


Ch3——数据分析之Pandas模块的应用
Pandas模块的使用
1、 序列与数据框的介绍
(1)定义:
- 序列:是一种存储数据的容器,类似于一维数组,要求序列中的元素具有相同的数据类型。可以将其理解为数据集中的一个字段(列)。
- 数据框:同样是存储数据的容器,类似于二维数组,所不同的是,数据框中的每一列可以是不同的数据类型。数据框实际上是由多个序列组合而成的。
(2)序列构造方法:
- 通过同质的列表或元组构造;
- 通过字典构造;
- 通过Numpy中的一维数组构造;
- 通过数据框DataFrame中的某一列构造;
(3)序列构造范例:
# 序列构造Test
# 导入模块
import pandas as pd
import numpy as np
# 构造序列
gdp1 = pd.Series([2.8, 3.01, 8.99, 8.59, 5.18]) # 通过列表
gdp2 = pd.Series({'北京': 2.8, '上海': 3.01, '广东': 8.99, '江苏': 8.59, '浙江': 5.18}) # 通过集合
gdp3 = pd.Series(np.array((2.8, 3.01, 8.99, 8.59, 5.18))) # 通过一维数组
print(gdp1)
print(gdp2)
print(gdp3) # 打印结果同gdp1
输出结果: (pycharm输出)
0 2.80
1 3.01
2 8.99
3 8.59
4 5.18
dtype: float64
北京 2.80
上海 3.01
广东 8.99
江苏 8.59
浙江 5.18
dtype: float64
0 2.80
1 3.01
2 8.99
3 8.59
4 5.18
dtype: float64
(4)对序列构造(范例)的说明:
- 从序列的打印结果看,会包含两列内容,第一列属于序列的行索引(可以理解为行号),自动从0开始,第二列属于序列的实际值;
- 通过字典构造的序列仍然包含两列,所不同的是第一列不再是行号,而是行名称(label),其对应到字典中的键,第二列是序列的实际值,对应到字典中的值;
(5)序列返回元素的方法:
- 位置索引法:该用法与字符串中的索引或切片完全一致,除此还可以使用任意不连续的位置索引;
- 名称索引法:如果序列是通过字典构造,可以使用名称索引法取出对应的元素;
- 布尔索引法:该用法是结合条件表达式将序列中的元素取出;
(6)序列元素返回范例:
# 序列元素返回
# 导入模块
import pandas as pd
import numpy as np
# 构造序列
gdp1 = pd.Series([2.8, 3.01, 8.99, 8.59, 5.18]) # 通过列表
gdp2 = pd.Series({'北京': 2.8, '上海': 3.01, '广东': 8.99, '江苏': 8.59, '浙江': 5.18}) # 通过集合
gdp3 = pd.Series(np.array((2.8, 3.01, 8.99, 8.59, 5.18))) # 通过一维数组
# 取出序列gdp1中的第一、第四和第五个元素
print(gdp1[[0, 3, 4]])
# 取出序列gdp2中上海、江苏和浙江的GDP值
print(gdp2[['上海', '江苏', '浙江']])
# 取出序列gdp2中,GDP超过5.0的元素
print(gdp2[gdp2 > 5.0])
输出结果: (pycharm输出)
0 2.80
3 8.59
4 5.18
dtype: float64
上海 3.01
江苏 8.59
浙江 5.18
dtype: float64
广东 8.99
江苏 8.59
浙江 5.18
dtype: float64
(7)数据框构造的方法:
- 通过嵌套的列表或元组构造;
- 通过字典构造;
- 通过二维数组构造;
- 通过外部数据的读取构造;
(8)数据框构造范例:
# 数据框构造
import pandas as pd
import numpy as np
# 基于嵌套的列表
df1 = pd.DataFrame([['张三', 23, '男'], ['李四', 27, '女'], ['王二', 26, '女']])
# 基于字典
df2 = pd.DataFrame({'姓名': ['张三', '李四', '王二'], '年龄': [23, 27, 26], '性别': ['男', '女', '女']})
# 基于数组
df3 = pd.DataFrame(np.array([['张三', 23, '男'], ['李四', 27, '女'], ['王二', 26, '女']]))
print('嵌套列表构造数据框:\n', df1)
print('字典构造数据框:\n', df2)
print('二维数组构造数据框:\n', df3) # 输出结果同df1
输出结果: (pycharm输出)
嵌套列表构造数据框:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
字典构造数据框:
姓名 年龄 性别
0 张三 23 男
1 李四 27 女
2 王二 26 女
二维数组构造数据框:
0 1 2
0 张三 23 男
1 李四 27 女
2 王二 26 女
2、外部数据的读取
(1)文本文件的读取:
- pd.read_table(filepath_or_buffer, sep='\t', header='infer', names=None, usecols=None,skiprows=None, skipfooter=None, comment=None, encoding=None,parse_dates=False, thousands=None)
对上述属性的说明表
| 属性 | 说明 |
|---|---|
| filepath_or_buffer | 指定txt文件或csv文件所在的具体路径 |
| sep | 指定原数据集中各字段之间的分隔符,默认为Tab制表符 |
| header | 是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称 |
| names | 如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头 |
| index_col | 指定原数据集中的某些列作为数据框的行索引(标签) |
| usecols | 指定需要读取原数据集中的哪些变量名 |
| dtype | 读取数据时,可以为原数据集的每个字段设置不同的数据类型 |
| converters | 通过字典格式,为数据集中的某些字段设置转换函数 |
| skiprows | 数据读取时,指定需要跳过原数据集开头的行数 |
| skipfooter | 数据读取时,指定需要跳过原数据集末尾的行数 |
| nrows | 指定读取数据的行数 |
| na_values | 指定原数据集中哪些特征的值作为缺失值 |
| skip_blank_lines | 读取数据时是否需要跳过原数据集的空白行,默认True |
| comment | 指定注释符,在读取数据时,如果碰到行首指定的注释符,则跳过该行 |
| encoding | 如果文件中含有中文,有时需要指定字符编码 |
| parse_dates | 如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键) |
| thousands | 指定原始数据集中的千分位符 |
(2)文本文件读取范例:
1)问题提出:
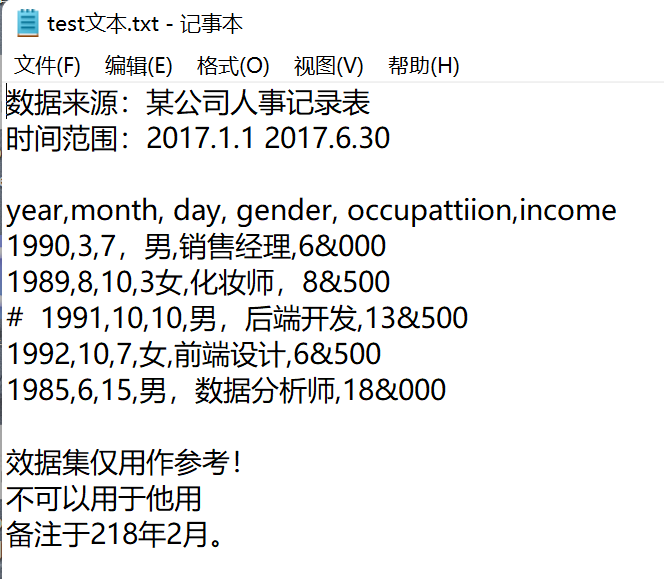
此文本中存在的问题:
- 数据集并不是从第一行开始,前面几行实际上是数据集的来源说明,读取数据时需要注意什么问题。
- 数据集的末尾3行仍然不是需要读入的数据,如何避免后3行数据的读入。
- 中间部分的数据,第四行前加了#号,表示不需要读取该行,该如何处理。
- 数据集中的收入一列,千分位符是&,如何将该字段读入为正常的数值型数据。
- 如果需要将year、month和day三个字段解析为新的birthday字段,该如何做到。
- 数据集中含有中文,一般在读取含中文的文本文件时都会出现编码错误,该如何解决
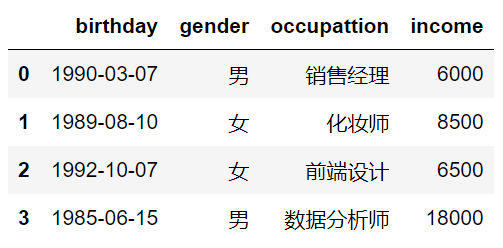
2)测试代码:
# 读取文本文件中的数据
import pandas as pd
