {"name":"Andy", "age":30} {"name":"Justin", "age":19} {"name":"RYJ", "age":20} {"name":"Justin", "age":17}Scala演示:
MyAverage.scala
import org.apache.spark.sql.Row import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction} import org.apache.spark.sql.types._ class MyAverage extends UserDefinedAggregateFunction { def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil) def bufferSchema: StructType = { StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil) } // 返回值类型 def dataType: DataType = DoubleType // 此函数是否始终在相同的输入上返回相同的输出 def deterministic: Boolean = true //初始化 def initialize(buffer: MutableAggregationBuffer): Unit = { buffer(0) = 0L buffer(1) = 0L } // 更新中间结果 def update(buffer: MutableAggregationBuffer, input: Row): Unit = { if (!input.isNullAt(0)) { buffer(0) = buffer.getLong(0) + input.getLong(0) buffer(1) = buffer.getLong(1) + 1 } } // 合并中间结果 def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = { buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0) buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1) } // 返回值 def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1) }调用:
val spark = SparkSession.builder().appName("UDAFDemo").master("local").getOrCreate() spark.udf.register("myAverage",new MyAverage) val df = spark.read.json("./data/people.json") df.createOrReplaceTempView("people") df.show() // +----+-------+ // | age| name| // +----+-------+ // |null|Michael| // | 30| Andy| // | 19| Justin| // | 20| RYJ| // | 17| Justin| // +----+-------+ val result = spark.sql("SELECT myAverage(age) as average_salary FROM people") result.show() // +--------------+ // |average_salary| // +--------------+ // | 21.5| // +--------------+ -
定义类型化的聚合函数
Scala演示:
MyAverage2.scala
import org.apache.spark.sql.{Encoder, Encoders, SparkSession} import org.apache.spark.sql.expressions.Aggregator case class Employee(name: String, age: Long) case class Average(var sum: Long, var count: Long) object MyAverage2 extends Aggregator[Employee, Average, Double] { //初始值 def zero: Average = Average(0L, 0L) //加权 def reduce(buffer: Average, employee: Employee): Average = { buffer.sum += employee.age buffer.count += 1 buffer } // 分区合并 def merge(b1: Average, b2: Average): Average = { b1.sum += b2.sum b1.count += b2.count b1 } // 计算结果 def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count // buffer数据类型 def bufferEncoder: Encoder[Average] = Encoders.product // 返回数据类型 def outputEncoder: Encoder[Double] = Encoders.scalaDouble }Main方法调用
def main(args: Array[String]): Unit = { val spark=SparkSession.builder().master("local").getOrCreate() import spark.implicits._ val ds= spark.read.json("./data/people.json").as[Employee] ds.show() // +---+------+ // |age| name| // +---+------+ // | 30| Andy| // | 19|Justin| // | 20| RYJ| // | 17|Justin| // +---+------+ val averageSalary= MyAverage2.toColumn.name("age") val result=ds.select(averageSalary) result.show() // +----+ // | age| // +----+ // |21.5| // +----+ }
3.3.2数据源
PS:Spark SQL可以通过DataFrame对接各种数据源进行操作。DataFrame可以使用关系转换进行操作,还可以创建临时视图。将DataFrame创建为临时视图可以运行SQL查询。本节介绍了使用Spark加载和保存数据源的一般方法,然后介绍了可用内置数据源的特定选项。
3.3.2.1 通用加载/保存功能
由于咨询了一些朋友,都说公司用scala,所以下面就用scala实现了。
公共代码部分:
val spark = SparkSession.builder().appName("test Scala").master("local").getOrCreate()
-
手动指定操作的文件格式
读取parquet格式文件,并提取保存为text格式。
val peopleDF=spark.read.format("parquet").load("./data/namesAndAges.parquet") peopleDF.select("name").write.format("text").save("./data/names.text") -
直接在文件上运行SQL
除了使用Read API运行API外,还可以直接使用SQL查询文件。
val sqlDF = spark.sql("SELECT * FROM parquet.`data/namesAndAges.parquet`") -
保存模式(Save Modes)
Scala/Java Any Language Meaning SaveMode.ErrorIfExists (default) "error" or "errorifexists" (default) 如果文件存在则报错。 SaveMode.Append "append" 如果有内容,则追加。 SaveMode.Overwrite "overwrite" 如果有内容,则覆盖。 SaveMode.Ignore "ignore" 如果有内容,则不作任何操作。 代码示例:
fsWords.write.format("parquet").mode(SaveMode.Overwrite).save("./data/namesAndAges.parquet") -
保存永久表
除了使用save将数据保存文件,还可以使用saveAsTable将数据保存在hive里面。如果不指定路径,则保存默认路径,删除表时会自动删除。当然了,还可以使用
df.write.option("path", "/some/path")指定路径。如果手工指定路径的话,默认不会收集metastore信息,需要手动在控制台执行MSCK REPAIR TABLE命令。 -
分组,排序和分区
分组的数据必须保存在table表里面,示例如下:
val fsWords = spark.read.format("json").load("./data/people.json") //加载数据 val fsTable = fsWords.write.bucketBy(1, "name").sortBy("age").saveAsTable("people")//保存到表 spark.sql("select *from people").show()//展示数据分区示例代码:
usersDF.write.partitionBy("favorite_color").format("parquet").save("namesPartByColor.parquet")分区和分桶一起使用:
usersDF .write .partitionBy("favorite_color") .bucketBy(42, "name") .saveAsTable("users_partitioned_bucketed")代码可参考: "examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala"
3.3.2.2 Parquet 文件
上面已经演示了通用的加载方法,这里还有专门针对Parquet的加载方法,其实也就是做了一步封装。
-
以编程方式加载数据
Scala演示如下:
val jsonData = spark.read.json("./data/people.json") //加载JSON文件 jsonData.write.mode(SaveMode.Ignore).parquet("./data/people.parquet") //将文件保存为parquet格式 val parquetData = spark.read.parquet("./data/people.parquet") //获取parquet文件 parquetData.createOrReplaceTempView("people") //将内容转换为临时表 val sparkSql = spark.sql("select name,age from people where age>20") //使用SQL查询大于20的人 implicit val encoder = org.apache.spark.sql.Encoders.STRING //声明类型 sparkSql.map(attributes => "Name: " + attributes(0) + ",Age:" + attributes.getAs("age")).show() //打印 -
分区发现
可以将文件放在多个分区里面,然后使用spark.read.parquet,spark.read.load 加载数据,Spark SQL会自动提取分区数据。
提取的数据会自动解析类型,如果不想自动解析的话,可以在SparkSession构建的时候配置 spark.sql.sources.partitionColumnTypeInference.enabled 为false。
文件会根据分区路径加载下面的数据。
-
文件合并
合并两个格式相同的文件,默认合并 功能是 关闭的,可以通过设置mergeSchema为true开启。例如:
import spark.implicits._ val squaresDF = spark.sparkContext.makeRDD(1 to 5).map(i => (i, i * i)).toDF("value", "square") squaresDF.write.parquet("./data/squaresDF/key=1") //保存在key标识符为1的文件夹内 val cubesDF = spark.sparkContext.makeRDD(6 to 10).map(i => (i, i * i)).toDF("value", "cube") cubesDF.write.parquet("./data/squaresDF/key=2") //保存在key标识符为2的文件夹内 val mergedDF = spark.read.option("mergeSchema", true).parquet("./data/squaresDF") //读取文件 mergedDF.printSchema() //打印结构 // root // |-- value: integer (nullable = true) // |-- square: integer (nullable = true) // |-- cube: integer (nullable = true) // |-- key: integer (nullable = true) -
Hive Metastor Parquet默认支持技术
Spark在读取Hive 的Metastor Parquet文件时,使用的是Spark SQL自己的Parquet支持,而不是使用Hive Serde进行序列化操作。
可以通过
spark.sql.hive.convertMetastoreParquet进行配置。 -
读取hive表时,数据变化,需要手动刷新表
读取hive的parquet时,通常会缓存下提高读取性能。
这个时候当parquet文件数据增加时,并且不是通过spark sql添加的,而是hive自己或其它外部工具添加的,这个时候需要手动刷新缓存,如下:
spark.catalog.refreshTable("person"); -
parquet配置
可以在创建SparkSession时对parquet进行配置
Property Name Default Meaning spark.sql.parquet.binaryAsStringfalse 在编写parquet时,其它一些parquet系统,例如hive,impala和旧版的Spark Sql不会区分二进制和字符串,这个属性设置为ture告诉SparkSql将二进制转换为字符串。以提供系统兼容性。 spark.sql.parquet.int96AsTimestamptrue 在编写parquet时,其它一些parquet系统,例如hive和impala,将时间戳存在INT96里面,该标识告诉Saprk Sql将INT96转换为时间戳,以提供系统兼容性。 spark.sql.parquet.compression.codecsnappy 指定压缩,可选择的值包括:none, uncompressed, snappy, gzip, lzo, brotli, lz4, zstd。 spark.sql.parquet.filterPushdowntrue 启用过滤优化。 spark.sql.hive.convertMetastoreParquettrue 设置false时,Spark SQL将使用Hive SerDe用于parquet。 spark.sql.parquet.mergeSchemafalse 合并所有收集的文件。 spark.sql.parquet.writeLegacyFormatfalse 设置为true,将将以Spark1.4及更早期版本的方式写入数据。
3.3.2.3 ORC文件
ORC是Hadoop生态圈的一个列式存储文件,最早产生于Hive,它和parquet相似,它旨在于降低存储空间时提高Hive的查询速度。有关它的配置如下:
| Property Name | Default | Meaning |
|---|---|---|
spark.sql.orc.impl |
native |
ORC实现的名称。 它可以是“ native”和“ hive”之一。 “ native”表示基于Apache ORC 1.4构建的本机ORC支持。 “ hive”是指Hive 1.2.1中的ORC库。 |
spark.sql.orc.enableVectorizedReader |
true |
设置为true,则在本机中使用矢量化解码。设置为false,则在本机中使用非矢量化解码。 |
3.3.2.4 JSON文件
Spark可以自动完成JSON类型的加载。使用SparkSession.read.json()就可以完成此转换。
例如:
val jsonData=spark.read.json("./data/people.json")
jsonData.createOrReplaceTempView("people")
spark.sql("select age from people").show()
3.3.2.5 Hive表
我们在编码之前,如果你使用maven的话,或者其它,要确认项目引入了spark-hive,否则一切都用不了。
使用hive不需要搭建环境,配置 spark.sql.warehouse.dir 就能直接运行。
简要代码如下:
val warehouseLocation = new File("spark-warehouse").getAbsolutePath
val spark = SparkSession
.builder()
.appName("hive demo")
.master("local")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport().getOrCreate()
import spark.sql
sql("create table if not exists src(id int,name string) row format delimited fields terminated by ' '")//创建表
sql("load data local inpath './data/words' overwrite into table src")//投放数据
sql("select name from src").show()
-
指定Hive存储格式
