Spark单点安装、 使用sparkshell
Spark分布式安装
Spark安装注意:需要和本机的hadoop版本对应
前往spark选择自己相对应的版本下载之后进行解压
命令:tar –zxf spark-2.4.0-bin-hadoop2.6.tgz –C /usr/local
配置spark分布式,修改两个主要配置文件 spark-env.sh.template slaves.template slaves 留存备份
命令: cp spark-env.sh.template spark-env.sh
命令:cp slaves.template slaves
配置spark-env.sh
#SPARK
export JAVA_HOME=/usr/local/jdk1.8.0_192
export SCALA_HOME=/usr/local/scala
export SPARK_MASTER_IP=master
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_PID_DIR=/usr/local/hadoop/pids
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
配置slaves
删除localhost 增加 node1 node2
将配置好的spark复制到子节点
命令:scp –r /usr/local/spark node1:/usr/local
scp –r /usr/local/spark node2:/usr/local
尝试启动spark
命令:/usr/local/spark/sbin/start-all.sh

进入spark-shell查看spark启动是否成功
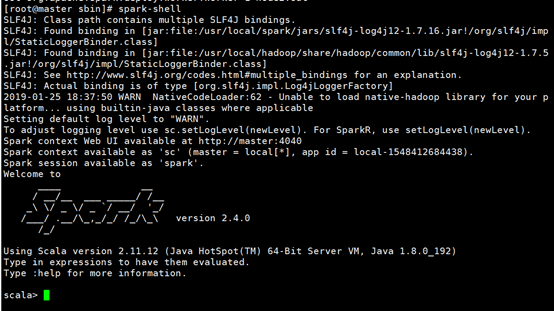
启动正常
为spark配置环境变量
命令:vim /etc/profile
#set SPARK_HOME
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
命令:source /etc/profile使配置生效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号