user_income = pd.read_table(r"D:\Programming\Python\Jupyter File\ch5...chn测试文件夹\1文本文件读取测试.txt", sep=',', parse_dates={'birthday': [0, 1, 2]}, skiprows=2, skipfooter=3, comment='#',encoding='utf8', thousands='&', engine='python')
user_income
3)输出结果: (Jupyter Notebook输出)
(3)电子表格的读取:
- pd.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, parse_cols=None, parse_dates=False, na_values=None, thousands=None, convert_float=True)
对上述属性的说明表
| 属性 | 说明 |
|---|---|
| io | 指定电子表格的具体路径 |
| sheetname | 指定需要读取电子表格中的第几个Sheet,既可以传递整数也可以传递具体的Sheet名称 |
| header | 是否需要将数据集的第一行用作表头,默认为是需要的 |
| skiprows | 读取数据时,指定跳过的开始行数 |
| skip_footer | 读取数据时,指定跳过的末尾行数 |
| index_col | 指定哪些列用作数据框的行索引(标签) |
| names | 如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头 |
| parse_cols | 指定需要解析的字段 |
| parse_dates | 如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键) |
| na_values | 指定原始数据中哪些特殊值代表了缺失值 |
| thousands | 指定原始数据集中的千分位符 |
| convert_float | 默认将所有的数值型字段转换为浮点型字段 |
| converters | 通过字典的形式,指定某些列需要转换的形式 |
(4)电子表格读取范例:
1)问题提出:
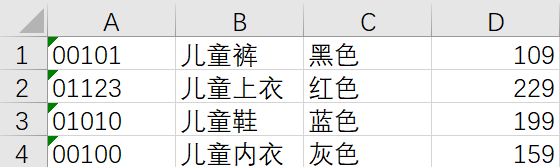
此excel存在的问题:
- 该表没有表头,如何读数据的同时就设置好具体的表头。
- 数据集的第一列实际上是字符型的字段,如何避免数据读入时自动变成数值型字段。
2)测试代码:
# 测试电子表格的读取
import pandas as pd
child_cloth = pd.read_excel(io=r"D:\Programming\Python\Jupyter File\ch5...chn测试文件夹\2电子表格读取测试.xlsx", header=None, converters={0:str},
names=['Prod_Id', 'Prod_Name', 'Prod_Color', 'Pro_Price'])
child_cloth
3)输出结果:(Jupyter Notebook输出)
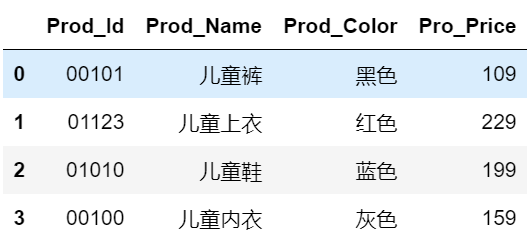
4)小结:
此处重点为,converters参数:通过该参数可以指定某些变量需要转换的函数。(此题中原数据集中的Prod_Id是字符型的,如果不将该参数设置为{0:str},读入的数据与原始的数据集就不一致了)
(5)数据库数据的读取:
1)连接MySQL
- pymysql.connect(host=None, user=None, password=‘’,database=None, port=0, charset=‘’)
对上述属性的说明表
| 属性 | 说明 |
|---|---|
| host | 指定需要访问的MySQL服务器 |
| user | 指定访问MySQL数据库的用户名 |
| password | 指定访问MySQL数据库的密码 |
| database | 指定访问MySQL数据库的具体库名 |
| port | 指定访问MySQL数据库的端口号 |
| charset | 指定读取MySQL数据库的字符集,如果数据库表中含有中文,一般可以尝试将该参数设置为“utf8”或“gbk” |
2)连接SQL Server
- pymssql.connect(server = None, user = None, password = None, database = None, charset = None)
对上述属性的说明表
| 属性 | 说明 |
|---|---|
| server | 指定需要访问的SQL服务器 |
| user | 指定访问SQL数据库的用户名 |
| password | 指定访问SQL数据库的密码 |
| database | 指定访问SQL数据库的具体库名 |
| charset | 指定读取SQL数据库的字符集,如果数据库表中含有中文,一般可以尝试将该参数设置为“utf8”或“gbk” |
3)数据库数据的读取:
- pd.read_sql(sql,con)
- pd.read_sql_table(table_name,con)
对上述属性的说明表
| 属性 | 说明 |
|---|---|
| sql | 指定SQL查询语句,将根据查询语句的逻辑返回对应的数据框 |
| con | 指定数据库与Python之间的连接器,即通过pymysql.connect函数或pymssql.connect构造的连接器 |
| table_name | 指定数据库中某张表的名称,将根据表名称返回对应的数据框 |
(6)数据库数据读取范例
1)问题提出(建表):
MySQL:

SQL server:

2)测试代码1(MySQL):
# 读取MySQL数据
# 导入第三方模块
import pymysql
import pandas as pd
# 连接MySQL数据库
conn = pymysql.connect(host='localhost', user='root', password='rootli',
database='Ch5_test', port=3306, charset='utf8') # database填写的是哪个数据库(新建的也行,用mysql的也行)
user = pd.read_sql('select * from student', conn) # from后面写表名
# 关闭连接
conn.close()
# 数据输出
user
3)输出结果1(MySQL):(Jupyter Notebook输出)

4)测试代码2(SQL server):无果
# SQL server被放弃了
3、数据类型转换及描述统计
(1)范例测试代码:
# 注:后面带有 '##' 的都是可以运行出结果的
import pandas as pd
# 数据读取
sec_cars = pd.read_table(r'D:\资料\机器学习\Python\从零开始\Python数据分析与挖掘源码\第5章 Python数据处理工具--Pandas\sec_cars.csv', sep = ',')
# 预览数据
print(sec_cars.head())
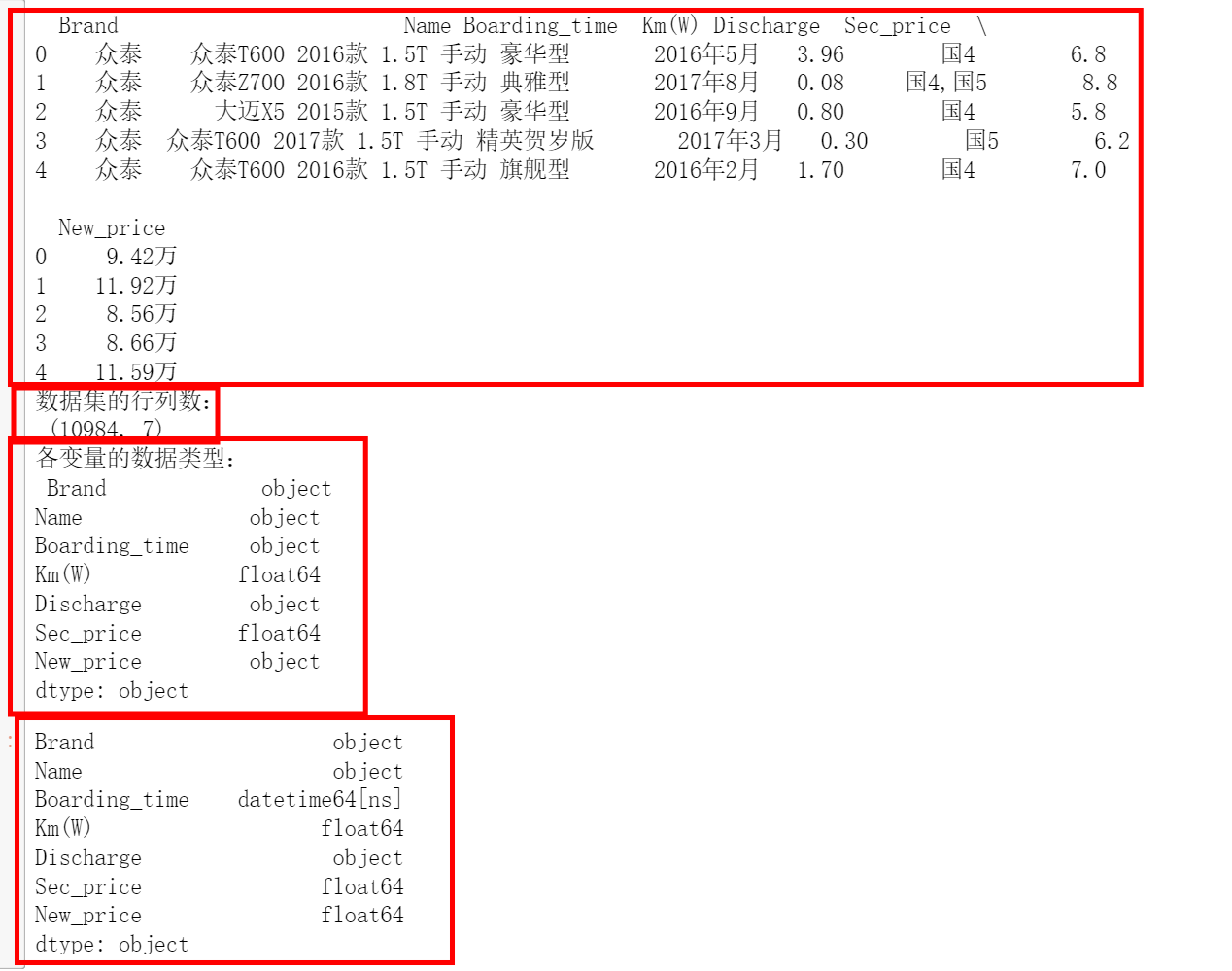
# 查看数据集的行列数
print('数据集的行列数:\n', sec_cars.shape)
# 查看数据每个变量的数据类型
print('各变量的数据类型:\n', sec_cars.dtypes)
# 修改二手车上牌时间的数据类型
sec_cars.Boarding_time = pd.to_datetime(sec_cars.Boarding_time, format = '%Y年%m月')
# 修改二手车新车价格的数据类型
sec_cars.New_price = sec_cars.New_price.str[:-1].astype('float')
# 重新查看各变量数据类型
sec_cars.dtypes ##
sec_cars.describe() ##
# 挑出所有数值型变量
num_variables = sec_cars.columns[sec_cars.dtypes != 'object'][:]
# 自定义函数,计算偏度和峰度
def skew_kurt(x):
skewness = x.skew()
kurtsis = x.kurt()
# 返回偏度值和峰度值
return pd.Series([skewness, kurtsis], index = ['Skew', 'Kurt'])