使用 CREATE TABLE src(id int) USING hive OPTIONS(fileFormat 'parquet') 定义。
Property Name Meaning fileFormat fileFormat是一种存储格式规范的软件包,其中包括“ serde”,“ input format”和“ output format”。 目前,我们支持6种文件格式:“ sequencefile”,“ rcfile”,“ orc”,“ parquet”,“ textfile”和“ avro”。 inputFormat, outputFormat 这2个选项将对应的 InputFormat和OutputFormat类的名称指定为字符串文字,例如 org.apache.hadoop.hive.ql.io.orc.OrcInputFormat。 这两个选项必须成对出现,如果已经指定fileFormat`选项,则不能指定它们。serde 此选项指定Serde类的名称。 当指定 fileFormat选项时,如果给定的fileFormat已经包含serde信息,则不要指定此选项。 当前,“ sequencefile”,“ textfile”和“ rcfile”不包含Serde信息,您可以将此选项与这3种fileFormats一起使用。fieldDelim, escapeDelim, collectionDelim, mapkeyDelim, lineDelim 这些选项只能与“文本文件” fileFormat一起使用。 它们定义了如何将定界文件读取为行。 -
与Hive Metastor不同版本进行交互
与Hive metastore的交互是Spark SQL对Hive的最重要支持之一,它使Spark SQL可以访问Hive表的元数据。 从Spark 1.4.0开始,使用以下描述的配置,可以使用Spark SQL的单个二进制版本来查询Hive元存储的不同版本。 请注意,与用于与Metastore进行通信的Hive版本无关,Spark SQL在内部将针对Hive 1.2.1进行编译,并将这些类用于内部执行(serdes,UDF,UDAF等)。
Property Name Default Meaning spark.sql.hive.metastore.version1.2.1Hive Metastore的版本。 可用的选项是0.12.0到2.3.3。 spark.sql.hive.metastore.jars用于实例化HiveMetastoreClient的jar的位置。 此属性可以是以下三个选项之一:
1.builtin
选用和Hive1.2.1捆绑在一起的
2.maven
使用maven下载jar
3.JVM标准路径
包括Hive和所有依赖项,一般用于生产。spark.sql.hive.metastore.sharedPrefixescom.mysql.jdbc,org.postgresql com.microsoft.sqlserver,oracle.jdbc共享类。 spark.sql.hive.metastore.barrierPrefixes(empty)使用前缀加载,例如:org.apache.spark.*
3.3.2.6JDBC到其它数据库
举例:
// Loading data from a JDBC source
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load()
val connectionProperties = new Properties()
connectionProperties.put("user", "username")
connectionProperties.put("password", "password")
val jdbcDF2 = spark.read
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
// Specifying the custom data types of the read schema
connectionProperties.put("customSchema", "id DECIMAL(38, 0), name STRING")
val jdbcDF3 = spark.read
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
// Saving data to a JDBC source
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save()
jdbcDF2.write
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
// Specifying create table column data types on write
jdbcDF.write
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties)
属性参照表:
| Property Name | Meaning |
|---|---|
| url | 要连接的JDBC URL指定。 mysql://localhost:3306/test?user=fred&password=secret |
| dbtable | 设置查询的数据表。 |
| query | 查询语句,例如:spark.read.format("jdbc").option("url", jdbcUrl).option("query", "select c1, c2 from t1").load() |
| driver | JDBC驱动URL配置。 |
| partitionColumn, lowerBound, upperBound | 设置分区数,这三个这顶的话 ,必须都设定。lowerBound和upperBound用于设置步幅。 |
| numPartitions | 表读写中并行处理的最大分区数,这也决定了JDBC连接的最大数量。 |
| queryTimeout | 查询超时设置,0表示没有限制。 |
| fetchsize | 每次读取文件的大小。适用于read。 |
| batchsize | 批处理大小,该大小决定每次往返插入多少行。默认是1000行。 |
| isolationLevel | 定义事物隔离级别,它可以是“ NONE”,“ READ_COMMITTED”,“ READ_UNCOMMITTED”,“ REPEATABLE_READ”或“ SERIALIZABLE”之一,对应于JDBC的Connection对象定义的标准事务隔离级别,默认值为“ READ_UNCOMMITTED”。此选项适用于write。 |
| sessionInitStatement | 这个选项用于执行在数据库进行会话后,执行自定义SQL语句之前。用于实现初始化。示例:option("sessionInitStatement", """BEGIN execute immediate 'alter session set "_serial_direct_read"=true'; END;""") |
| truncate | 这是与JDBC编写器相关的选项。用于wrie。 |
| cascadeTruncate | 这是与JDBC编写器相关的选项。用于wrie。 |
| createTableOptions | 创建数据表。(例如,“ CREATE TABLE t(名称字符串)ENGINE = InnoDB”) |
| createTableColumnTypes | 用于添加字段。应以与CREATE TABLE列语法相同的格式指定(例如:“名称CHAR(64),注释VARCHAR(1024)”),此选项用于write。 |
| customSchema | 指定读取模式的自定义数据类型,例如:("customSchema", "id DECIMAL(38, 0), name STRING") |
| pushDownPredicate | predicate是一个函数式接口,可以用于lambda接口和方法引用。此选项是用于启用或者禁用将数据推送给JDBC处理,默认是开启的,如果Spark处理predicate速度比较快的话,可以禁用掉。 |
3.3.2.7Avro文件
Avro是一个数据序列化系统,由Hadoop创始人 Doug Cutting 开发。
-
部署中
将spark-avro添加到spark-submit中
./bin/spark-submit --packages org.apache.spark:spark-avro_2.12:2.4.5 ...将spark-avro添加到spark-shell中
./bin/spark-shell --packages org.apache.spark:spark-avro_2.12:2.4.5 ... -
加载和保存功能
引入spark-avro依赖项,并在项目中声明
org.apache.spark.sql.avro举例:
val usersDF = spark.read.format("avro").load("examples/src/main/resources/users.avro") usersDF.select("name", "favorite_color").write.format("avro").save("namesAndFavColors.avro") -
to_avro()和from_avro()
通过from_avro处理数据,并通过to_avro向下传递,代码如下所示:
import org.apache.spark.sql.avro._ // from_avro需要JSON字符串格式的Avro模式 val jsonFormatSchema = new String(Files.readAllBytes(Paths.get("./examples/src/main/resources/user.avsc"))) val df = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("subscribe", "topic1") .load() // 1. 将Avro数据解码为结构; // 2. 按“ favorite_color”列过滤; // 3. 以Avro格式对“名称”列进行编码。 val output = df .select(from_avro('value, jsonFormatSchema) as 'user) .where("user.favorite_color == \"red\"") .select(to_avro($"user.name") as 'value) val query = output .writeStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("topic", "topic2") .start() -
数据源选项
可以通过DataFrameReader或DataFrameWriter上的option设置Avro的数据选项。
Property Name Default Meaning Scope avroSchema None 用于以JSON格式提供可选的Avro模式。 read and write recordName topLevelRecord 写入文件的时候,定义名称。 write recordNamespace "" 写入文件的时候,定义命名空间。 write ignoreExtension true 是否忽略扩展名。(带与不带.avro) read compression snappy 写入文件时,指定压缩解码器。支持的压缩解码器有 uncompressed,snappy,deflate,bzip2andxz。write -
配置
可以通过SparkSession上的setConf方法或通过SQL 运行set key=value来完成avro的配置。
Property Name Default Meaning spark.sql.legacy.replaceDatabricksSparkAvro.enabled true 设置为true,则将com.databricks.spark.avro映射到外部数据模块,以提供向后兼容。 spark.sql.avro.compression.codec snappy 指定压缩解码器,可选则的有:uncompressed, deflate, snappy, bzip2 and xz. spark.sql.avro.deflate.level -1 指定压缩级别,可选的数值为1-9和-1.默认是-1. -
与Databricks spark-avro兼容性
该Avro数据源模块最初来自Databricks的开源存储库spark-avro并与之兼容。
AvroDataFrameWriter和AvroDataFrameReader删除了,改用DataFrameWriter或DataFrameReader中的.format(“ avro”)。
-
Avro->Spark SQL转换支持的类型
Avro type Spark SQL type boolean BooleanType int IntegerType long LongType float FloatType double DoubleType string StringType enum StringType fixed BinaryType bytes BinaryType record StructType array ArrayType map MapType union See below 除了上面列出的类型之外,它还支持读取联合类型。 以下三种类型被视为基本联合类型:
union(int,long)将映射到LongType。
union(float,double)将被映射为DoubleType。
union(something,null),其中something是任何受支持的Avro类型。 这将被映射为与something相同的Spark SQL类型,并将nullable设置为true。 所有其他联合类型都被认为是复杂的。它还支持读取以下Avro逻辑类型:
Avro logical type Avro type Spark SQL type date int DateType timestamp-millis long TimestampType timestamp-micros long TimestampType decimal fixed DecimalType decimal bytes DecimalType -
Spark SQL支持的类型->Avro类型的转换
Spark SQL type Avro type Avro logical type ByteType int ShortType int BinaryType bytes DateType int date TimestampType long timestamp-micros DecimalType fixed decimal 您还可以使用选项avroSchema指定整个输出Avro模式,以便可以将Spark SQL类型转换为其他Avro类型。 默认情况下,不应用以下转换,并且需要用户指定的Avro模式:
Spark SQL type Avro type Avro logical type BinaryType fixed StringType enum TimestampType long timestamp-millis DecimalType bytes decimal
3.3.3性能调优
3.3.3.1 在内存中缓存数据
Spark SQL可以通过调用spark.catalog.cacheTable("tableName")或者调用dataFrame.cache()。然后,Spark SQL要查询必须的列。取消缓存使用spark.catlog.uncacheTable("tableName")。
可以使用setConf来设置缓存数据。
| Property Name | Default | Meaning |
|---|---|---|
spark.sql.inMemoryColumnarStorage.compressed |
true | 设置为true,Spark Sql将自动选择压缩器来进行压缩。 |
spark.sql.inMemoryColumnarStorage.batchSize |
10000 | 设置缓存的批处理大小。设置的越大越能提高缓存的处理和压缩效率。但是太大了会出现OOMs问题。 |
3.3.3.2 其它配置选项
以下选项也可以用于调整查询执行的性能。 随着自动执行更多优化,这些选项可能会在将来的版本中弃用。
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.files.maxPartitionBytes | 134217728 (128 MB) | read文件时,打包到单个分区的最大字节数。 |
| spark.sql.files.openCostInBytes | 4194304 (4 MB) | 可以同时扫描打开文件的总大小。 |
| spark.sql.broadcastTimeout | 300 | 广播超时时间。 |
| spark.sql.autoBroadcastJoinThreshold | 10485760 (10 MB) | 配置表的最大大小。 |
| spark.sql.shuffle.partitions | 200 | 配置join和aggregations时的分区数。 |
3.3.3.3 SQL查询的广播提示
join表时进行广播,例如:
import org.apache.spark.sql.functions.broadcast
broadcast(spark.table("src")).join(spark.table("records"), "key").show()
3.3.4 分布式SQL引擎
Spark SQL可以使用JDBC和ODBC进行调用,在这种模式下Spark SQL可以直接运行SQL,而无需其它代码。
3.3.4.1 运行Thrift JDBC/ODBC 服务器
运行以下命令来启动JDBC/ODBC。
./sbin/start-thriftserver.sh
使用以下./sbin/start-thriftserver.sh --help查看帮助,默认运行在localhost:10000端口。也可以手动配置:
export HIVE_SERVER2_THRIFT_PORT=<listening-port>
export HIVE_SERVER2_THRIFT_BIND_HOST=<listening-host>
./sbin/start-thriftserver.sh \
--master <master-uri> \
...
或运行时配置:
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=<listening-port> \
--hiveconf hive.server2.thrift.bind.host=<listening-host> \
--master <master-uri>
...
