大数据基础---HDFS,Zookeeper,ZookeeperFailOverController(简称:ZKFC),JournalNode是什么?
HDFS介绍:
简述:
Hadoop Distributed File System(HDFS)是一种分布式文件系统,设计用于在商用硬件上运行。它与现有的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的差异很大。HDFS具有高度容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,适用于具有大型数据集的应用程序。HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。HDFS最初是作为Apache Nutch网络搜索引擎项目的基础设施而构建的。HDFS是Apache Hadoop Core项目的一部分。
主要成分:
HDFS主要由NameNode和DataNode组成。NameNode负责存储数据的元数据信息和数据的偏移量。DataNode负责存储数据。
数据进入先通过NameNode
NameNode在Hadoop1.x存在一个,在Hadoop2.x可以有两个了。推荐使用2.x,因为2.x相比1.x更能快速切换新的NameNode。
NameNode里面由EditLog和FsImage组成,EdtiLog记录的是操作日志,FsImage记录的所有文件的元数据(包括:文件大小,文件名称,创建时间等等)。另外FsImage还记录了文件的偏移量,不过这个偏移量是由DataNode做心跳机制反馈给NameNode的。当NameNode启动或者触发配置的检查点时,它会读取EditLog和FsImage,并使用EditLog应用到FsImage并加载到缓存,然后刷新EditLog。
我画了个交互图如下:

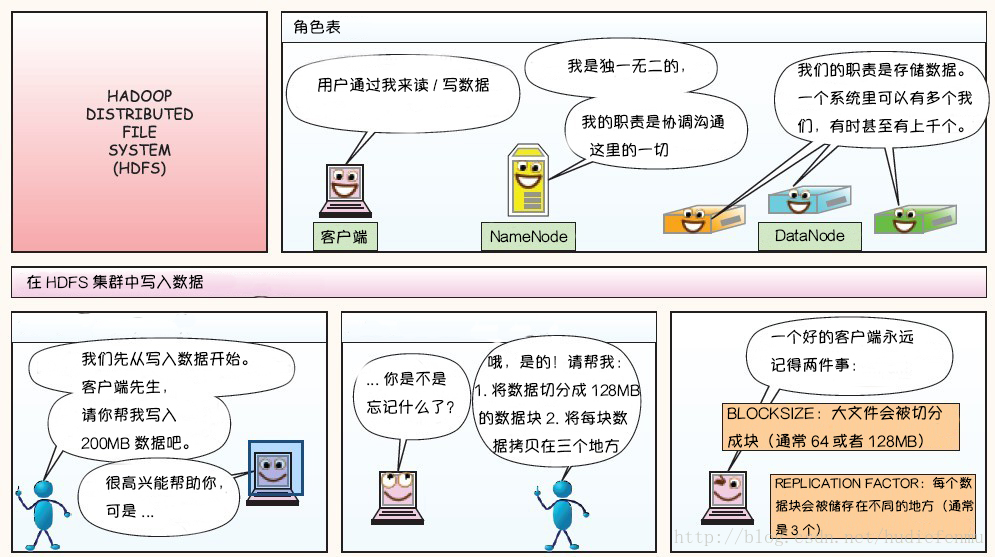
下面这则漫画摘自https://blog.csdn.net/hudiefenmu,他很形象的讲解了文件的写入原理,读取原理以及处理故障原理。
HDFS写数据原理:
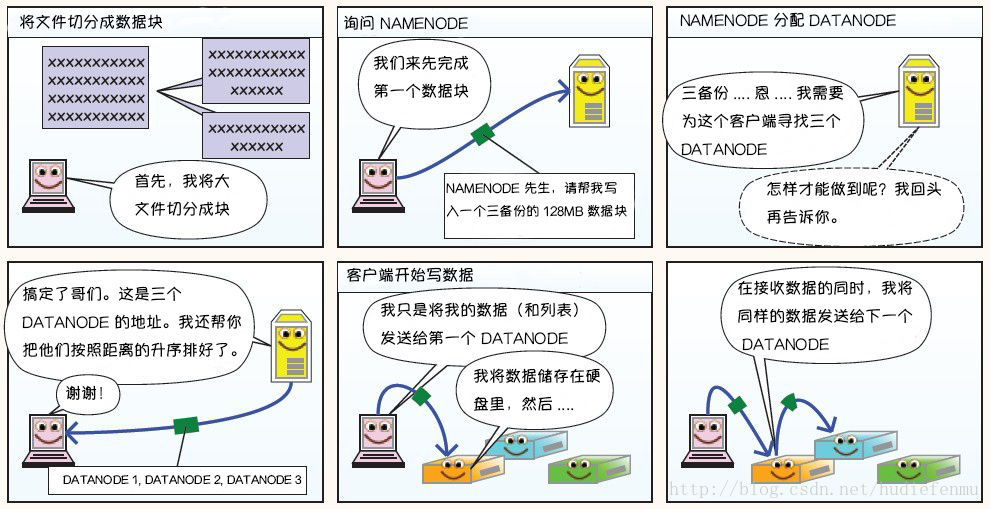
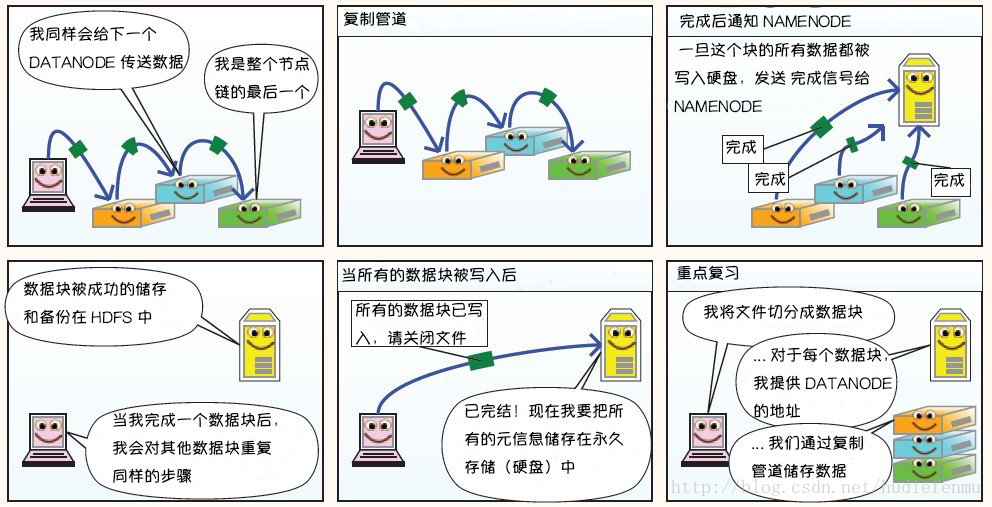
HDFS读数据原理:
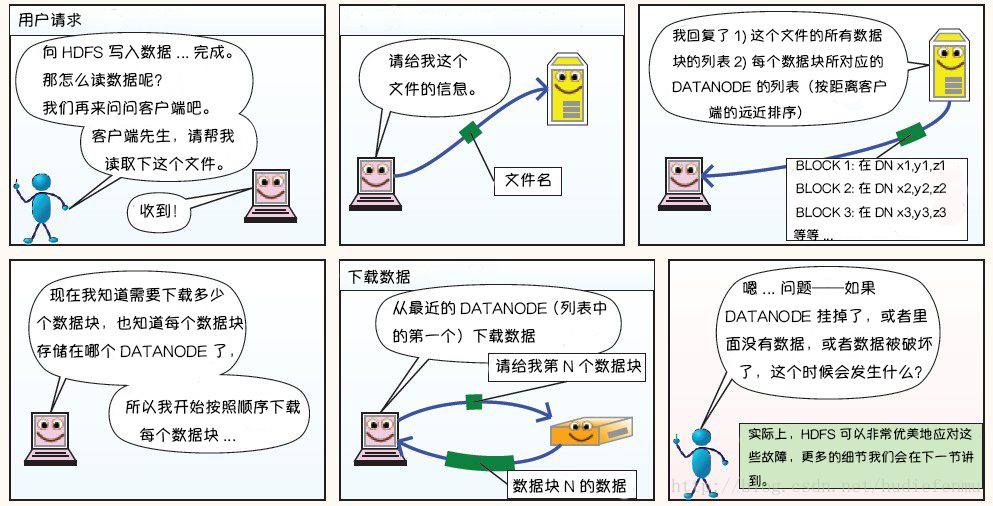
HDFS故障类型和其检测方法:
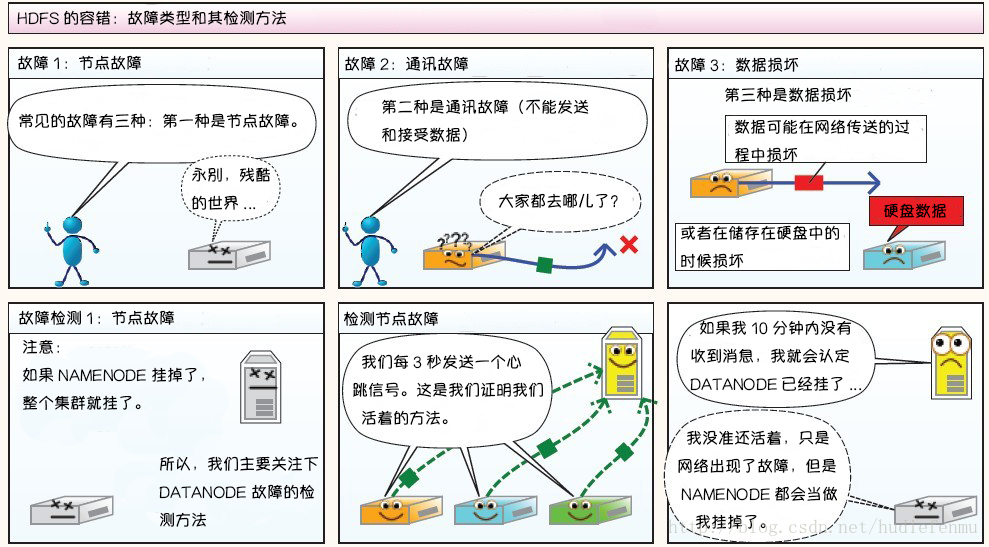
-读写故障的处理
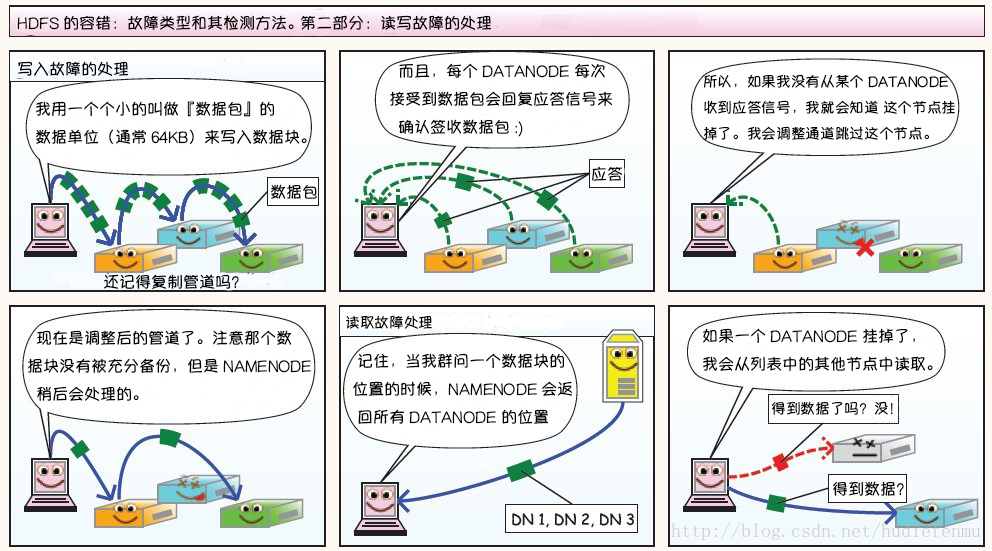
-DataNode故障处理
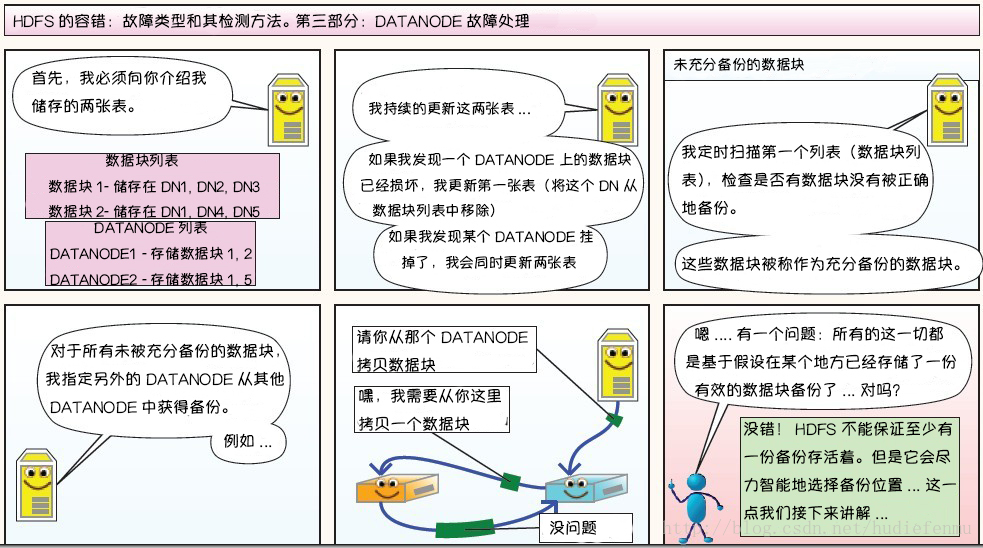