# 运行apply方法
sec_cars[num_variables].apply(func = skew_kurt, axis = 0) ##
# 离散型变量的统计描述
sec_cars.describe(include = ['object']) ##
# 离散变量频次统计
Freq = sec_cars.Discharge.value_counts()
Freq_ratio = Freq/sec_cars.shape[0]
Freq_df = pd.DataFrame({'Freq':Freq, 'Freq_ratio': Freq_ratio})
Freq_df.head() ##
# 将行索引重设为变量
Freq_df.reset_index(inplace = True)
Freq_df.head() ##
(2)输出结果:(Jupyter Notebook输出)
1)apply的:
| Km(W) | Sec_price | |
|---|---|---|
| Skew | 0.829915 | 6.313738 |
| Kurt | 2.406258 | 55.381915 |
2)object的:
| Brand | Name | Boarding_time | Discharge | New_price | |
|---|---|---|---|---|---|
| count | 10984 | 10984 | 10984 | 10984 | 10984 |
| unique | 104 | 4374 | 187 | 33 | 1658 |
| top | 别克 | 经典全顺 2010款 柴油 短轴 多功能 中顶 6座 | 2010年8月 | 国4 | 12.14万 |
| freq | 1346 | 126 | 223 | 4262 | 129 |
3)离散变量频次统计
| Freq | Freq_ratio | |
|---|---|---|
| 国4 | 4262 | 0.388019 |
| 欧4 | 1848 | 0.168245 |
| 欧5 | 1131 | 0.102968 |
| 国4,国5 | 843 | 0.076748 |
| 国3 | 772 | 0.070284 |
4)将行索引重设为变量
| Freq | Freq_ratio | |
|---|---|---|
| 国4 | 4262 | 0.388019 |
| 欧4 | 1848 | 0.168245 |
| 欧5 | 1131 | 0.102968 |
| 国4,国5 | 843 | 0.076748 |
| 国3 | 772 | 0.070284 |
4、字符与日期数据的处理:
(1)常用的日期时间处理“方法”
| 方法 | 含义 | 方法 | 含义 |
|---|---|---|---|
| year | 返回年份 | month | 返回月份 |
| day | 返回月份中的日 | hour | 返回时 |
| minute | 返回分钟 | second | 返回秒 |
| date | 返回日期 | time | 返回时间 |
| dayofyear | 返回一年中的第几天 | weekofyear | 返回年中的第几周 |
| dayofweek | 返回一周中的第几天 | weekday_name(测试中用不了) | 返回具体的周几名称 |
| quarter | 返回第几季度 | days_in_month | 返回月中多少天 |
(2)范例测试代码1:
import pandas as pd
# 数据读入
df = pd.read_excel(r'D:\资料\机器学习\Python\从零开始\Python数据分析与挖掘源码\第5章 Python数据处理工具--Pandas\data_test03.xlsx')
# 各变量数据类型
df.dtypes
# 将birthday变量转换为日期型
df.birthday = pd.to_datetime(df.birthday, format = '%Y/%m/%d')
# 将手机号转换为字符串
df.tel = df.tel.astype('str')
# 新增年龄和工龄两列
df['age'] = pd.datetime.today().year - df.birthday.dt.year
df['workage'] = pd.datetime.today().year - df.start_work.dt.year
# 将手机号中间4位数隐藏起来
df.tel = df.tel.apply(func = lambda x : x.replace(x[3:7], '****'))
# 取出邮箱域名
df['email_domain'] = df.email.apply(func = lambda x : x.split('@')[1])
# 去专业人员的专业信息
df['profession'] = df.other.str.findall('专业:(.*?),')
# 去除birthday、start_work和other变量
df .drop(['birthday', 'start_work', 'other'], axis = 1, inplace = True)
df.head()
(3)输出结果1:(Jupyter Notebook输出)
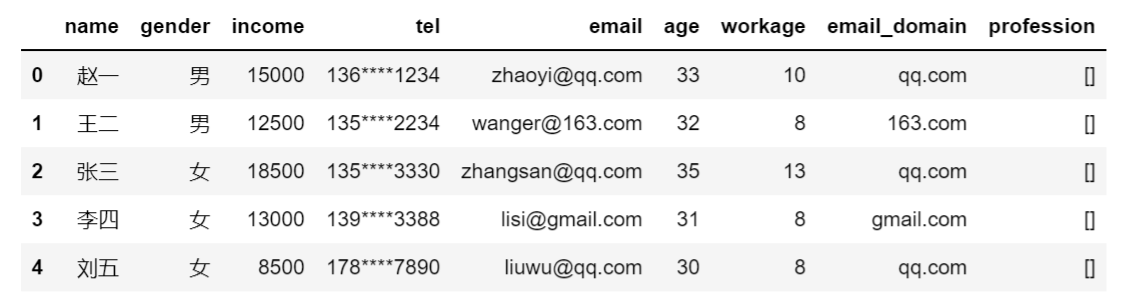
(4)测试代码2:(关于日期时间的测试)
import pandas as pd
# 常用日期处理方法
dates = pd.to_datetime(pd.Series(['1989-8-18 13:14:55', '1995-2-16']),
format = '%Y-%m-%d %H:%M:%S')
print('返回日期值:\n', dates.dt.date)
print('返回季度:\n', dates.dt.quarter)
print('返回几点钟:\n', dates.dt.hour)
print('返回年中的几天:\n', dates.dt.dayofyear)
print('返回年中的周:\n', dates.dt.weekofyear)
print('返回星期几:\n', dates.dt.day_name(locale = 'English'))
print('返回月份的天数:', dates.dt.days_in_month)
(5)输出结果2:
返回日期值:
0 1989-08-18
1 1995-02-16
dtype: object
返回季度:
0 3
1 1
dtype: int64
返回几点钟:
0 13
1 0
dtype: int64
返回年中的几天:
0 230
1 47
dtype: int64
返回年中的周:
0 33
1 7
dtype: int64
返回星期几:
0 Friday
1 Thursday
dtype: object
返回月份的天数: 0 31
1 28
dtype: int64
5、数据的清洗:
(1)数据类型的转换:
- 对于数值型、字符型、布尔型等类型的转换可以使用astype方法;
- 对于日期时间型的转换需使用to_datetime函数;
(2)数据类型转换范例:
1)问题:
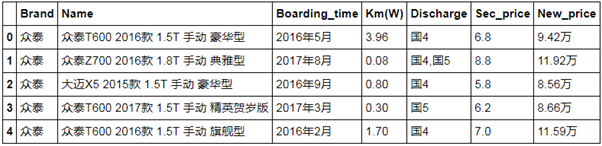
- 二手车的上牌时间Boarding_time应该为日期型;
- 新车价格New_price应该为浮点型;
2)测试代码:
import pandas as pd
# 数据读取
sec_cars = pd.read_table(r'D:\资料\机器学习\Python\从零开始\Python数据分析与挖掘源码\第5章 Python数据处理工具--Pandas\sec_cars.csv', sep = ',')
# 预览数据
print(sec_cars.head())
# 查看数据集的行列数
print('数据集的行列数:\n', sec_cars.shape)
# 查看数据每个变量的数据类型
print('各变量的数据类型:\n', sec_cars.dtypes)
# 修改二手车上牌时间的数据类型
sec_cars.Boarding_time = pd.to_datetime(sec_cars.Boarding_time, format = '%Y年%m月')
# 修改二手车新车价格的数据类型
sec_cars.New_price = sec_cars.New_price.str[:-1].astype('float')
# 重新查看各变量数据类型
sec_cars.dtypes