现在你可以使用beeline 对JDBC/ODBC进行测试:
./bin/beeline
使用以下命令进行连接:
beeline> !connect jdbc:hive2://localhost:10000
belline会要求您提供用户名和密码。在非安全模式下,用户名和密码空白即可。
通过将您的hive-site.xml,core-site.xml和hdfs-site.xml文件放在/conf中来完成配置。
JDBC支持通过Http传输发送Thrift RPC,可以在/conf下的hive-site.xml文件中进行启用:
hive.server2.transport.mode - Set this to value: http
hive.server2.thrift.http.port - HTTP port number to listen on; default is 10001
hive.server2.http.endpoint - HTTP endpoint; default is cliservice
要进行测试,可以使用beeline通过以下方式通过http进行测试。
beeline> !connect jdbc:hive2://<host>:<port>/<database>?hive.server2.transport.mode=http;hive.server2.thrift.http.path=<http_endpoint>
3.3.4.2 运行Spark SQL CLI
Spark SQL CLI是一种工具,可以在本地模式下运行Hive Metastore服务执行查询。使用以下命令打开:
./bin/spark-sql
3.4 Structured Streaming
3.4.1前言
结构化数据流是基于Spark Sql进行的一种流式计算框架。原来的架构延迟低至100毫秒,新架构能低至1毫秒。
3.4.2 简单演示
在执行程序前必须创建的结构就是Spark了。
//创建Spark
val spark = SparkSession
.builder()
.appName("hive demo")
.master("local")
.getOrCreate()
操作Streaming。
import spark.implicits._
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", "9999")
.load()
//从9999端口获取流数据
val words = lines.as[String].flatMap(_.split(" ")) //分隔数据
val wordCount = words.groupBy("value").count() //计算值的数量
val query = wordCount.writeStream.outputMode("complete").format("console").start() //打印到控制台
query.awaitTermination() //等待结束,以防止程序还没执行完就停止运行
执行的话可以选择在本地编译执行,可以放在服务器执行现有的Demo。
这里我选择在Linux执行。
$ nc -lk 8888
然后打开一个新的端口执行:
$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 8888
然后,将对运行netcat服务器的终端中键入的任何行进行计数并每秒打印一次。 它将类似于以下内容:
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 2|
| spark| 1|
|hadoop| 1|
+------+-----+
3.4.3 程序设计模型
Structured Streaming的关键思想是将传输的流数据看作是被连续添加的表。
-
基本概念
新添加的流都会追加新表中。
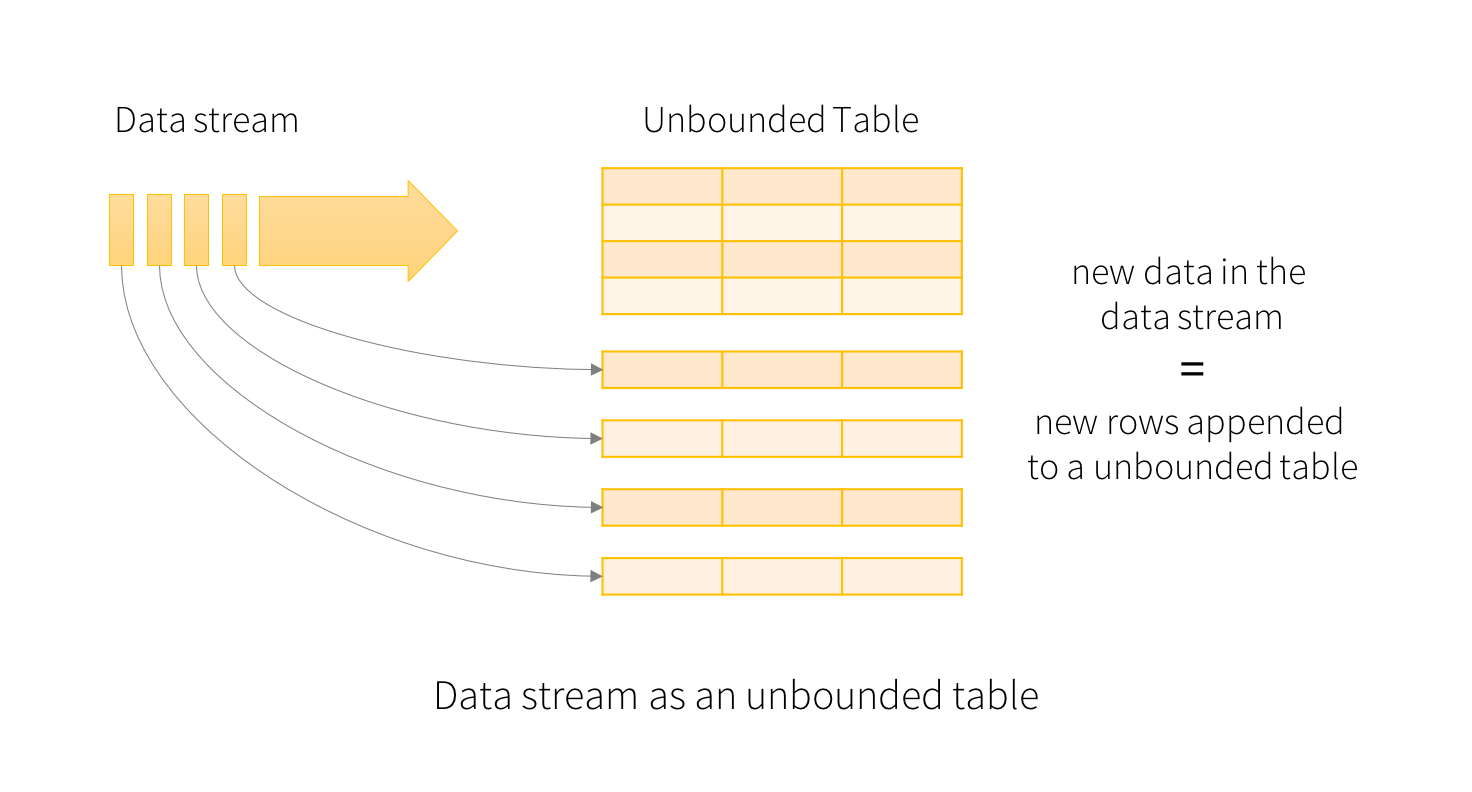
计算一段时间,会生成一个结果表,后续的计算会更新此表,并且此表会同步到外部存储。
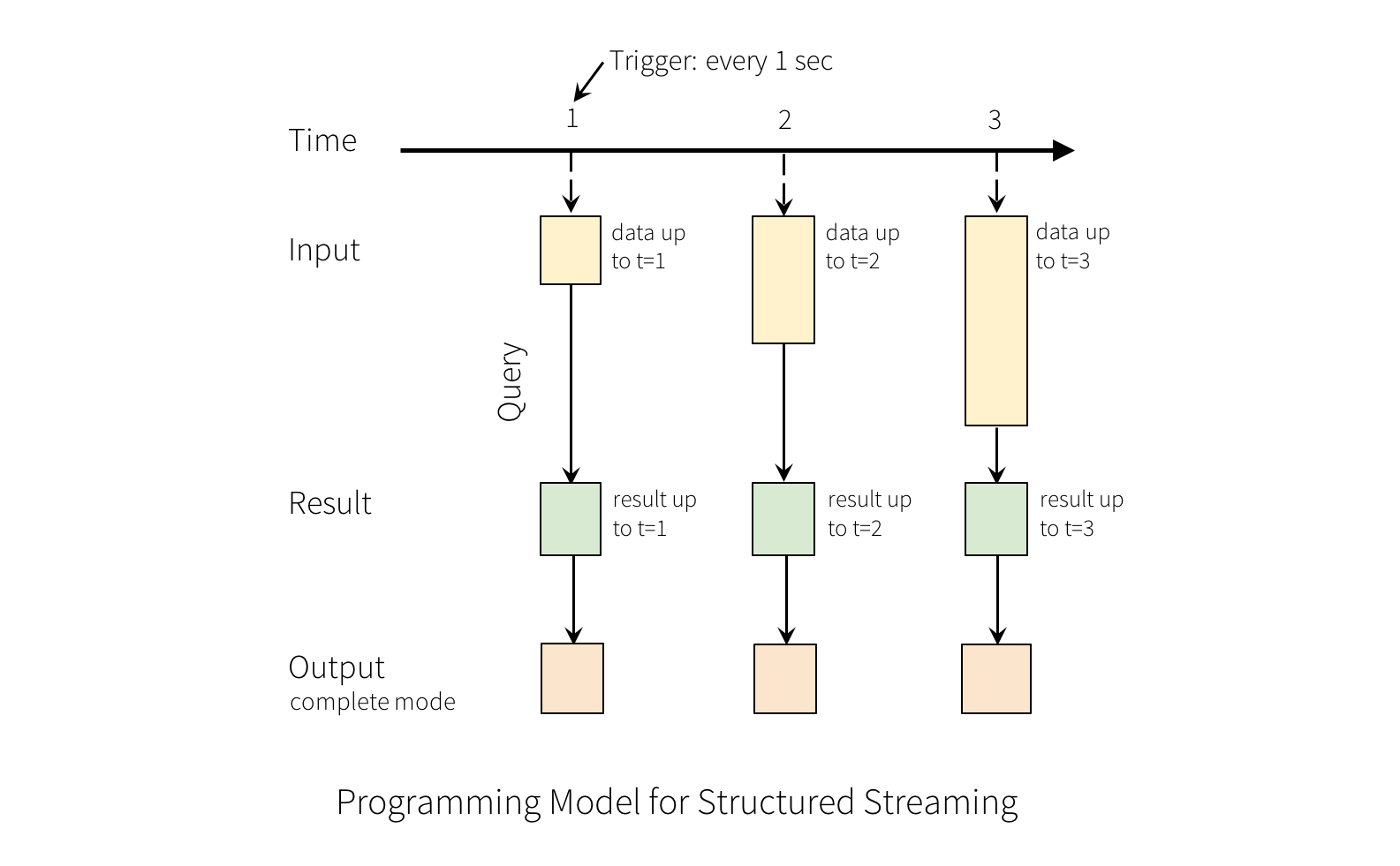
写入外部存储器的几种模式:
1.完整模式:将整个结果表对存储器进行更新。
2.追加模式:仅仅追加新写入的行。
3.更新模式:仅仅更新改过的内容或新追加的内容。(2.1.1版本后才可用)
拿上面简单演示举例,wordcount是生成的结果表,spark会不断检查是否有了新数据,如果有了的话,则它会将原来的结果集和新数据集合并进行计算。
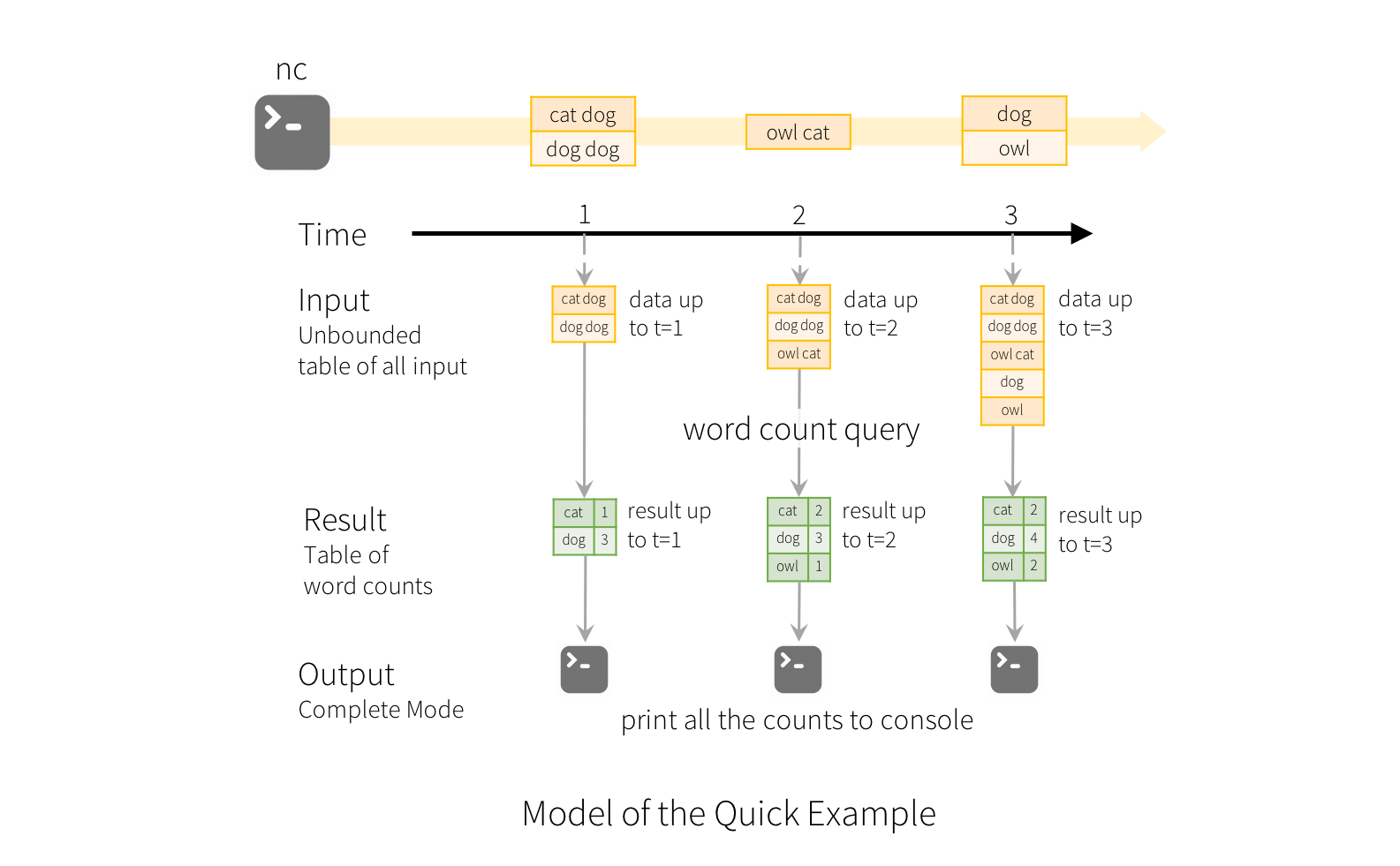
PS:结构化流不会实现整个表。 它从流数据源读取最新的可用数据,对其进行增量处理以更新结果,然后丢弃该源数据。 它仅保留更新结果所需的最小中间状态数据。
-
时间处理和延迟数据
每行数据都有个时间,根据时间可以查询出某个时间段的数据流。
有晚到达的数据,也能很好的自行处理。
-
容错
采用了端到端跟踪处理,可以采用重启或重新处理来处理故障。
3.4.4 使用Datasets 和DataFramesAPI
可以使用SparkSession像处理静态有界数据一样处理动态无界数据。
3.4.4.1 创建streaming DataFrames和streaming Datasets
可以使用SparkSession.readStream返回的DataStreamReader创建streaming DataFrames。
- 数据源
File source :可以从json,text,orc,parquet,csv获取数据。
Kafka source :可以从kafka获取数据。
Socket source (for testing) :可以从socket获取数据,此功能用于测试。
Rate source (for testing) :可以生成带时间的一行行数据进行测试。
下面是一些详细介绍:
| Source | Options | 容错 |
|---|---|---|
| File source | maxFilesPerTrigger:处理文件的最大数量。(默认值no max)。 latestFirst:是否处理最新的文件。当存在积压文件时。(默认值false)。 fileNameOnly:是否基于文件名,而不是完整路径检查文件。(默认值false)。当为true时,E:/1.txt 和F:/1.txt将视为一样。 |
Yes |
| Socket Source | host:要链接的主机。 port:要链接的端口。 |
No |
| Rate Source | rowsPerSecond:每秒生成多少行。(默认值1) rampUpTime:生成速度。(默认值0) rowsPerSecond:加速时间。(默认最大加速) numPartitions:所生成的分区号,例如10.(默认是spark的并行度) |
Yes |
| Kafka Source | 参考 Kafka Integration Guide. | Yes |
接下来演示下:
val socketDF = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", "22")
.load()
println(socketDF.isStreaming)//打印是否是流数据,这里显示true
socketDF.printSchema()//打印结构图
// root
// |-- value: string (nullable = true)
//将文件流存入csv文件。
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark.readStream
.option("sep", ";").