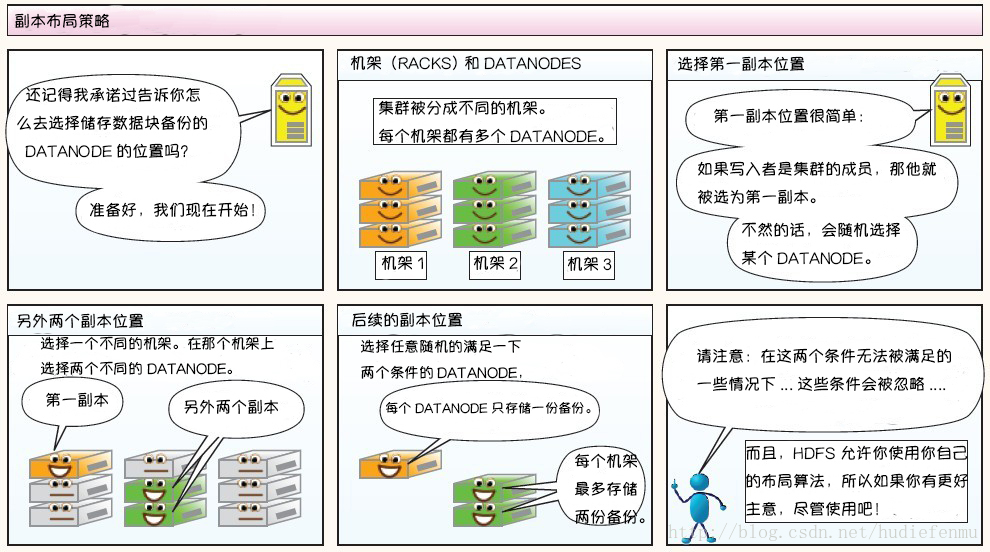
-副本布局策略
Quorum Journal Manager :
简述:
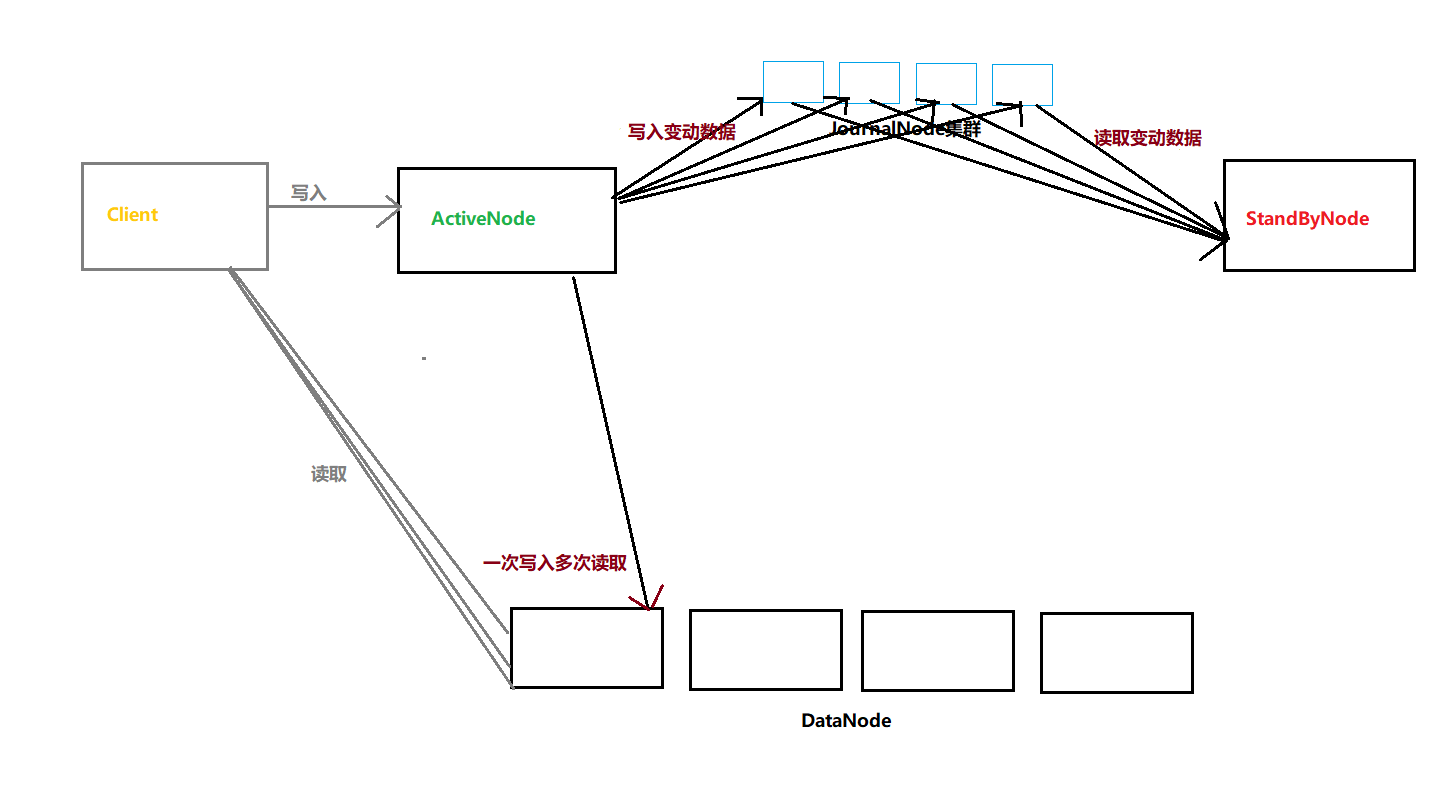
由于部署了两个NameNode,并且仅仅允许一台(ActiveNode)对外提供服务,另一台(StandByNode)在NameNode不可用的时候切换过去,这样就要保证StandBy数据是最新的。 而JournalManager就是接受ActiveNode的变动日志,然后StandBy节点读取同步更新数据。
结合上面的NameNode我画了个图如下:
Zookeeper和ZookeeperFailOverController介绍:
简述:
Zookeeper简称ZK,ZookeeperFailOverController简称ZKFC
上面使用JournalManager遇到故障的时候需要手动切换NameNode节点,这样处理会很不及时,所以必须想个办法自动切换,这样就有了Zookeeper,然后配套的出现了ZKFC,ZKFC和NameNode是一一对应的,它是一个守护进程,它负责和ZK通信,并且时刻检查NameNode的健康状况。它通过不断的ping,如果能ping通,则说明节点是健康的。然后ZKFC会和ZK保持一个持久通话,及Session对话,并且ActiveNode在ZK里面记录了一个"锁",这样就会Prevent其它节点成为ActiveNode,当会话丢失时,ZKFC会发通知给ZK,同时删掉"锁",这个时候其它NameNode会去争抢并建立新的“锁”,这个过程叫ZKFC的选举。
结合上面简要图如下:

本文来自博客园,作者:数据驱动,转载请注明原文链接:https://www.cnblogs.com/shun7man/p/11521290.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号