3)输出结果:(Jupyter Notebook输出)
(3)重复观察的识别与处理:(专用duplicated方法检测)
1)范例问题:
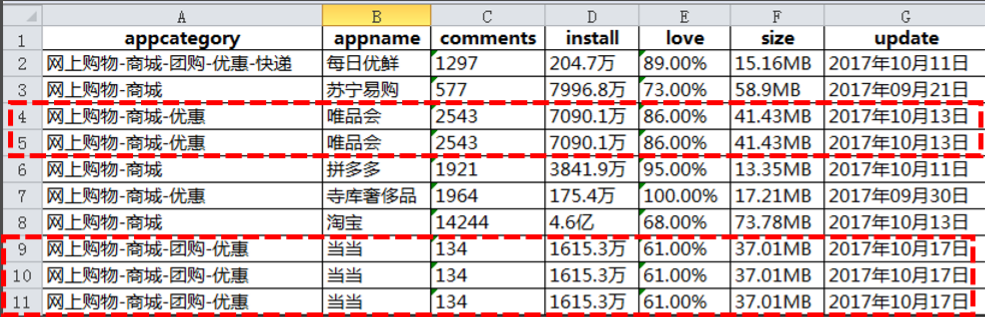
2)测试代码:
# 数据读入
df = pd.read_excel(r'C:\Users\Administrator\Desktop\data_test04.xlsx')
# 重复观测的检测
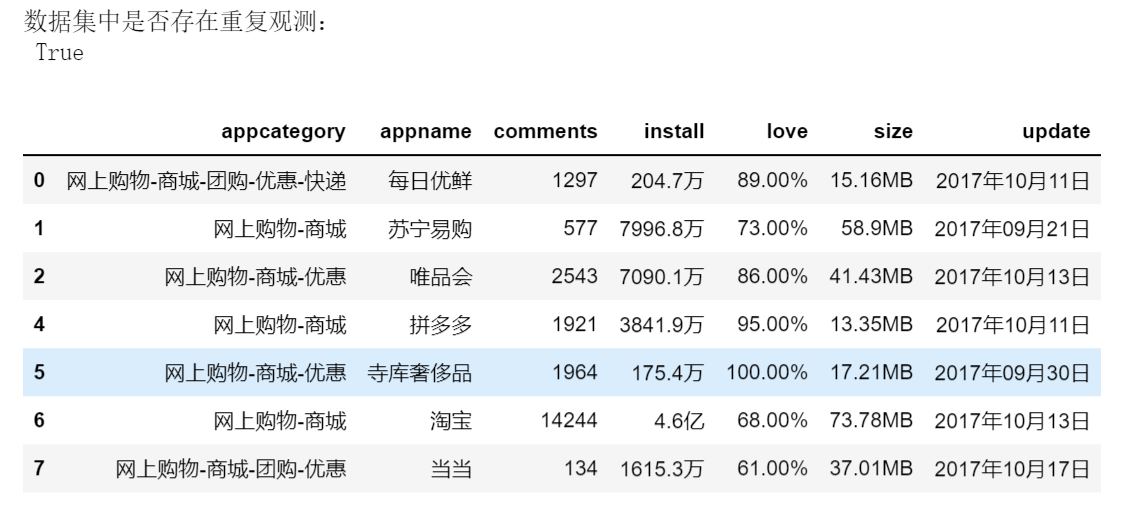
print('数据集中是否存在重复观测:\n',any(df.duplicated()))
# 删除重复项
df.drop_duplicates(inplace = True)
df
3)输出结果:(Jupyter Notebook输出)
(4)缺失值的识别和处理:(专用isnull方法检测)
1)范例问题:
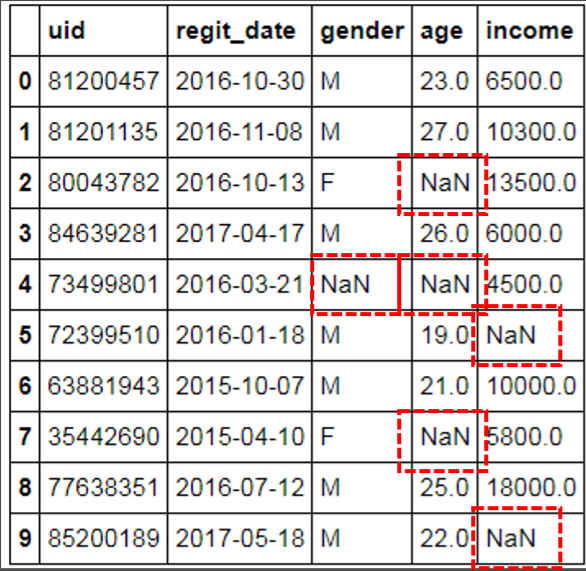
2)测试代码:
①删除之记录删除:
import pandas as pd
# 数据读入
df = pd.read_excel(r'C:\Users\Administrator\Desktop\data_test05.xlsx')
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
# 删除法之记录删除
print('删除法之记录删除:\n', df.dropna())
②删除之变量删除:
import pandas as pd
# 数据读入
df = pd.read_excel(r'C:\Users\Administrator\Desktop\data_test05.xlsx')
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
# 删除法之变量删除
print('删除法之变量删除:\n', df.drop('age', axis = 1))
③替换之前向替换:
import pandas as pd
# 数据读入
df = pd.read_excel(r'C:\Users\Administrator\Desktop\data_test05.xlsx')
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
# 替换法之前向替换
print('替换法之前向替换:\n', df.fillna(method = 'ffill’))
④替换之后向替换:
import pandas as pd
# 数据读入
df = pd.read_excel(r'C:\Users\Administrator\Desktop\data_test05.xlsx')
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
# 替换法之后向替换
print('替换法之后向替换:\n', df.fillna(method = 'bfill'))
⑤替换之常数替换:
import pandas as pd
# 数据读入
df = pd.read_excel(r'C:\Users\Administrator\Desktop\data_test05.xlsx')
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
# 替换法之常数替换
print('替换法之常数替换:\n', df.fillna(value = 0))
⑥替换之统计值替换:
import pandas as pd
# 数据读入
df = pd.read_excel(r'C:\Users\Administrator\Desktop\data_test05.xlsx')
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(df.isnull()))
# 替换法之统计值替换
print('替换法之统计值替换:\n',
df.fillna(value = {'gender':df.gender.mode()[0], 'age':df.age.mean(),
'income':df.income.median()})
3)输出结果:(Jupyter Notebook)
①删除法之记录删除:
数据集中是否存在缺失值:
True
删除法之记录删除:
uid regit_date gender age income
0 81200457 2016-10-30 M 23.0 6500.0
1 81201135 2016-11-08 M 27.0 10300.0
3 84639281 2017-04-17 M 26.0 6000.0
6 63881943 2015-10-07 M 21.0 10000.0
8 77638351 2016-07-12 M 25.0 18000.0
②删除法之变量删除:
数据集中是否存在缺失值:
True
删除法之变量删除:
uid regit_date gender income
0 81200457 2016-10-30 M 6500.0
1 81201135 2016-11-08 M 10300.0
2 80043782 2016-10-13 F 13500.0
3 84639281 2017-04-17 M 6000.0
4 73499801 2016-03-21 NaN 4500.0
5 72399510 2016-01-18 M NaN
6 63881943 2015-10-07 M 10000.0
7 35442690 2015-04-10 F 5800.0
8 77638351 2016-07-12 M 18000.0
9 85200189 2017-05-18 M NaN
③替换法之前向替换:
数据集中是否存在缺失值:
True
替换法之前向替换:
uid regit_date gender age income
0 81200457 2016-10-30 M 23.0 6500.0
1 81201135 2016-11-08 M 27.0 10300.0
2 80043782 2016-10-13 F 27.0 13500.0
3 84639281 2017-04-17 M 26.0 6000.0
4 73499801 2016-03-21 M 26.0 4500.0
5 72399510 2016-01-18 M 19.0 4500.0
6 63881943 2015-10-07 M 21.0 10000.0
7 35442690 2015-04-10 F 21.0 5800.0
8 77638351 2016-07-12 M 25.0 18000.0
9 85200189 2017-05-18 M 22.0 18000.0
④替换法之后向替换:
数据集中是否存在缺失值:
True
替换法之后向替换:
uid regit_date gender age income
0 81200457 2016-10-30 M 23.0 6500.0
1 81201135 2016-11-08 M 27.0 10300.0
2 80043782 2016-10-13 F 26.0 13500.0
3 84639281 2017-04-17 M 26.0 6000.0
4 73499801 2016-03-21 M 19.0 4500.0
5 72399510 2016-01-18 M 19.0 10000.0
6 63881943 2015-10-07 M 21.0 10000.0
7 35442690 2015-04-10 F 25.0 5800.0
8 77638351 2016-07-12 M 25.0 18000.0
9 85200189 2017-05-18 M 22.0 NaN
⑤替换法之同级值替换:
数据集中是否存在缺失值:
True
替换法之同级值替换:
uid regit_date gender age income
0 81200457 2016-10-30 M 23.0 6500.0
1 81201135 2016-11-08 M 27.0 10300.0
2 80043782 2016-10-13 F 0.0 13500.0
3 84639281 2017-04-17 M 26.0 6000.0
4 73499801 2016-03-21 0 0.0 4500.0
5 72399510 2016-01-18 M 19.0 0.0
6 63881943 2015-10-07 M 21.0 10000.0