schema(userSchema)
.csv("./data/csvDir")
- DataFrames/Datasets的模式推断和分区
默认情况下从源转换为structured streaming时,需要手动指定schema,而不是让它自动推断,这样在发生故障时方便进行恢复,当然了也可以通过spark.sql.streaming.schemaInference设置为true来启动自动模式推断。
当存在/key=value/的子目录时,分区发现会产生,列表会自动归到这些目录中。
3.4.4.2 DataFrames/Datasets的操作
你可以在DataFrames和Datasets上运行无类型的操作,例如SQL操作(select,join,groupBy),和有类型的操作,类似于RDD操作,例如(filter,map,flatMap)。
-
基本操作:选择,投影,汇总
DataFrame和Dataset支持大部分操作,还有一小部分不支持,在后面会讲。
举例:
//创建Spark val spark = SparkSession .builder() .appName("hive demo") .master("local") .getOrCreate() import spark.implicits._ val df: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", "22").load() val ds: Dataset[DeviceData] = df.as[DeviceData] df.select("device").where("signal > 10")//使用"untyped "API ds.filter(_.signal > 10).map(_.device)//使用"typed "API //获取每种设备上的更新信号 df.groupBy("deviceType").count() //获取每种设备上的平均信号 import org.apache.spark.sql.expressions.scalalang.typed ds.groupByKey(_.deviceType).agg(typed.avg(_.signal))也可以生成临时视图,然后使用SQL调用。
import spark.implicits._ val df: DataFrame = spark.readStream.format("socket").option("host", "localhost").option("port", "22").load() df.createOrReplaceTempView("updates")//生成updates临时视图 spark.sql("select *from updates")//使用SQL调用PS:您可以使用df.isStreaming来确定DataFrame/Dataset是否有数据流。
-
事件时间窗口的操作
sliding 类似于聚合索引。考虑到单词可能会进入两个重合的时间段之间,因此可以指定单词名称和时间戳。例如下图是10分钟统计一次,5分钟更新一次效果图:
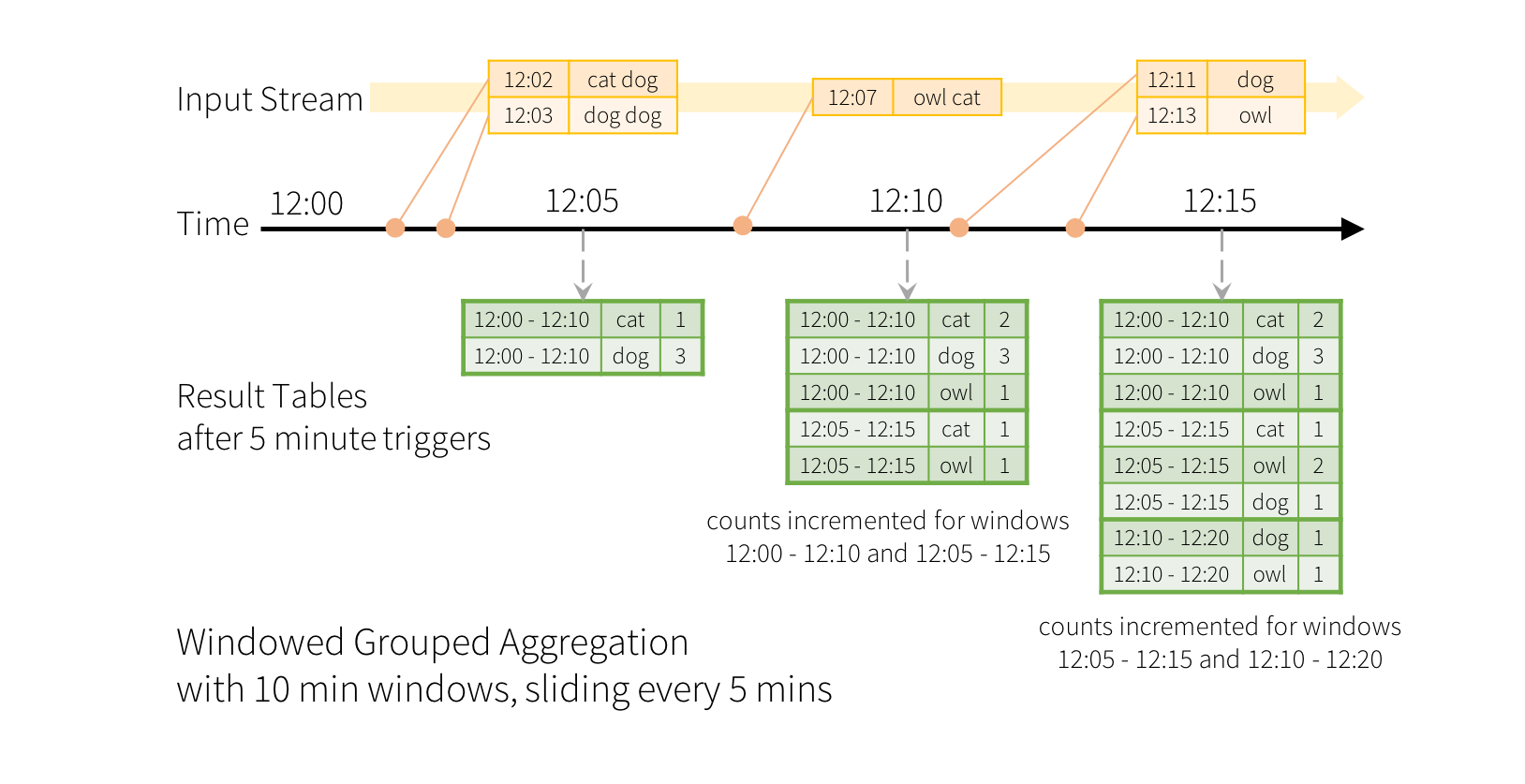
由于此窗口化类似于分组,因此在代码中,您可以使用groupBy()和window()操作来表示窗口化聚合。
import spark.implicits._ val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String } // Group the data by window and word and compute the count of each group val windowedCounts = words.groupBy( window($"timestamp", "10 minutes", "5 minutes"), $"word" ).count()-
处理后期数据和加水印
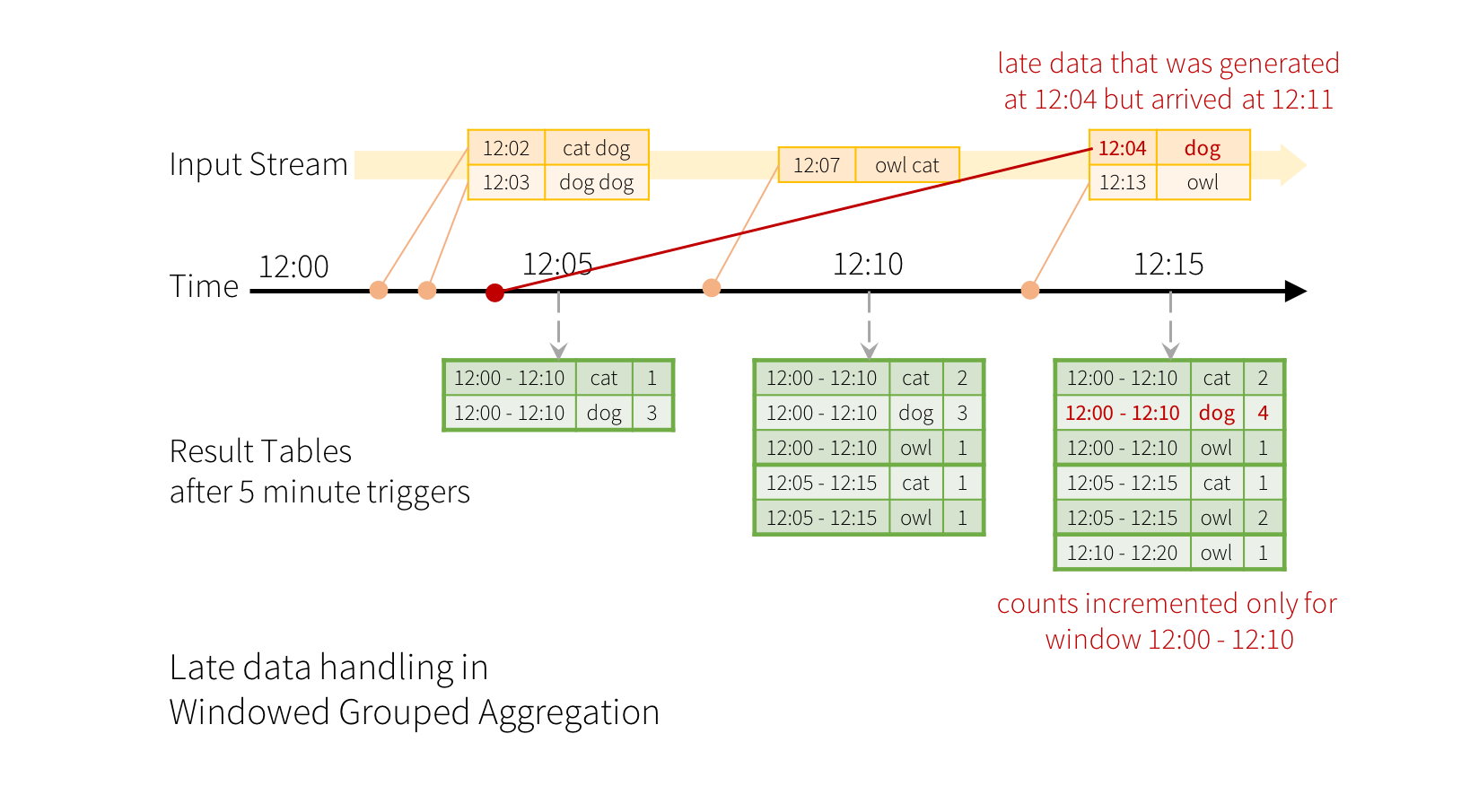
现在考虑如果事件之一迟到了应用程序会发生什么。 例如,应用可以在12:11接收在12:04(即事件时间)生成的单词。 应用程序应使用12:04而不是12:11来更新窗口12:00-12:10的旧计数。 这在基于窗口的分组中很自然地发生–结构化流可以长时间保持部分聚合的中间状态,这样后期的数据就可以正确地更新旧窗口的聚合,如下所示。
但是,要连续几天运行此查询,系统必须限制其累积的中间内存状态量。这意味着系统需要知道何时可以从内存中状态删除旧聚合,因为应用程序将不再接收该聚合的最新数据。为此,在Spark 2.1中,我们引入了水印功能,该功能使引擎自动跟踪数据中的当前事件时间,并尝试相应地清除旧状态。您可以通过指定事件时间列和有关事件时间期望数据延迟的阈值来定义查询的水印。对于在时间T结束的特定窗口,引擎将维持状态并允许延迟数据更新状态,直到(引擎看到的最大事件时间-延迟阈值> T)。换句话说,阈值内的延迟数据将被汇总,但阈值后的数据将开始被丢弃(有关确切保证,请参阅本节后面的内容)。让我们通过一个例子来理解这一点。我们可以使用withWatermark()在前面的示例中轻松定义水印,如下所示。
import spark.implicits._ val userSchema = new StructType().add("timestamp", "timestamp").add("word", "string") val words = spark.readStream.schema(userSchema).json("./data/senddata") //流格式{"timestamp":TimeStamp,"word":String} words.printSchema() import org.apache.spark.sql.functions._ val windowedCounts = words .withWatermark("timestamp", "10 minutes") .groupBy( window($"timestamp", "10 minutes", "5 minutes"), $"word") .count()在此示例中,我们将timestamp定义为查询的水印,并将10分钟定义为数据晚到的阈值。流程图如下:
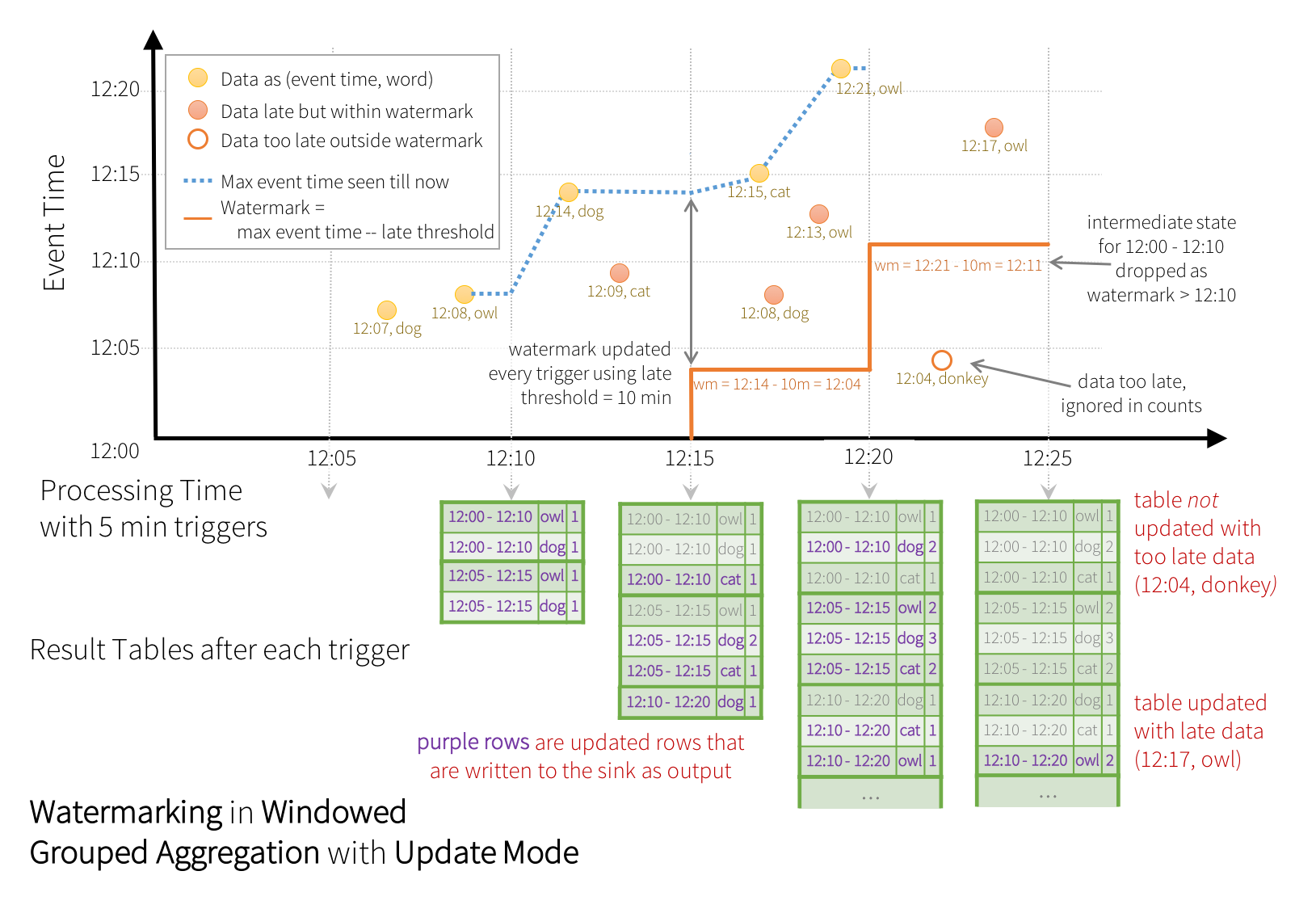
(更新模式)
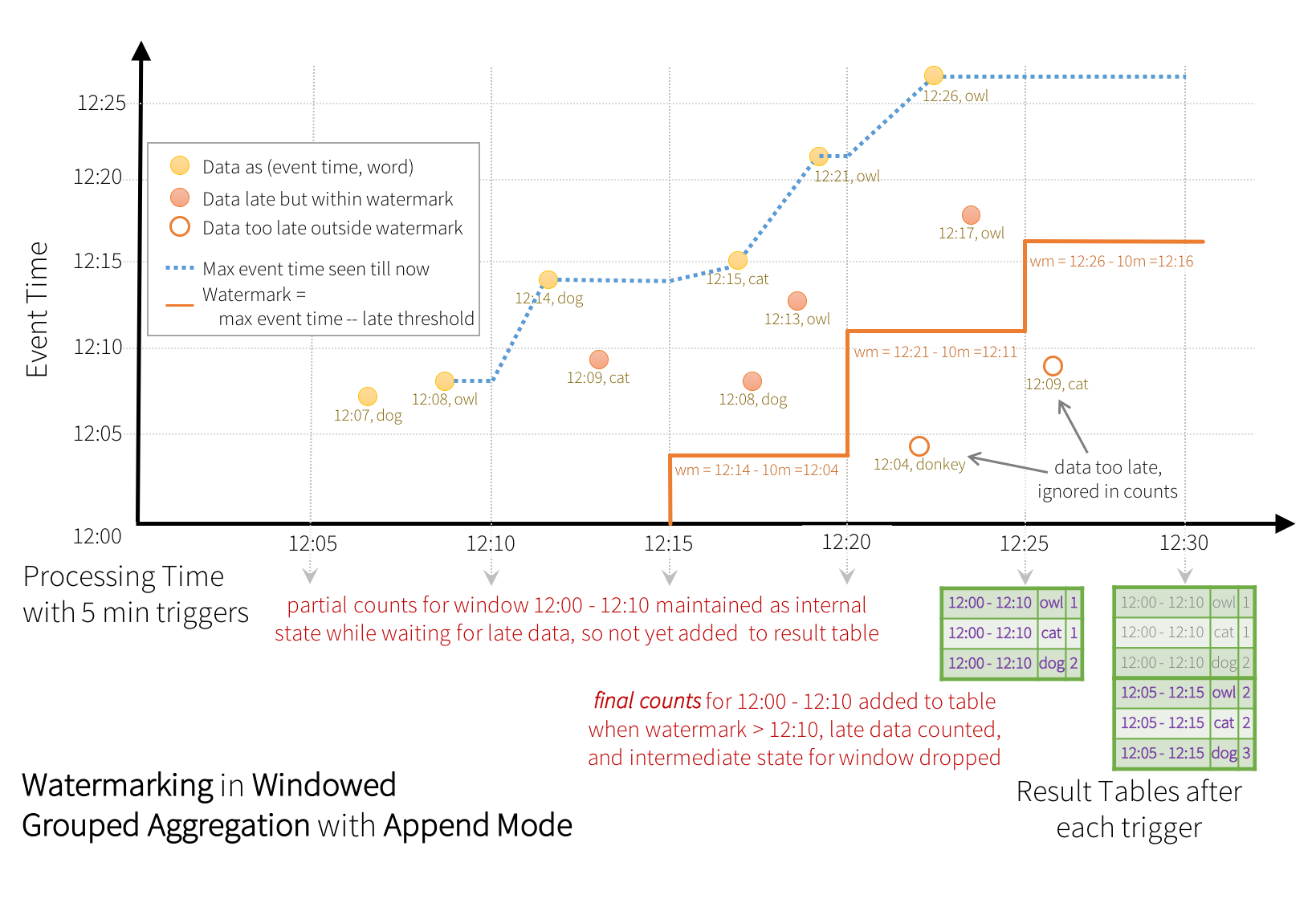
(追加模式)
-
PS:1.加水印必须为“更新”或“追加”模式,“完整复制”必须保留所有中间结果,所以不支持添加水印。
- 在加水印前,必须提前使用 .withWatermark(time)定义。
- 加水印的时间戳必须和计算的时间戳保持一致。
-
流式数据和静态数据可以进行整合操作。
-
流静态联接
自动Spark2.0以来,Spark支持流和静态之间的链接。如下所示:
val staticDF=spark.read.... val streamingDF=spark.readStream... streamingDF.join(staticDF,"type") //内链接 streamingDF.join(staticDF,"type","right_join")//外链接请注意,流静态联接不是有状态的,因此不需要状态管理。 但是,尚不支持某些类型的流静态外部联接。 这些在本“连接”部分的末尾列出。
-
流连接
在Spark2.3中,添加了对流链接的支持。两个图链接的困难在于在任何时间点,连接双方的数据图不完整。因此,对于这两个输入流,我们将过去的流状态进行缓冲,以便我们可以将每个流状态的输入与过去的输入进行匹配。
-
内部链接加水印(可选)
PS:支持任何类型的列上的内部链接以及任何类型的链接条件。但是,随着流的运行,流状态将无限期的增长,因为必须保存过去的输入,因为任何输入都可以与过去的输入匹配。为了避免无界状态,您必须定义其它链接条件,以使无限期的旧输入不能与将来输入匹配,因此可以从状态中清除它们。换句话说,您必须在连接中执行以下步骤。
1.给两个流加水印。
2.在两个时间之间进行约束。
举例:将广告展示次数和点击流进行关联,以统计点击多少次可获利。代码如下所示:
import org.apache.spark.sql.functions.expr val impressions = spark.readStream. ... val clicks = spark.readStream. ... // Apply watermarks on event-time columns val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours") val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours") // Join with event-time constraints impressionsWithWatermark.join( clicksWithWatermark, expr(""" clickAdId = impressionAdId AND clickTime >= impressionTime AND clickTime <= impressionTime + interval 1 hour """) ) -
外部链接加水印
外部链接和上面的内部链接不同之处时,使用外部链接时必须指定事件+水印。语法差不多,不过多加一个joinType进行指定。
impressionsWithWatermark.join( clicksWithWatermark, expr(""" clickAdId = impressionAdId AND clickTime >= impressionTime AND clickTime <= impressionTime + interval 1 hour """), joinType="leftOuter" ) -
流查询中的联接支持矩阵
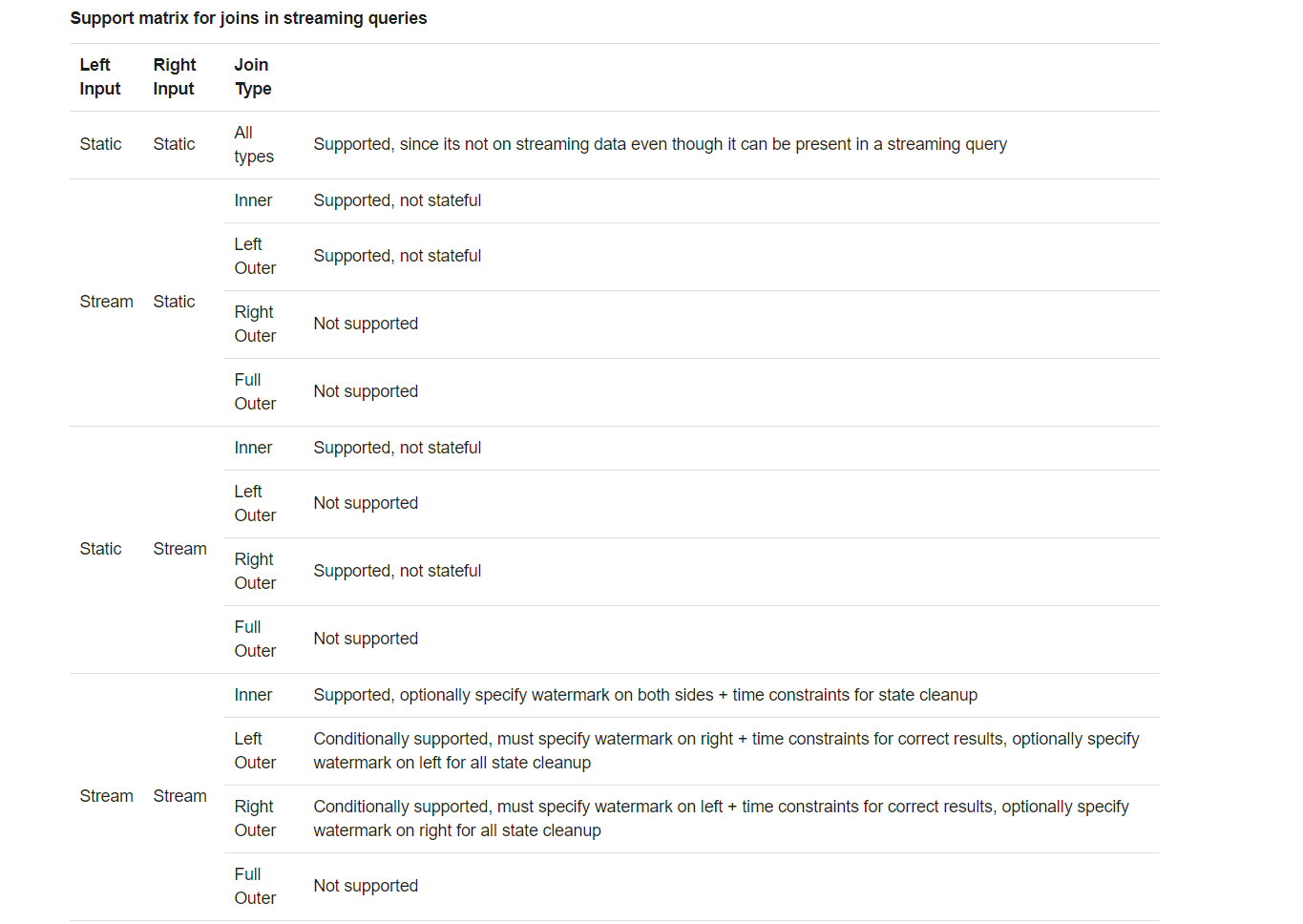
-
-
-
流重复数据删除
可以使用带水印进行延迟删除,也可以不带水印直接删除。如下所示:
val streamingDf = spark.readStream. ... // columns: guid, eventTime, ... // Without watermark using guid column streamingDf.dropDuplicates("guid") // With watermark using guid and eventTime columns streamingDf .withWatermark("eventTime", "10 seconds") .dropDuplicates("guid", "eventTime") -
处理多个水印的政策
流查询可以有多个输入流,这些输入流可以合并或进行链接。每个流都可以有自己的阈值。