7 35442690 2015-04-10 F 0.0 5800.0
8 77638351 2016-07-12 M 25.0 18000.0
9 85200189 2017-05-18 M 22.0 0.0
⑥替换法之统计替换:
数据集中是否存在缺失值:
True
替换法之统计替换:
uid regit_date gender age income
0 81200457 2016-10-30 M 23.000000 6500.0
1 81201135 2016-11-08 M 27.000000 10300.0
2 80043782 2016-10-13 F 23.285714 13500.0
3 84639281 2017-04-17 M 26.000000 6000.0
4 73499801 2016-03-21 M 23.285714 4500.0
5 72399510 2016-01-18 M 19.000000 8250.0
6 63881943 2015-10-07 M 21.000000 10000.0
7 35442690 2015-04-10 F 23.285714 5800.0
8 77638351 2016-07-12 M 25.000000 18000.0
9 85200189 2017-05-18 M 22.000000 8250.0
(5)异常值的识别和处理:
1)范例问题:
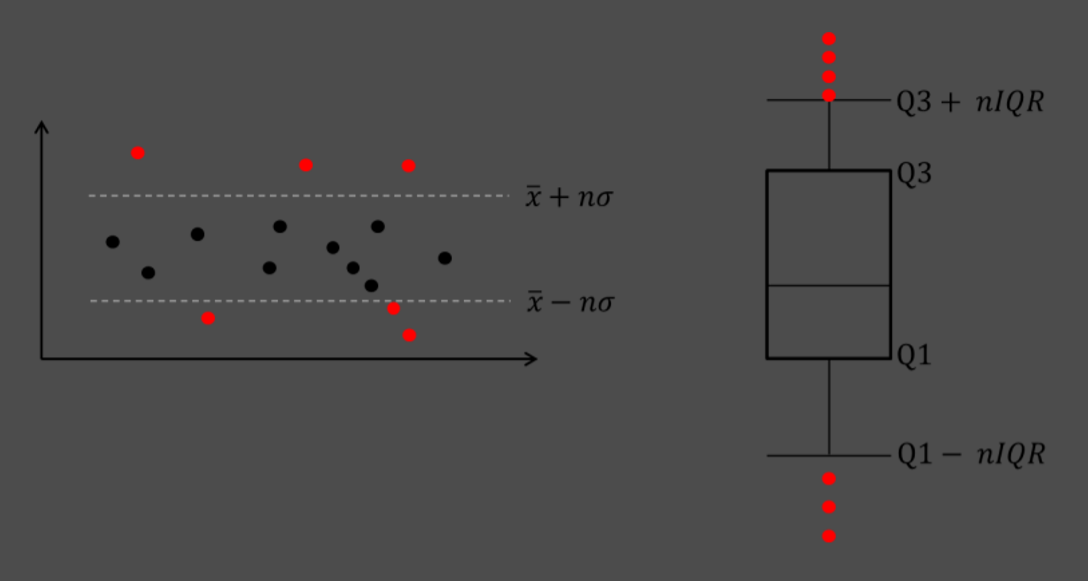
2)测试代码:
import pandas as pd
# 数据读入
sunspots = pd.read_table(r"D:\资料\机器学习\Python\从零开始\Python数据分析与挖掘源码\第5章 Python数据处理工具--Pandas\sunspots.csv", sep = ',')
# 异常值检测之标准差法
xbar = sunspots.counts.mean()
xstd = sunspots.counts.std()
print('标准差法异常值上限检测:\n',any(sunspots.counts > xbar + 2 * xstd))
print('标准差法异常值下限检测:\n',any(sunspots.counts < xbar - 2 * xstd))
# 异常值检测之箱线图法
Q1 = sunspots.counts.quantile(q = 0.25)
Q3 = sunspots.counts.quantile(q = 0.75)
IQR = Q3 - Q1
print('箱线图法异常值上限检测:\n',any(sunspots.counts > Q3 + 1.5 * IQR))
print('箱线图法异常值下限检测:\n',any(sunspots.counts < Q1 - 1.5 * IQR))
# 设置绘图风格
plt.style.use('ggplot')
# 绘制直方图
sunspots.counts.plot(kind = 'hist', bins = 30, density = True) # 原本density为normed
# 绘制核密度图
sunspots.counts.plot(kind = 'kde')
# 图形展现
plt.show()
# 替换法处理异常值
print('异常值替换前的数据统计特征:\n',sunspots.counts.describe())
# 箱线图中的异常值判别上限
UL = Q3 + 1.5 * IQR
print('判别异常值的上限临界值:\n',UL)
# 从数据中找出低于判别上限的最大值
replace_value = sunspots.counts[sunspots.counts < UL].max()
print('用以替换异常值的数据:\n',replace_value)
# 替换超过判别上限异常值
sunspots.counts[sunspots.counts > UL] = replace_value
print('异常值替换后的数据统计特征:\n',sunspots.counts.describe())
3)输出结果: (Jupyter Notebook 输出)
标准差法异常值上限检测:
True
标准差法异常值下限检测:
False
箱线图法异常值上限检测:
True
箱线图法异常值下限检测:
False
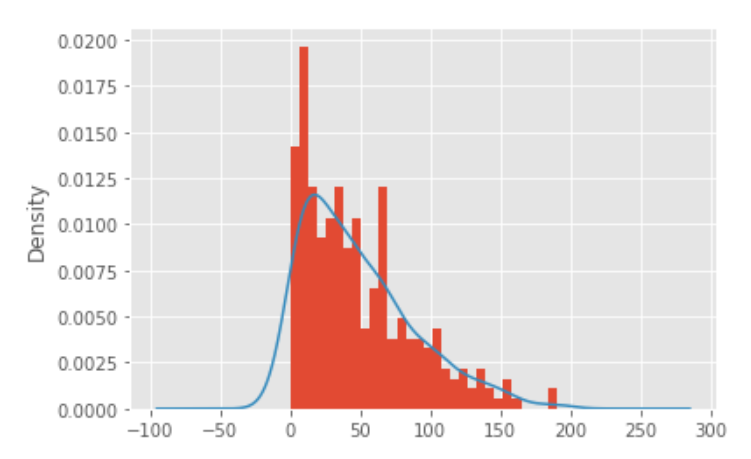
异常值替换前的数据统计特征:
count 289.000000
mean 48.613495
std 39.474103
min 0.000000
25% 15.600000
50% 39.000000
75% 68.900000
max 190.200000
Name: counts, dtype: float64
判别异常值的上限临界值:
148.85000000000002
用以替换异常值的数据:
141.7
异常值替换后的数据统计特征:
count 289.000000
mean 48.066090
std 37.918895
min 0.000000
25% 15.600000
50% 39.000000
75% 68.900000
max 141.700000
Name: counts, dtype: float64
(6)数据子集的筛选:
1)定义:
- iloc只能通过行号和列号进行数据的筛选;
- loc要比iloc灵活一些,可以指定具体的行标签(或条件表达式)和列标签(字段名);
- 已移除‘ix’:ix是iloc和loc的混合,其吸收了iloc和loc的优点,使数据框子集的获取更加灵活;
2)范例测试代码:
import pandas as pd
# 构造数据集
df1 = pd.DataFrame({'name':['张三','李四','王二','丁一','李五'],
'gender':['男','女','女','女','男'],
'age':[23,26,22,25,27]},
columns = ['name','gender','age'])
print('输出原表:\n', df1)
# 取出数据集的中间三行(即所有女性),并且返回姓名和年龄两列
print('取出中间三行[不带性别](iloc):\n', df1.iloc[1:4,[0,2]])
print('取出中间三行[不带性别](loc):\n', df1.loc[1:3, ['name','age']])
# df1.ix[1:3,[0,2]] # ix已移除
# 将员工的姓名用作行标签
df2 = df1.set_index('name')
print('name表:\n', df2)
# 取出数据集的中间三行
print('取出数据集的中间三行[带性别](iloc):\n', df2.iloc[1:4,:])
print('取出数据集的中间三行[带性别](loc):\n', df2.loc[['李四','王二',
'丁一'],:])
# 使用筛选条件,取出所有男性的姓名和年龄
print('取出所有男性的姓名和年龄(loc):\n', df1.loc[df1.gender == '男',
['name','age']])
3)输出结果:(Jupyter Notebook输出)
①原表:
| name | gender | age | |
|---|---|---|---|
| 0 | 张三 | 男 | 23 |
| 1 | 李四 | 女 | 26 |
| 2 | 王二 | 女 | 22 |
| 3 | 丁一 | 女 | 25 |
| 4 | 李五 | 男 | 27 |
②取出中间三行1【不带性别】:
| name | age | |
|---|---|---|
| 1 | 李四 | 26 |
| 2 | 王二 | 22 |
| 3 | 丁一 | 25 |
③取出中间三行2【带性别】:
| name | gender | age |
|---|---|---|
| 李四 | 女 | 26 |
| 王二 | 女 | 22 |
| 丁一 | 女 | 25 |
④取出所有男性的姓名和年龄:
| name | age | |
|---|---|---|
| 0 | 张三 | 23 |
| 4 | 李五 | 27 |
6、数据汇总:
(1)Excel中的透视表:
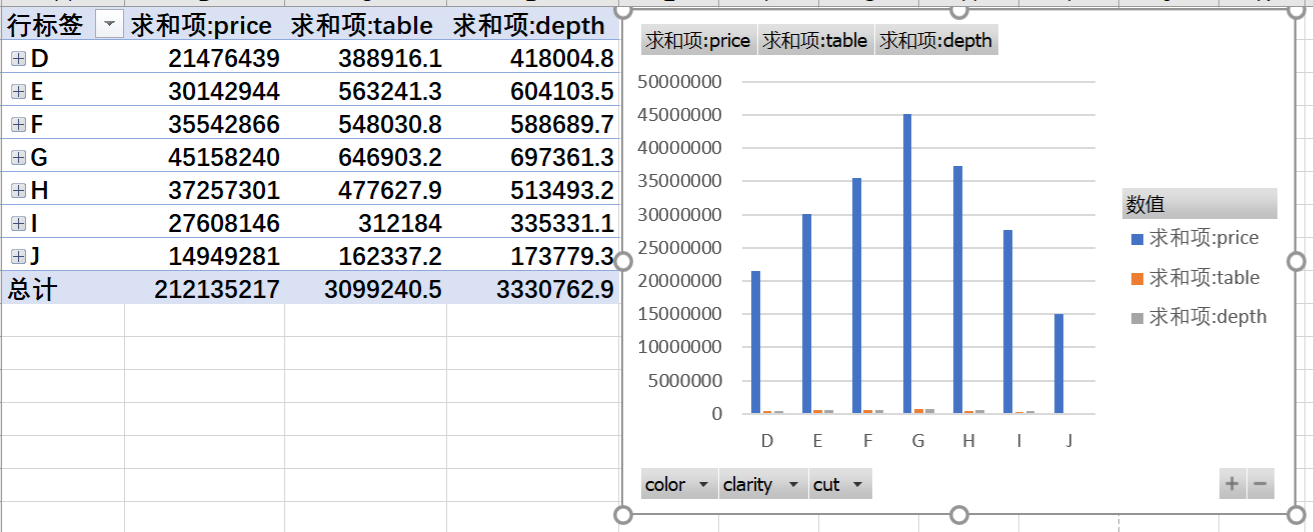
(2)Python中的透视表:
1)对属性的说明:
- pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
对上述属性的说明表
| 属性 | 说明 |