inputStream1.withWatermark("eventTime1", "1 hour") .join( inputStream2.withWatermark("eventTime2", "2 hours"), joinCondition)//joinCondition是join条件的意思,这里我们根据实际情况配置。默认情况下选择最小水印作为全局水印,因为如果一个流落后于其它流,它却没有数据时而被丢弃为时已晚。
但是,在某些情况下,即使在最慢的流中获取数据,您也想获取最快的结果。从spark2.4开始,您可以通过
spark.sql.streaming.multipleWatermarkPolicy设置max(默认为min)来设置多重水印,这使水印以最快的速度流动。 -
任意状态作业
与聚合相比,许多用例需要更高级的状态操作。 例如,在许多用例中,您必须跟踪事件数据流中的会话。 为了进行这种会话化,您将必须将任意类型的数据保存为状态,并在每个触发器中使用数据流事件对状态执行任意操作。 从Spark 2.2开始,可以使用mapGroupsWithState操作和功能更强大的flatMapGroupsWithState操作来完成此操作。 两种操作都允许您将用户定义的代码应用于分组的数据集以更新用户定义的状态。 有关更多具体细节,请查看API文档(Scala / Java)和示例(Scala / Java)。
-
不支持的操作
不支持.cout()而要使用ds.groupBy().count()
不支持.foreach()而要使用ds.writeStream.foreach()
3.4.4.3 开始流查询
定义了DataFrame和DataSet后,接下来就是流查询了。
-
输出方式
有几种类型的输出模式:
1.追加模式-将自上次以来添加的结果进行追加。(默认)
2.更新模式-紧更新自上次变动的内容。
3.完全模式-每次触发后会将整个内容覆盖。
不同类型的查询支持不同的输出模式,如下所示:
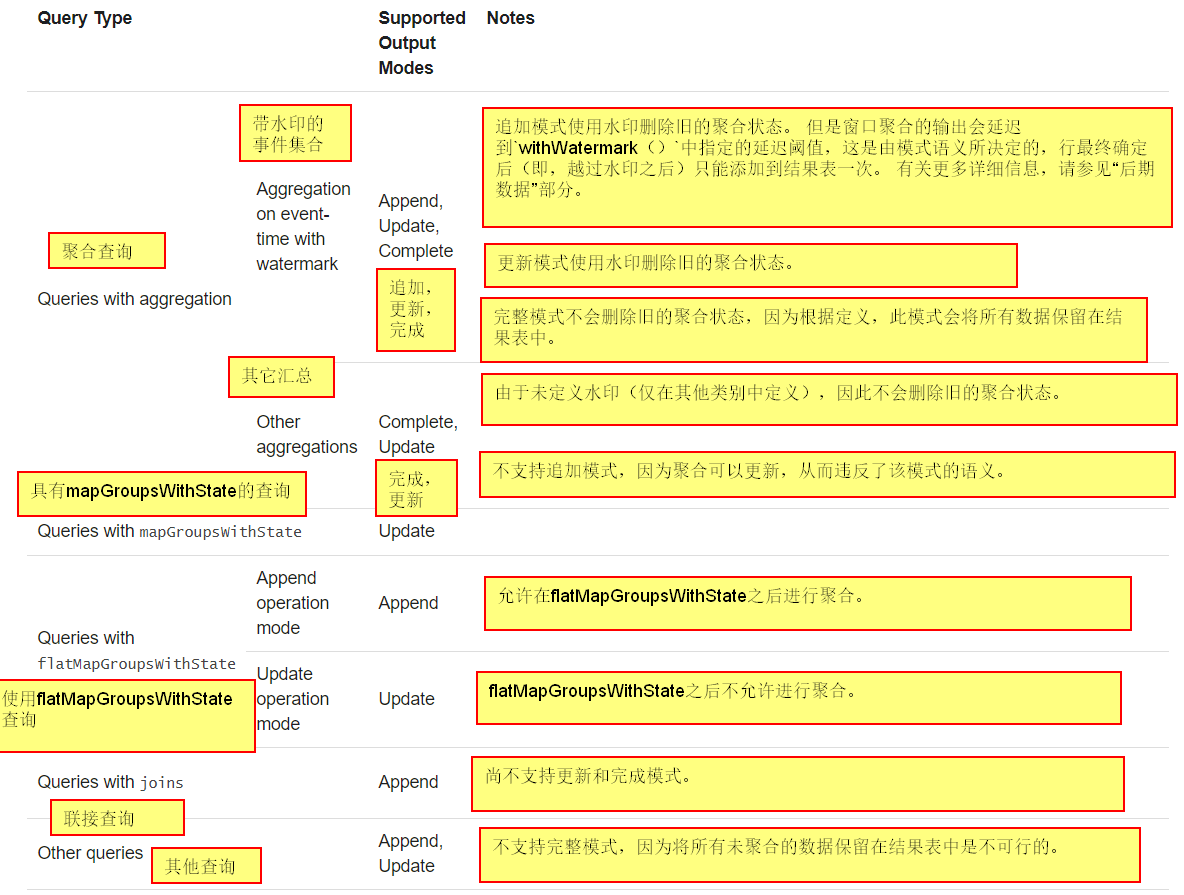
-
有几种内置类型的输出接收器:
1.File sink-将输出存储在目录
writeStream .format("parquet") // can be "orc", "json", "csv", etc. .option("path", "path/to/destination/dir") .start()2.Kafka sink-将输出存储在Kafka的一个或多个主题
writeStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("topic", "updates") .start()3.Foreach sink-对输出的记录运行任意计算
writeStream .foreach(...) .start()4.Console-sink(供调试使用):每次运行,将内容输出到控制台。
writeStream .format("console") .start()5.Memonry-sink(供调试使用):输出作为内存表存储在内存中。
writeStream .format("memory") .queryName("tableName") .start()一些接收器是不容错的,紧用于调试的目的,下面表格展示具体信息。

下面写个Demo演示下:
scala val peopleStruct = new StructType().add("name", "string").add("age", "integer") val peopleDataDF = spark.readStream.schema(peopleStruct).format("json").load("./data/people.json") val result = peopleDataDF.select("name").where("age>18")println("----没有聚合的情况---") //在控制台打印 result .writeStream .format("console") .start() //写入parquet文件 result.writeStream .format("parquet") .option("checkpointLocation", "./data/result") .option("path", "./data/result") .start() println("---有聚合的情况---") val groNameDF = peopleDataDF.groupBy("name").count() //将更新的聚合打印到控制台 groNameDF.writeStream .outputMode("complete") //指定模式为完整编译 .format("console") .start() //将结果打印到内存表 groNameDF.writeStream .queryName("person") .outputMode("complete") .format("memory") .start() spark.sql("select *from person")-
使用foreach和foreachBatch操作
-
foreach流查询
foreachBatch(...)允许您在每个微批处理的输出数据上指定函数。从Spark2.4开始支持。
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) => // Transform and write batchDF }.start()使用foreachBatch,可以执行以下操作。
1.重用现有的批处理数据源-对于许多存储系统,可能还没有流式接收器,但是可能已经存在用于批处理查询的数据写入器。 使用foreachBatch,可以在每个微批处理的输出上使用批处理数据写入器。
2.写入多个位置-如果要将流查询的输出写入多个位置,则可以简单地多次写入输出DataFrame / Dataset。 但是,每次写入尝试都可能导致重新计算输出数据(包括可能重新读取输入数据)。 为了避免重新计算,您应该缓存输出DataFrame / Dataset,将其写入多个位置,然后取消缓存。 这是一个轮廓。streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) => batchDF.persist() batchDF.write.format(...).save(...) // location 1 batchDF.write.format(...).save(...) // location 2 batchDF.unpersist() } -
foreach
foreachBatch从根本上依赖于微批处理执行,无法连续处理,如果使用连续模式,请改用foreach。
步骤就是打开->处理->关闭。
在scala中,您必须扩展foreach扩展类。
result.writeStream.foreach( new ForeachWriter[String] { def open(partitionId: Long, version: Long): Boolean = { // Open connection } def process(record: String): Unit = { // Write string to connection } def close(errorOrNull: Throwable): Unit = { // Close the connection } } ).start()
-
-
-
Triggers(触发)
流查询触发器定义了流处理的时间,无论是foreachBatch还是foreach,以下是否支持的各种触发器。

下面有一些案例:
result.writeStream .format("console") .start() result.writeStream .format("console") .trigger(Trigger.ProcessingTime("1 seconds")) .start() result.writeStream .format("console") .trigger(Trigger.Once()) .start() result.writeStream .format("console") .trigger(Trigger.Continuous("1 hours")) .start()
3.4.4.4 管理流查询
启用查询时创建的StreamingQuery对象用于监视和管理查询。
val query = df.writeStream.format("console").start() //
query.id // 获取正在运行的查询的唯一标识符,该标识符在从检查点数据重新启动后持续存在
query.runId // 获取此查询运行的唯一ID,它将在每次启动/重新启动时生成
query.name //获取自动生成的名称或用户指定的名称
query.explain() // 打印查询的详细说明
query.stop() // 停止查询
query.awaitTermination() // 阻塞,直到查询终止,带有stop()或错误
query.exception // 如果查询因错误而终止,则为异常
query.recentProgress // 此查询的最新进度更新的数组
query.lastProgress // 此流查询的最新进度更新
您可以 在单个SparkSession启动任意数量的查询,它们将同时运行以共享群资源。您可以使用spark.streams()获取可用于管理当前活动查询的StreamingQueryManager。
spark.streams.active // 获取当前活动的流查询列表
spark.streams.get(id) // 通过其唯一ID获取查询对象
spark.streams.awaitAnyTermination() //阻止直到其中任何一个终止
3.4.4.5 监视流查询
有多种方法可以监视活动的流查询。 您可以使用Spark的Dropwizard指标支持将指标推送到外部系统,也可以通过编程方式访问它们。
-
交互阅读指标
您可以使用streamingQuery.lastProgress()和streamingQuery.status()直接获取活动查询的当前状态和指标。下面是一些案例:
val query: StreamingQuery = ... //以writeStream...start() 结尾的 println(query.lastProgress) /* Will print something like the following. { "id" : "ce011fdc-8762-4dcb-84eb-a77333e28109", "runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a", "name" : "MyQuery", "timestamp" : "2016-12-14T18:45:24.873Z", "numInputRows" : 10, "inputRowsPerSecond" : 120.0, "processedRowsPerSecond" : 200.0, "durationMs" : { "triggerExecution" : 3, "getOffset" : 2 }, "eventTime" : { "watermark" : "2016-12-14T18:45:24.873Z" }, "stateOperators" : [ ], "sources" : [ { "description" : "KafkaSource[Subscribe[topic-0]]", "startOffset" : { "topic-0" : { "2" : 0, "4" : 1, "1" : 1, "3" : 1, "0" : 1 } }, "endOffset" : { "topic-0" : { "2" : 0, "4" : 115, "1" : 134, "3" : 21, "0" : 534 } }, "numInputRows" : 10, "inputRowsPerSecond" : 120.0, "processedRowsPerSecond" : 200.0 } ], "sink" : { "description" : "MemorySink" } } */ println(query.status) /* Will print something like the following. { "message" : "Waiting for data to arrive", "isDataAvailable" : false, "isTriggerActive" : false } */ -
使用异步API以编程方式报告指标
您还可以通过附加的StreamingQueryListener来异步监视与SparkSession关联的所有查询。
val spark: SparkSession = ... spark.streams.addListener(new StreamingQueryListener() { override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = { println("Query started: " + queryStarted.id) } override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = { println("Query terminated: " + queryTerminated.id) } override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = { println("Query made progress: " + queryProgress.progress) } }) -
使用Dropwizard报告指标
Spark支持使用Dropwizard库的报告指标。 要同时报告结构化流查询的指标,您必须在SparkSession中显式启用配置spark.sql.streaming.metricsEnabled。
spark.conf.set("spark.sql.streaming.metricsEnabled", "true") // or spark.sql("SET spark.sql.streaming.metricsEnabled=true")启用此配置后,在SparkSession中启动的所有查询都将通过Dropwizard向所有已配置的接收器报告指标(例如Ganglia,Graphite,JMX等)。
3.4.4.6 通过检查点从故障中恢复
万一发生故障或有意关闭时,您可以恢复先前的进度和先前查询的状态,并在中断的地方继续进行。 这是通过使用 checkpointing 和预写日志来完成的。 您可以使用 checkpoint 配置查询,查询会将所有进度信息(即在每个触发器中处理的偏移量范围)和正在运行的聚合(例如快速示例中的字数)保存到检查点位置。 此检查点位置必须是与HDFS兼容的文件系统中的路径,并且可以在启动查询时在DataStreamWriter中设置为选项。
aggDF
.writeStream
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start()
3.4.4.7 流查询中的更改后的恢复语义
这部分内容较多,都是文字,没有代码,自行阅览官网。
3.4.5 连续加工
这是个实验功能,说可以实现最低1ms的延迟,之前最低是100毫秒。自行阅览官网。
3.5 Spark Streaming
3.5.1前言
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。 可以从许多数据源(例如Kafka,Flume,Kinesis或TCP sockets)中提取数据,并可以使用以高级功能(如map,reduce,join和window)表示的复杂算法来处理数据。 最后,可以将处理后的数据推送到文件系统,数据库和实时仪表板。 实际上,您可以在数据流上应用Spark的机器学习和图形处理算法。

在内部,它的工作方式如下。 Spark Streaming接收实时输入数据流,并将数据分成批次,然后由Spark引擎进行处理,以生成批次的最终结果流。
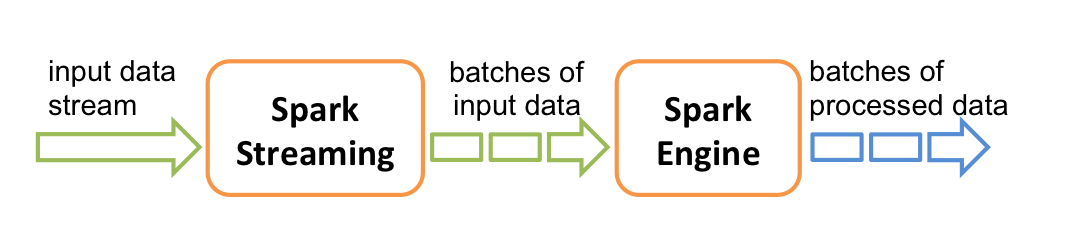
Spark Streaming提供了称为离散流或DStream的高级抽象,它表示连续的数据流。 DStreams可以根据来自诸如Kafka,Flume和Kinesis之类的源的输入数据流来创建,也可以通过对其他DStreams应用高级操作来创建。 在内部,DStream表示为RDD序列。
本指南将向您演示使用DStream操作Spark Streaming程序。
3.5.2快速演示
在详细介绍如何编写自己的Spark Streaming程序之前,让我们快速看一下简单的Spark Streaming程序的外观。 假设我们要计算从TCP套接字侦听的数据服务器接收到的文本数据中的单词数。 您需要做的如下。
首先,我们将Spark Streaming类的名称以及从StreamingContext进行的一些隐式转换导入到我们的环境中,以便向我们需要的其他类(如DStream)添加有用的方法。 StreamingContext是所有流功能的主要入口点。 我们创建具有两个执行线程和1秒批处理间隔的本地StreamingContext。
编写代码前,如果你使用的Maven,请先引入
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>2.4.5</version>
<scope>provided</scope>
</dependency>
要使用Kafka,Flume,Kinesis添加以下依赖项:
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-10_2.12 |
| Flume | spark-streaming-flume_2.12 |
| Kinesis | spark-streaming-kinesis-asl_2.12 [Amazon Software License] |
编写代码:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val conf = new SparkConf().setAppName("demo").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(1)) //SparkStreaming中最主要的就是StreamingContext
val lines = ssc.socketTextStream("localhost", 9999) //获取socket的text流
val words = lines.flatMap(_.split(" "))//分割字段
val wordKey = words.map(word => (word, 1))//映射字段文字为(key,value)也就是给每个单词加初始值1,便于后面进行计算
val wordCount = wordKey.reduceByKey(_ + _)//统计文字数量
ssc.start() //开始执行
ssc.awaitTermination()//等待全部执行完毕
如果在Linux服务器运行可以使用$ nc -lk 9999来开启一个9999端口的小型服务。
然后通过执行$ ./bin/run-example streaming.NetworkWordCount localhost 9999来运行项目。
3.5.3基础操作
3.5.3.1 初始化StreamingContext
要初始化Spark Streaming程序,必须创建StreamingContext对象,该对象是所有Spark Streaming功能的主要入口点。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
appName参数是您的应用程序在群集UI上显示的名称。master是一个Spark,Mesos,Kubernetes或YARN群集URL,或一个特殊的“ local []”字符串,以本地模式运行。 实际上,当在集群上运行时,您将不希望对程序中的母版进行硬编码,而希望通过spark-submit启动应用程序并在其中接收它。 但是,对于本地测试和单元测试,您可以传递“ local [*]”以在内部运行Spark Streaming(检测本地系统中的内核数)。 请注意,这在内部创建了一个SparkContext(所有Spark功能的起点),可以作为ssc.sparkContext访问。
必须根据应用程序的延迟要求和可用的群集资源来设置批处理间隔。 有关更多详细信息,请参见性能调整部分。
也可以从现有的SparkContext对象创建StreamingContext对象。
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))
定义上下文后,您必须执行以下操作。
1.通过创建输入DStream定义输入源。
2.通过将转换和输出操作应用于DStream来定义流计算。
3.开始使用streamingContext.start()接收数据并对其进行处理。
4.等待使用streamingContext.awaitTermination()停止处理(手动或由于任何错误)。
5.可以使用streamingContext.stop()手动停止该处理。
需要注意的几点:
1.一旦启动上下文,就无法设置新的流计算或将其添加到该流计算中。
2.上下文一旦停止,就无法重新启动。
3.JVM中只能同时激活一个StreamingContext。