|---|---|
| data | 指定需要构造透视表的数据集 |
| values | 指定需要拉入“数值”框的字段列表 |
| index | 指定需要拉入“行标签”框的字段列表 |
| columns | 指定需要拉入“列标签”框的字段列表 |
| aggfunc | 指定数值的统计函数,默认为统计均值,也可以指定numpy模块中的其他统计函数 |
| fill_value | 指定一个标量,用于填充缺失值 |
| margins | bool类型参数,是否需要显示行或列的总计值,默认为False |
| dropna | bool类型参数,是否需要删除整列为缺失的字段,默认为True |
| margins_name | 指定行或列的总计名称,默认为All |
2)范例测试代码:
import pandas as pd
import numpy as np
# 数据读取
diamonds = pd.read_table(r"D:\资料\机器学习\Python\从零开始\Python数据分析与挖掘源码\第5章 Python数据处理工具--Pandas\diamonds.csv", sep = ',')
# 单个分组变量的均值统计
print('单个分组变量的均值统计:\n', pd.pivot_table(data = diamonds, index = 'color', values = 'price', margins = True,margins_name = '总计'))
# 两个分组变量的列联表
print('两个分组变量的均值统计:\n', pd.pivot_table(data = diamonds, index = 'clarity', columns = 'cut', values = 'carat',
aggfunc = np.size, margins = True, margins_name = '总计'))
3)输出结果:(Jupyter Notebook输出)
单个分组变量的均值统计:
color price
D 3169.954096
E 3076.752475
F 3724.886397
G 3999.135671
H 4486.669196
I 5091.874954
J 5323.818020
总计 3932.799722
两个分组变量的均值统计:
cut Fair Good Ideal Premium Very Good 总计
clarity
I1 210.0 96.0 146.0 205.0 84.0 741.0
IF 9.0 71.0 1212.0 230.0 268.0 1790.0
SI1 408.0 1560.0 4282.0 3575.0 3240.0 13065.0
SI2 466.0 1081.0 2598.0 2949.0 2100.0 9194.0
VS1 170.0 648.0 3589.0 1989.0 1775.0 8171.0
VS2 261.0 978.0 5071.0 3357.0 2591.0 12258.0
VVS1 17.0 186.0 2047.0 616.0 789.0 3655.0
VVS2 69.0 286.0 2606.0 870.0 1235.0 5066.0
总计 1610.0 4906.0 21551.0 13791.0 12082.0 53940.0
(3)数据库中的分组统计
1)范例测试代码:
(4)Python中的分组汇总:
1)分组汇总的属性:
-
groupby“方法”:用于汇总前,设定被分组的变量;
-
aggregate“方法”:可基于groupby的结果做进一步的统计汇总;
-
注:在aggregate阶段,需以字典的形式传递参数,用于选择被统计的变量和对应的统计方法;
2)范例测试代码:
import pandas as pd
import numpy as np
# 数据读取
diamonds = pd.read_table(r"D:\资料\机器学习\Python\从零开始\Python数据分析与挖掘源码\第5章 Python数据处理工具--Pandas\diamonds.csv", sep = ',')
# 通过groupby方法,指定分组变量
grouped = diamonds.groupby(by = ['color','cut'])
# 对分组变量进行统计汇总
result = grouped.aggregate({'color':np.size, 'carat':np.min,
'price':np.mean})
print(result) # ①
# 调整变量名的顺序
result = pd.DataFrame(result, columns=['color','carat','price'])
print(result) # ②
# 数据集重命名
result.rename(columns={'color':'counts','carat':'min_weight','price':'avg_price'}, inplace=True)
print(result) # ③
# 将行索引转换为数据框的变量
result.reset_index(inplace=True)
result # ④
3)输出结果:(Jupyter Notebook输出)
第一次输出result:
color carat price
color cut
D Fair 163 0.25 4291.061350
Good 662 0.23 3405.382175
Ideal 2834 0.20 2629.094566
Premium 1603 0.20 3631.292576
Very Good 1513 0.23 3470.467284
E Fair 224 0.22 3682.312500
Good 933 0.23 3423.644159
Ideal 3903 0.20 2597.550090
Premium 2337 0.20 3538.914420
Very Good 2400 0.20 3214.652083
F Fair 312 0.25 3827.003205
Good 909 0.23 3495.750275
Ideal 3826 0.23 3374.939362
Premium 2331 0.20 4324.890176
Very Good 2164 0.23 3778.820240
G Fair 314 0.23 4239.254777
Good 871 0.23 4123.482204
Ideal 4884 0.23 3720.706388
Premium 2924 0.23 4500.742134
Very Good 2299 0.23 3872.753806
H Fair 303 0.33 5135.683168
Good 702 0.25 4276.254986
Ideal 3115 0.23 3889.334831
Premium 2360 0.23 5216.706780
Very Good 1824 0.23 4535.390351
I Fair 175 0.41 4685.445714
Good 522 0.30 5078.532567
Ideal 2093 0.23 4451.970377
Premium 1428 0.23 5946.180672
Very Good 1204 0.24 5255.879568
J Fair 119 0.30 4975.655462
Good 307 0.28 4574.172638
Ideal 896 0.23 4918.186384
Premium 808 0.30 6294.591584
Very Good 678 0.24 5103.513274
第二次输出result:
color carat price
color cut
D Fair 163 0.25 4291.061350
Good 662 0.23 3405.382175
Ideal 2834 0.20 2629.094566
Premium 1603 0.20 3631.292576
Very Good 1513 0.23 3470.467284
E Fair 224 0.22 3682.312500
Good 933 0.23 3423.644159
Ideal 3903 0.20 2597.550090
Premium 2337 0.20 3538.914420
Very Good 2400 0.20 3214.652083
F Fair 312 0.25 3827.003205
Good 909 0.23 3495.750275
Ideal 3826 0.23 3374.939362
Premium 2331 0.20 4324.890176
Very Good 2164 0.23 3778.820240
G Fair 314 0.23 4239.254777
Good 871 0.23 4123.482204
Ideal 4884 0.23 3720.706388
Premium 2924 0.23 4500.742134
Very Good 2299 0.23 3872.753806
H Fair 303 0.33 5135.683168
Good 702 0.25 4276.254986
Ideal 3115 0.23 3889.334831
Premium 2360 0.23 5216.706780
Very Good 1824 0.23 4535.390351
I Fair 175 0.41 4685.445714
Good 522 0.30 5078.532567
Ideal 2093 0.23 4451.970377
Premium 1428 0.23 5946.180672
Very Good 1204 0.24 5255.879568
J Fair 119 0.30 4975.655462
Good 307 0.28 4574.172638
Ideal 896 0.23 4918.186384
Premium 808 0.30 6294.591584
Very Good 678 0.24 5103.513274
第三次输出result:
| counts | min_weight | avg_price | ||
|---|---|---|---|---|
| color | cut | |||
| D | Fair | 163 | 0.25 | 4291.061350 |
| Good | 662 | 0.23 | 3405.382175 | |
| Ideal | 2834 | 0.20 | 2629.094566 | |
| Premium | 1603 | 0.20 | 3631.292576 | |
| Very Good | 1513 | 0.23 | 3470.467284 | |
| E | Fair | 224 | 0.22 | 3682.312500 |
| Good | 933 | 0.23 | 3423.644159 | |
| Ideal | 3903 | 0.20 | 2597.550090 | |
| Premium | 2337 | 0.20 | 3538.914420 | |
| Very Good | 2400 | 0.20 | 3214.652083 | |
| F | Fair | 312 | 0.25 | 3827.003205 |
| Good | 909 | 0.23 | 3495.750275 | |
| Ideal | 3826 | 0.23 | 3374.939362 | |
| Premium | 2331 | 0.20 | 4324.890176 | |
| Very Good | 2164 | 0.23 | 3778.820240 | |
| G | Fair | 314 | 0.23 | 4239.254777 |
| Good | 871 | 0.23 | 4123.482204 | |
| Ideal | 4884 | 0.23 | 3720.706388 | |
| Premium | 2924 | 0.23 | 4500.742134 | |
| Very Good | 2299 | 0.23 | 3872.753806 | |
| H | Fair | 303 | 0.33 | 5135.683168 |
| Good | 702 | 0.25 | 4276.254986 | |
| Ideal | 3115 | 0.23 | 3889.334831 | |
| Premium | 2360 | 0.23 | 5216.706780 | |
| Very Good | 1824 | 0.23 | 4535.390351 | |
| I | Fair | 175 | 0.41 | 4685.445714 |
| Good | 522 | 0.30 | 5078.532567 | |
| Ideal | 2093 | 0.23 | 4451.970377 | |
| Premium | 1428 | 0.23 | 5946.180672 | |
| Very Good | 1204 | 0.24 | 5255.879568 | |
| J | Fair | 119 | 0.30 | 4975.655462 |
| Good | 307 | 0.28 | 4574.172638 | |
| Ideal | 896 | 0.23 | 4918.186384 | |
| Premium | 808 | 0.30 | 6294.591584 | |
| Very Good | 678 | 0.24 | 5103.513274 |
第四次输出result:
| color | cut | counts | min_weight | avg_price | |
|---|---|---|---|---|---|
| 0 | D | Fair | 163 | 0.25 | 4291.061350 |
| 1 | D | Good | 662 | 0.23 | 3405.382175 |
| 2 | D | Ideal | 2834 | 0.20 | 2629.094566 |
| 3 | D | Premium | 1603 | 0.20 | 3631.292576 |
| 4 | D | Very Good | 1513 | 0.23 | 3470.467284 |
| 5 | E | Fair | 224 | 0.22 | 3682.312500 |
| 6 | E | Good | 933 | 0.23 | 3423.644159 |
| 7 | E | Ideal | 3903 | 0.20 | 2597.550090 |
| 8 | E | Premium | 2337 | 0.20 | 3538.914420 |
| 9 | E | Very Good | 2400 | 0.20 | 3214.652083 |
| 10 | F | Fair | 312 | 0.25 | 3827.003205 |
| 11 | F | Good | 909 | 0.23 | 3495.750275 |
| 12 | F | Ideal | 3826 | 0.23 | 3374.939362 |
| 13 | F | Premium | 2331 | 0.20 | 4324.890176 |
| 14 | F | Very Good | 2164 | 0.23 | 3778.820240 |
| 15 | G | Fair | 314 | 0.23 | 4239.254777 |
| 16 | G | Good | 871 | 0.23 | 4123.482204 |
| 17 | G | Ideal | 4884 | 0.23 | 3720.706388 |
| 18 | G | Premium | 2924 | 0.23 | 4500.742134 |
| 19 | G | Very Good | 2299 | 0.23 | 3872.753806 |
| 20 | H | Fair | 303 | 0.33 | 5135.683168 |
| 21 | H | Good | 702 | 0.25 | 4276.254986 |
| 22 | H | Ideal | 3115 | 0.23 | 3889.334831 |
| 23 | H | Premium | 2360 | 0.23 | 5216.706780 |
| 24 | H | Very Good | 1824 | 0.23 | 4535.390351 |
| 25 | I | Fair | 175 | 0.41 | 4685.445714 |
| 26 | I | Good | 522 | 0.30 | 5078.532567 |
| 27 | I | Ideal | 2093 | 0.23 | 4451.970377 |
| 28 | I | Premium | 1428 | 0.23 | 5946.180672 |
| 29 | I | Very Good | 1204 | 0.24 | 5255.879568 |
| 30 | J | Fair | 119 | 0.30 | 4975.655462 |