4.StreamingContext上的stop()也会停止SparkContext。 要仅停止StreamingContext,请将名为stopSparkContext的stop()的可选参数设置为false。
5.只要在创建下一个StreamingContext之前停止了上一个StreamingContext(不停止SparkContext),就可以将SparkContext重用于创建多个StreamingContext。
3.5.3.2 Discretized Streams(DStreams)
离散流或DStream是Spark Streaming提供的基本抽象。 它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。 在内部,DStream由一系列连续的RDD表示,这是Spark对不可变的分布式数据集的抽象(有关更多详细信息,请参见Spark编程指南)。 DStream中的每个RDD都包含来自特定间隔的数据,如下图所示。

在DStream上执行的任何操作都转换为对基础RDD的操作。 例如,在将行流转换为单词的较早示例中,flatMap操作应用于行DStream中的每个RDD,以生成单词DStream的RDD。 如下图所示。
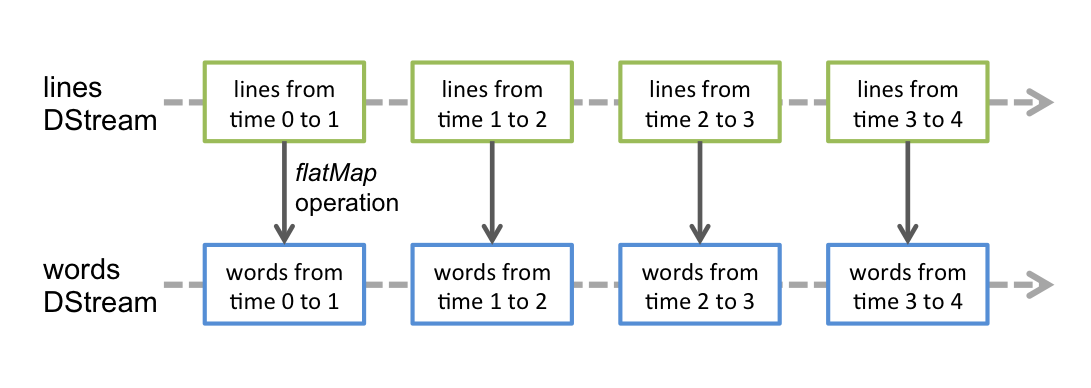
这些基础的RDD转换由Spark引擎计算。 DStream操作隐藏了大多数这些细节,并为开发人员提供了更高级别的API,以方便使用。 这些操作将在后面的部分中详细讨论。
3.5.3.3 输入DStreams和接收器
输入DStream是表示从流源接收的输入数据流的DStream。在快速示例中,行是输入DStream,因为它表示从netcat服务器接收的数据流。每个输入DStream(文件流除外,本节后面将讨论)都与一个Receiver对象(Scala doc,Java doc)相关联,该对象从源接收数据并将其存储在Spark的内存中以进行处理。
Spark Streaming提供了两类内置的流媒体源。
基本来源:直接在StreamingContext API中可用的来源。示例:文件系统和套接字连接。
高级资源:可以通过其他实用程序类获得诸如Kafka,Flume,Kinesis等资源。如链接部分所述,它们需要针对额外的依赖项进行链接。
我们将在本节后面的每个类别中讨论一些资源。
请注意,如果要在流应用程序中并行接收多个数据流,则可以创建多个输入DStream(在“性能调整”部分中进一步讨论)。这将创建多个接收器,这些接收器将同时接收多个数据流。但是请注意,Spark工作程序/执行程序是一项长期运行的任务,因此它占用了分配给Spark Streaming应用程序的核心之一。因此,重要的是要记住,必须为Spark Streaming应用程序分配足够的内核(或线程,如果在本地运行),以处理接收到的数据以及运行接收器。
要记住的要点
在本地运行Spark Streaming程序时,请勿使用“ local”或“ local [1]”作为主URL。 这两种方式均意味着仅一个线程将用于本地运行任务。 如果您使用的是基于接收方的输入DStream(例如套接字,Kafka,Flume等),则将使用单个线程来运行接收方,而不会留下任何线程来处理接收到的数据。 因此,在本地运行时,请始终使用“ local [n]”作为主URL,其中n>要运行的接收器数(有关如何设置主服务器的信息,请参见Spark属性)。
为了将逻辑扩展到在集群上运行,分配给Spark Streaming应用程序的内核数必须大于接收器数。 否则,系统将接收数据,但无法处理它。
Basic Sources
我们已经在快速示例中查看了ssc.socketTextStream(...),该示例根据通过TCP套接字连接接收的文本数据创建DStream。 除了套接字外,StreamingContext API还提供了从文件作为输入源创建DStream的方法。
文件流
为了从与HDFS API兼容的任何文件系统(即HDFS,S3,NFS等)上的文件读取数据,可以通过StreamingContext.fileStream [KeyClass,ValueClass,InputFormatClass]创建DStream。
文件流不需要运行接收器,因此无需分配任何内核来接收文件数据。
对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)。
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
For text files
streamingContext.textFileStream(dataDirectory)
Spark Streaming将监视目录dataDirectory并处理在该目录中创建的所有文件。
可以监视一个简单目录,例如“ hdfs:// namenode:8040 / logs /”。发现后,将直接处理该路径下的所有文件。
可以提供POSIX全局模式,例如“ hdfs:// namenode:8040 / logs / 2017 / *”。在这里,DStream将由目录中与模式匹配的所有文件组成。也就是说:它是目录的模式,而不是目录中的文件。
所有文件必须具有相同的数据格式。
根据文件的修改时间而不是创建时间,将其视为时间段的一部分。
处理后,在当前窗口中对文件的更改不会导致重新读取该文件。也就是说:更新将被忽略。
目录下的文件越多,扫描更改所需的时间就越长-即使未修改任何文件。
如果使用通配符标识目录,例如“ hdfs:// namenode:8040 / logs / 2016- *”,则重命名整个目录以匹配路径会将目录添加到受监视目录列表中。流中仅包含目录中修改时间在当前窗口内的文件。
调用FileSystem.setTimes()修复时间戳是一种在以后的窗口中拾取文件的方法,即使其内容没有更改。
使用对象存储作为数据源
HDFS之类的“完整”文件系统倾向于在创建输出流后立即对其文件设置修改时间。当打开文件时,甚至在数据完全写入之前,它也可能包含在DStream中-之后,将忽略同一窗口中对该文件的更新。也就是说:更改可能会丢失,流中会省略数据。
为了确保在窗口中能够接收到更改,请将文件写入一个不受监视的目录,然后在关闭输出流后立即将其重命名为目标目录。如果重命名的文件在创建窗口期间出现在扫描的目标目录中,则将拾取新数据。
相反,由于实际复制了数据,因此诸如Amazon S3和Azure存储之类的对象存储的重命名操作通常较慢。此外,重命名的对象可能具有named()操作的时间作为其修改时间,因此可能不被视为原始创建时间所暗示的窗口的一部分。
需要对目标对象存储进行仔细的测试,以验证存储的时间戳行为与Spark Streaming期望的一致。直接写入目标目录可能是通过所选对象存储流传输数据的适当策略。
有关此主题的更多详细信息,请查阅Hadoop Filesystem Specification。
3.5.3.4 DStreams上的转换
与RDD相似,转换允许修改来自输入DStream的数据。 DStream支持普通Spark RDD上可用的许多转换。 一些常见的方法如下。
| Transformation | Meaning |
|---|---|
| map(func) | 通过将源DStream的每个元素传递给函数 func 来返回新的DStream。 |
| flatMap(func) | 与map相似,但是每个输入项可以映射到0个或多个输出项。 |
| filter(func) | 通过仅选择* func *返回true的源DStream记录来返回新的DStream。 |
| repartition(numPartitions) | 通过创建更多或更少的分区来更改此DStream中的并行度。 |
| union(otherStream) | 返回一个新的DStream,其中包含源DStream和* otherDStream *中元素的并集。 |
| count() | 通过计算源DStream的每个RDD中的元素数,返回一个新的单元素RDD DStream。 |
| reduce(func) | 通过使用函数* func *(带有两个参数并返回一个)来聚合源DStream的每个RDD中的元素,从而返回一个单元素RDD的新DStream。 该函数应具有关联性和可交换性,以便可以并行计算。 |
| countByValue() | 在类型为K的元素的DStream上调用时,返回一个新的(K,Long)对的DStream,其中每个键的值是其在源DStream的每个RDD中的频率。 |
| reduceByKey(func, [numTasks]) | 根据reduce后面的函数进行聚合。 |
| join(otherStream, [numTasks]) | 在(K,V)和(K,W)对的两个DStream上调用时,返回一个新的(K,(V,W))对的DStream,其中每个键都有所有元素对。 |
| cogroup(otherStream, [numTasks]) | 在(K,V)和(K,W)对的DStream上调用时,返回一个新的(K,Seq [V],Seq [W])元组的DStream。 |
| transform(func) | 通过对源DStream的每个RDD应用RDD-to-RDD函数来返回新的DStream。 这可用于在DStream上执行任意RDD操作。 |
| updateStateByKey(func) | 返回一个新的“状态” DStream,在该DStream中,通过在键的先前状态和键的新值上应用给定函数来更新每个键的状态。 这可用于维护每个键的任意状态数据。 |
updateStateByKey操作使您可以保持任意状态,同时用新信息连续更新它。 要使用此功能,您将必须执行两个步骤。
定义状态-状态可以是任意数据类型。
定义状态更新功能-使用功能指定如何使用输入流中的先前状态和新值来更新状态。
在每个批次中,Spark都会对所有现有密钥应用状态更新功能,无论它们是否在批次中具有新数据。 如果更新函数返回None,则将删除键值对。
让我们用一个例子来说明。 假设您要保持在文本数据流中看到的每个单词的连续计数。 此处,运行计数是状态,它是整数。 我们将更新函数定义为:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
将为每个单词调用update函数,其中newValues的序列为1(从(word,1)对开始),而runningCount具有先前的计数。
请注意,使用updateStateByKey要求配置检查点目录,这将在检查点部分中详细讨论。
转换操作
可以很方便的将一个 RDD流转换为另一个RDD流。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // 包含垃圾信息的RDD
val cleanedDStream = wordCounts.transform { rdd =>
rdd.join(spamInfoRDD).filter(...) // 将数据流与垃圾信息一起加入进行清理
...