| 31 | J | Good | 307 | 0.28 | 4574.172638 |
| 32 | J | Ideal | 896 | 0.23 | 4918.186384 |
| 33 | J | Premium | 808 | 0.30 | 6294.591584 |
| 34 | J | Very Good | 678 | 0.24 | 5103.513274 |
7、数据的合并和连接
(1)数据的合并与连接示意图:
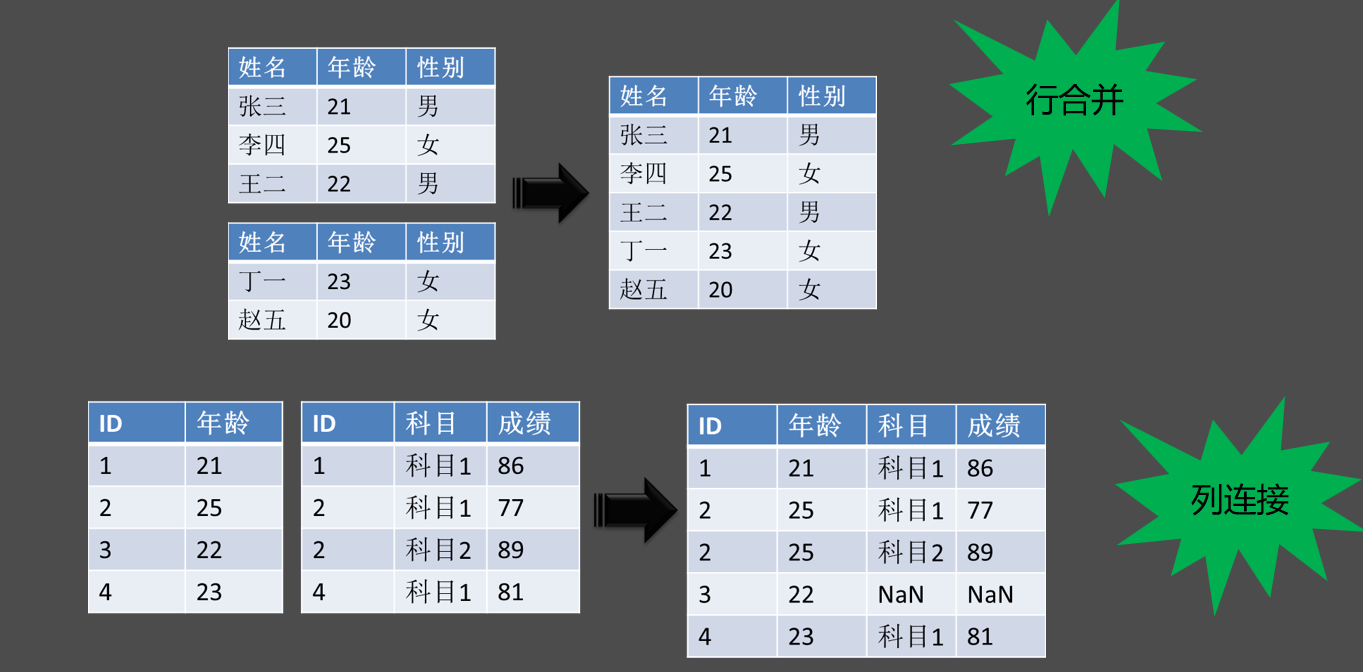
(2)数据的合并:
1)属性的说明:
- pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None)
对上述属性的说明表
| 属性 | 说明 |
|---|---|
| objs | 指定需要合并的对象,可以是序列、数据框或面板数据构成的列表 |
| axis | 指定数据合并的轴,默认为0,表示合并多个数据的行,如果为1,就表示合并多个数据的列 |
| join | 指定合并的方式,默认为outer,表示合并所有数据,如果改为inner,表示合并公共部分的数据 |
| join_axes | 合并数据后,指定保留的数据轴 |
| ignore_index | bool类型的参数,表示是否忽略原数据集的索引,默认为False,如果设为True,就表示忽略原索引并生成新索引 |
| keys | 为合并后的数据添加新索引,用于区分各个数据部分 |
2)范例测试代码:
import pandas as pd
# 构造数据集df1和df2
df1 = pd.DataFrame({'name':['张三','李四','王二'], 'age':[21,25,22],
'gender':['男','女','男']})
df2 = pd.DataFrame({'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']})
# 数据集的纵向合并
pd.concat([df1,df2] , keys = ['df1','df2']) ##
# 如果df2数据集中的“姓名变量为Name”
df2 = pd.DataFrame({'name':['丁一','赵五'], 'age':[23,22], 'gender':['女','女']})
# 数据集的纵向合并
pd.concat([df1,df2]) ##
3)输出结果:(Jupyter Notebook输出)
①创建后直接合并:
| name | age | gender | |
|---|---|---|---|
| df1 | 张三 | 21 | 男 |
| 李四 | 25 | 女 | |
| 王二 | 22 | 男 | |
| df2 | 丁一 | 23 | 女 |
| 赵五 | 22 | 女 |
②将name变为Name后合并:
| name | age | gender | Name | |
|---|---|---|---|---|
| 0 | 张三 | 21 | 男 | NaN |
| 1 | 李四 | 25 | 女 | NaN |
| 2 | 王二 | 22 | 男 | NaN |
| 0 | NaN | 23 | 女 | 丁一 |
| 1 | NaN | 22 | 女 | 赵五 |
(3)数据的连接:
1)定义:
- 内连接:用于返回两张表中的共同部分,可理解为集合的交集(缺点:两张表的数据都会有丢失)
- 左连接:保全左表的所有数据,将右表数据分配到左表中
示意图:
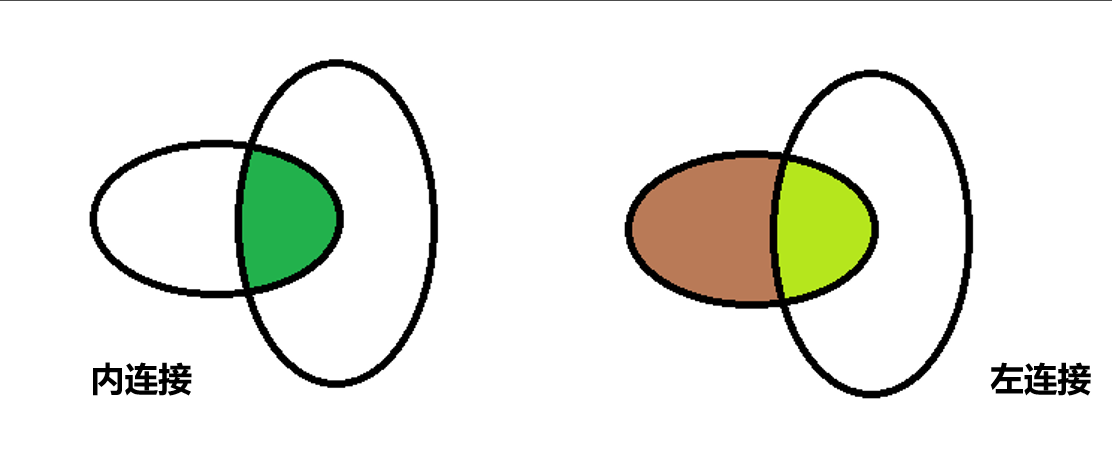
2)属性的说明:
- pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('x', '_y'))
对上述属性的说明表
| 属性 | 说明 |
|---|---|
| left | 指定需要连接的主 |
| right | 指定需要连接的辅表 |
| how | 指定连接方式,默认为inner内连,还有其他选项,如左连left、右连right和外连outer |
| on | 指定连接两张表的共同字段 |
| left_on | 指定主表中需要连接的共同字段 |
| right_on | 指定辅表中需要连接的共同字段 |
| left_index | bool类型参数,是否将主表中的行索引用作表连接的共同字段,默认为False |
| right_index | bool类型参数,是否将辅表中的行索引用作表连接的共同字段,默认为False |
| sort | bool类型参数,是否对连接后的数据按照共同字段排序,默认为False |
| suffixes | 如果数据连接的结果中存在重叠的变量名,则使用各自的前缀进行区分 |
3)范例测试代码:
import pandas as pd
# 构造数据集
df3 = pd.DataFrame({'id':[1,2,3,4,5],'name':['张三','李四','王二','丁一','赵五'],'age':[27,24,25,23,25],'gender':['男','男','男','女','女']})
df4 = pd.DataFrame({'Id':[1,2,2,4,4,4,5],
'score':[83,81,87,75,86,74,88],
'kemu':['科目1','科目1','科目2','科目1','科目2','科目3','科目1']})
df5 = pd.DataFrame({'id':[1,3,5],
'name':['张三','王二','赵五'],
'income':[13500,18000,15000]})
# 三表的数据连接
# 首先df3和df4连接
merge1 = pd.merge(left = df3, right = df4, how = 'left',
left_on='id', right_on='Id')
merge1
# 再将连接结果与df5连接
merge2 = pd.merge(left = merge1, right = df5,
how = 'left')
merge2
4)输出结果:(Jupyter Notebook输出)
①输出merge1:
| id | name | age | gender | Id | score | kemu | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 张三 | 27 | 男 | 1.0 | 83.0 | 科目1 |
| 1 | 2 | 李四 | 24 | 男 | 2.0 | 81.0 | 科目1 |
| 2 | 2 | 李四 | 24 | 男 | 2.0 | 87.0 | 科目2 |
| 3 | 3 | 王二 | 25 | 男 | NaN | NaN | NaN |
| 4 | 4 | 丁一 | 23 | 女 | 4.0 | 75.0 | 科目1 |
| 5 | 4 | 丁一 | 23 | 女 | 4.0 | 86.0 | 科目2 |
| 6 | 4 | 丁一 | 23 | 女 | 4.0 | 74.0 | 科目3 |
| 7 | 5 | 赵五 | 25 | 女 | 5.0 | 88.0 | 科目1 |
②输出merge2:
| id | name | age | gender | Id | score | kemu | income | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 张三 | 27 | 男 | 1.0 | 83.0 | 科目1 | 13500.0 |
| 1 | 2 | 李四 | 24 | 男 | 2.0 | 81.0 | 科目1 | NaN |
| 2 | 2 | 李四 | 24 | 男 | 2.0 | 87.0 | 科目2 | NaN |
| 3 | 3 | 王二 | 25 | 男 | NaN | NaN | NaN | 18000.0 |
| 4 | 4 | 丁一 | 23 | 女 | 4.0 | 75.0 | 科目1 | NaN |
| 5 | 4 | 丁一 | 23 | 女 | 4.0 | 86.0 | 科目2 | NaN |
| 6 | 4 | 丁一 | 23 | 女 | 4.0 | 74.0 | 科目3 | NaN |
| 7 | 5 | 赵五 | 25 | 女 | 5.0 | 88.0 | 科目1 | 15000.0 |
注:部分图片、数据来源网络侵删;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号