}
PS:每个批处理都会调用方法,这样保证了每次有新的数据都会执行。
Window Operations(Window计算)
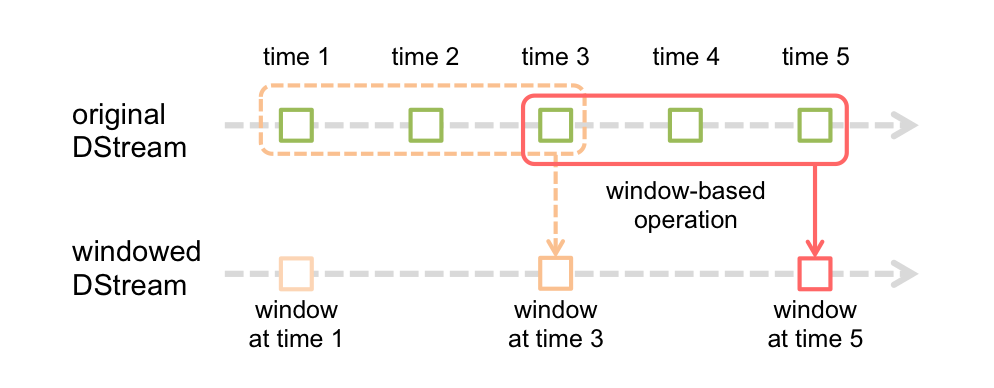
下面演示下每10秒减少一次30秒的数据的操作。
// 每10秒减少最后30秒的数据
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
一些window操作定义如下,这些都依赖操作windowLength和slideInternal实现的。
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | window处理DStream后,返回新的DStream。 |
| countByWindow(windowLength, slideInterval) | 返回window计数。 |
| reduceByWindow(func, windowLength, slideInterval) | 返回slide时间内聚合的数据。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 返回通过func聚合的K,V数据。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 这个和上面的区别是多了一个invFunc参数,这个参数的意思是处理输出值用的。 |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 作用于(K,V)上,返回(K,Long)数据。 |
流合并
Scala实现:
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
Java实现:
JavaPairDStream<String, String> stream1 = ...
JavaPairDStream<String, String> stream2 = ...
JavaPairDStream<String, Tuple2<String, String>> joinedStream = stream1.join(stream2);
这样就把两个流合并在一起了。
Scala实现:
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)
Java实现:
JavaPairDStream<String, String> windowedStream1 = stream1.window(Durations.seconds(20));
JavaPairDStream<String, String> windowedStream2 = stream2.window(Durations.minutes(1));
JavaPairDStream<String, Tuple2<String, String>> joinedStream = windowedStream1.join(windowedStream2);
流数据集连接
Scala实现:
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }
Java实现:
JavaPairRDD<String, String> dataset = ...
JavaPairDStream<String, String> windowedStream = stream.window(Durations.seconds(20));
JavaPairDStream<String, String> joinedStream = windowedStream.transform(rdd -> rdd.join(dataset));
3.5.3.5 DStreams上的输出操作
输出操作可以将DStream输出到外部系统,比如HDFS,数据库。
| Output Operation | Meaning |
|---|---|
| print() | 打印前10个数据。 |
| saveAsTextFiles(prefix, [suffix]) | 保存为text文件。 |
| saveAsObjectFiles(prefix, [suffix]) | 保存为object文件。 |
| saveAsHadoopFiles(prefix, [suffix]) | 保存为hadoop文件。 |
| foreachRDD(func) | 将func应用于循环RDD。 |
使用foreachRDD操作
dstream.foreachRDD是一个功能强大的原语,可以将数据发送到外部系统。使用过程中应该创建一个连接对象,负责连接外部系统。
Scala实现:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool是静态的,延迟初始化连接池。
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) //返回池中以备调用
}
}
Java实现:
dstream.foreachRDD(rdd -> {
rdd.foreachPartition(partitionOfRecords -> {
// ConnectionPool是静态的,延迟初始化连接池。
Connection connection = ConnectionPool.getConnection();
while (partitionOfRecords.hasNext()) {
connection.send(partitionOfRecords.next());
}
ConnectionPool.returnConnection(connection); // 返回池中以备调用
});
});
3.5.3.6 DataFrame和SQL操作
Scala演示:
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// 获取SparkSession单例实例
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
// 将rdd转换为DataFrame
val wordsDataFrame = rdd.toDF("word")
// 创建一个临时表
wordsDataFrame.createOrReplaceTempView("words")
// 使用sql语句进行统计
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
3.5.3.7 缓存/持久化
DStream操作默认使用缓存,无序开发人员手动设置。
3.5.3.8 检查点
检查点的作用是,在服务器节点发生故障时,可以根据检查点进行恢复。
以下是一个设置检查点的Demo:
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // 创建context
val lines = ssc.socketTextStream(...) // 创建DStream
...
ssc.checkpoint(checkpointDirectory) // 设置检查点
ssc
}
// 从检查点创建一个新的StreamingContext
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
//根据需要进行其他设置,
// 不管是启动还是重新启动
context. ...
// 启动上下文
context.start()
context.awaitTermination()
3.5.3.9 累加器,广播变量和检查点
如果检查点恢复累加器和广播变量,那么我们要做的是延迟创建累加器和广播变量。如下:
object WordBlacklist {
@volatile private var instance: Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext): Broadcast[Seq[String]] = {
if (instance == null) {
synchronized {
if (instance == null) {
val wordBlacklist = Seq("a", "b", "c")
instance = sc.broadcast(wordBlacklist)
}
}
}
instance
}
}
object DroppedWordsCounter {
@volatile private var instance: LongAccumulator = null
def getInstance(sc: SparkContext): LongAccumulator = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.longAccumulator("WordsInBlacklistCounter")
}
}
}
instance
}
}
wordCounts.foreachRDD { (rdd: RDD[(String, Int)], time: Time) =>
// 获取注册广播变量
val blacklist = WordBlacklist.getInstance(rdd.sparkContext)
// 获取注册累加器
val droppedWordsCounter = DroppedWordsCounter.getInstance(rdd.sparkContext)
// 删除黑名单列表包含的单词,并使用droppedWordsCounter对其进行计数。
val counts = rdd.filter { case (word, count) =>
if (blacklist.value.contains(word)) {
droppedWordsCounter.add(count)
false
} else {
true
}
}.collect().mkString("[", ", ", "]")
val output = "Counts at time " + time + " " + counts
})
3.5.3.10 部署应用
将项目打包成jar来部署。
要确保有足够的内存存中间结果。
Spark不会对读写日志进行加密,请手动加密。
更新应用
更新应用有两种方式:一种直接上传服务,然后新服务旧服务一块跑,等待黄金时机把旧服务去掉。 第二种,是直接把旧服务去掉,换成新服务。
3.5.3.11 监控应用
监控主要有两点,一种是批处理时间,一种是批处理等待时间。
3.5.4 SparkStreaming处理Kafka数据
-
修改server.properties
listeners=PLAINTEXT://tuge1:9092 advertised.listeners=PLAINTEXT://tuge1:9092 //这个配置是允许外部侦听,需要放开。tuge1是主机名,修改为你自己主机名即可。 -
开启zookeeper
> bin/zookeeper-server-start.sh config/zookeeper.properties -
开启server
> bin/kafka-server-start.sh config/server.properties -
创建主题
> bin/kafka-topics.sh --create --bootstrap-server tuge1:9092 --replication-factor 1 --partitions 1 --topic test -
构建生产者
> bin/kafka-console-producer.sh --broker-list tuge1:9092 --topic test -
编写代码让Spark处理Kafka数据
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaDemo") //注意local[n]n代表处理线程,它要大于接收器,不然只能接收数据,而没有线程处理数据 val streamingContext = new StreamingContext(conf, Seconds(1)) //这个设置的每隔1秒获取一次 val kafkaParam = Map[String, Object]( "bootstrap.servers" -> "tuge1:9092" //指定kafka服务 , "key.deserializer" -> classOf[StringDeserializer] //反序列化 , "value.deserializer" -> classOf[StringDeserializer] //反序列化 , "group.id" -> "use_a_separate_group_id_for_each_stream" , //latest:如果有已提交的offset,从提交的offset开始消费。如果没有提交的,则获取应用程序启动后生产者发送的数据。 //earliest:如果有已提交的offset,从提交的offset开始消费。如果没有提交的,则从头开始消费。 //none:如果有已提交的offset,从提交的的offset开始消费。如果没有,则抛出异常。 "auto.offset.reset" -> "latest" , "enable.auto.commit" -> (false: java.lang.Boolean) ) val topics = Array("test") val stream = KafkaUtils.createDirectStream[String, String]( streamingContext, PreferConsistent, Subscribe[String, String](topics, kafkaParam) ) stream.foreachRDD(f => { //遍历RDD if (f.count > 0) f.foreach(f => println(f.value())) //将每批RDD元素取出 }) streamingContext.start() //开始运行 streamingContext.awaitTermination() //运行等待,直到手动关闭程序 -
生产者输入一些信息

-
可以在控制台看到刚刚输入的信息,这样就使用Spark处理了Kafka数据。
3.6 性能调优
详细的调优指南参考页面,这里只列出最重要的几个调优。
3.6.1 减少批处理时间
3.6.1.1 数据接收并行度
通过将单个流转为多个流提高并行度。例如:
val numStreams = 5
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()
3.6.1.2 数据处理并行度
通过设置spark.default.parallelism来设置并行度,以充分利用系统性能。
3.6.1.3 序列化级别
有时候在流数据不大的情况下,可以禁用序列化,以降低序列化和反序列化带来的CPU和时间消耗。
3.6.2 设置正确批次间隔
在观察批处理间隔和批处理时间是否稳定,如果批处理时间很长,则需要优化,如降低批处理量。
3.7 容错语义
在本节中,我们将讨论发生故障时Spark Streaming应用程序的行为。
RDD自己是容错的,Spark 1.2 及以上也实现了容错机制,实现零数据丢失。
本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/12736702.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号